paddle OCR 文本识别总结
paddle OCR 文本识别总结
- 1、OCR学习汇总
-
- 1、文本检测
-
- 1、DB(Differentiable Binarization)
- 2、EAST(Efficient and Accuracy Scene Text)
- 3、CTPN
- 4、CRAFT(Character Region Awareness for Text)
- 5、SegLink
- 2、文本识别
-
- 1、水平文本识别,CRNN(CNM+RNN+CTC)
- 2、水平文本识别,CNN+Seq2Seq+Attention
- 3、Rosetta
- 4、STAR-Net
- 5、RARE
- 6、SRN
- 7、NRTR
- 8、SAR
- 9、SEED
- 3、文本分类
- 4、字符检测
-
- 1、Scene Text Recognition from Two-Dimensional Perspective
- 5、字符识别
- 6、字符分类
1、OCR学习汇总
在paddle OCR中对于文本的任务分为三步:检测、识别、分类。
1、文本检测
1、DB(Differentiable Binarization)
论文:
《Real-time Scene Text Detection with Differentiable Binarization》
摘要
最近,基于分割的方法在场景文本检测中相当流行,因为分割结果可以更准确地描述各种形状的场景文本,例如曲线文本。但是,二值化的后处理对于基于分割的检测至关重要,该检测将分割方法生成的概率图转换为文本的边界框/区域。在本文中,我们提出了一个名为可微分二值化(DB)的模块,它可以在分段网络中执行二值化过程。分段网络与数据库模块一起优化,可以自适应地设置二值化的阈值,这不仅简化了后处理,还增强了文本检测的性能。基于简单的分段网络,我们在五个基准数据集上验证了数据库的性能改进,这些数据集在检测精度和速度方面始终如一地实现了最先进的结果。
特别是,使用轻量级主干网,DB的性能改进是显着的,因此我们可以在检测精度和效率之间寻找理想的权衡。具体来说,使用ResNet-18的主干,我们的探测器在MSRA-TD500数据集上实现了82.8的F测量,以62FPS的速度运行。
1、DB算法全称可微分二值化处理,基于分割的场景文本检测即把分割方法产生的概率图(热力图)转化为边界框和文字区域,其中会包含二值化的后处理过程。二值化的过程非常关键,常规二值化操作通过设定固定的阈值,然而固定的阈值难以适应复杂多变的检测场景。本文作者提出了一种可微分的二值化操作,通过将二值化操作插入到分割网络中进行组合优化,从而实现阈值在热力图各处的自适应。
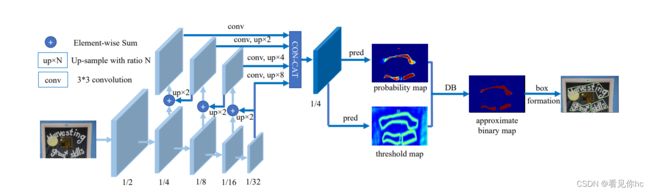
简要解释:
1、首先通过卷积网络进行特征提取(Resnet 18);
2、对提取到的特征通过特征金字塔(FPN)进行融合,后一层特征二倍上采样后与前一层特征进行融合(Element-wise Sum);
3、将特征金字塔生成的特征进行拼接(CONTACT),之后预测Probability map和threshold map用于后续的二值化图像(approximate binary map);
4、由二值化图像(approximate binary map)收缩得到文字区域。
在之前的文本检测网络中,获取到segmentation map图后,一般人为设定一个阈值,将其二值化,之后根据二值化的结果(binarization map),再慢慢扩大典型区域(红色区域),找到文字区域。
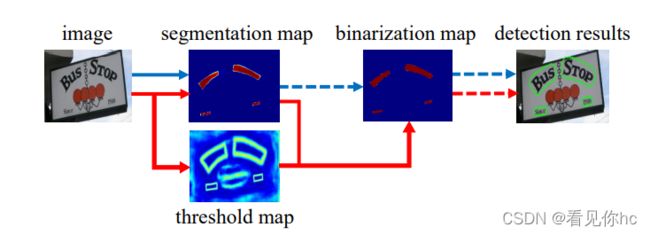
2、DB与传统方法区别在于阈值选取方面,通过网络预测每一个位置处的阈值,而不是采用一个固定的值,可以很多的将背景和前景分离出来,但是这样的操作会遇到一个问题:给训练带来了梯度不可微的情况,因此,对于此二值化提出了Differentiable Binarization (DB)来解决不可微的问题。
将常见的二值化函数进行sigmoid近似,则二值化函数变得可微,具体如下所示:
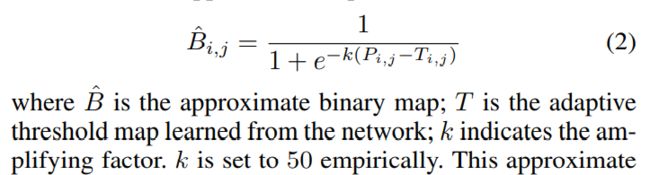
—————————————————————————————————————————————————————————————

2、EAST(Efficient and Accuracy Scene Text)
论文:
《EAST: An Efficient and Accurate Scene Text Detector》
摘要
以前的场景文本检测方法已经在各种基准测试中取得了可喜的性能。然而,即使在配备深度神经网络模型的情况下,它们在处理具有挑战性的场景时通常也不足,因为整体性能由pipelines中多个阶段和组件的相互作用决定。在这项工作中,我们提出了一个简单而强大的pipelines,可以在自然场景中产生快速准确的文本检测。该pipeline直接预测完整图像中任意方向和四边形的单词或文本行,消除了不必要的中间步骤(例如,候选聚合和单词分区),使用单个神经网络。我们pipeline的简单性允许将精力集中在设计损失函数和神经网络架构上。在ICDAR 2015、COCO-Text和MSRA-TD500等标准数据集上的实验表明,所提出的算法在精度和效率方面均明显优于最先进的方法。
1、目前主流文本检测网络与我们的网络的比较
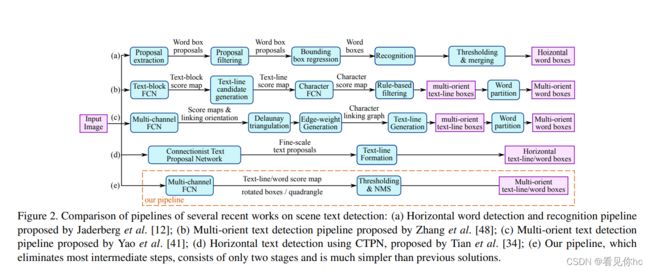
2、文章的创新之处
1.提出了一个由两阶段组成的场景文本检测方法:全卷积网络阶段和NMS阶段。
2.该pipeline可灵活生成word level或line level上文本框的预测,预测的几何形状可为旋转框或水平框。
3.算法在准确性和速度上优于最先进的方法。
3、网络结构
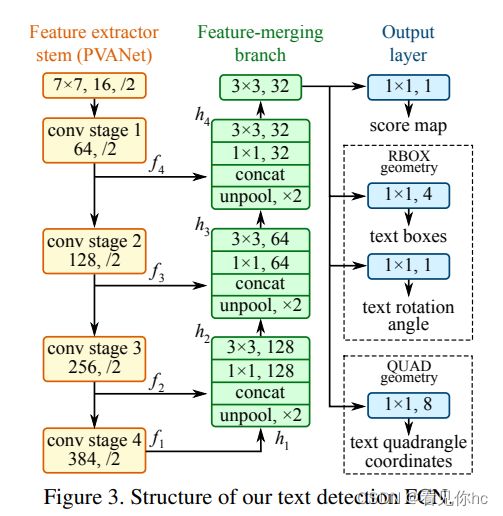
参考链接:
链接: link
3、CTPN
论文:
《Detecting Text in Natural Image with Connectionist Text Proposal Network》
1、这个算法很有创新,Faster RCNN做目标检测的一个缺点就是,没有考虑带文本自身的特点。文本行一般以水平长矩形的形式存在,而且文本行中每个字都有间隔。针对这个特点,CTPN提出一个新奇的想法,我们可以把文本检测的任务拆分,第一步我们检测文本框中的一部分,判断它是不是一个文本的一部分,当对一幅图里所有小文本框都检测之后,我们就将属于同一个文本框的小文本框合并,合并之后就可以得到一个完整的、大的文本框了,也就完成了文本的检测任务。这个想法真的很有创造性,有点像“分治法”,先检测大物体的一小部分,等所有小部分都检测出来,大物体也就可以检测出来了。
2、除了这个新意,CTPN还提出了在文本检测中应加入RNN来进一步提升效果。为什么要用RNN来提升检测效果?
文本具有很强的连续字符,其中连续的上下文信息对于做出可靠决策来说很重要。我们知道RNN常用于序列模型,比如事件序列,语言序列等等,那我们CTPN算法中,把一个完整的文本框拆分成多个小文本框集合,其实这也是一个序列模型,可以利用过去或未来的信息来学习和预测,所以同样可以使用RNN模型。
3、在CTPN中,用的还是BiLSTM(双向LSTM,可以利用前、后的信息进行推理),因为一个小文本框,对于它的预测,我们不仅与其左边的小文本框有关系,而且还与其右边的小文本框有关系!这个解释就很有说服力了,如果我们仅仅根据一个文本框的信息区预测该框内含不含有文字其实是很草率的,我们应该多参考这个框的左边和右边的小框的信息后(尤其是与其紧挨着的框)再做预测准确率会大大提升。
4、CRAFT(Character Region Awareness for Text)
论文:
《Character Region Awareness for Text Detection》
摘要
基于神经网络的场景文本检测方法最近已经出现,并显示出有希望的结果。 以前使用刚性单词级边界框训练的方法在以任意形状表示文本区域方面存在局限性。本文提出了一种新的场景文本检测方法,通过探索每个字符和字符之间的亲和力来有效地检测文本区域。为了克服缺乏单个字符级注释的问题,我们提出的框架既利用了合成图像的给定字符级注释,也利用了通过学习的临时模型获得的真实图像的估计字符级基本事实。为了估计字符之间的亲和力,使用新提出的亲和力表示来训练网络。对六个基准测试的广泛实验,包括包含自然图像中高度弯曲文本的TotalText和CTW-1500数据集,表明我们的字符级文本检测明显优于最先进的检测器。根据研究结果,我们提出的方法保证了检测复杂场景文本图像的高度灵活性,例如任意定向,弯曲或变形的文本。
1、核心思想
提出单字分割以及单字间分割的方法,更符合目标检测这一核心概念,不是把文本框当做目标,这样使用小感受野也能预测大文本和长文本,只需要关注字符级别的内容而不需要关注整个文本实例。
提出如何利用现有文本检测数据集合成数据得到真实数据的单字标注的弱监督方法。
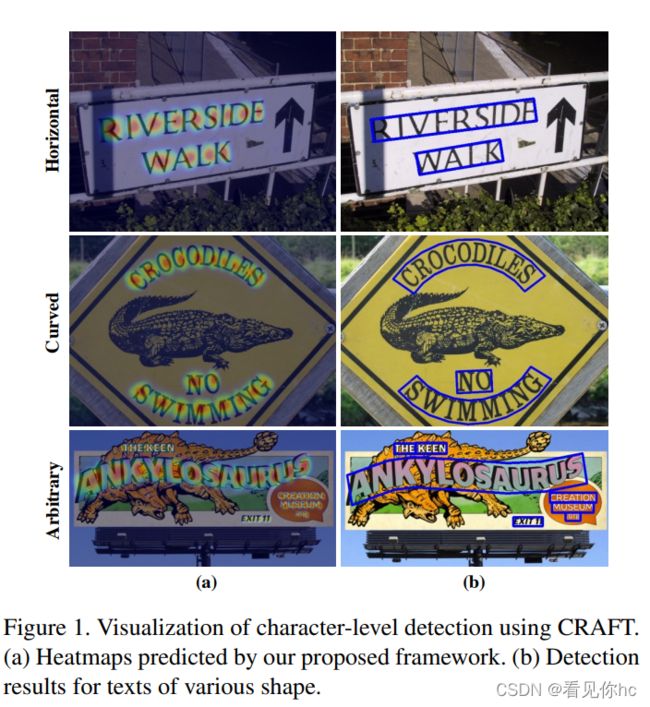
检测效果一览
2、网络结构
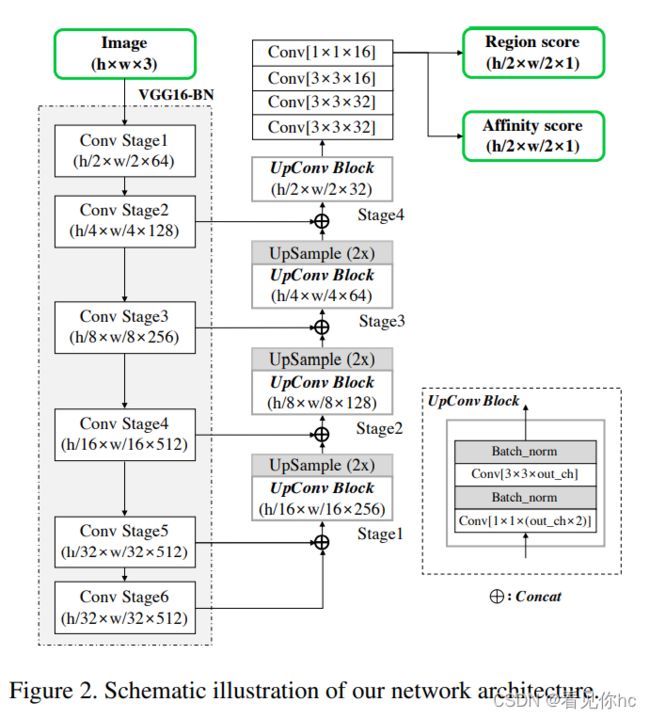
其实主要就是一个基于VGG16骨干网的FCN网络,文章的解码器采用了U-Net的方法,在stage4后再接几个卷积层便可以得到分割图像,这里输出分为两个通道region score和affinity score,分别为单字符中心区域的概率和相邻字符区域中心的概率,得到原图大小1/2的预测图。
3、训练过程示意图
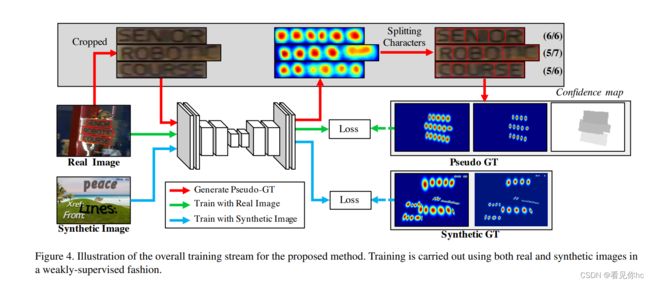
训练分为两种方式:人造数据和real数据集。
在real image没有字符级别的标注时,自己检测合成产生label再进行训练。如上图所示,对真实场景中的数据集和人造合成的数据集有不同的训练方式。
4、region score GT和affinity score GT生成
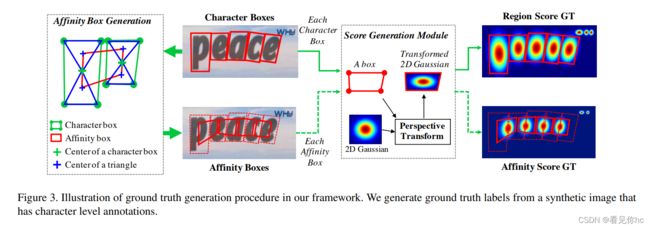
上述过程可以简单描述为
先找到Character Box的中心(center),之后连接中心和四个顶点。找到上下两个三角形的中心(center),之后将两个Character box的四个三角形的中心连接,形成Affinity Box;
之后将二维Gaussian函数根据仿射变换变换形状(这里仿射变换的参数是由A box生成,但是这个box是从哪里来的呢?难道是Character Box和Affinity Box),得到Region Score GT和Affinity Score GT;
5、如何由词一级别的标注信息获取字符级别的标注信息
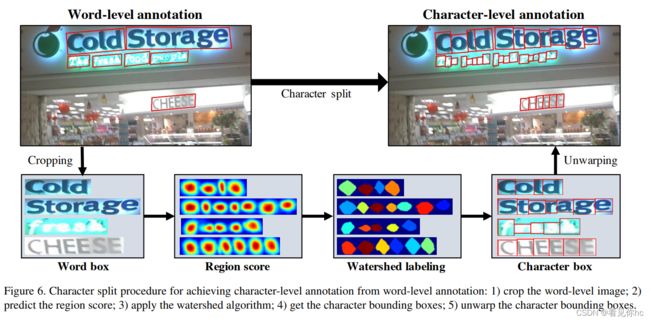
参考链接:
链接: link
5、SegLink
论文:
《Detecting Oriented Text in Natural Images by Linking Segments》
摘要
大多数最先进的文本检测方法都特定于水平拉丁文本,并且对于实时应用程序来说速度不够快。我们介绍分段链接(SegLink),这是一种面向文本的检测方法。主要思想是将文本分解为两个本地可检测的元素,即段和链接。句段是一个定向框,覆盖单词或文本行的一部分;链接连接两个相邻的段,指示它们属于同一单词或文本行。这两个元素都由端到端训练的全卷积神经网络在多个尺度上密集检测。通过组合通过链接连接的段来生成最终检测。与以前的方法相比,SegLink在准确性,速度和易于训练的维度上有所提高。它在标准ICDAR 2015附带(挑战4)基准上实现了75.0%的f测量,大大优于之前的最佳水平。它在512×512张图像上以超过20 FPS的速度运行。此外,无需修改,SegLink能够检测长行非拉丁文本,如中文。
1、检测效果一览

2、网络结构
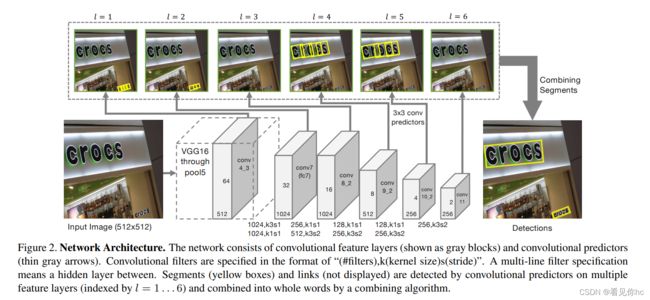
3、link思想

4、输出
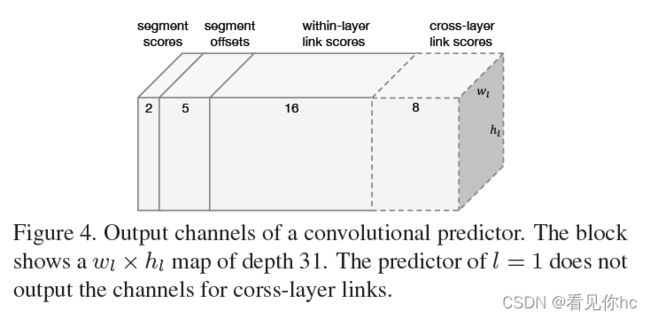
5、总结
1、引入了预测框的角度变量
2、与之前的网络不同,这里在每个尺度上都进行预测
2、文本识别
1、水平文本识别,CRNN(CNM+RNN+CTC)
论文:
《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition》
摘要
基于图像的序列识别一直是计算机视觉领域长期的研究课题。本文探讨了场景文本识别问题,这是基于图像的序列识别中最重要和最具挑战性的任务之一。提出一种将特征提取、序列建模和翻译集成到一个统一框架中的新型神经网络架构。与以往的场景文本识别系统相比,所提出的架构具有四个独特的特性:
(1)它是端到端可训练的,与大多数现有算法相比,其组件是单独训练和调优的。
(2)它自然处理任意长度的序列,不涉及字符分割或水平尺度归一化。
(3)不局限于任何预定义的词典,在无词典和基于词典的场景文本识别任务中都取得了卓越的表现。
(4)它生成了一个有效但小得多的模型,这对于实际应用场景来说更实用。在标准基准测试(包括IIIT-5K、街景文本和ICDAR数据集)上的实验证明了所提出算法优于现有技术。此外,该算法在基于图像的音乐乐谱识别任务中表现良好,显然验证了其普遍性。
CRNN 全称为 Convolutional Recurrent Neural Network,主要用于端到端地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别(目前没有思路将其应用到单个字符识别)。
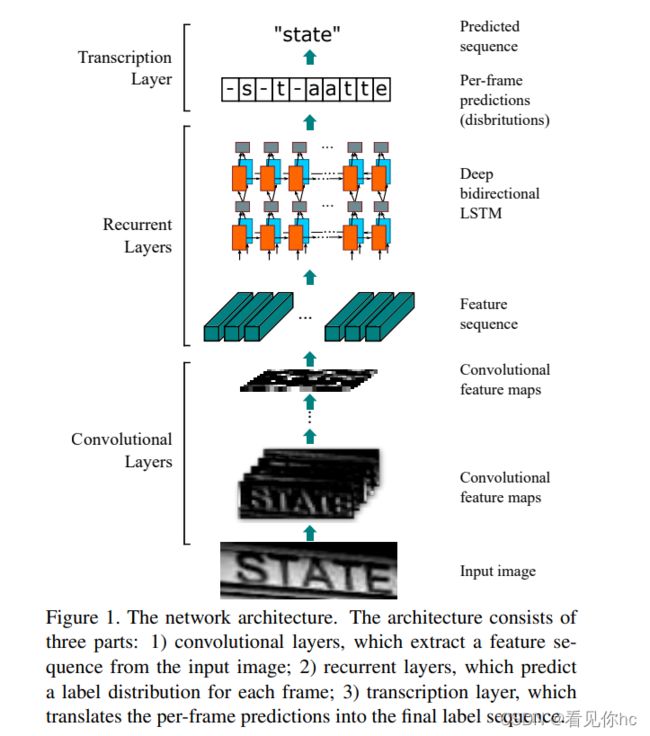
简要解释:
1、在卷积层通过简单的CNN网络,提取图像的卷积特征。注意这里的输入是文件检测出的区域,不再是整张图片。
2、将文本区域提取出的卷积特征输入到循环网络层,例如:深层双向LSTM网络,在卷积特征的基础上继续提取文字序列特征。
RNN对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息
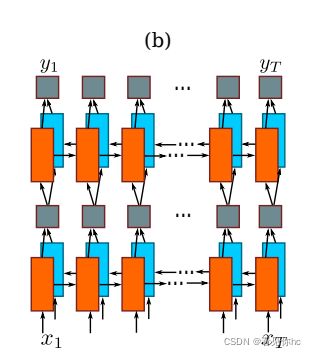
这里 x 1 … … x t x_1……x_t x1……xt 可以理解为每个Feature Sequence,黄色、蓝色方格理解为Feature Sequence中的元素?
3、将循环神经网络的输出结果做softmax后,输出字符。
值得注意的地方:
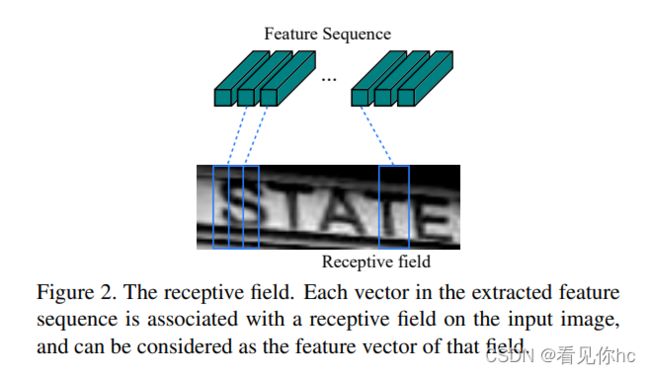
特征序列(Feature Sequence)的每个特征向量都是按列在特征图上从左到右生成的。 每一个特征序列表征了输入中某一段区间的特征信息。
CTC简介:
对于Recurrent Layers,如果使用常见的Softmax cross-entropy loss,则每一列输出都需要对应一个字符元素。那么训练时候每张样本图片都需要标记出每个字符在图片中的位置,再通过CNN感受野对齐到Feature map的每一列获取该列输出对应的Label才能进行训练。
在实际情况中,标记这种对齐样本非常困难(除了标记字符,还要标记每个字符的位置),工作量非常大。另外,由于每张样本的字符数量不同,字体样式不同,字体大小不同,导致每列输出并不一定能与每个字符一一对应。
当然这种问题同样存在于语音识别领域。例如有人说话快,有人说话慢,那么如何进行语音帧对齐,是一直以来困扰语音识别的巨大难题。
Connectionist Temporal Classification(CTC)是一种Loss计算方法,用CTC代替Softmax Loss,训练样本无需对齐。其具有一下特点:
引入blank字符,解决有些位置没有字符的问题。
通过递推,快速计算梯度。
2、水平文本识别,CNN+Seq2Seq+Attention
在Seq2Seq结构中,编码器Encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻 t − 1 t-1 t−1 的输出作为后一个时刻 t t t 的输入,循环解码,直到输出停止符为止。
然而,上述过程只是Seq2Seq结构的一种经典实现方式。与经典RNN结构不同的是,Seq2Seq结构不再要求输入和输出序列有相同的时间长度!
在Seq2Seq结构中,encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由Decoder解码。由于context包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。如机器翻译问题,当要翻译的句子较长时,一个Context可能存不下那么多信息,就会造成精度的下降。除此之外,如果按照上述方式实现,只用到了编码器的最后一个隐藏层状态,信息利用率低下。
所以如果要改进Seq2Seq结构,最好的切入角度就是:利用Encoder所有隐藏层状态 h t h_t ht 解决Context长度限制问题。
3、Rosetta
4、STAR-Net
5、RARE
6、SRN
7、NRTR
8、SAR
9、SEED
3、文本分类
4、字符检测
1、Scene Text Recognition from Two-Dimensional Perspective
论文:
《Scene Text Recognition from Two-Dimensional Perspective》
摘要
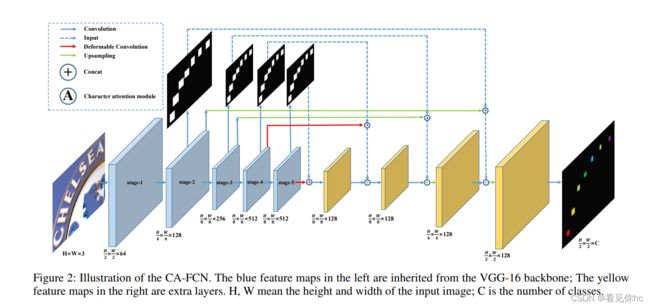
受语音识别的启发,最近最先进的算法大多将场景文本识别视为序列预测问题。虽然这些方法取得了优异的性能,但通常忽略了一个重要事实,即图像中的文本实际上是在二维空间中分布的。它的性质与语音的性质完全不同,语音本质上是一维信号。原则上,将文本的特征直接压缩为一维形式可能会丢失有用的信息并引入额外的噪音。 在本文中,我们从二维视角接近场景文本识别。一种简单而有效的模型,称为字符注意完全卷积网络(CA-FCN),用于识别任意形状的文本。 场景文本识别是通过语义分割网络实现的,其中采用了对字符的注意力机制。结合单词形成模块,CAFCN可以同时识别脚本并预测每个字符的位置。实验表明,所提出的算法在常规和不规则文本数据集上均优于先前的方法。此外,事实证明,在文本检测阶段进行不精确的本地化会更加健壮,这在实践中非常普遍。
1、传统水平文本检测和弯曲不规则文本检测。
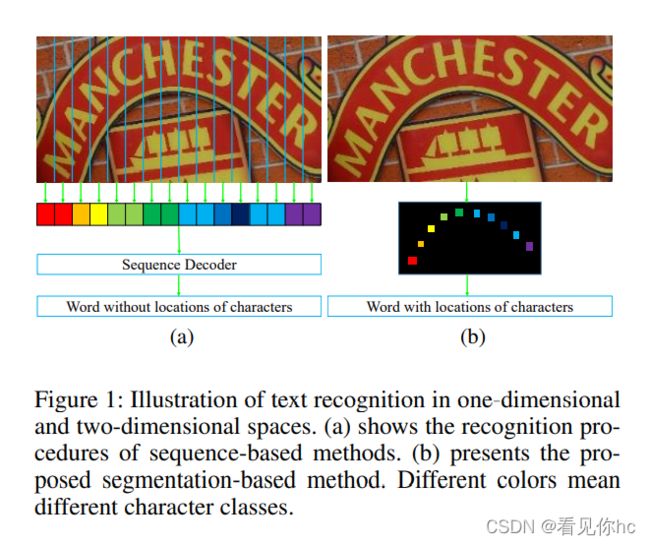
2、网络结构示意图
引入了注意力机制和可变形卷积
3、效果显示
