嵩天《Python数据分析与展示》实例5:Pandas库分析房价增幅与M2增幅的相关性
关于Pandas库的使用方法,嵩天老师做了详细的介绍,具体的知识点暂不一一列举,这里仅对其中用到的一个实例做基本的记录。
目录
1.相关性指数计算
2.Series类型数据可视化呈现
3.DataFrame类型数据可视化呈现
1.相关性指数计算
这个例子介绍的是如何使用Pandas数据的相关性进行分析,涉及的知识点包括创建Pandas的Series类型数据以及计算两组数据的相关性系数,代码的构成非常简单,如下:
#微实例1:房价增幅与M2增幅的相关性指数计算
import pandas as pd
hprice=pd.Series([3.04,22.93,12.75,22.6,12.33],index=['2008','2009','2010','2011','2012'])
#调用Pandas库创建Series类型的房价增幅数据,指定索引标签为年份
M2=pd.Series([8.18,18.18,9.13,7.82,6.69],index=['2008','2009','2010','2011','2012'])
#使用同样的方法创建对应年份的M2增幅数据
print('房价增幅与M2增幅的相关性指数为:{:.2f}'.format(hprice.corr(M2)))运行结果是打印计算出的相关性指数,如下:
房价增幅与M2增幅的相关性指数为:0.52
在写这段小代码时还出现过一个错误,就是我把print('房价增幅与M2增幅的相关性指数为:{:.2f}'.format(hprice.corr(M2)))中的{:.2f}漏掉冒号写成{.2f}了,这种情况会报错:
AttributeError: 'numpy.float64' object has no attribute '2f'
2.Series类型数据可视化呈现
从打印的相关性指数结果可以看到,两者的相关性不是特别强,属于中等,引入之前的pyplot将数据做简单的可视化后也可以曲线的变化趋势看出两者的相关程度:
#微实例2:房价增幅与M2增幅的Series类型数据可视化呈现
import matplotlib.pyplot as plt
import pandas as pd
hprice=pd.Series([3.04,22.93,12.75,22.6,12.33],index=['2008','2009','2010','2011','2012'])
M2=pd.Series([8.18,18.18,9.13,7.82,6.69],index=['2008','2009','2010','2011','2012'])
hprice.plot()
M2.plot()
plt.show()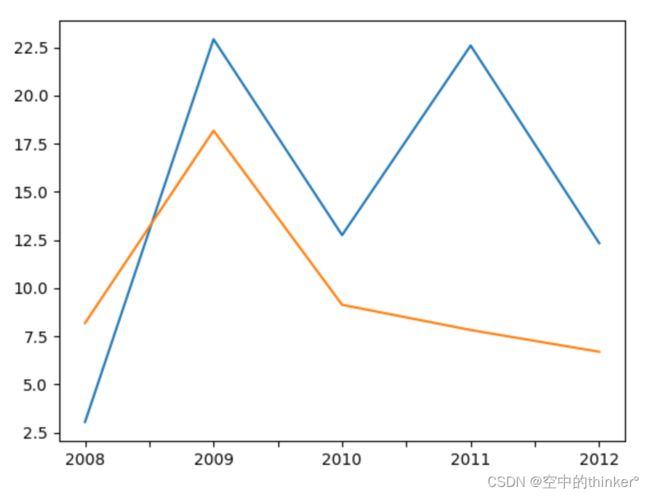
3.DataFrame类型数据可视化呈现
为了复习Pandas的另一种数据类型DataFrame,我决定将这两组数合并,并创建为DataFrame类型数据,再在此基础上做可视化呈现,代码如下:
#微实例3:房价增幅与M2增幅的DataFrame类型数据可视化呈现
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib
#由于标签包含中文文本,为了使中文正常显示,这里需额外引入matplotlib库
matplotlib.rcParams['font.family']='SimHei'
#将字体改为细黑,这样中文就能正常显示了
Values={'房价增幅':pd.Series([3.04,22.93,12.75,22.6,12.33],index=[2008,2009,2010,2011,2012]),
'M2增幅':pd.Series([8.18,18.18,9.13,7.82,6.69],index=[2008,2009,2010,2011,2012])}
DataFrameValues=pd.DataFrame(Values)
#使用一维ndarray对象字典创建DataFrame类型数据
DataFrameValues.plot()
plt.show()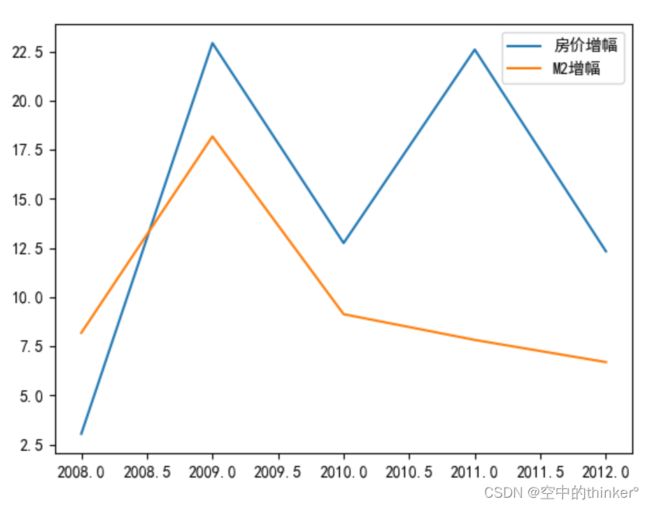
这里出现了一件非常让我困惑的事情,即年份变成了小数且新增了一些中间值如2008.5,可是将代码中的DataFrameValues打印出来显示的是正常的数据,与写入的一致,不清楚为什么绘图时会自动更改索引的值。
尝试用DataFrameValues['年份']=DataFrameValues['年份'].astype(int)将年份这一列的数据转置成整数也依然如此,暂时还没有找到解决方案,这里先保留这个困惑吧,希望后面能找到原因所在。
参考资料:
嵩天. Python数据分析与展示[EB/OL].https://www.icourse163.org/learn/BIT-1001870002.