集成学习(上)——Task1 机器学习三要素
机器学习三要素
- 进度条
- 踩的小坑
- 机器学习到底学习啥?
- 文科生能搞定机器学习吗?
- 常用的工具有哪些?[^1]
- 回归
-
- 具体过程
-
- 数据导入
- 数据概览
- 模型训练——线性回归
-
- 制作训练集和测试集的数据
- 训练模型
- 分类
- 无监督学习
进度条
踩的小坑
RemoveError: 'setuptools' is a dependency of conda and cannot be removed from conda's operating environment.
今天莫名其妙,我的jupyter总是报这个错误,然后打开的时候Home可以显示,但具体的文件打开总是一片空白。第一反应是上次非正常关机导致jupyter的配置或者哪里出了什么bug,所以第一个 想到的解决思路是重装Jupyter。但是重装后总是显示,Setuptools有问题,如下:
![]()
就搞得很郁闷,于是就上CSDN看了一下,发现说的是浏览器打开少了点配置,具体看这里:
https://blog.csdn.net/xavier_muse/article/details/83830394
尝试了一波,还是没解决。郁闷极了,本来想着重装一遍Anaconda,但是有点担心之前配的那些环境都没了,所以随手复制了一下Host在Edges打开,奇迹出现了!!!居然可以呈现,真的是不知道哪里搭错了,上百度看了一下,也有人反映这样的问题,求大佬解释一下具体原因。
机器学习到底学习啥?
顾名思义,机器学习的主体是机器,谓语是学习,说的就是研究怎么让机器学东西。但是他们看的不是书,看的是一堆数据,说白了,就是让计算机从一堆数据中,通过我们设定好的数学模型与算法,从而在数据中找到某种规律(或者称为模式)。对于一个新的场景或者样本的特征,利用这个规律,对未知的或者无法获取的数据进行预测。
常见的机器学习应用场景有:天气预测、股市预测、字符识别、语音识别、人脸识别等等,对于人类而言,这些任务是很容易被实现的,但是对于机器,由于我们不知道我们自己是怎么会的,只是能完成这样子的任务。所以,我们很难人工设计一个算法实现我们学习的过程。
随着统计学的推进与发展,人们尝试着去对一些线性的有标注的数据进行计算,企图找到一条直线,来揭示样本的特征 X X X与值 y y y的关系,所以这就是在有标注的数据集上做的一种尝试,即有监督学习,给定某些特征去估计因变量,因变量存在的时候,我们称这个机器学习任务为有监督学习。在有监督学习任务中,如果我们研究的数据集的因变量是连续的,我们称这个任务为回归,也就是说,找到的这个模型是连续的。否则,我们就是对一些数据在进行区分,加以分类,我们称其为分类。
随着生产的需要,我们发现有些数据我们似乎找不到他们的因变量 y y y,需要我们去用算法分辨出各种类别之间的区别,从而将数据进行某种“分类”(这里分类是不太标准的说法,因为分类属于有监督学习,而在没有因变量标注的情况下的“分类”,我们称之为聚类)。
文科生能搞定机器学习吗?
显然,可以。
在实际的应用中,有许多的模型已经被大佬们研究出来了,你只要稍微的了解他的应用背景,和优缺点,以及在使用中的坑,我想你已经能够解决大部分生活中的机器学习问题,只是如果希望得到一个很好的效果,那么建议还是学一下原理。另外,python与R语言已经集成了大量的包与函数,您只需会import、fit基本上就能使得动大部分的库和模块了,当然,您依旧需要一点关于python或者R编程的知识。在这个专题中,我们还是主要以python的实战为主。
常用的工具有哪些?1
下面介绍一下在python中常见的常见的机器学习库:
- NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,
支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。一般简写为np。
import numpy as np
- pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。一般简写为
pd。
import pandas as pd
- matplotlib 是python的综合的可视化库,是一个综合库,用于在Python中创建静态,动画和交互式可视化。
ggplot2的核心理念是将绘图与数据分离,数据相关的绘图与数据无关的绘图分离。按图层作图,保有命令式作图的调整函数,使其更具灵活性,并将常见的统计变换融入到了绘图中。
ggplot的绘图有以下几个特点:第一,有明确的起始(以ggplot函数开始)与终止(一句语句一幅图);其二,图层之间的叠加是靠“+”号实现的,越后面其图层越高。 - %matplotlib作用
是在使用jupyter notebook 或者 jupyter qtconsole的时候,才会经常用到%matplotlib,也就是说那一份代码可能就是别人使用jupyter notebook 或者 jupyter qtconsole进行编辑的。
而%matplotlib具体作用是当你调用matplotlib.pyplot的绘图函数plot()进行绘图的时候,或者生成一个figure画布的时候,可以直接在你的python console里面生成图像。
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use("ggplot")
- seaborn是基于matplotlib的图形可视化python包。它提供了一种高度交互式界面,便于用户能够做出各种有吸引力的统计图表。直观来说,seaborn画出来的图会更好看,但是渲染的速度也会相对来说比较慢。
import seaborn as sns
回归
如何用sklearn的例子实现回归呢?首先我们要明白我们究竟要做什么:我们希望找到一个有多个变量的函数 f f f,当我们输入特征1、特征2、特征3、···、特征 k k k时,我们可以通过函数 f f f得到一个输出值(或是一个向量),使得这些输出值误差越少越好。具体的算法和原理,我们在下篇文章具体的去讨论,我们先使用一个数据集Boston房价数据来演示一遍这个过程。
具体过程
数据导入
- 导入机器学习算法库
sklearn
# 引入相关科学计算包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use("ggplot")
import seaborn as sns
from sklearn import datasets
- 读取内置数据Boston房价数据
boston = datasets.load_boston() # 返回一个类似于字典的类
X = boston.data
y = boston.target
features = boston.feature_names
- 用
pandas将返回的ndarray转换成DataFrame
这样做的好处是,方便前期的数据预处理,同时又可以和sklearn的工具进行交互。
boston_data = pd.DataFrame(X,columns=features)
boston_data["Price"] = y
数据概览
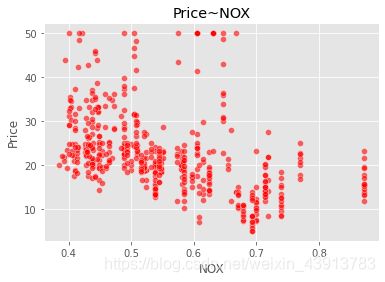
我们画出具体的一个特征 NOX一氧化氮浓度(千万分之一) 与价格的关系。
sns.scatterplot(boston_data['NOX'],boston_data['Price'],color="r",alpha=0.6)
plt.title("Price~NOX")
plt.show()
模型训练——线性回归
制作训练集和测试集的数据
我只选取了部分特征,分别是:较低地位人口、按城镇分配的学生与教师比例、每个住宅的平均房间数
data_pd = data_pd[['LSTAT','PTRATIO','RM','price']]
y = np.array(data_pd['price'])
data_pd=data_pd.drop(['price'],axis=1)
X = np.array(data_pd)
# 分割训练集和测试集
train_X,test_X,train_Y,test_Y = train_test_split(X,y,test_size=0.2)
训练模型
# 加载模型
linreg = LinearRegression()
# 拟合数据
linreg.fit(train_X,train_Y)
# 进行预测
y_predict = linreg.predict(test_X)
# 计算均方误差
metrics.mean_squared_error(y_predict,test_Y)
最后的误差约为22.02。还是一个比较高的波动的,后面会采用特征工程与集成学习的方式来优化这个结果,现在只需要有一个简单的印象即可。
分类
分类我们采用另外一个经典的数据集,那就是iris数据集,它的目标是根据花的特征,分出花的类别。
- 首先同上面一样,导入数据:
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
features = iris.feature_names
iris_data = pd.DataFrame(X,columns=features)
iris_data['target'] = y
- 做一步简单的可视化
marker = ['s','x','o']
for index,c in enumerate(np.unique(y)):
plt.scatter(x=iris_data.loc[y==c,"sepal length (cm)"],y=iris_data.loc[y==c,"sepal width (cm)"],alpha=0.8,label=c,marker=marker[c])
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.legend()
plt.show()
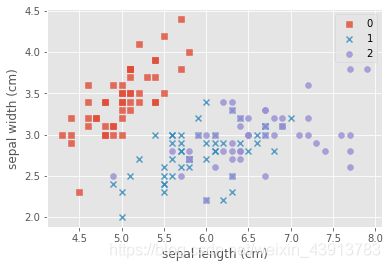
我们可以看到:每种不同的颜色和点的样式为一种类型的鸢尾花,数据集有三种不同类型的鸢尾花。因此因变量是一个类别变量,因此通过特征预测鸢尾花类别的问题是一个分类问题。
无监督学习
我们可以使用sklearn生成符合自身需求的数据集,下面我们用其中几个函数例子来生成无因变量的数据集:
举个例子:
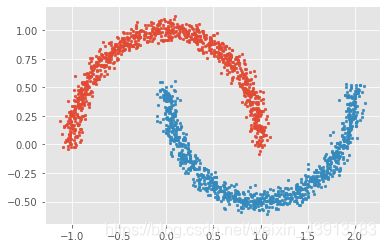
# 生成月牙型非凸集
from sklearn import datasets
x, y = datasets.make_moons(n_samples=2000, shuffle=True,
noise=0.05, random_state=None)
for index,c in enumerate(np.unique(y)):
plt.scatter(x[y==c,0],x[y==c,1],s=7)
plt.show()
# 生成符合正态分布的聚类数据
from sklearn import datasets
x, y = datasets.make_blobs(n_samples=5000, n_features=2, centers=3)
for index,c in enumerate(np.unique(y)):
plt.scatter(x[y==c, 0], x[y==c, 1],s=7)
plt.show()
Datawhale 组队学习——集成学习 ↩︎