Scala | Spark核心编程 | SparkCore | 算子
文章目录
-
- 一、SparkCore
-
- 1.RDD
-
- 1.1 概念
- 1.2 RDD的五大属性(重点)
- 1.3 RDD理解图
- 2.Spark任务执行原理
- 3.Spark代码流程
- 二、算子
-
- 1.Transformations转换算子
-
- 1.1 filter算子
- 1.2 map算子
- 1.3 flatMap算子
- 1.4 sample算子
- 1.5 reduceByKey算子
- 1.6 sortByKey与sortBy算子
- 1.7 join算子
- 1.8 union算子
- 1.9 intersection算子
- 1.10 subtract算子
- 1.11 mapPartition算子
- 1.12 distinct算子(map+reduceByKey+map)
- 1.13 cogroup算子
- 1.14 mapPartitionWithIndex算子
- 1.15 repartition算子
- 1.16 coalesce算子
- 1.17 groupByKey算子
- 1.18 zip算子
- 1.19 zipWithIndex算子
- 2.Action行动算子
-
- 2.1 count算子
- 2.2 take(n)`算子
- 2.3 first算子
- 2.4 foreach算子
- 2.5 collect算子
- 2.6 foreachPartition算子
- 2.7 countByKey算子
- 2.8 countByValue算子
- 2.9 reduce算子
- 3.控制算子(持久化算子)
-
- 3.1 cache算子
- 3.2 persist算子
- 3.3 cache 和 persist 的注意事项
- 3.4 checkpoint算子
- 课程地址:spark讲解
- Scala | Spark基础入门 | IDEA配置 | 集群搭建与测试
- Scala | Spark核心编程 | SparkCore | 算子
- Scala | 宽窄依赖 | 资源调度与任务调度 | 共享变量 | SparkShuffle | 内存管理
- Scala | SparkSQL | 创建DataSet | 序列化问题 | UDF与UDAF | 开窗函数
一、SparkCore
1.RDD
1.1 概念
RDD(Resilient Distributed Dataset) ,弹性分布式数据集。
1.2 RDD的五大属性(重点)
- RDD 是由一系列的 partition 组成的。
- 函数是作用在每一个 partition(split)上的。
- RDD 之间有一系列的依赖关系。
- 分区器是作用在 K,V 格式的 RDD 上。
- RDD 提供一系列最佳的计算位置,体现了大数据中“计算移动数据不移动”的理念。
1.3 RDD理解图
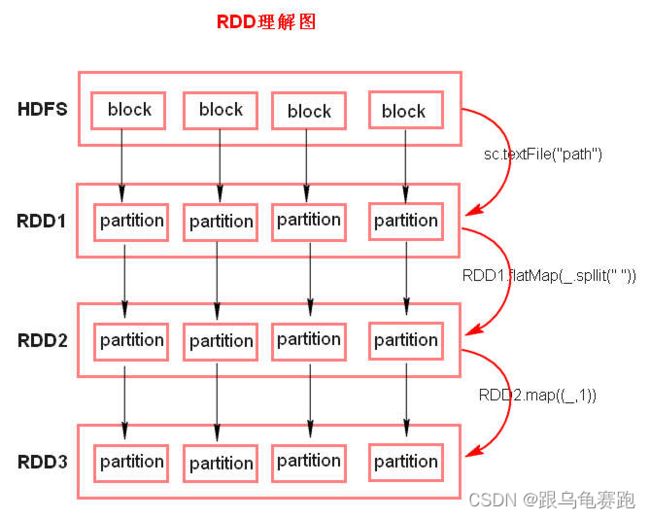
注意:
-
textFile方法底层封装的是MR读取文件的方式,读取文件之前先split,默认split大小是一个block大小。 -
RDD实际上不存储数据,这里方便理解,暂时理解为存储数据。 -
什么是
K、V 格式的 RDD?
如果RDD里面存储的数据都是二元组对象,那么这个 RDD 我们就叫做 K,V 格式的 RDD。 -
哪里体现
RDD的弹性?
RDD是由 一系列的partition组成。其大小和数量都是可以改变的,默认情况下,partition的个数和block块个数相同,体现了RDD的弹性。 -
哪里体现
RDD的容错?
RDD之间存在依赖关系,子RDD可以找出对应的父RDD然后通过一系列计算得到相应结果,这就是容错的体现。 -
哪里体现
RDD的分布式?RDD是由Partition组成,partition是分布在不同节点上的。RDD提供计算最佳位置,体现了数据本地化。体现了大数据中“计算移动数据不移动”的理念。
2.Spark任务执行原理
以standalone模式为例,Standalone模式是Spark自带的一种集群模式,Standalone模式是真实地在多个机器之间搭建Spark集群的环境,完全可以利用该模式搭建多机器集群,用于实际的大数据处理。
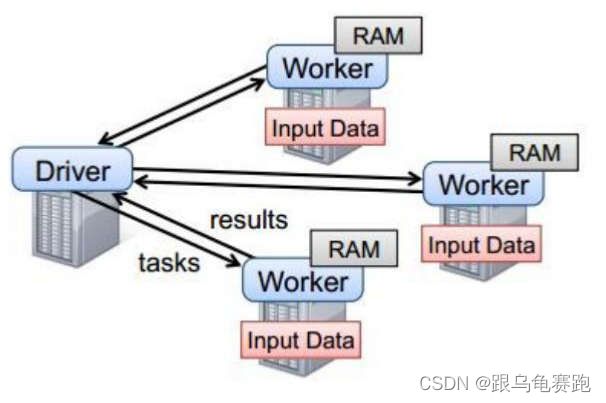
以上图中有四个机器节点,Driver 和 Worker 是启动在节点上的进程,运行在 JVM 中的进程。其中:
- Master角色以Master进程存在, Worker角色以Worker进程存在
- Driver和Executor运行于Worker进程内, 由Worker提供资源供给它们运行
- Driver 与集群节点之间有频繁的通信。
- Driver 负责任务(tasks)的分发和结果的回收。任务的调度。如果 task的计算结果非常大就不要回收了。会造成 oom。
这里只是做了简单介绍,更多可查看Spark四种运行模式介绍
3.Spark代码流程
- 创建
SparkConf对象- 可以设置
Application name。 - 可以设置运行模式及资源需求。
- 可以设置
- 创建
SparkContext对象 - 基于
SparkContext即上下文环境对象创建一个RDD,对RDD进行处理。 - 应用程序中要有
Action类算子来触发Transformation类算子执行。 - 关闭
Spark上下文对象。
二、算子
常见的算子如下图所示,主要也分为如下几种:

1.Transformations转换算子
Transformations 类算子是一类算子(函数)叫做转换算子,如map,flatMap,reduceByKey 等。Transformations 算子是延迟执行,也叫懒加载执行。
1.1 filter算子
filter:过滤符合条件的记录数,true 保留,false 过滤掉。
Operator_filter.scala:
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_filter {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("filter")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
val result = lines.filter { _.indexOf("Spark") >= 0 }
result.foreach { println}
sc.stop()
}
}
hello Spark
1.2 map算子
map:将一个 RDD 中的每个数据项,通过 map 中的函数映射变为一个新的元素。
特点:输入一条,输出一条数据。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_map {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("map")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
val result = lines.map { _.split(" ") }
result.foreach(println)
sc.stop()
}
}
[Ljava.lang.String;@1c200b99
[Ljava.lang.String;@1ae41188
[Ljava.lang.String;@72a7be25
[Ljava.lang.String;@26de52e0
1.3 flatMap算子
flatMap:先 map 后 flat。与 map 类似,每个输入项可以映射为 0 到多个输出项。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_flatMap {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("flatMap")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
val result = lines.flatMap { _.split(" ")}
result.foreach(println)
sc.stop()
}
}
hello
tiantian
hello
shsxt
hello
gzsxt
hello
Spark
1.4 sample算子
sample:随机抽样算子,根据传进去的小数按比例进行有放回或者无放回的抽样。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_sample {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("sample")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
lines.sample(true, 0.5,10).foreach(println)
}
}
hello shsxt
1.5 reduceByKey算子
reduceByKey:将相同的 Key 根据相应的逻辑进行处理。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_reduceByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("reduceByKey")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
val flatMap = lines.flatMap { _.split(" ")}
val map = flatMap.map {(_,1)}
map.reduceByKey(_+_).foreach(println)
sc.stop()
}
}
(Spark,1)
(shsxt,1)
(tiantian,1)
(hello,4)
(gzsxt,1)
1.6 sortByKey与sortBy算子
sortByKey/sortBy:作用在 K、V 格式的 RDD 上,对 key 进行升序或者降序排序。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_sortByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("sortByKey")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
val reduceResult = lines.flatMap { _.split(" ")}.map { (_,1)}.reduceByKey(_+_)
reduceResult.map(f => {(f._2,f._1)}).sortByKey(false).map(f => {(f._2,f._1)}).foreach(println)
sc.stop()
}
}
(hello,4)
(Spark,1)
(shsxt,1)
(tiantian,1)
(gzsxt,1)
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_sortBy {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("sortBy")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
val reduceResult = lines.flatMap { _.split(" ")}.map{ (_,1)}.reduceByKey(_+_)
val result = reduceResult.sortBy(_._2,false)
result.foreach{println}
sc.stop()
}
}
(hello,4)
(Spark,1)
(shsxt,1)
(tiantian,1)
(gzsxt,1)
1.7 join算子
join算子:作用在 K,V 格式的 RDD 上。根据 K 进行连接,对(K,V)join(K,W)返回(K,(V,W))
leftOuterJoin算子rightOuterJoin算子fullOuterJoin算子
注意:join 后的分区数与父 RDD 分区数多的那一个相同。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Operator_Join {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("flatMap")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(
Array(("a",1),("b",2),("c",3)),
3
)
val rdd2 = sc.parallelize(
Array(("a",1),("d",2),("e",3)),
2
)
val result1: RDD[(String, (Int, Int))] = rdd1.join(rdd2)
//注意:join 后的分区数与父 RDD 分区数多的那一个相同
println("join后的分区数=",result1.partitions.length)
result1.foreach(println)
val result2: RDD[(String, (Int, Option[Int]))] = rdd1.leftOuterJoin(rdd2)
result2.foreach(println)
val result3: RDD[(String, (Option[Int], Int))] = rdd1.rightOuterJoin(rdd2)
result3.foreach(println)
val result4: RDD[(String, (Option[Int], Option[Int]))] = rdd1.fullOuterJoin(rdd2)
result4.foreach(println)
}
}
(join后的分区数=,3)
//join
(a,(1,1))
//leftOuterJoin
(a,(1,Some(1)))
(b,(2,None))
(c,(3,None))
//rightOuterJoin
(d,(None,2))
(e,(None,3))
(a,(Some(1),1))
//fullOuterJoin
(d,(None,Some(2)))
(e,(None,Some(3)))
(a,(Some(1),Some(1)))
(b,(Some(2),None))
(c,(Some(3),None))
1.8 union算子
union算子合并两个数据集。两个数据集的类型要一致。
注意:返回新的 RDD 的分区数是合并 RDD 分区数的总和。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Operator_union {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("sortBy")
val sc = new SparkContext(conf)
//union算子
val rdd1: RDD[Int] = sc.parallelize(List(1, 2, 3), 3)
val rdd2: RDD[Int] = sc.parallelize(List(4, 5, 6), 2)
val rdd3: RDD[Int] = rdd1.union(rdd2)
println(rdd3.getNumPartitions) //并行度
rdd3.foreach(println)
sc.stop()
}
}
5
1
2
3
4
5
6
1.9 intersection算子
intersection算子:取两个数据集的交集。
注意:intersection 后的分区数与父 RDD 分区数多的那一个相同。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Operator_intersection {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("sortBy")
val sc = new SparkContext(conf)
//union算子
val rdd1: RDD[Int] = sc.parallelize(List(1, 2, 3), 3)
val rdd2: RDD[Int] = sc.parallelize(List(2, 3, 4), 2)
val rdd3: RDD[Int] = rdd1.intersection(rdd2)
println(rdd3.getNumPartitions)
rdd3.foreach(println)
sc.stop()
}
}
3
3
2
1.10 subtract算子
subtract算子是取两个数据集的差集。
注意:subtract后的分区数与父 RDD 分区数多的那一个相同。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Operator_subtract {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("sortBy")
val sc = new SparkContext(conf)
//union算子
val rdd1: RDD[Int] = sc.parallelize(List(1, 2, 3), 3)
val rdd2: RDD[Int] = sc.parallelize(List(2, 3, 4), 2)
val rdd3: RDD[Int] = rdd1.subtract(rdd2)
println(rdd3.getNumPartitions)
rdd3.foreach(println)
sc.stop()
}
}
3
1
1.11 mapPartition算子
与 map 类似,mapPartition算子遍历的单位是每个 partition 上的数据。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object Operator_mapPartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("map")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt",minPartitions = 2)
//map算子
lines.map(x=>{
println("创建数据库连接:")
println("插入数据"+x)
println("关闭数据库连接")
x
}).foreach(println)
//mapPartition算子
val result: RDD[String] = lines.mapPartitions(x => {
println("创建数据库连接:")
val list: ListBuffer[String] = ListBuffer("")
while (x.hasNext) {
val next: String = x.next()
println("查询数据库数据" + next)
list.append(next)
}
println("关闭数据库连接")
list.iterator
})
result.foreach(println)
sc.stop()
}
}
//map算子
创建数据库连接:
插入数据hello tiantian
关闭数据库连接
hello tiantian
创建数据库连接:
插入数据hello shsxt
关闭数据库连接
hello shsxt
创建数据库连接:
插入数据hello gzsxt
关闭数据库连接
hello gzsxt
创建数据库连接:
插入数据hello Spark
关闭数据库连接
hello Spark
//mapPartition算子
创建数据库连接:
查询数据库数据hello tiantian
查询数据库数据hello shsxt
关闭数据库连接
hello tiantian
hello shsxt
创建数据库连接:
查询数据库数据hello gzsxt
查询数据库数据hello Spark
关闭数据库连接
hello gzsxt
hello Spark
1.12 distinct算子(map+reduceByKey+map)
distinct算子用于去重。其底层逻辑是
/**
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
}
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_distinct {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("filter")
val sc = new SparkContext(conf)
val lines = sc.parallelize(Array(1,2,2,3,4,4))
lines.distinct().foreach(println)
//手动给定分组条件,再利用map去掉不要的东西
lines.map(x=>{(x,1)}).reduceByKey(_+_).map(x=>{x._1}).foreach(println)
sc.stop()
}
}
//distinct算子
4
1
3
2
//map+reduceByKey+map算子
4
1
3
2
1.13 cogroup算子
当调用类型(K,V)和(K,W)的数据上时,返回一个数据集
(K,(Iterable
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Operator_cogroup {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("sortByKey")
val sc = new SparkContext(conf)
val nameRDD: RDD[(String, String)] = sc.parallelize(List(
("1", "zhangsan"),
("2", "lisi"),
("3", "wangwu"),
("4", "maliu")
))
val scoreRDD: RDD[(String, Int)] = sc.parallelize(List(
("1", 100),
("2", 99),
("3", 89),
("4", 60),
("1",1000)
))
val value: RDD[(String, (Iterable[String], Iterable[Int]))] = nameRDD.cogroup(scoreRDD)
value.foreach(println)
sc.stop()
}
}
(4,(CompactBuffer(maliu),CompactBuffer(60)))
(2,(CompactBuffer(lisi),CompactBuffer(99)))
(3,(CompactBuffer(wangwu),CompactBuffer(89)))
(1,(CompactBuffer(zhangsan),CompactBuffer(100, 1000)))
1.14 mapPartitionWithIndex算子
类似于 mapPartitions,除此之外还会携带分区的索引值,能获取到当前处理数据的分区号。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object Operator_mapPartitionsWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("mapPartitionsWithIndex")
val sc = new SparkContext(conf)
val rdd = sc.parallelize(List("a","b","c"),3)
rdd.mapPartitionsWithIndex((index,iter)=>{
val list = ListBuffer[String]()
while(iter.hasNext){
val v = iter.next()
list.append(v)
println("index = "+index+" , value = "+v)
}
list.iterator
}, false).foreach(println)
sc.stop();
}
}
index = 0 , value = a
a
index = 1 , value = b
b
index = 2 , value = c
c
1.15 repartition算子
增加或减少分区都会产生 shuffle。当考虑减少分区时,一般使用coalesce算子,可以避免Shuffle。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object Operator_repartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("repartition")
val sc = new SparkContext(conf)
val rdd1 = sc.makeRDD(List(1,2,3,4,5,6,7),3)
val rdd2 = rdd1.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = new ListBuffer[String]()
while(iter.hasNext){
list += "rdd1partitionIndex : "+partitionIndex+",value :"+iter.next()
}
list.iterator
})
rdd2.foreach{ println }
val rdd3 = rdd2.repartition(4)
val result = rdd3.mapPartitionsWithIndex((partitionIndex,iter)=>{
val list = ListBuffer[String]()
while(iter.hasNext){
list +=("repartitionIndex : "+partitionIndex+",value :"+iter.next())
}
list.iterator
})
result.foreach{ println}
sc.stop()
}
}
rdd1partitionIndex : 0,value :1
rdd1partitionIndex : 0,value :2
rdd1partitionIndex : 1,value :3
rdd1partitionIndex : 1,value :4
rdd1partitionIndex : 2,value :5
rdd1partitionIndex : 2,value :6
rdd1partitionIndex : 2,value :7
repartitionIndex : 0,value :rdd1partitionIndex : 0,value :2
repartitionIndex : 0,value :rdd1partitionIndex : 1,value :4
repartitionIndex : 0,value :rdd1partitionIndex : 2,value :6
repartitionIndex : 1,value :rdd1partitionIndex : 2,value :7
repartitionIndex : 3,value :rdd1partitionIndex : 0,value :1
repartitionIndex : 3,value :rdd1partitionIndex : 1,value :3
repartitionIndex : 3,value :rdd1partitionIndex : 2,value :5
1.16 coalesce算子
coalesce 常用来减少分区,第二个参数是减少分区的过程中是否产生shuffle。true 为产生 shuffle,false 不产生 shuffle。默认是 false。如果 coalesce 设置的分区数比原来的 RDD 的分区数还多的话,第二个参数设置为 false 不会起作用,相当于分区原封不动。如果设置成 true,效果和 repartition 一样。即 repartition(numPartitions) = coalesce(numPartitions,true)。意思就是只有当设置为True时,coalesce 增加分区才会生效,此时与repartition一致。两个算子底层均是coalesce算子。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
object Operator_coalesce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("coalesce")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array(1, 2, 3, 4, 5, 6), 4)
//可变长度的集合 不可变长度的集合
//List
val rdd2 = rdd1.mapPartitionsWithIndex((partitionIndex, iter) => {
val list = new ListBuffer[String]()
while (iter.hasNext) {
list += "rdd1 PartitonIndex : " + partitionIndex + ",value :" + iter.next()
}
list.iterator
})
rdd2.foreach {
println
}
val rdd3 = rdd2.coalesce(5, false)
println("rdd3 Partitions=" + rdd3.getNumPartitions)
val rdd4 = rdd3.mapPartitionsWithIndex((partitionIndex, iter) => {
val list = new ListBuffer[String]()
while (iter.hasNext) {
list += "coalesce PartitionIndex :" + partitionIndex + ",value:" + iter.next()
}
list.iterator
})
rdd4.foreach {
println
}
sc.stop()
}
}
rdd1 PartitonIndex : 0,value :1
rdd1 PartitonIndex : 1,value :2
rdd1 PartitonIndex : 1,value :3
rdd1 PartitonIndex : 2,value :4
rdd1 PartitonIndex : 3,value :5
rdd1 PartitonIndex : 3,value :6
rdd3 Partitions=4
coalesce PartitionIndex :0,value:rdd1 PartitonIndex : 0,value :1
coalesce PartitionIndex :1,value:rdd1 PartitonIndex : 1,value :2
coalesce PartitionIndex :1,value:rdd1 PartitonIndex : 1,value :3
coalesce PartitionIndex :2,value:rdd1 PartitonIndex : 2,value :4
coalesce PartitionIndex :3,value:rdd1 PartitonIndex : 3,value :5
coalesce PartitionIndex :3,value:rdd1 PartitonIndex : 3,value :6
1.17 groupByKey算子
作用在 K,V 格式的 RDD 上。根据 Key 进行分组。作用在(K,V),返 回(K,Iterable )。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_groupByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("groupByKey")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array(
(1,"a"),
(1,"b"),
(2,"c"),
(3,"d")
))
val result = rdd1.groupByKey()
result.foreach(println)
sc.stop()
}
}
(1,CompactBuffer(a, b))
(3,CompactBuffer(d))
(2,CompactBuffer(c))
1.18 zip算子
将两个 RDD 中的元素(KV 格式/非 KV 格式)变成一个 KV 格式的 RDD,
注意:两个 RDD 的个数必须相同。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将两个RDD中的元素(KV格式/非KV格式)变成一个KV格式的RDD,两个RDD的个数必须相同。
*/
object Operator_zip {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("zip").setMaster("local")
val sc = new SparkContext(conf)
val nameRDD = sc.parallelize(Array("zhangsan","lisi","wangwu"))
val scoreRDD = sc.parallelize(Array(1,2,3))
val result = nameRDD.zip(scoreRDD)
result.foreach(println)
sc.stop()
}
}
(zhangsan,1)
(lisi,2)
(wangwu,3)
1.19 zipWithIndex算子
该函数将 RDD 中的元素和这个元素在 RDD 中的索引号(从 0 开始)组合成(K,V)对。
package com.shsxt.scalaTest.core.transform_operator
import org.apache.spark.{SparkConf, SparkContext}
/**
* 该函数将RDD中的元素和这个元素在RDD中的索引号(从0开始)组合成(K,V)对
*/
object Operator_zipWithIndex {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("zipWithIndex")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array((1,"a"),(2,"b"),(3,"c")))
val result = rdd1.zipWithIndex()
result.foreach(println)
sc.stop()
}
}
((1,a),0)
((2,b),1)
((3,c),2)
2.Action行动算子
Action 类 算 子 也 是 一 类 算 子 ( 函 数 ) 叫 做 行 动 算 子 , 如foreach,collect,count 等。Transformations 类算子是延迟执行,Action 类算子是触发执行。一个 application 应用程序中有几个 Action 类算子执行,就有几个 job 运行。
2.1 count算子
count算子:返回数据集中的元素数。会在结果计算完成后回收到 Driver 端。
package com.shsxt.scalaTest.core.action_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_count {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("count")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
val result = lines.count()
println(result)
sc.stop()
}
}
4
2.2 take(n)`算子
take(n)算子:返回一个包含数据集前 n 个元素的集合。
package com.shsxt.scalaTest.core.action_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_take {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
val rdd1 = sc.parallelize(Array(1, 2, 3, 4, 5))
val result = rdd1.take(2)
result.foreach(println)
sc.stop()
}
}
1
2
2.3 first算子
first算子:first=take(1),返回数据集中的第一个元素。
2.4 foreach算子
foreach算子:循环遍历数据集中的每个元素,运行相应的逻辑。
package com.shsxt.scalaTest.core.action_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_foreach {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("collect")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
lines.foreach(println)
}
}
hello tiantian
hello shsxt
hello gzsxt
hello Spark
2.5 collect算子
collect算子:将计算结果回收到 Driver 端。
package com.shsxt.scalaTest.core.action_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_collect {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("collect")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
lines.collect().foreach {
println
}
sc.stop()
}
}
hello tiantian
hello shsxt
hello gzsxt
hello Spark
2.6 foreachPartition算子
foreachPartition算子:遍历的数据是每个 partition 的数据。
package com.shsxt.scalaTest.core.action_operator
import org.apache.spark.{SparkConf, SparkContext}
object Operator_foreachPartition {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("collect")
val sc = new SparkContext(conf)
val lines = sc.textFile("data/word.txt")
lines.foreachPartition(x=>{
System.out.println("连接数据库....")
while(x.hasNext){
println(x.next())
}
System.out.println("关闭数据库....")
})
}
}
连接数据库....
hello tiantian
hello shsxt
hello gzsxt
hello Spark
关闭数据库....
2.7 countByKey算子
作用到 K,V 格式的 RDD 上,根据 Key 计数相同 Key 的数据集元素。
package com.shsxt.scalaTest.core.action_operator
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* countByKey
*
* 作用到K,V格式的RDD上,根据Key计数相同Key的数据集元素。返回一个Map
*/
object Operator_countByKey {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("countByKey")
val sc = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(List(
("a", 100),
("b", 200),
("a", 300),
("c", 400)
))
val result: collection.Map[String, Long] = rdd1.countByKey()
result.foreach(println)
sc.stop()
}
}
(a,2)
(b,1)
(c,1)
2.8 countByValue算子
根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数。
package com.shsxt.scalaTest.core.action_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* countByValue
* 根据数据集每个元素相同的内容来计数。返回相同内容的元素对应的条数。
*/
object Operator_countByValue {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("countByValue")
val sc: SparkContext = new SparkContext(conf)
val rdd1: RDD[(String, Int)] = sc.parallelize(List(
("a", 100),
("a", 100),
("b", 300),
("b", 300),
("c", 400)
))
val rdd2: collection.Map[(String, Int), Long] = rdd1.countByValue()
rdd2.foreach(println)
sc.stop()
}
}
((b,300),2)
((c,400),1)
((a,100),2)
2.9 reduce算子
根据聚合逻辑聚合数据集中的每个元素。
package com.shsxt.scalaTest.core.action_operator
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* reduce
*
* 根据聚合逻辑聚合数据集中的每个元素。
*/
object Operator_reduce {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local").setAppName("reduce")
val sc = new SparkContext(conf)
val rdd1: RDD[Int] = sc.parallelize(Array(1, 2, 3, 4, 5))
val result: Int = rdd1.reduce(_ + _)
println(result)
sc.stop()
}
}
15
3.控制算子(持久化算子)
控制算子有三种:cache,persist,checkpoint,以上算子都可以将RDD 持久化,持久化的单位是 partition。
cache和persist算子都是懒执行的。必须有一个action类算子触发执行。checkpoint算子不仅能将 RDD 持久化到磁盘,还能切断 RDD 之间的依赖关系。
3.1 cache算子
默认将 RDD 的数据持久化到内存中。cache 是懒执行。针对重用RDD,可以将其持久化到内存中。
注意:
cache () = persist()=persist(StorageLevel.Memory_Only)
未加入cache算子之前:
package com.shsxt.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test_Persistent {
def main(args: Array[String]): Unit = {
//新建SparkContext执行环境入口对象
val conf = new SparkConf().setAppName("TransformationOperator").setMaster("local")
val sc = new SparkContext(conf)
//读取数据
var line: RDD[String] = sc.textFile("data/NASA_access_log_Aug95")
//cache算子:将 RDD 的数据持久化到内存中
// line = line.cache()
//统计行数并计算时间
val start: Long = System.currentTimeMillis()
val count: Long = line.count()
val end: Long = System.currentTimeMillis()
println("一共"+count+"条数据,初始化和缓存时间及计算时间总共为="+(end-start))
//统计行数并计算时间
val start2: Long = System.currentTimeMillis()
val count2: Long = line.count()
val end2: Long = System.currentTimeMillis()
println("一共"+count2+"条数据,初始化和缓存时间及计算时间总共为="+(end2-start2))
sc.stop()
}
}
一共1569898条数据,初始化和缓存时间及计算时间总共为=772
一共1569898条数据,初始化和缓存时间及计算时间总共为=478
加入cache算子之后:
package com.shsxt.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test_Persistent {
def main(args: Array[String]): Unit = {
//新建SparkContext执行环境入口对象
val conf = new SparkConf().setAppName("TransformationOperator").setMaster("local")
val sc = new SparkContext(conf)
//读取数据
var line: RDD[String] = sc.textFile("data/NASA_access_log_Aug95")
//cache算子:将 RDD 的数据持久化到内存中
line = line.cache()
//统计行数并计算时间
val start: Long = System.currentTimeMillis()
val count: Long = line.count()
val end: Long = System.currentTimeMillis()
println("一共"+count+"条数据,初始化和缓存时间及计算时间总共为="+(end-start))
//统计行数并计算时间
val start2: Long = System.currentTimeMillis()
val count2: Long = line.count()
val end2: Long = System.currentTimeMillis()
println("一共"+count2+"条数据,初始化和缓存时间及计算时间总共为="+(end2-start2))
sc.stop()
}
}
一共1569898条数据,初始化和缓存时间及计算时间总共为=1470
一共1569898条数据,初始化和缓存时间及计算时间总共为=55
发现:虽然第一次速度变慢,但是第二次速度明显加快!
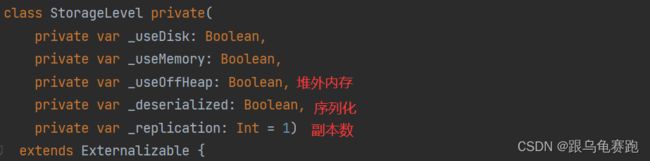
3.2 persist算子
可以指定持久化的级别。最常用的是MEMORY_ ONLY和MEMORY_ AND_ DISK。
持久化级别如下:
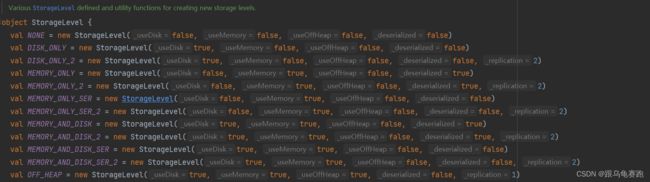
package com.shsxt.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Test_Persistent {
def main(args: Array[String]): Unit = {
//新建SparkContext执行环境入口对象
val conf = new SparkConf().setAppName("TransformationOperator").setMaster("local")
val sc = new SparkContext(conf)
//读取数据
var line: RDD[String] = sc.textFile("data/NASA_access_log_Aug95")
//持久化算子:中间结果的持久化,提升整体的效率
//默认持久化级别是MEMORY_ ONLY,与cache算子一致
line = line.persist()
// line = line.cache()
//统计行数并计算时间
val start: Long = System.currentTimeMillis()
val count: Long = line.count()
val end: Long = System.currentTimeMillis()
println("一共"+count+"条数据,初始化和缓存时间及计算时间总共为="+(end-start))
//统计行数并计算时间
val start2: Long = System.currentTimeMillis()
val count2: Long = line.count()
val end2: Long = System.currentTimeMillis()
println("一共"+count2+"条数据,初始化和缓存时间及计算时间总共为="+(end2-start2))
sc.stop()
}
}
一共1569898条数据,初始化和缓存时间及计算时间总共为=1292
一共1569898条数据,初始化和缓存时间及计算时间总共为=62
3.3 cache 和 persist 的注意事项
- cache 和 persist 都是懒执行,必须有一个 action 类算子触发执行。
- cache 和 persist 算子的返回值可以赋值给一个变量,在其他 job 中直接使用这个变量就是使用持久化的数据了。持久化的单位是 partition。
- cache 和 persist 算子后不能立即紧跟 action 算子。
错误:
rdd.cache().count()返回的不是持久化的 RDD,而是一个数值了。
3.4 checkpoint算子
checkpoint 将 RDD 持久化到磁盘,还可以切断 RDD 之间的依赖关系。
checkpoint 的执行原理:
- 当 RDD 的 job 执行完毕后,会从 finalRDD 从后往前回溯。
- 当回溯到某一个 RDD 调用了 checkpoint 方法,会对当前的RDD 做一个标记。
- Spark 框架会自动启动一个新的 job,重新计算这个 RDD 的数据,将数据持久化到 HDFS 上。
使用checkpoint 时常用优化手段:对 RDD 执行 checkpoint 之前,最好对这个 RDD 先执行cache,这样新启动的 job 只需要将内存中的数据拷贝到 HDFS上就可以,省去了重新计算这一步。
使用:
package com.shsxt.scala
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
object Test_Checkpoint {
def main(args: Array[String]): Unit = {
//新建SparkContext执行环境入口对象
val conf = new SparkConf().setAppName("TransformationOperator").setMaster("local")
val sc = new SparkContext(conf)
//读取数据
sc.setCheckpointDir("./chkpoint")
var line: RDD[String] = sc.textFile("data/NASA_access_log_Aug95")
//RDD保存到内存中是对checkpoint过程的优化,因为它是新的任务(new job)
line = line.persist(StorageLevel.MEMORY_ONLY)
line.checkpoint()
//统计行数并计算时间
val start: Long = System.currentTimeMillis()
val count: Long = line.count()
val end: Long = System.currentTimeMillis()
println("一共" + count + "条数据,初始化和缓存时间及计算时间总共为=" + (end - start))
//统计行数并计算时间
val start2: Long = System.currentTimeMillis()
val count2: Long = line.count()
val end2: Long = System.currentTimeMillis()
println("一共" + count2 + "条数据,初始化和缓存时间及计算时间总共为=" + (end2 - start2))
sc.stop()
}
}
一共1569898条数据,初始化和缓存时间及计算时间总共为=2189
一共1569898条数据,初始化和缓存时间及计算时间总共为=40