Scala | Spark基础入门 | IDEA配置 | 集群搭建与测试
文章目录
-
- 一、学习目标
- 二、本机开发--scala配置
-
- 1. 下载Scala
- 2. 安装scala
- 3. 配置Scala的系统环境变量
- 4. IDEA中的scala配置
- 5.开发第一个项目wordcount
- 三、集群搭建与测试
-
- 1.Standalone 模式两种提交任务方式
-
- 1.1 Standalone-client 提交任务方式
- 1.2 Standalone-cluster 提交任务方式
- 2.Yarn 模式两种提交任务方式
-
- 2.1 yarn-client 提交任务方式
- 2.2 yarn-cluster 提交任务方式
- 3.standalone模式与yarn模式对比
- 四、Spark入门
-
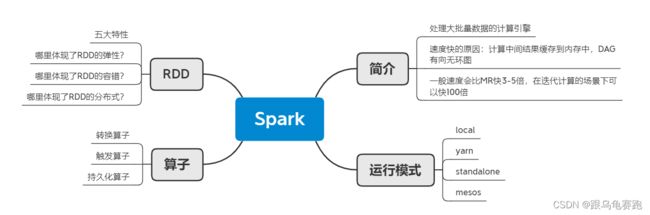
- 1. 什么是Spark?
- 2. 总体技术栈分析
- 3.Spark 与 MapReduce 的区别
- 4.Saprk API
- 5.Spark运行模式
- 6.Spark-Submit 提交参数
-
- 6.1 不同提交模式下
- 7.SparkShell 的使用
- 8.SparkUI
- 9.Master HA
- 课程地址:spark讲解
- Scala | Spark基础入门 | IDEA配置 | 集群搭建与测试
- Scala | Spark核心编程 | SparkCore | 算子
- Scala | 宽窄依赖 | 资源调度与任务调度 | 共享变量 | SparkShuffle | 内存管理
- Scala | SparkSQL | 创建DataSet | 序列化问题 | UDF与UDAF | 开窗函数
一、学习目标
二、本机开发–scala配置
1. 下载Scala
我这里选择的scala2.11.8
2. 安装scala
- 将下载的scala2.11.8的msi的文件剪切到指定文件夹
D:\scala2.11.8 - 双击点击安装,一直点击next,或者同意协议,然后选择自己的安装目录
3. 配置Scala的系统环境变量
进入环境变量设置界面。
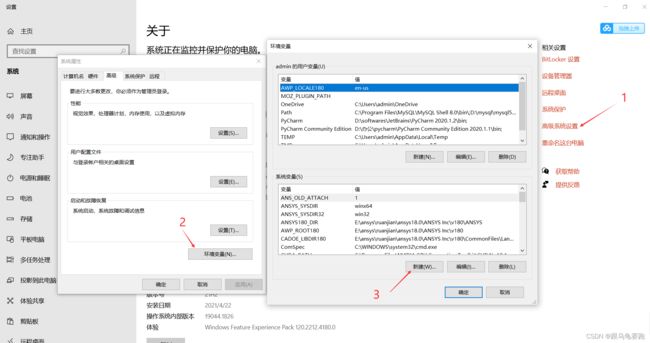
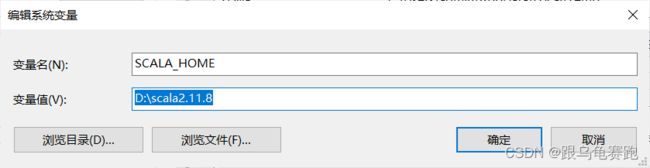
配置SCALA_HOME的地址;
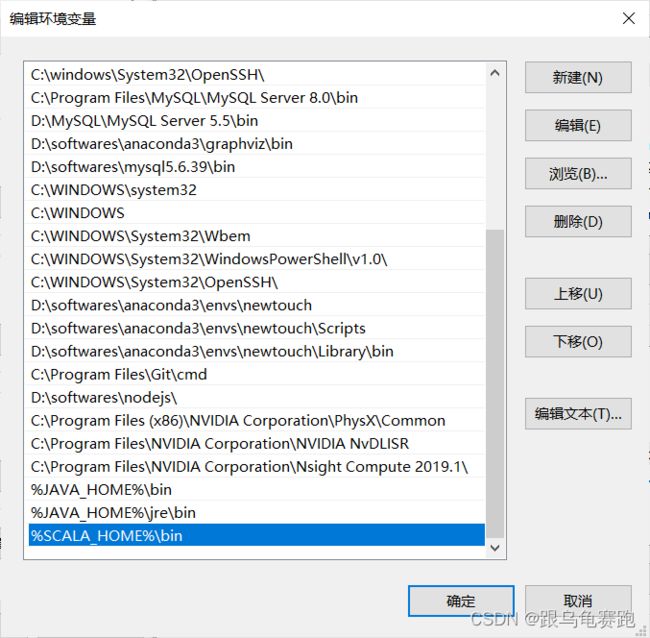
添加到path;
验证是否安装成功;打开命令提示符 输入scala,是否出现对应的版本号;

4. IDEA中的scala配置
新建一个java–spark的java项目

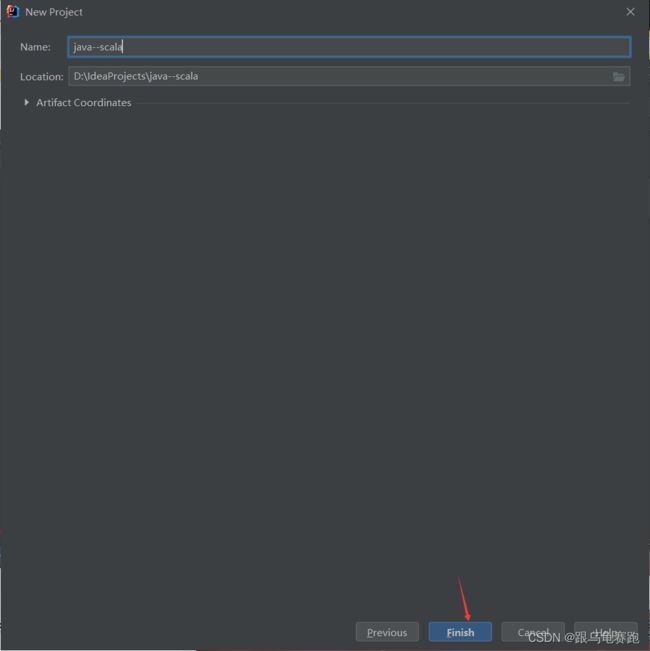
配置下载好的Scala-SDK

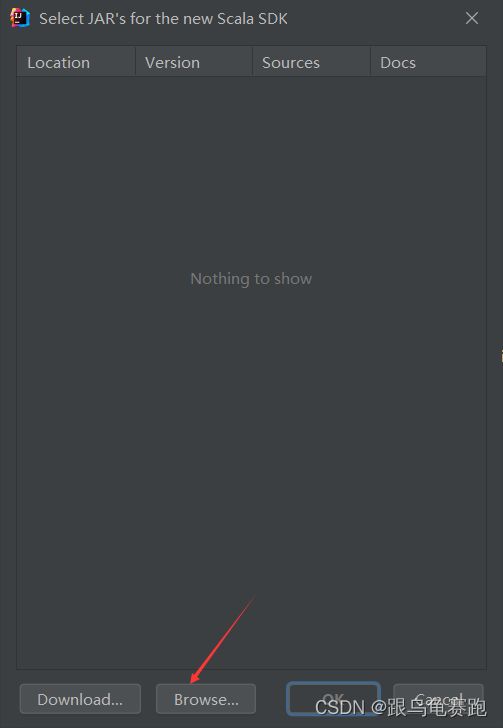
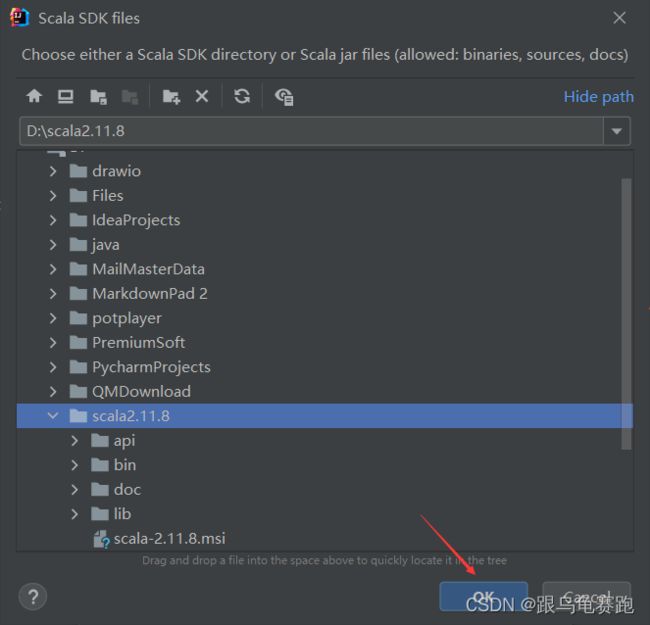

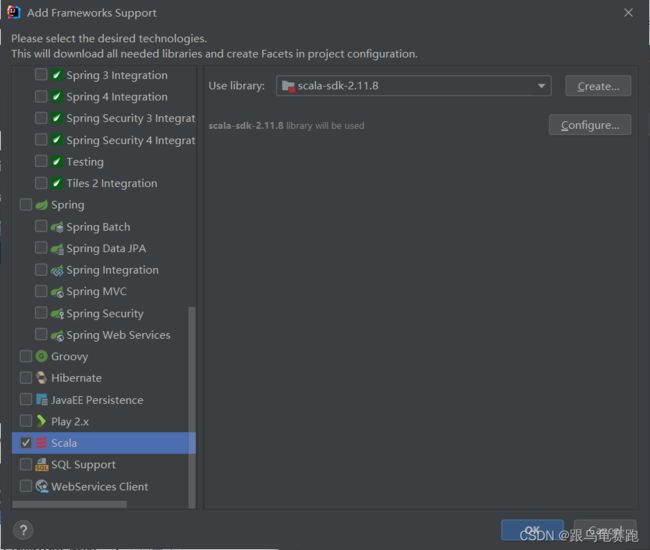
如果找不到Scala,查看IDEA安装完插件Scala后 通过add frameworks support找到不到scala插件
因为不是maven模式,因此,需要拿到spark相应的jar包spark-2.3.1-bin-hadoop2.6/jars
下载地址:https://archive.apache.org/dist/spark/spark-2.3.1/
放置到项目下的lib文件夹中
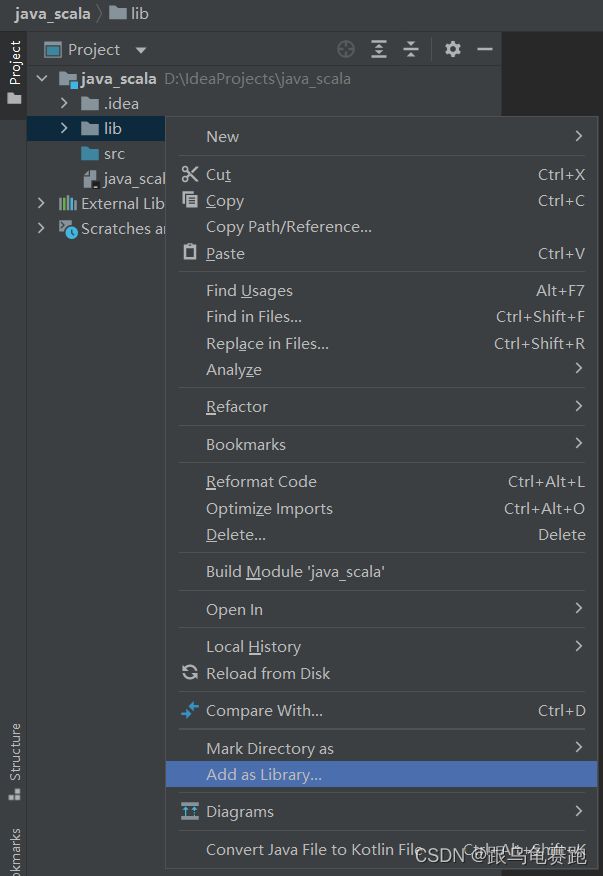
此时,会加载这些jar包
搞定!!!
5.开发第一个项目wordcount
Wordcount.scala:
package com.shsxt.scala
import org.apache.spark.rdd.RDD
import org.apache.spark.{SPARK_BRANCH, SparkConf, SparkContext}
object Wordcount {
//主入口程序
def main(args: Array[String]): Unit = {
//1.创建sparkconf对象,针对此对象,配置改spark应用的配置信息
val conf = new SparkConf()
//setAppName:设置spark应用程序在运行时的任务名称
//setMaster:设置app的运行模式,本地模式设置为local即可
conf.setAppName("wordcount").setMaster("local")
//SparkContext是spark应用程序的所有入口
val sc = new SparkContext(conf)
//2.读取数据源文件
val line: RDD[String] = sc.textFile("data/word.txt")
//将数据分割并且一对多映射关系
val word: RDD[String] = line.flatMap(x => x.split(" "))
//一对一映射关系变成元祖
val word1: RDD[(String, Int)] = word.map(x => (x, 1))
//归约,按照key进行归约,相同key为一组,对应的value值进行累加
val result: RDD[(String, Int)] = word1.reduceByKey((x, y) => x + y)
//将数据进行遍历打印
result.foreach(println)
// //上述代码可以一行代码搞定
// line.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
sc.stop()
}
}
运行结果为:
(shsxt,1)
(tiantian,1)
(hello,4)
(ttttt,1)
(gzsxt,1)
三、集群搭建与测试
之前学习Pyspark的时候,搭建过集群。有疑问的可以参考:Spark环境搭建、Sparkalone环境搭建、StandAlone HA环境搭建、Spark On Yarn环境搭建。下面会对这几种模式做简单介绍与测试。
在集群运行前,需要启动如下常驻进程:
-
先启动hadoop及其历史服务器
(pyspark_env) [root@node1 hadoop]# sbin/start-dfs.sh Starting namenodes on [node1.itcast.cn] Starting datanodes Starting secondary namenodes [node2.itcast.cn] (pyspark_env) [root@node1 hadoop]# sbin/start-yarn.sh Starting resourcemanager Starting nodemanagers [root@node1 hadoop]# sbin/mr-jobhistory-daemon.sh start historyserver WARNING: Use of this script to start the MR JobHistory daemon is deprecated. WARNING: Attempting to execute replacement "mapred --daemon start" instead. (pyspark_env) [root@node1 hadoop]# jps 2960 NodeManager 2771 ResourceManager 2347 DataNode 3388 JobHistoryServer 2127 NameNode 3455 Jps -
再启动Spark及日志服务器
(pyspark_env) [root@node1 spark]# sbin/start-history-server.sh starting org.apache.spark.deploy.history.HistoryServer, logging to /export/server/spark/logs/spark-root-org.apache.spark.deploy.history.HistoryServer-1-node1.itcast.cn.out (pyspark_env) [root@node1 spark]# sbin/start-all.sh starting org.apache.spark.deploy.master.Master, logging to /export/server/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-node1.itcast.cn.out node3.itcast.cn: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node3.itcast.cn.out node2.itcast.cn: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node2.itcast.cn.out node1.itcast.cn: starting org.apache.spark.deploy.worker.Worker, logging to /export/server/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-node1.itcast.cn.out (pyspark_env) [root@node1 spark]# jps 4049 DataNode 7873 Master 3832 NameNode 4664 NodeManager 7976 Worker 7737 HistoryServer 4475 ResourceManager 8028 Jps ## 可以发现spark的Master和Worker进程
1.Standalone 模式两种提交任务方式
1.1 Standalone-client 提交任务方式
-
执行原理图解:
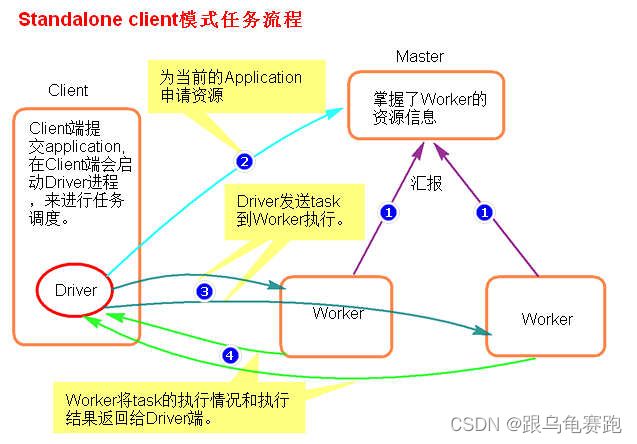
-
执行流程:
- client 模式提交任务后,会在客户端启动 Driver 进程。
- Driver 会向 Master 申请启动 Application 启动的资源。
- 资源申请成功,Driver 端将 task 发送到 worker 端执行。
- Worker 端将 task 执行结果返回到 Driver 端。
-
提交命令:
./spark-submit
–master spark://node1:7077
–class org.apache.spark.examples.SparkPi
…/examples/jars/spark-examples_2.11-2.2.1.jar
1000[root@node1 bin]# ./spark-submit --master spark://node1:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.1.2.jar 1000 22/07/19 19:18:56 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Pi is roughly 3.141678511416785或者
./spark-submit
–master spark://node1:7077
–deploy-mode client
–class org.apache.spark.examples.SparkPi
…/examples/jars/spark-examples_2.11-2.2.1.jar
100[root@node1 bin]# ./spark-submit --master spark://node1:7077 --deploy-mode client --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.1.2.jar 1000 22/07/19 19:20:14 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Pi is roughly 3.141744191417442 -
总结:
client 模式适用于测试调试程序。Driver 进程是在客户端启动的,这里的客户端就是指提交应用程序的当前节点。在 Driver 端可以看到 task 执行的情况。生产环境下不能使用 client 模式,是因为:假设要提交 100 个 application 到集群运行,Driver 每次都会在client 端启动,那么就会导致客户端 100 次网卡流量暴增的问题。
1.2 Standalone-cluster 提交任务方式
-
执行原理图解
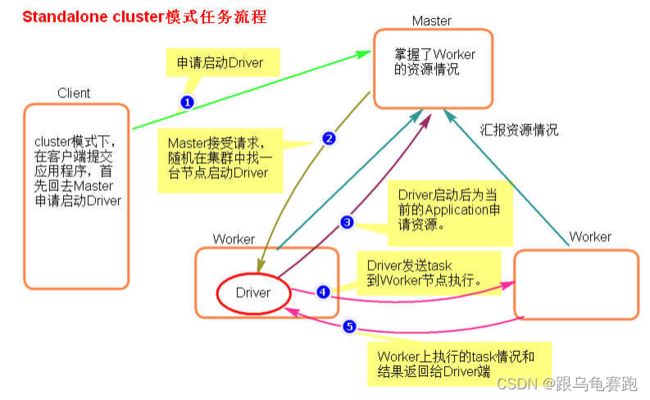
-
执行流程
- cluster 模式提交应用程序后,会向 Master 请求启动 Driver.
- Master 接受请求,随机在集群一台节点启动 Driver 进程。
- Driver 启动后为当前的应用程序申请资源。
- Driver 端发送 task 到 worker 节点上执行。
- worker 将执行情况和执行结果返回给 Driver 端。
-
提交命令
./spark-submit
–master spark://node1:7077
–deploy-mode cluster
–class org.apache.spark.examples.SparkPi
…/examples/jars/spark-examples_2.11-2.2.1.jar
100[root@node1 bin]# ./spark-submit --master spark://node1:7077 --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.1.2.jar 1000 22/07/19 19:26:01 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
注意:Standalone-cluster 提交方式,应用程序使用的所有 jar 包和文件,必须保证所有的 worker 节点都要有,因为此种方式,spark 不会自动上传包。
解决方式:- 将所有的依赖包和文件打到同一个包中,然后放在 hdfs 上。
- 将所有的依赖包和文件各放一份在 worker 节点上。
-
总结
Driver 进程是在集群某一台 Worker 上启动的,在客户端是无法查看 task 的执行情况的。假设要提交 100个 application 到集群运行,每次 Driver 会随机在集群中某一台 Worker 上启动,那么这 100 次网卡流量暴增的问题就散布在集群上。 -
总结 Standalone 两种方式提交任务,Driver 与集群的通信包括:
- Driver 负责应用程序资源的申请
- 任务的分发。
- 结果的回收。
- 监控 task 执行情况。
2.Yarn 模式两种提交任务方式
2.1 yarn-client 提交任务方式
-
执行原理图解

-
执行流程
- 客户端提交一个 Application,在客户端启动一个 Driver 进程。
- 应用程序启动后会向 RM(ResourceManager)发送请求,启动AM(ApplicationMaster)的资源。
- RM 收到请求,随机选择一台 NM(NodeManager)启动 AM。这里的 NM 相当于 Standalone 中的 Worker 节点。
- AM启动后,会向RM请求一批container资源,用于启动Executor.
- RM 会找到一批 NM 返回给 AM,用于启动 Executor。
- AM 会向 NM 发送命令启动 Executor。
- Executor 启动后,会反向注册给 Driver,Driver 发送 task 到Executor,执行情况和结果返回给 Driver 端。
-
提交命令
./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100[root@node1 bin]# ./spark-submit --master yarn --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.1.2.jar 100 22/07/19 23:01:02 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Pi is roughly 3.141336714133671或者
./spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100[root@node1 bin]# ./spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.1.2.jar 100 22/07/19 23:05:56 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Pi is roughly 3.1429639142963914 -
总结
Yarn-client 模式同样是适用于测试,因为 Driver 运行在本地,Driver会与 yarn 集群中的 Executor 进行大量的通信,会造成客户机网卡流量的大量增加。 -
ApplicationMaster 的作用
- 为当前的 Application 申请资源
- 给 NodeManager 发送消息启动 Executor。
注意:ApplicationMaster 有 launchExecutor 和申请资源的功能,并没有作业调度的功能
2.2 yarn-cluster 提交任务方式
-
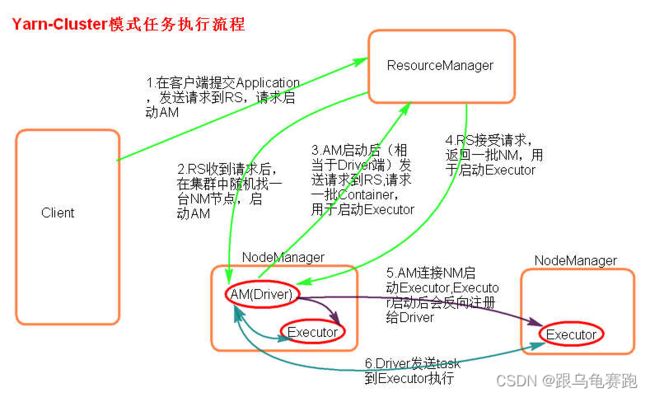
执行原理图解
-
执行流程
- 客户机提交 Application 应用程序,发送请求到RM(ResourceManager),请求启动AM(ApplicationMaster)。
- RM 收到请求后随机在一台 NM(NodeManager)上启动 AM(相当于 Driver 端)。
- AM 启动,AM 发送请求到 RM,请求一批 container 用于启动Excutor。
- RM 返回一批 NM 节点给 AM。
- AM 连接到 NM,发送请求到 NM 启动 Excutor。
- Excutor 反向注册到 AM 所在的节点的 Driver。Driver 发送 task到 Excutor。
-
提交命令
./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 100[root@node1 bin]# ./spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.12-3.1.2.jar 100 22/07/19 23:18:32 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
-
总结
Yarn-Cluster 主要用于生产环境中,因为 Driver 运行在 Yarn 集群中某一台 nodeManager 中,每次提交任务的 Driver 所在的机器都是随机的,不会产生某一台机器网卡流量激增的现象,缺点是任务提交后不能看到日志。只能通过 yarn 查看日志。 -
ApplicationMaster 的作用
- 为当前的 Application 申请资源
- 给NodeManger 发送消息启动 Excutor。
- 任务调度。
3.standalone模式与yarn模式对比
总结:
搭建模式不同: standalone yarn
部署方式的不同:
client cluster体现在driver的位置
driver干什么? 发任务,回收结果,监控过程
executor启动在worker/ nodemanager
client:
driver就在客户端机器:好处能直接看到结果。
坏处:没有分布式的分而治之。容易出现网卡流量激增问题
yarn:
角色不同。RM NM AM
client模式下,driver不是AM
cluster模式下,AM就是driver
四、Spark入门
1. 什么是Spark?
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark 是 UC Berkeley AMP lab (加州大学伯克利分校的 AMP 实验室)所开源的类 Hadoop MapReduce 的通用并行计算框架,Spark 拥有Hadoop MapReduce 所具有的优点;但不同于 MapReduce 的是 Job中间输出结果可以保存在内存中,从而不再需要读写 HDFS,因此 Spark能更好地适用于数据挖掘与机器学习等需要迭代的 MapReduce 的算法。Spark 是 Scala 编写,方便快速编程。
- 特点1:速度快,Spark基于内存和DAG有向无环图进行工作流的处理,保证中间结果不要落盘,避免无谓的IO消耗,加快处理速度
- 特点2:方便使用,易于开发,可以使用Java, Scala, Python, R和 SQL实现交互式处理
- 特点3:一站式开发,融合了SQL, strealming(实时处理),ML(机器学习)和GraphX(图计算)
- 离线:batch批处理
- 实时:strealming流式开发
- SQL:交互式查询
- ML和GraphX:大数据中常用的分析任务
- 特点4:可以到处使用。Spark 运行在 Hadoop、Apache Mesos、Kubernetes,独立使用或在云中。 它可以访问不同的数据源。
更多内容可以查看官网
2. 总体技术栈分析

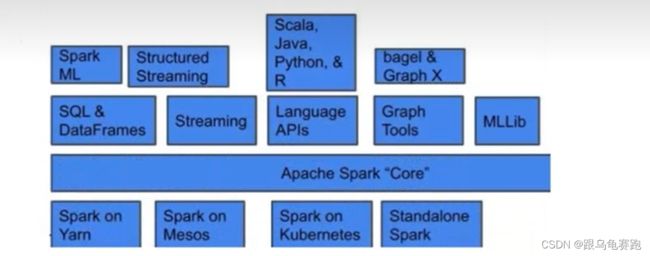
Spark提供了Sparkcore RDD、Spark SQL、 Spark Streaming、 Spark MLlib、 Spark GraphX 等技术
组件,可以一站式地完成大数据领域的离线批处理、交互式查询、流式计算、机器学习、图计算等常见的任务。这就是spark一站式开发的特点。
3.Spark 与 MapReduce 的区别
归根结底最重要的区别还是在于Spark 计算中间结果基于内存缓存,MapReduce 甚于HDFS存储。也正因此,Spark 处理数据的能力一般是MR的三到五倍以上,Spark 中除了基于内存计算这一个计算快的原因, 还有DAG (DAGShecdule)有向无环图来切分任务的执行先后顺序。
4.Saprk API
多种编程语言的支持: Scala,Java,Python,R,SQL 。
5.Spark运行模式
-
Local
多用于本地测试,如在eclipse,idea中写程序测试等。 -
Standalone
Standalone是Spark自带的一个资源调度框架,它支持完全分布式。 -
Yarn
Hadoop 生态圈里面的一个资源调度框架,Spark 也是可以基于 Yarn
来计算的。
-
Mesos
资源调度框架
要基于 Yarn 来进行资源调度,必须实现AppalicationMaster 接口,Spark 实现了这个接口,所以
可以基于 Yarn。
6.Spark-Submit 提交参数
Options:
--master
MASTER_URL,可 以 是 spark://host:port, mesos://host:port,yarn, yarn-cluster,yarn-client, local--deploy-mode
DEPLOY_MODE, Driver 程序运行的地方,client 或者 cluster,默认是client。--class
CLASS_NAME,主类名称,含包名--jars
逗号分隔的本地 JARS,Driver 和 executor 依赖的第三方 jar 包--files
用逗号隔开的文件列表,会放置在每个 executor 工作目录中--conf
spark 的配置属性
https://spark.apache.org/docs/latest/configuration.html#application-properties--driver-memory
Driver 程序使用内存大小(例如:1000M,5G),默认 1024M--executor-memory
每个 executor 内存大小(如:1000M,2G),默认 1G
6.1 不同提交模式下
Spark standalone with cluster deploy mode only:
--driver-cores
Driver 程序的使用 core 个数(默认为 1),仅限于 Spark standalone
模式
Spark standalone or Mesos with cluster deploy mode only:
--supervise
失败后是否重启 Driver,仅限于 standalone或者 Mesos 模式
Spark standalone and Mesos only:
--total-executor-cores
executor 使用的总核数,仅限于 SparkStandalone、Spark on Mesos模式
Spark standalone and YARN only:
--executor-cores
每个 executor 使用的 core 数,Spark on Yarn 默认为 1,standalone默认为 worker 上所有可用的 core。
YARN-only:
--driver-cores
driver 使用的 core,仅在 cluster 模式下,默认为 1。--queue
QUEUE_NAME 指定资源队列的名称,默认:default--num-executors
一共启动的 executor 数量,默认是 2 个。
7.SparkShell 的使用
SparkShell 是 Spark 自带的一个快速原型开发工具,也可以说是Spark 的 scala REPL(Read-Eval-Print-Loop),即交互式 shell。支持使用 scala 语言来进行 Spark 的交互式编程。
- 使用:
- 启动 Standalone 集群,
./start-all.sh - 在客户端上启动 spark-shell:
./spark-shell --master spark://node1:7077 - 启动 hdfs,创建目录 spark/test,上传文件 wc.txt
- 运行程序
- 启动 Standalone 集群,
8.SparkUI
-
SparkUI 界面介绍
可以指定提交 Application 的名称./spark-shell --master spark://node1:7077 --name myapp -
配置 historyServer
-
临时配置,对本次提交的应用程序起作用
./spark-shell --master spark://node1:7077 --name myapp1 --conf spark.eventLog.enabled=true --conf spark.eventLog.dir=hdfs://node1:8020/spark/test停 止程 序, 在 Web Ui 中 Completed Applications 对 应的
ApplicationID 中能查看 history。 -
spark-default.conf 配置文件中配置 HistoryServer,对所有提交的
Application 都起作用
在客户端节点,进入../spark-2.2.1/conf/ spark-defaults.conf最后
加入://开启记录事件日志的功能 spark.eventLog.enabled true //设置事件日志存储的目录 spark.eventLog.dir hdfs://node1:8020/spark/test //日志优化选项,压缩日志 spark.eventLog.compress true spark.history.fs.logDirectory hdfs://node1:8020/spark/test启动 HistoryServer:
./start-history-server.sh访问 HistoryServer:node1:18080,之后所有提交的应用程序运行
状况都会被记录。
-
9.Master HA
-
Master 的高可用原理
Standalone 集群只有一个 Master,如果 Master 挂了就无法提交应用程序,需要给 Master 进行高可用配置,Master 的高可用可以使用fileSystem(文件系统)和zookeeper(分布式协调服务)。
fileSystem 只 有 存 储 功 能 , 可 以 存 储 Master 的 元 数 据 信 息 , 用fileSystem 搭建的 Master 高可用,在 Master 失败时,需要我们手动启动另外的备用 Master,这种方式不推荐使用。
zookeeper 有选举和存储功能,可以存储 Master 的元素据信息,使用zookeeper 搭建的 Master 高可用,当 Master 挂掉时,备用的 Master会自动切换,推荐使用这种方式搭建 Master 的 HA。

-
Master 高可用搭建
-
在 Spark Master 节点上配置主 Master,配置 spark-env.sh
export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node3:2181,node4:2181,node5:2181 -Dspark.deploy.zookeeper.dir=/sparkmaster0821"
-
发送到其他 worker 节点上


-
找一台节点(非主 Master 节点),比如 node2
配置备用 Master,修改 spark-env.sh 配置节点上的 MasterIP,

-
启动集群之前启动 zookeeper 集群:
-
在 node1 上启动 spark Standalone 集群 ./start-all.sh
在 node2 上启动备用 Master ./ start-master.sh -
打开主 Master 和备用 Master WebUI 页面,观察状态

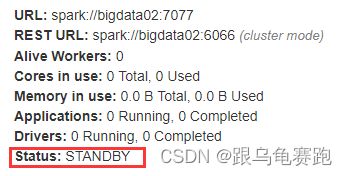
-
-
注意点
- 主备切换过程中不能提交 Application。
- 主备切换过程中不影响已经在集群中运行的 Application。因为
Spark 是粗粒度资源调度。
-
测试验证
提交 SparkPi 程序,kill 主 Master 观察现象。./spark-submit --master spark://node1:7077,node2:7077 --class org.apache.spark.examples.SparkPi ../examples/jars/spark-examples_2.11-2.2.1.jar 10000