Linux编译器 gcc/g++ 的编译过程
以Visual Studio 2019为例,我们只需要点击下面这个键,VS就会自动帮我们编译然后运行项目

但是一般的Linux系统没有图形化界面,只有命令行,如果我们想要运行项目的话那应该怎么做呢?
所以Linux给我们提供了对应的编译工具gcc/g++,gcc是C语言对应的编译器,g++是C++对应的编译器
那么一个可执行文件的形成要经过哪些步骤??
目录
一、预处理
1、预处理的作用
2、 预处理指令
二、编译(生成汇编代码)
1、编译的作用
2、 编译指令
三、汇编(生成机器可识别代码)
1、汇编的作用
2、为什么不直接将c语言代码转化为二进制文件
3、 汇编指令
四、连接(生成可执行文件或库文件)
1、连接的作用
2、连接指令
五、gcc选项记忆
一、预处理
1、预处理的作用
预处理的主要功能是头文件包含、宏替换、条件编译、去除注释等,生成一个比较干净的C原始程序
头文件展开:包含第三方库文件的路径,将自定义的头文件在目标文件展开
宏替换:将定义的宏 替换为对应的值
条件编译:遇到 #ifdefine 就进行条件判断,然后仅留下相应的结果,生成的文件中就不会包含
#ifdefine等语句
去除注释:既然要生成一个干净的C程序,注释是必然不需要的
2、 预处理指令
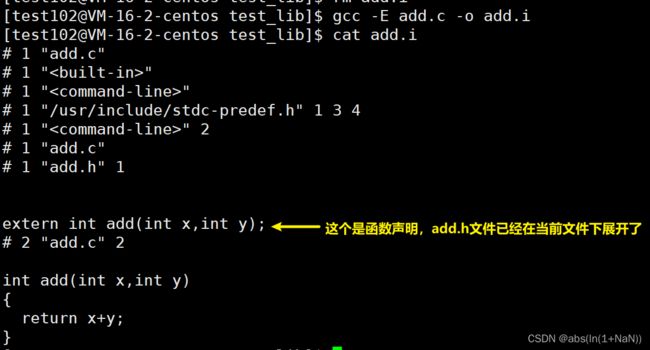
基本指令:gcc -E 依赖的.c文件 -o 输出的.i文件
#使用gcc编译器,编译的文件是add.c,执行到预处理就停止编译,生成的目标文件是add.i文件
gcc -E add.c -o add.i-E:执行完预处理就停止编译过程
-o:目标文件,预处理生成的是 .i文件
二、编译(生成汇编代码)
1、编译的作用
检查代码的规范性、是否有语法错误等,检查无误后,把代码翻译成汇编代码
2、 编译指令
基本指令:gcc -S 依赖的.c文件 -o 生成的.s文件
gcc -S 依赖的.i文件 -o 生成的.s文件
方式一:依赖.c文件。从头开始,经过预处理、编译,最后生成.s文件
gcc -S add.c -o add.s
方式二:依赖.i文件。使用上一次生成的文件,无需经过预处理,直接对上一次的文件进行编译
gcc -S add.i -o add.s-S:执行完编译就停止
-o:生成的目标文件是 .s 文件

三、汇编(生成机器可识别代码)
1、汇编的作用
计算机无法识别汇编语言,需要生成计算机可识别代码(也就是二进制文件)
2、为什么不直接将c语言代码转化为二进制文件
早期写代码都是用的汇编语言,后来有了C语言,就有了现在的流程,C语言 ——》汇编语言 ——》二进制文件,分别对应着我们目前的三个阶段预处理 ——》 编译 ——》 汇编
现在如果要将c语言直接转化为 二进制文件,就相当于要放弃现有的编译器,成本太高
3、 汇编指令
基本指令:gcc -c 依赖的.c文件 -o 生成的.o文件
gcc -c 依赖的.s文件 -o 生成的.o文件
(注意这里的-c 是小写的!!)
方式一:依赖.c文件。从头开始,经过预处理、编译、汇编,最后生成.o文件
gcc -c add.c -o add.o
方式二:依赖.s文件。使用上一次生成的文件,无需经过预处理、编译,直接对上一次的文件进行汇编操作
gcc -c add.s -o add.o-c:执行完汇编就停下来
-o:生成的目标文件是 .o文件
四、连接(生成可执行文件或库文件)
1、连接的作用
将生成的 .o文件转化为 可执行文件(Windows下的.exe文件)
这里是计算机开始解读代码的时候,若要用到xx第三方函数,就会根据路径连接到对应的库,至于是动态连接还是静态,不是本次讨论的话题
2、连接指令
基本指令:gcc 依赖的.o文件 -o 生成的可执行文件
gcc -o 生成的可执行文件 依赖的.c文件列表
方式一:从头开始,一直运行到最后生成可执行文件
gcc -o add add.c
方式二:在上一次add.o的基础上运行
gcc add.o -o add这里就一直运行到结束了,无需停下来了
-o:生成的目标文件是可执行文件
五、gcc选项记忆
