TYD2019python机器学习实战笔记,初识 numpy 和 pandas
目录
目录
第一章:入学指南及其杂项
.ipynb 文件如何打开
python库安装工具
第二章:python科学计算库numpy
第三章:python数据分析处理库—Pandas
第一章:入学指南及其杂项
在校生更偏重底层算法推导,而不仅仅是会用。
自己做笔记很重要,要用自己的话说,用自己的话写,用别人的容易忘。
最好的资源站点 GitHub,kaggle(找数据的,竞赛网站)。
案例积累很重要,因为实际接手项目时,都不是从头开始做的,都是在之前做过的案例或者学过的案例中找相似的地方套进去。
.ipynb 文件如何打开
在安装好Anaconda之后,
1、打开开始菜单找到Anaconda3(64-bit)。
2、点击Anaconda Prompt(类似windows的命令行工具)。
3、找到你存放ipynb文件,小编这里是D盘。输入 d:
4、进入存放ipynb文件的目录。输入 cd 目录名
5、查看ipynb目录。输入dir (list命令也可以)
6、输入命令 jupyter lab 将在该目标下启动Jupyterlab。
.ipynb 文件如何打开(二)
一、找到安装jupyter Notebook的本地文件夹

二、右键--属性--目标--复制目标中的内容至文档

三、将目标内容最后的%USERPROFILE%改为%1--保存为.bat文件

四、将.ipynb文件的打开方式改为上面保存的.bat文件
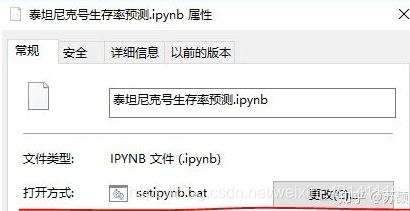
五、双击即可在Jupyter Notebook中打开本文档
python库安装工具
- 打开jupyter prompt 输入conda list 查看已安装的库
- pip install +包名
- 如果2不成功,进入Window_python包安装页面
- ctrl+F找到要安装的包,点击进入下载
- 弹出页面中选中下载位置,下载到canda的环境中。(或者下到任何位置,因为pip已经配好了环境变量)
- 如果2步骤不成功并显示socket.timeout: The read operation timed out错误,一般是由于网速不稳定,下载过慢,超出默认时间,所以只要修改一下响应时间就好了。
- windows下输入 pip --default-timeout=100 install 包名
linux下输入 pip --default-timeout=100 install -U 包名 - 如果步骤7还是不顶用,可以包源镜像:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 库名。例如:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple superset
第二章:python科学计算库numpy
结构化数据(表格)在算法中运算都是以矩阵的形式。Numpy是做底层运算的,pandas是建立的Numpy基础之上的。
import Numpy as np
array = [1,2,3,4,5]
array + 1 #将会报错,不能加。
array = np.array([1,2,3,4,5])
print (type(array)) #
array2 = array + 1
array2 # array([2, 3, 4, 5, 6])
array2 * array #array([ 3, 5, 7, 9, 11])
tang_list = [1,2,3,4,5]
tang_list.shape #报错,没有用到工具包
np.array([[1,2,3],[4,5,6]]) #array([[1, 2, 3], [4, 5, 6]])
array.shape #(2,3)两行,三列。
对于nparray结构来说,里面所有的元素必须是同一类型的 如果不是的话,会自动的向下进行转换
import Numpy as np
tang_list = [1,2,3,4,5.1]
tang_array = np.array(tang_list)
tang_array #array([1. , 2. , 3. , 4. , 5.1])nparray基本属性操作
import Numpy as np
type(tang_array) #numpy.ndarray
tang_array.dtype #dtype('int32')
tang_array.itemsize #4
tang_array.ndim #数据的维度 1
tang_array.fill(0)
tang_array #array([0, 0, 0, 0, 0])索引与切片:跟Python都是一样的 还是从0开始的
import Numpy as np
tang_array = np.array([[1,2,3],
[4,5,6],
[7,8,9]])
tang_array.shape #(3, 3)
tang_array.ndim #2
tang_array[1,1] #5
tang_array[:,1] # 取所有样本第二列
tang_array2 = tang_array #索引共享
tang_array2 = tang_array.copy() #拷贝一份Boolean类型索引
import Numpy as np
tang_array = np.arange(0,100,10) #array([ 0, 10, 20, 30, 40, 50, 60, 70, 80, 90])
mask = np.array([0,0,0,1,1,1,0,0,1,1],dtype=bool) #array([False, False, False, True, True, True, False, False, True, True], dtype=bool)
tang_array[mask] #array([30, 40, 50, 80, 90])
random_array = np.random.rand(10) #array([ 0.51388374, 0.57986996, 0.05474169,0.5019837 , 0.82705166, 0.95557716, 0.83348612, 0.32385451, 0.52586287, 0.92505535])
mask = random_array > 0.5 #array([ True, True, False, True, True, True, True, False, True, True], dtype=bool)
np.where(tang_array > 30) #返回的是索引数组 (array([3, 4,5,6,7,8,9], dtype=int64),)type
import Numpy as np
tang_array.astype(np.float32) #array([ 1., 2., 3., 4., 5.], dtype=float32)数值计算
import Numpy as np
tang_array = np.array([[1,2,3],[4,5,6]])
np.sum(tang_array) #左上角加到右下角
np.sum(tang_array,axis=0) #指定要进行的操作是沿着什么轴(维度)array([5, 7, 9])
tang_array.prod() #左上角乘到右下角
tang_array.prod(axis = 0) #array([ 4, 10, 18])
tang_array.argmin() #找最小值索引
tang_array.std() #求标准差
tang_array.var() #求方差
tang_array.clip(2,4) #截断操作 array([[2, 2, 3], [4, 4, 4]])
tang_array.round() #精确到小数点后一位的四舍五入
排序
import numpy as np
tang_array = np.array([[1.5,1.3,7.5],
[5.6,7.8,1.2]])
np.sort(tang_array,axis = 0)
np.argsort(tang_array) #array([[1, 0, 2],[2, 0, 1]], dtype=int64)
tang_array = np.linspace(0,10,10) #从0开始到10结束,10个数。
values = np.array([2.5,6.5,9.5])
np.searchsorted(tang_array,values) #一个数组插入另外一个,返回索引数组。array([3, 6, 9], dtype=int64)
index = np.lexsort([-1*tang_array[:,0],tang_array[:,2]]) #在第一列降序的基础上,第二列升序数组形状
import numpy as np
tang_array = np.arange(10) #array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
tang_array.shape = 2,5 #array([[0, 1, 2, 3, 4],[5, 6, 7, 8, 9]])
tang_array.reshape(1,10) #array([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]) 分清一二维的表示区别
tang_array = tang_array[np.newaxis,:] #加新轴 一个样本十个特征
tang_array = tang_array[:,np.newaxis]
tang_array = tang_array[:,np.newaxis,np.newaxis] #(10, 1, 1, 1)
tang_array = tang_array.squeeze() #(10,) 压缩没有数据的维度
tang_array.T #矩阵转置
a = np.array([[123,456,678],[3214,456,134]])
b = np.array([[1235,3124,432],[43,13,134]])
c = np.concatenate((a,b),axis = 0) #横着拼接,往下加
a.flatten() #array([ 123, 456, 678, 3214, 456, 134])拉长操作矩阵的生成
import Numpy as np
np.zeros((3,3)) #array([[ 0., 0., 0.],[ 0., 0., 0.],[ 0., 0., 0.]])
np.ones((3,3)) * 8 #array([[ 8., 8., 8.],[ 8., 8., 8.],[ 8., 8., 8.]])
a = np.empty(6) #全零
a.fill(1) #array([ 1., 1., 1., 1., 1., 1.])
np.zeros_like(tang_array)
np.ones_like(tang_array) #按照之前的维度构造新的矩阵。矩阵运算
import Numpy as np
x = np.array([5,5])
y = np.array([2,2])
np.multiply(x,y) #array([10, 10])
np.dot(x,y) #矩阵乘法,一维时候做内积(对应位置相乘相加)随机模块
import Numpy as np
np.random.rand(3,2) #array([[ 0.87876027, 0.98090867],[ 0.07482644, 0.08780685],[ 0.6974858 , 0.35695858]])
#返回的是随机的整数,左闭右开
np.random.randint(10,size = (5,4))
np.random.randint(0,10,3) #array([7, 7, 5]) 从0开始 到10结束。取三个。
mu, sigma = 0,0.1
np.random.normal(mu,sigma,10) # 指定参数构造高斯分布
np.set_printoptions(precision = 2) #设置精度
#洗牌
tang_array = np.arange(10)
np.random.shuffle(tang_array) #array([6, 2, 5, 7, 4, 3, 1, 0, 8, 9])
#随机种子
np.random.seed(100) #指定随机种子之后每次随机完结果都是一样的。
#seed( ) 用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed( )值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。读写文件
import numpy as np
%%writefile zhang.txt #magi命令按惯例要写在第一行
1 2 3 4
5 6 7 8
data2 = np.loadtxt('zhang2.txt',delimiter=',',skiprows=1)
print(data2) #[6. 7. 8. 9. 0.] delimiter分隔符 skiprows忽略一行
zhang3 = np.array([[1,2,3],[4,5,6]])
np.savetxt('zhang3.txt',zhang3,fmt='%d',delimiter=',') #保存矩阵到文件,
#读写array结构,之前都是txt和CSV的文件
zhang_array = np.array([[1,2,3],[4,5,6]])
np.save('zhang4.npy',zhang_array) #注意这里的文件后缀npy
第三章:python数据分析处理库—Pandas
import pandas as pd
df = pd.read_csv('I:/ITLearningMaterials/TYD/Python_dataAnalyseAndMachineLearning/Chapter3_Pandas_Utils/Pandas_code/titanic_train.csv')
df.head() #注意斜杠的方向,最好用英文创建文件名。
df.info() #显示列表信息
df.values #重要,将表格以array形式展现。创建一个dataFrame结构
import pandas as pd
data = {'coutry':['aaa','bbb','ccc'],'population':[243,432,785]}
df_data = pd.DataFrame(data) 取指定数据
import pandas as pd
age = df['Age']自定义索引
import pandas as pd
df = df.set_index('Name')describe()可以得到数据的基本统计特性 like this

df.describe()Pandas 索引,用loc(标签)和iloc(位置)定位
import pandas as pd
# boolean 做索引
df['Fare']>40 #展示所有数据的Boolean值
df[df['Fare']>50][:] #展示所有为true的数据条
df[df['Sex'] == 'male'][:] #展示所有男性
df.loc[df['Sex'] == 'male','Age'].mean() #计算所有男性的平均年龄groupBy函数
import pandas as pd
import numpy as np
# 求解所有A组中的总和,
df = pd.DataFrame({'key':['A','B','C','A','B','C','A','B','C'],'data':[12,32,2,4,32,213,4,23,54]})
for key in ['A','B','C']: #常规方法
print(key,df[df['key'] == key].sum())
df.groupby('key').sum() # 使用groupby函数 更便捷
df.groupby('key').aggregate(np.mean) #按组别计算均值
df.groupby('Sex')['Age'].mean() #统计不同性别的年龄均值
数值计算——二元统计
import pandas as pd
df.cov() #协方差
df.corr() #相关系数
df['Age'].value_counts() #对年龄相同值计数
df['Age'].value_counts(ascending=True,bins=5) #升序排列,分成五组Series 结构的增删改查
import pandas as pd
# 构造series
data = [12,43,23]
index = ['a','b','c']
s = pd.Series(index = index,data = data)
#查
s.loc['a']
s.iloc[2]
#改
s1 = s.copy()
s1[2] = 100
#增
s1['j'] = 100
#删
del s1['j']merge操作
import pandas as pd
left = pd.DataFrame({'Key1':['K0','K1','K2','K3'],
'Key2':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right = pd.DataFrame({'Key1':['K0','K1','K2','K3'],
'Key2':['K0','K1','K2','K4'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
res = pd.merge(left,right,on = ['Key1','Key2'],how = 'outer',indicator = True) #不写how属性默认内连接,indicator是最后一行 both left_only
显示设置
import pandas as pd
zhang = pd.read_csv('I:/ITLearningMaterials/TYD/Python_dataAnalyseAndMachineLearning/Chapter3_Pandas_Utils/Pandas_code/titanic_train.csv')
pd.set_option('display.max_rows',1000) #展示1000条数据,其他省略号。
pd.set_option('display.max_columns',3) #同理pivot 函数
import pandas as pd
example = pd.DataFrame({'Month': ["January", "January", "January", "January",
"February", "February", "February", "February",
"March", "March", "March", "March"],
'Category': ["Transportation", "Grocery", "Household", "Entertainment",
"Transportation", "Grocery", "Household", "Entertainment",
"Transportation", "Grocery", "Household", "Entertainment"],
'Amount': [74., 235., 175., 100., 115., 240., 225., 125., 90., 260., 200., 120.]})
example_pivot = example.pivot(index = 'Category',columns= 'Month',values = 'Amount') #属性分别代表横标,纵标,数值。
df = pd.read_csv('./data/titanic.csv') #默认就是求平均
df.pivot_table(index = 'Sex',columns='Pclass',values='Fare',aggfunc='count') #不默认的情况
df.pivot_table(index = 'Sex',columns='Pclass',values='Fare') #统计不同性别在不同船舱的平均价格
df['Underaged'] = df['Age'] <= 18
df.pivot_table(index = 'Underaged',columns='Sex',values='Survived',aggfunc='mean') #结果见下图
时间操作
import pandas as pd
import datetime
dt = datetime.datetime(year=2020,month=2,day=7,hour=15,minute=3) #注意data和date
dt = pd.Timestamp('2020-2-7') #Timestamp('2017-11-24 00:00:00')
ts.month
ts.day #
td = pd.Timedelta('5 days') #Timedelta('5 days 00:00:00')
ts + pd.Timedelta('5 days')
s = pd.Series(pd.date_range(start='2020-2-7',periods=10,freq='12H')) #时间序列,开始时间,十条数据,间隔12小时
df = pd.read_csv('I:/ITLearningMaterials/TYD/Python_dataAnalyseAndMachineLearning/Chapter3_Pandas_Utils/Pandas_code/data/flowdata.csv')
df['Time'] = pd.to_datetime(df['Time']) #将时间列格式标准化
df = df.set_index('Time') #将时间列设置为索引列
df = pd.read_csv('I:/ITLearningMaterials/TYD/Python_dataAnalyseAndMachineLearning/Chapter3_Pandas_Utils/Pandas_code/data/flowdata.csv',index_col=0,parse_dates=True) #读取的同时将时间列设置为索引列
data[data.index.month == 1] #取所有一月份的数据
data.resample('D').mean().head() #按天进行重采样,每天取均值,同理可以对三天重采样,按月等等常用操作
import pandas as pd
data = pd.DataFrame({'group':['a','a','a','b','b','b','c','c','c'],
'data':[4,3,2,1,12,3,4,5,7]})
data.sort_values(by=['group','data'],ascending=[False,True],inplace=True) #在group降序的基础上data升序
data.drop_duplicates() #去掉所有列都相同的项,
data.drop_duplicates(subset='k1') #去掉某一列相同的项
apply函数
import pandas as pd
data = pd.DataFrame({'food':['A1','A2','B1','B2','B3','C1','C2'],'data':[1,2,3,4,5,6,7]})
def food_map(series):
if series['food'] == 'A1':
return 'A'
elif series['food'] == 'A2':
return 'A'
elif series['food'] == 'B1':
return 'B'
elif series['food'] == 'B2':
return 'B'
elif series['food'] == 'B3':
return 'B'
elif series['food'] == 'C1':
return 'C'
elif series['food'] == 'C2':
return 'C'
data['food_map'] = data.apply(food_map,axis = 'columns') #对其中的每一个样本使用一次food_map函数
data = pd.read_csv('I:/ITLearningMaterials/TYD/Python_dataAnalyseAndMachineLearning/Chapter3_Pandas_Utils/Pandas_code/titanic_train.csv')
def not_null_count(columns):
columns_null = pd.isnull(columns) #对每列操作,如果为null则true否则为false
null = columns[columns_null] #对一个Boolean列操作
return len(null)
pd.set_option('display.max_rows',1000)
columns_null_count = data.apply(not_null_count)常用操作
import pandas as pd
import numpy as np
ages = [15,18,20,21,22,34,41,52,63,79]
bins = [10,40,80]
bins_res = pd.cut(ages,bins) #bins 如果传入数值就按数值均分,如果是数组就按数组间隔均分
#[(10, 40], (10, 40], (10, 40], (10, 40], (10, 40], (10,40], (40, 80], (40, 80], (40, 80], (40, 80]]Categories (2, interval[int64]): [(10, 40] < (40, 80]]
pd.value_counts(bins_res) #对每个区间计数
group_names = ['Yonth','Mille','Old']
pd.value_counts(pd.cut(ages,[10,20,50,80],labels=group_names)) #对每组贴标签然后计数
df = pd.DataFrame({'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df['data'] = df['data1']/df['data2'] #添加新的一行,为前两行的比值
df2.drop('ration',axis='columns',inplace=True) #删除列, inplace 参数在很多函数中都会有,它的作用是:是否在原对象基础上进行修改,inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果。
df.isnull() #改变成Boolean的表,nan显示为true
df.isnull().any(axis = 1) #axis=0指的是逐行,axis=1指的是逐列。 每一列中只要有一个是true则为true否则为false
df[df.isnull().any(axis = 1)] #能显示含有nan的具体行
df.fillna(5) #将nan填充为5
字符串操作
import pandas as pd
s1 = pd.DataFrame(np.random.randn(3,2),index=range(3),columns=['A a','B b'])
s1.columns = s1.columns.str.replace(' ','_') #改变列条目名字的形式
s3 = pd.Series(['a_b_C','c_d_e','f_g_h'])
s3.str.split('_') #分了之后还在同一行,用列表的形式表示
s3.str.split('_',expand=True) #分成不同的行