Python 学习基础pandas刷题(四)

# 1.查看最后五行数据
import pandas as pd
import numpy as np
data={"course":["A","B","C","D","E",np.nan,"F","G"],"grade":[22,34,45,45,67,np.nan,53,23]}
df=pd.DataFrame(data)
df
上面便是查看最后五行的数据,即df.tail(5),或者df.tail();当查看前面第几行时使用,访问前五行df.head()或者df.head(),“()”括号内数字为几,则访问前几行。
扩展一下:当访问第几行时,则使用
df.loc[1:1]这样可以访问到第一行, 如果df.loc[1:4] 这样可以访问到第一到第四行,然后df.loc[1:1]['course']可以访问到第一行并且只含‘grade’列数据。
# 2.删除最后一行数据
df.drop(len(df)-1,inplace=True)
df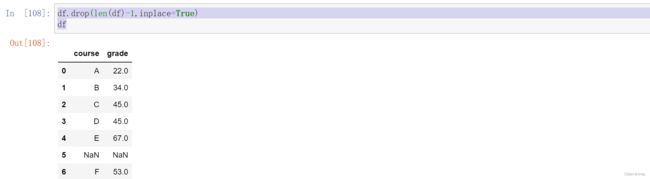
同样可以删除任意行数据,将len(df)-1,可以替换成0,1,3到len(df)-1。
删除某一列元素
df.drop(columns=["len__str"],inplace=True)"len__str"为删除的列。
# 3.添加一行数据['ABC',6.6]
row={'course':'ABC','grade':6.6}
df=df.append(row,ignore_index=True)
df扩张到添加两行或者几行;
##这是将要添加的序列
data1={"course":["H","I","J","O","K"],"grade":[22,34,45,45,63]}
df1=pd.DataFrame(data1)
df=df.append(df1,ignore_index=True)##将df1添加到df中
# 4.对数据按照“grade”列值的大小进行排序
row={'course':'ABC','grade':6.6}
df=df.append(row,ignore_index=True)
df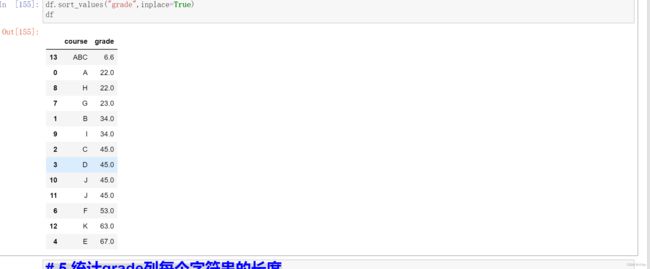
# 5.统计grade列每个字符串的长度
df["len_str"]=df["course"].map(lambda x:len(x))
df