机器学习时代,神经科学家如何阅读和解码人类的思想
机器之心分析师网络
作者:Jiying
编辑:Joni
这篇文章围绕机器学习(ML)和功能性磁共振成像(fMRI)的应用问题,以三篇最新的研究型论文为基础,探讨基于统计学中 ML 的 fMRI 分析方法。
本文主要讨论的是机器学习(ML)和功能性磁共振成像(fMRI)的应用问题。fMRI 主要用来检测人在进行各种脑神经活动时(包括运动、语言、记忆、认知、情感、听觉、视觉和触觉等)脑部皮层的磁力共振讯号变化,配合在人脑皮层中枢功能区定位,就可研究人脑思维进行的轨迹,揭示人脑奥秘。其基本原理是利用 MRI 来测量神经元活动所引发之血液动力的改变。所以,利用 ML 连接 fMRI 图像,以了解人脑正在观察和思考的物件是理论上可行的。以本文讨论的问题为例,神经科学家现在可以通过像数据科学家一样运行计算模型来预测并准确地将神经功能与认知行为联系起来。不过,这些技术与人工智能模型有着相同的偏见(biases)和局限性(limitations),需要严格的科学方法加以应用[1]。
虽然神经科学家在 20 世纪初就注意到了大脑血流有明显的变化,但是却一直没有找到合适的方法来测量这些变化。20 世纪 80 年代出现了一种有效的方法:正电子发射体层摄影(术) (position emissiom tomography,PET)。有了这种技术,研究人员能够通过放射性追踪和检测光子(phonto)发射来观察神经元活动的变化。由于这些光子在神经元消耗最多葡萄糖的地方降解得最多,因此它们可以显示出神经元的活动。然而,早期使用这种方法时面临着一个问题:每个人的大脑都有不同的尺寸和结构,差异和变化非常大。此外,PET 扫描的空间和时间图像分辨率非常低。它们检测的区域至少有一毫米宽,需要 10 秒钟才能收集到足够的数据来形成图像。所以该技术的早期应用范围相当有限。
磁共振成像(magnetic resonance imaging,MRI)可以在原子核振动的基础上构建更准确的大脑图像。由于 MRI 扫描仪以不同的速度向许多位置发送信号,它可以通过解码不同的频段来成像。不过在 MRI 成像时需要使用一种造影剂,这种造影剂可能对受试者的健康有危险。幸运的是,在注意到核磁共振信号对大脑中血液循环的含氧量敏感后,许多研究小组在 90 年代提出了检测大脑活动的功能性磁共振成像(fMRI)的概念。
神经科学家的传统方法是通过发现最活跃的信号区域来推断统计学上的选择性区域。现代研究目标则是推断出选择性区域的共性活动模式。研究人员发现,神经网络并不会对一个物体有特别的反应,但从统计学角度上分析,却分布着对许多物体的不同比例的反应。这是一种统计学上的相关关系。此外,现代神经科学家的另一个研究目标是通过训练一个计算模型,从更大的数据集中预测人类感知的物体。这种基于机器和统计学习的方法旨在根据神经模型的交叉验证来预测人们的思维。
但是,尽管取得了一些成功,但是对这些基于统计学的科学推论我们仍需要谨慎分析和讨论。fMRI 分析测量了数十万个称为体素(voxel)的小方块。为了从大脑的某个部分找到有意义的反应,而不是由于随机的变化,必须进行统计测试。因此,需要衡量真假阳性的风险,如研究人员在他们的一个实验中发现了一个重要的反应,但当这些实验被多次重复时,这一反应信号在一般的数据中却变得不明显。因此,人们必须能够将实验重复几百次甚至几千次,才能确定结果。使用 fMRI 统计的另一个问题是所谓的 "非独立性(non independence)" 统计错误。研究人员倾向于选择最适合他们研究的数据和结果。例如,在所有的统计测试中,他们可能会关注那些体素显示出最强关联性的实验,而这相对来说可以使他们的实验结果好得多。
我们在这篇文章中,围绕上面的主题,以三篇最新的研究型论文为基础,探讨基于统计学中 ML 的 fMRI 分析方法。
1、通过深度学习对人脑的任务状态进行解码和映射

本文是来自中科大和北大的研究人员 2020 年发表在 Human brain mapping 中的一篇文章[2]。本文重点讨论基于支持向量机(SVM)的多变量模式分析(multivariate pattern analysis,MVPA)在基于人脑功能磁共振成像(fMRI)的特定任务状态解码中的应用。本文作者提出了一个深度神经网络(DNN),用于从大脑的 fMRI 信号中直接解码多个大脑任务状态,无需人工进行特征提取。
关于根据脑功能成像数据解码和识别人脑的功能的问题,SVM-MVPA 是一种应用最为广泛的方法。SVM-MVPA 是一种监督学习技术,可同时考虑多个变量的信息。不过,SVM-MVPA 在高维数据中的表现欠佳,往往依赖于专家选择 / 提取特征的结果。因此,作者在本研究中探索了一种开放式的大脑解码器,它使用的是人类的全脑神经成像数据。相对应的,具有非线性激活函数的 DNN 的分层结构使其能够学习比传统机器学习方法更复杂的输出函数,并且可以进行端到端的训练。由此,本文提出了一个 DNN 分类器,通过读取与任务相关的 4D fMRI 信号,有效解码并映射个人正在进行的大脑任务状态。
1.1 方法介绍
1.1.1 数据介绍
本研究使用了 HCP S1200 最小预处理的 3T 数据版本,其中包含了大量年轻健康成年人的成像和行为数据[3]。作者使用了 1034 名 HCP 受试者的数据,他们共执行了七项任务:情绪、赌博、语言、运动、关系、社交和工作记忆(working memory,WM)。具体用于实验分析的是 HCP volume-based 的预处理 fMRI 数据,这些数据已经被归一到 Montreal Neurological Institute's(MNI) 152 空间。七项任务中的大部分是由控制条件(例如,WM 任务中的 0 - 回位和情感任务中的形状刺激)和任务条件(例如,WM 任务中的 2 - 回位和情感任务中的恐惧刺激)组成的。在每个任务中,只有一个条件被选为下一个步骤。对于只有两个条件的任务(情感、语言、赌博、社交和关系任务),与任务关联度大的条件优先于其他条件。WM 和运动任务包含一个以上的任务条件,作者则是从列表中随机选择一个(WM 的 2 个背部身体和运动的右手)(表 1)。
对于每个任务,输入样本是一个连续的 BOLD(Blood-oxygen-level-dependent imaging)序列,涵盖了整个区块和区块后的 8s 内的样本,包括血流动力学反应函数(hemodynamic response function,HRF)的后信号。此外,将每个 BOLD volume 从 91×109×91 剪裁到 75×93×81,以排除掉不属于大脑的区域。因此,输入数据的大小从 27×75×93×81 到 50×75×93×81(time × x × y × z,TR=0.72s)。在所有的任务和受试者中,总共获得了 34,938 个 fMRI 4D 数据项。
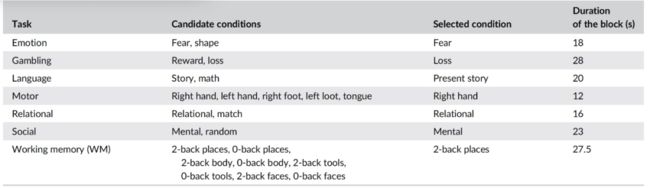
表 1. 每个任务所选择的 BOLD 时间序列的细节
1.1.2 模型介绍
图 1 为本文提出的网络模型的完整流程图。该网络由五个卷积层和两个全连接层组成。其中,27×75×93×81 的数据是通过节 1.1.1 的预处理和数据增强步骤产生的。第一层使用了 1×1×1 的卷积滤波器,即卷积神经网络(CNN)的结构中最普遍的设定,这些滤波器可以在不改变卷积层的感受野的情况下增加非线性。这些滤波器可以为 fMRI volume 中的每个体素生成时间描述符,而且它们的权重可以在训练中由 DNN 学习得到。因此,采用这种类型的过滤器后,数据的时间维度从 27 降到了 3。在这之后,堆叠一个卷积层和四个残差块以提取高层次(high-level)特征。本文使用的残差块是通过用一个三维卷积层替换原始残差块中的二维卷积层而得到的。四个残差块的输出通道分别为 2 的倍数 -----32、64、64 和 128。这些层的设计方式是:它们的尺寸可以迅速减少以平衡 GPU 内存的消耗。为了便于网络可视化分析,作者在最后一个卷积层中使用了全卷积,而不是常见的 CNN 中的池化操作。在卷积层堆叠之后,使用了两个全连接层;第一个有 64 个通道,第二个进行七路分类(每类一个)。在本文模型中,每个卷积层之后都引入了 ReLU 函数和 BN 层,而在最后一个全连接层中采用了 softmax 函数。

图 1. 深度神经网络。
该网络由五个卷积层和两个全连接层组成。该模型将 fMRI 扫描作为输入,并提供标记的任务类别作为输出
对人脑进行特定任务解码面临的一个最大问题是可用数据有限。在其他类似的应用中,可以采用数据增强的方式以基于有限的数据生成更多的数据样本。数据增强的主要目的是增加数据的变化,这可以防止过度拟合并提高神经网络的不变性。与传统图像相反,本实验中的输入图像已经与标准的 MNI152 模板对齐。因此,在空间域进行数据增强是多余的。考虑到输入数据的不同持续时间,作者在时间域中应用了数据增强,以提高神经网络在这种情况下的泛化能力。在训练阶段的每个 epoch 中,从每个输入数据项中随机分割出 k 个连续的 TR 片段(实验中 k=27)(图 2a)。为了避免报告的准确性出现波动,在验证和测试阶段只使用由每个数据的前 k 个 TR 组成的片段。
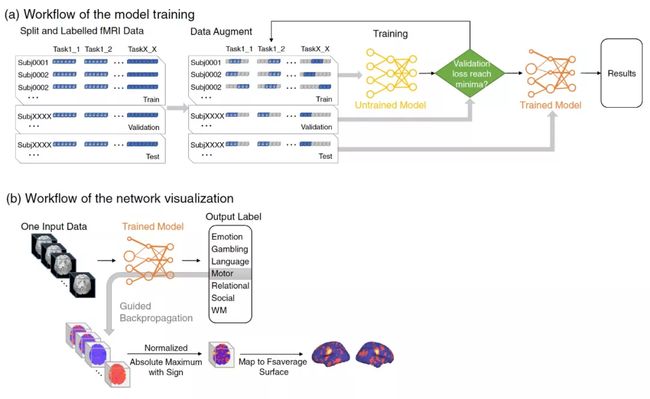
图 2. 模型训练和网络可视化的工作流程。
(a) 模型自动学习标记的 fMRI 时间序列的特征,并在验证的损失达到最小时停止训练。因此,模型训练时不需要手工提取特征。迁移学习的工作流程类似,只是使用训练后的模型取代未训练的模型。每个数据项的分类被反向传播到网络层,以获得对分类重要的部分的可视化。可视化的数据具有与输入数据相同的大小,然后在时间维度上缩小,并映射到 fsaverage 表面
1.1.3 迁移学习
与传统方法相比,深度学习方法,特别是 CNN 的一个重要优势是其可重复使用性,这意味着训练好的 CNN 可以直接在类似的任务中重复使用。作者对训练好的 CNN 使用了迁移学习策略来验证所提出的模型的适用性。迁移训练的工作流程与初始训练的工作流程基本相似(图 2a),只是它从一个前四层已经训练好的模型开始,而输出层是未训练的。作者采用了 HCP 的 TEST-RETEST 任务 - fMRI 组的 TEST 数据集(N = 43)训练深度模型来分类两个 WM 任务子状态 ----0bk body 和 2bk-body。作者采用了按主题划分的五重交叉验证,其中 60% 的数据(25 个主题的 100 个样本)用于训练,20%(9 个主题的 36 个样本)用于验证,20%(9 个主题的 36 个样本)用于测试(总共 172 个样本的规模与常用的 fMRI 研究数据集相当)。为了进一步验证,作者训练深度模型来分类四个运动任务子状态—左脚、左手、右脚和舌头运动。使用五重交叉验证,其中 60%(25 名受试者的 400 个样本)用于训练,20%(9 名受试者的 144 个样本)用于验证,20%(9 名受试者的 144 个样本)用于测试(共 688 个样本)。输入样本是一个连续的 BOLD 序列,涵盖了整个区块和区块后的 8 秒,包括 HRF 的后信号。
为了评估使用小样本量的 fMRI 研究的 DNN 的适用性,作者对来自 HCP TEST 扫描的 43 个对象的数据进行了深度分类器的训练。N = 1, 2, 4, 8, 17, 25, 34。为了避免准确性的差异,所有的测试都应用于 HCP TEST-RETEST 数据集中全部 43 名受试者的 RETEST 数据。深度学习在 120 个 epochs 后停止。此外,作者使用传统的搜索光和全脑 SVM-MVPA 方法进行实验比较。
1.1.4 性能评估
为了评估该模型在不同分类任务中的表现,作者首先定义了一组参数。每个任务条件的 F1 分数被计算为 TP、FP 和 FN 的函数:F1=(2×TP)/(2×TP + FP + FN)。其中,TP 是真阳性,FP 是假阳性,FN 是每个标签的假阴性。作者还通过一比一的方法计算每个标签的 ROC 曲线,参数灵敏度和特异性表示为:灵敏度 sensitivity=TP/(TP+FN),特异性 specificity=TN/(TN+FP),其中 TN 是真阴性,等于其余标签的 TP 之和。准确率被定义为正确预测与分类总数的比率:准确率 accuracy=(TP + TN)/(TP + FP + TN + FN)。
1.1.5 网络可视化分析
本文使用引导反向传播(Guided back-propagation [4]) ,一种广泛使用的深度网络可视化方法,生成每个分类的模式图和输入 fMRI 4D 时间序列的任务加权表示。在标准的反向传播过程中,如果一个 ReLU 单元的输入是正的,那么该单元的偏导就向后复制,否则就设置为零。在引导式反向传播中,如果一个 ReLU 单元的输入和部分导数都是正数,则该单元的部分导数被向后复制。因此,引导式反向传播保持了对类别得分有积极影响的路径,并输出 CNN 检测到的数据特征,而不是那些它没有检测到的特征。如图 2b 所示,在向训练好的网络输入数据后,相对于输入数据产生了 27×75×93×81 的预测梯度。然后,每个体素的时域绝对最大值的符号值被抽出并建立在三维任务模式图中,然后被归一化为其最大值。最后,将 pattern map 映射到 fsaverage 表面。此外,测试组的归一化 pattern map 的 Cohen's d 效应被计算为每个任务的 pattern map 的平均值除以其 SD。
本文的可视化对比分析是在 AFNI[5]、Freesurfer[6]、HCP Connectome Workbench和 MATLAB(MathWorks, Natick, MA)中进行。为了比较传统的 GLM 图和模式图(pattern map),作者还从 HCP 任务的 fMRI 分析包中获取了参数估计对比度(COPE)的 Cohen 效应。
1.2 实验结果分析
首先,作者完成了针对深度模型在一般分类任务中的实验。作者在实验中使用 NVIDIA GTX 1080Ti 板进行了约 30 个 epoch 的训练,所需时间大约 72 小时。本文所提出的模型成功地区分了七个任务,准确率为 93.7±1.9%(mean±SD)。根据 F1 得分,本文使用的模型 / 分类器在七个任务中的表现不同:情绪(94.0±1.6%)、赌博(83.7±4.6%)、语言(97.6±1.1%)、运动(97.3±1.6%)、关系(89.8±3.2%)、社交(96.4±1.0%)和 WM(91.9±2.3%,平均值 ±SD)。平均混淆矩阵(The average confusion matrix)显示,前两个混淆分别是由赌博与关系、WM 与关系引起的(图 3a)。图 3b 显示了 ROC 曲线,根据该曲线,运动、语言和社交任务具有最大的曲线下面积(area under the curve,AUC),而赌博具有最小的面积。在验证关键超参数的选择,即 1×1×1 核通道的数量(NCh1)时,模型记录的准确值分别为 93.2%、91.5% 和 92.7%,NCh1=3、9 和 27(图 3c)。在 NCh1=1 的情况下,该模型无法在 30 个 epoch 内收敛。
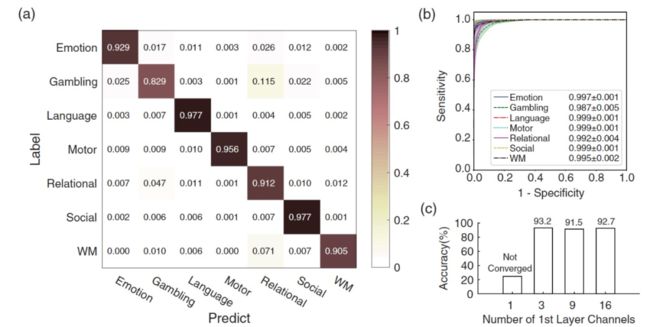
图 3. HCP S1200 任务 fMRI 数据集上的深度学习分类结果
然后,为了确定对每个分类贡献最大的体素(Voxel,指一段时间内多次测量大脑某块区域),作者使用引导式反向传播法生成了模式图,以可视化模型学习到的模式。图 4 给出了对任务 COPE 的 GLM 分析的 Cohen's d 效应大小的分组统计图(图 4a-g),以及 DNN 模式图的 Cohen's d(图 4h-n)。如图所示,DNN 模式图上的 Cohen's d 与 GLM COPEs 上的情感、语言、运动、社交和 WM 任务相似。例如,在语言条件下,GLMCOPEs(图 4c)和 DNN 模式图(图 4j)中的 bilateral Brodmann 22 区出现了较大的效应大小异常。同样,在运动任务的右手运动条件下,两个图(图 4d,k)显示在 Brodmann 4 和 bilateral Brodmann 18 区有类似的效应。

图 4. HCP S1200 数据集上的 HCP 组平均值(左栏)和 DNN 热图(右栏)的 Cohen's d 效应
最后,关于迁移学习的问题,经过五次交叉验证,本文提出的 DNN 在测试中达到了 89.0±2.0% 的平均准确率(图 5a),平均 AUC 为 0.931±0.032(图 5b)。如图 5c 所示,通过双样本 t 检验,DNN 的准确性明显高于 SVM-MVPA 全脑(t[8]=9.14,p=.000017;平均 ±SD=55.6±7.9%)和 SVM-MVPA ROI(t[8]=7.59,p=.000064;平均 ±SD=69.2±5.4%)。
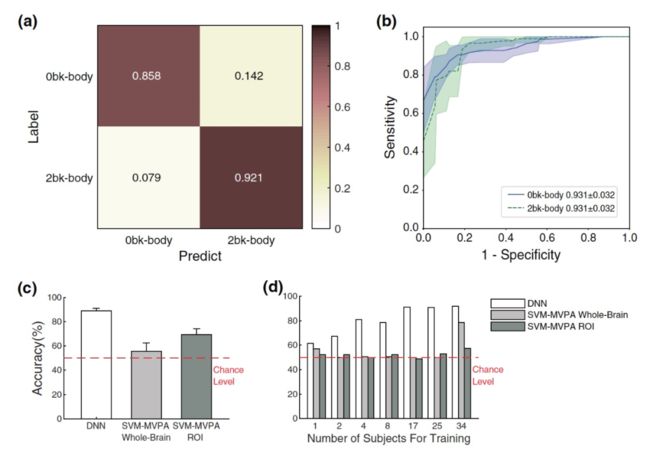
图 5. 工作记忆任务分类的迁移学习结果(0bk-body 与 2bk-body)
经过五次交叉验证,本文提出的 DNN 的平均准确率为 94.7±1.7%(图 6a),平均 AUC 为 ROC 0.996±0.005(图 6b)。平均混淆矩阵显示,最主要的混淆是由左脚与右脚造成的(图 6a)。图 6c 显示,通过双样本 t 检验,DNN 的准确性(94.7±1.7%)明显高于 SVM-MVPA 全脑(t[8]=3.59,p=.0071;平均 ±SD=81.6±7.1%)和 SVM-MVPA ROI(t[8]=8.77,p=.000022;平均 ±SD=68.6±5.7%)。然后,作者验证了学习所需的数据量。所有三种方法在所有 N_Subj 中都报告了高于经典方法的准确性。N_Subj=8 足以使 DNN(80.3%)在准确性方面超过普通的 SVM-MVPA 全脑方法(41.7%)和 SVM-MVPA ROI(56.3%)(图 6d)。
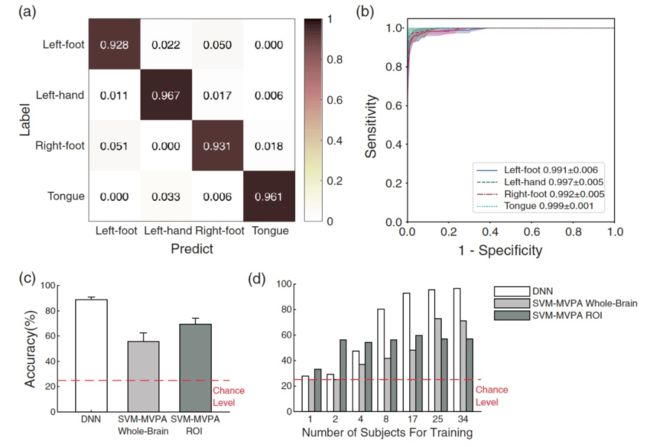
图 6. 运动任务(左脚、左手、右脚和舌头)的分类迁移学习结果
小结:本文提出的方法能够直接从 4D fMRI 时间序列中对人正在进行的大脑功能进行分类和映射。本文方法允许从简短的 fMRI 扫描中解码受试者的任务状态,无需进行特征选择。这种灵活高效的大脑解码方法可以应用于神经科学的大规模数据和精细的小规模数据。此外,它的便利性、准确性和通用性的特点使得该深度框架可以很容易地应用于新的人群以及广泛的神经影像学研究,包括内部精神状态分类、精神疾病诊断和实时 fMRI 神经反馈等等。
2、使用深度生成神经网络从 fMRI 模式重建人脸

本文是发表在 Communications Biology 中的一篇文章[7]。由上一篇文章的介绍可以知道,目前,已经可以从功能磁共振成像的大脑反应中解码识别不同的类别。但是,针对视觉上相似的输入(例如不同的人脸)的分类和识别仍然是非常困难的。本文具体探讨的是应用深度学习系统从人类的功能磁共振成像重建人脸图像。作者基于一个大型名人脸部数据库使用一个生成对抗网络(GAN)的无监督过程训练了一个变分自动编码器(VAE)神经网络。自动编码器的潜在空间为每幅图像提供了一个有意义的、拓扑学上有组织的 1024 维描述。然后,向人类受试者展示了几千张人脸图像,并学习了多体素 fMRI 激活模式和 1024 个潜在维度之间的简单线性映射。最后,将这一映射应用于新的测试图像,将 fMRI 模式转化为 VAE 潜在编码,并将编码重建为人脸。
2.1 模型介绍
本文所使用的 VAE-GAN 模型如图 7(a)所示,其中的三个网络学习完成互补的任务。具体包括:编码器网络将人脸图像映射到一个潜在的表征(1024 维)上,显示为红色。生成器网络将其转换为一个新的人脸图像。鉴别器网络(只在训练阶段使用)为每张给定的图像输出一个二进制的判断,可以是来自原始数据集,也可以是来自生成器输出,即:该图像是真的还是假的?训练的过程具有 "对抗性",因为判别器和生成器的目标函数相反,并交替更新:如果鉴别器能够可靠地确定哪些图像来自生成器(假的),而不是来自数据库(真的),就会得到奖励。如果生成器能够产生鉴别器网络不会正确分类的图像,就会得到奖励。训练结束后,丢弃鉴别器网络,编码器 / 生成器网络被用作标准(变分)自动编码器。
网络中的 "人脸潜在空间" 提供了对大量人脸特征的描述,可以近似于人脑中的脸部表现。在这个潜在空间中,人脸和人脸特征(例如,男性)可以被表示为彼此的线性组合,不同的概念(例如,男性,微笑)可以用简单的线性操作来处理(图 7b)。作者分析,这种深度生成神经网络潜在空间的多功能性表明它可能与人脑的人脸表征有同源性,这也使得它成为基于 fMRI 的人脸解码的理想候选方法。由此,作者推断,在对大脑活动进行解码时,学习 fMRI 模式空间和这种潜在空间之间的映射,而不是直接学习图像像素空间(或这些像素的线性组合,例如 PCA 等的处理方法),可能是非常有用的。此外,作者推测 ,VAE-GAN 模型能够捕捉人脸表征的大部分复杂性,使 "人脸流形" 变得平坦,就像人类大脑可能做的那样。因此,作者认为,采用简单的线性大脑解码方法就足够了。

图 7. 深度神经网络潜在空间。(a)VAE-GAN 网络架构。(b)潜在空间属性
作者首先使用无监督 GAN 在 202,599 张名人人脸标记数据库上训练了一个 VAE 深度网络(13 层)(CelebA[8]),共执行 15 个 epoch。使用编码器处理向人类受试者展示的人脸图像以生成 1024 维的潜在编码,这些编码作为设计矩阵后续会用于 fMRI GLM(一般线性模型)分析。作者使用 SPM12 处理 fMRI 数据(https://www.fil.ion.ucl.ac (https://www.fil.ion.ucl.ac/).uk/spm/software/spm12/)。接下来,作者对每份数据分别进行了切片时间校正和重新对齐。然后将每个时段的数据与第二个 MRI 时段的 T1 扫描数据进行联合登记。不过,作者并未对这些数据进行归一化或平滑化处理。具体的,作者将每个实验的开始和持续时间(固定、训练脸、测试脸、单人背影或意象)输入一般线性模型(general linear model,GLM)中作为回归因子;将用于训练脸部的 1024 - 维潜在向量(来自 VAE-GAN 或 PCA 模型)作为参数化的回归器来建模,并将运动参数作为滋扰回归器(nuisance regressors)输入用于消除滋扰信号。此外,在估计 GLM 参数之前,令整个设计矩阵与 SPM 的血流动力学反应函数(hemodynamic response function,HRF)进行卷积处理。
作者训练了一个简单的大脑 fMRI 的编码器(线性回归),将人脸图像的 1024 维潜在表征(通过 "编码器" 运行图像,或使用 PCA 变换获得)与相应的大脑反应模式联系起来,并将人类受试者在扫描仪中观看相同的人脸时记录下来。图 8(a)给出了这一过程的完整描述。每个受试者平均看到超过 8000 张人脸(每个人都有一个演示),使用 VAE-GAN 潜在维度(或图像在前 1024 个主成分上的投影)作为 BOLD 信号的 1024 个参数化回归因子。这些参数化的回归因子可以是正的,也可以是负的(因为根据 VAE 的训练目标,VAE-GAN 的潜在变量是近似正态分布的)。将一个额外的分类回归因子("面部与固定" 对比)作为一个恒定的 "偏差" 项添加到模型中。作者验证了设计矩阵是 "full-rank" 的,也就是说,所有的回归因子都是线性独立的。作者分析,这一属性是因为 VAE-GAN(和 PCA)的潜在变量往往是不相关的。因此,由 SPM GLM 分析进行的线性回归产生了一个优化的权重矩阵 W,以预测大脑对训练人脸刺激的反应模式。
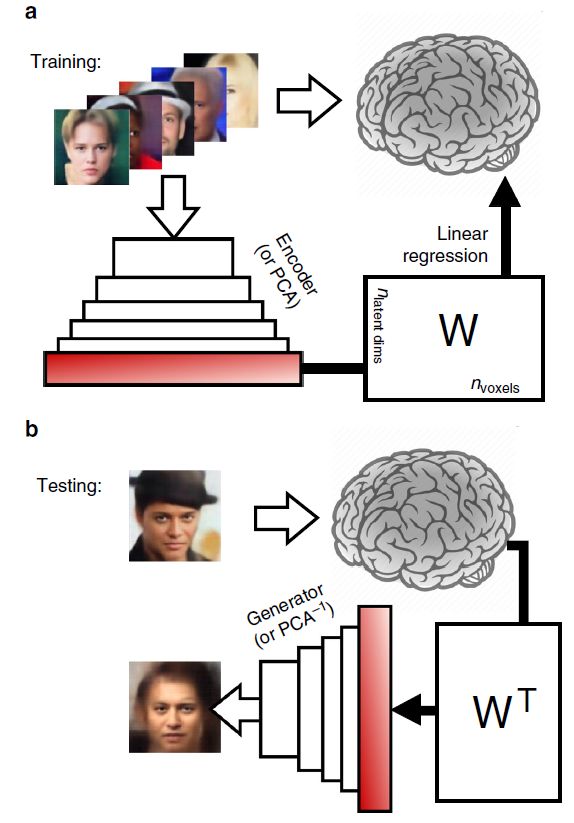
图 8. 基于 VAE-GAN 潜在表征的人脸图像的大脑解码。(a)训练训阶段。(b)测试阶段
假设在 1025 维的人脸潜在向量 X(包括了一个偏置项)和相应的大脑激活向量 Y 之间存在一个线性映射 W:
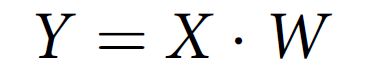
训练大脑解码器通过以下方式找到最佳映射 W:
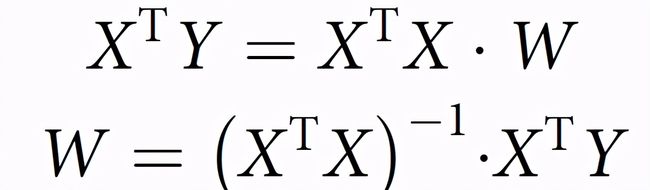
为了在 "测试阶段" 使用这个大脑解码器,作者简单地反转了线性系统,如图 8b 所示。作者向同一受试者展示了 20 张新的测试人脸,这些人脸在训练阶段并没有向受试者展示过。每个测试人脸平均呈现 52.8 次以增加信噪比。所得的大脑活动模式简单地与转置的权重矩阵 W^T 及其反协方差矩阵相乘,以产生 1024 个潜在人脸维度估计值。然后,使用 GAN(如图 7a 所示)将预测的潜在向量转化为重建的人脸图像。对于基线 PCA 模型,方法的流程是相同的,但人脸的重建是通过解码的 1024 维向量的 inverse PCA 获得的。测试大脑解码器包括使用学到的权重 W 为每个新的大脑激活模式 Y 检索潜在的向量 X,利用下式求解 X:

作者已经将本文使用的预训练的 VAE-GAN 网络以及 Python 和 TensorFlow 源代码公布在了 GitHub 上:https://github.com/rufinv/VAE-GAN-celebA.
2.2 实验结果分析
本实验中,通过 Amazon Mechanical Turk (AMT)获得用于比较 VAE-GAN 和 PCA 人脸重建的图像质量的人类评价结果。四个受试者的 20 张测试图像中的每一张都标记为 "原始 ”,然后是 VAE-GAN 和基于 PCA 的重建图像,在" 选项 A "和" 选项 B "的字样下显示。实验中,向受试者发布的指示为:" 在两个修改过的人脸中,哪一个最像原来的人脸?选择 A 或 B"。每对图像总共被比较了 15 次,由至少 10 个不同的 AMT" 工作者 " 进行,每个反应分配(VAE-GAN/PCA 为选项 A/B)由至少 5 个工作者查看。因此,该实验在两个人脸重建模型之间总共进行了 1200 次(=4×20×15)比较。
作者首先对比了 VAE-GAN 和 PCA,将灰质体素的一个子集定义为 "兴趣区域" (ROI)。事实上,大脑的许多部分都在进行与人脸处理或识别无关的计算。作者的 ROI 只选择生理上的可能应激大脑区域,选择标准考虑了两个因素。(i) 预计体素会对人脸刺激作出反应(通过脸部和基线条件之间的 t 检验来确定,即固定在空屏幕上),(ii)将 1024 个潜在人脸特征作为回归因子输入线性模型时,体素的 BOLD 反应的解释方差有望改进(与只有二元人脸回归因子的基线模型相比:存在 / 不存在人脸)。所选的体素如图 9 描述,包括 枕部、颞部、顶部和额部区域。作者对 PCA 人脸参数进行了单独的选择, 并将这些参数用于基于 PCA 的 "大脑解码器"(所选体素的平均数量:106,685;范围:74,073-164,524);两个模型所选区域几乎相同。
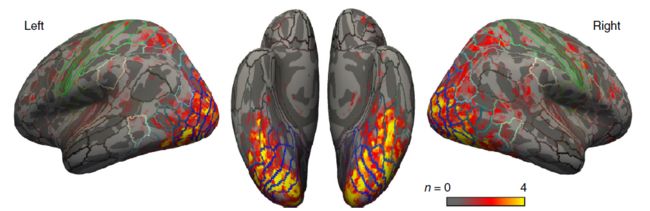
图 9. 为大脑解码选择的体素。
在大脑解码器训练阶段,体素的选择是基于其视觉反应性和 GLM 拟合度的综合考虑(图 8a)。颜色代码(红色到黄色)表示每个特定体素被选中的受试者的数量(1-4)。彩色的线表示标准皮质区域的边界
图 10(a)给出了人脸重建图像的示例。虽然 VAE-GAN 和 PCA 都能重建出与原始人脸相似的图像,但是由 VAE-GAN 重建的图像更真实,更接近原始图像。作者通过将 20 张测试人脸的大脑估计潜在向量与 20 张实际人脸的潜在向量相关联来量化大脑解码系统的性能,并使用成对相关值来测量正确分类的百分比。具体结果见图 10(b)。实验结果表明,从人脑激活到 VAE–GAN 潜在空间的线性映射比到 PCA 空间的映射更容易、更有效。作者认为,这与其 “深度生成神经网络更接近于人脸表征的空间” 的假设相吻合。此外,作者还进行了模型间的完全识别结果比较,即利用重建图像的感知质量作为指标衡量重建的人脸水平。实验要求人类观察者比较两种模型重建的人脸质量:四个受试者的原始测试图像与相应的 VAE-GAN 和 PCA 重建图像一起显示,受试者判断哪一个重建图像从感知角度判断更像原始图像。具体结果见图 10(c)。76.1% 的实验中受试者选择了 VAE-GAN 重建的图像,而 23.9% 的实验中受试者选择了 PCA 重建的图像。

图 10. 人脸重建。(a)重建人脸图像示例;(b)两两识别结果;(c)完全识别结果
进一步的,为了确定哪一个大脑区域对两个大脑解码模型的人脸重建能力贡献最大,作者将每个受试者的体素选择划分为三个大小相等的子集,如图 11a 所示。然后分别对这三个子集进行脑解码和面部重建。两两识别结果显示,枕骨体素和较小程度的颞体素提供了大脑解码所需的大部分信息(图 11b)。
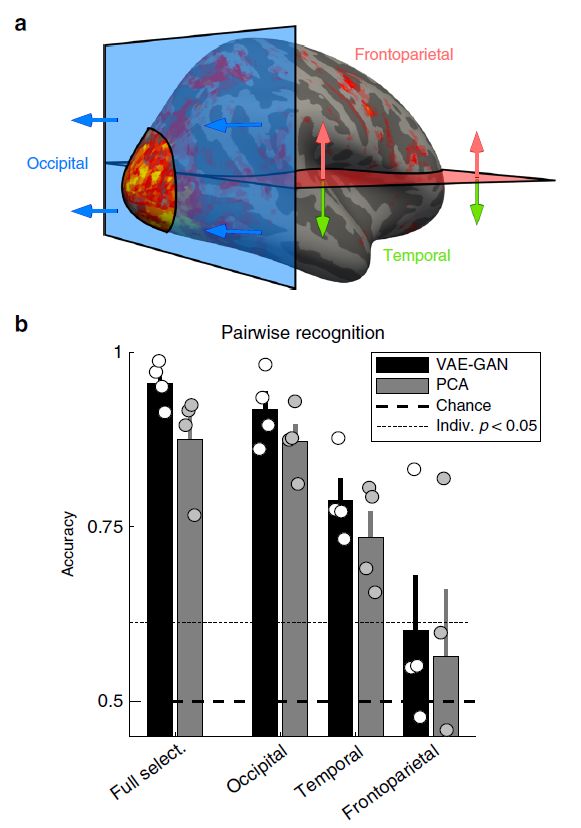
图 11. 不同脑区的贡献情况。
(a)体素分割过程;(b)不同区域的两两识别结果,Full select 指的是图 9 中描述的体素集;它与图 10b 中的数据相同。圆圈代表个别受试者的表现。虚线是单个受试者表现的 p<0.05 的显著性阈值。在三个子集中,枕部体素的表现是最优的,其次是颞部体素。在所有情况下, VAE-GAN 模型的性能仍然高于 PCA 模型。
最后,作者通过创建一个简单的分类器以根据人脸属性为大脑解码的潜在向量贴标签的方式,研究人脑对于特定人脸属性的表征。具体的关于人脸 “性别” 属性的实验结果见图 12。将每个大脑解码的潜在向量投射到潜在空间的 "性别" 轴上(图 12a),投射的符号决定了分类输出(正数代表“男性”,负数代表“女性 ”)。由图 12b 的结果可以看出,这个单一衡量标准的分类器提供了足够的信息来对人脸性别进行分类,准确率达到了 70%。非参数 Friedman 检验表明,性别解码性能在三个体素子集中是不同的,而 post hoc 检验则显示枕叶体素的表现明显好于额顶叶体素,而颞叶体素介于两者之间。
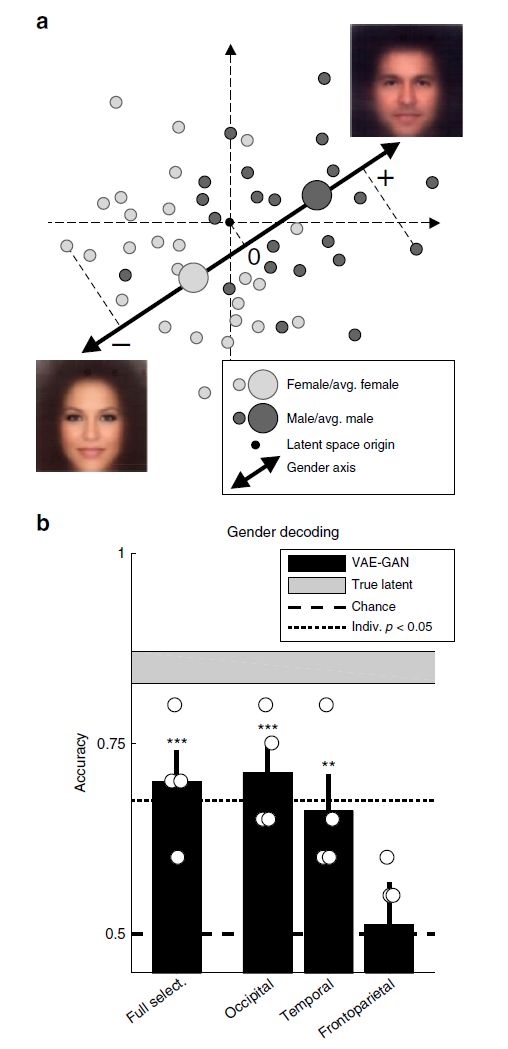
图 12. 图 6 性别解码。(a)基本线性分类器;(b)解码准确度
3、AI 解码大脑神经反馈动力学 - 用于解码神经反馈实验的数据

本文是来自日本 ATR 国际学院计算神经科学实验室的研究人员发表在《Scientific Data》2021 上的一篇文章[9],主要为利用 AI 解码大脑神经反馈以读取和识别大脑中特定信息的方法提供实验所需的数据。解码神经反馈(Decoded neurofeedback,DecNef)是一种闭环 fMRI 神经反馈与机器学习方法相结合的形式,意思是分析 fMRI 的状态改变外围不同设备(比如被测者面前的显示器)的刺激。这是对操纵大脑动力学表现或表征这一长期目标的更细化的呈现。本文针对 DecNef 实验,提供了可应用的数据来源。作者发布了一个大型的、可公开访问的神经影像学数据库,其中包括 60 多个接受 DecNef 训练的人。这个数据库由大脑的结构和功能图像、机器学习解码器和额外的处理数据组成。作者在文中描述了编译数据库时采用的协议,包括源数据中常见的和不同的扫描参数、元数据、结构,以及匿名化、清理、排列和分析等处理方式。
3.1 DecNef 背景分析
在单变量(univariate)方法中,人们具体测量一个感兴趣区域(ROI)的整体活动水平。与此不同,多体素模式分析(multivoxel pattern analysis,MVPA)则是学会对分布在活动模式中的信息进行解码。DecNef 利用了 MVPA 而不是使用单变量方法,因此它具有很高的目标特异性。此外,尽管受试者清楚解码神经反馈实验的存在,但他们并不知道具体的内容和目的,从而有助于减少由于认知过程或对被操纵维度的了解而产生的混淆。此外,解码神经反馈实验甚至可以通过一种称为 "超边界(hyperalignmen)" 的方法,根据受试者间接推断出目标神经表征。通过这样的功能排列方法,将不同受试者的神经活动模式通过一组线性变换构建了一个共同的、高维的空间。这些转换是有效的参数,可以用来将任何新的数据模式带入 / 带出个人的大脑坐标系统和模型空间坐标。上述特点使得 DecNef 成为了开发新的临床应用的一种有效工具,特别是在神经精神疾病方面。除了面向临床的研究外,DecNef 还可以作为系统和认知神经科学的一个重要范式来研究大脑的基本功能。
不同的 DecNef 实验探究的是不同的认知过程或心理表征,但所有研究都采用了相同的基本设计逻辑(如图 13a)。(1)最初的环节是获取 fMRI 数据,用于训练机器学习算法—MVPA 或解码器构建环节。(2)随后的神经反馈阶段,持续 2 到 5 天不等。在解码器构建环节,受试者完成了简单的动作,包括视觉(研究 2、3)、偏好(研究 1)、知觉(研究 4)或记忆任务(研究 5),在神经反馈环节,所有程序几乎都是相同的(图 13b)。在神经反馈训练中,要求受试者调节或操纵他们的大脑活动,以最大限度地扩大反馈盘(feedback disc)的大小。
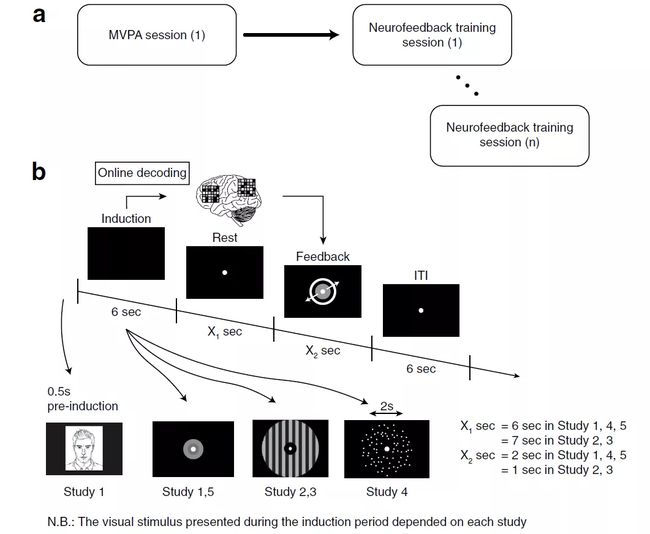
图 13. 实验设计的示意性概述。
(a) 每项研究都包括一段 fMRI,用于获得构建 "解码器" 所需的数据,这是一个机器学习的大脑活动模式分类器。(b) 所有的研究都有相同的基本实验设计
到目前为止,全世界只有少数研究小组有机会完成这种技术上具有挑战性的实验。作者介绍,他们已经发表了关于如何运行解码神经反馈实验这部分工作的介绍[10]。不过,关于 DecNef(以及一般的神经反馈)的一个关键问题仍未解决:潜在神经机制究竟是什么?一些近期的研究工作已经开始聚焦于这个问题,并应用了元分析、计算模型、神经网络等工具。表 2 总结了已有的部分研究,包括相关出版物、神经反馈过程训练目标等内容。
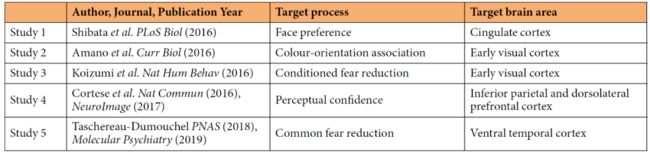
表 2. 纳入数据收集的研究摘要
3.2 数据分析
关于本文提供的源数据,表 3 给出所有研究中使用的扫描参数的技术细节,以及不同研究之间的差异。

表 3. 不同研究之间的扫描参数
可通过机构存储库 "DecNef 项目大脑数据存储库(DecNef Project Brain Data Repository)"(https://bicr-resource.atr.jp/drmd/),或从 Synapse 数据存储库 (https://doi.org/10.7303/syn23530650) 访问数据。数据是按照图 14 所示的结构来组织的。简而言之,对于每项研究,最上层的文件夹包含了每个受试者的文件夹(例如,"sub-01")。其中有三个子文件夹,"anat" 包含与结构 / 解剖扫描有关的原始 Nifti 文件,"func"—进一步细分为特定会话文件夹(例如,"ses-0":解码器,"ses-1":神经反馈的第一个会话,等等),包含所有来自功能扫描的压缩 Nifti 文件。
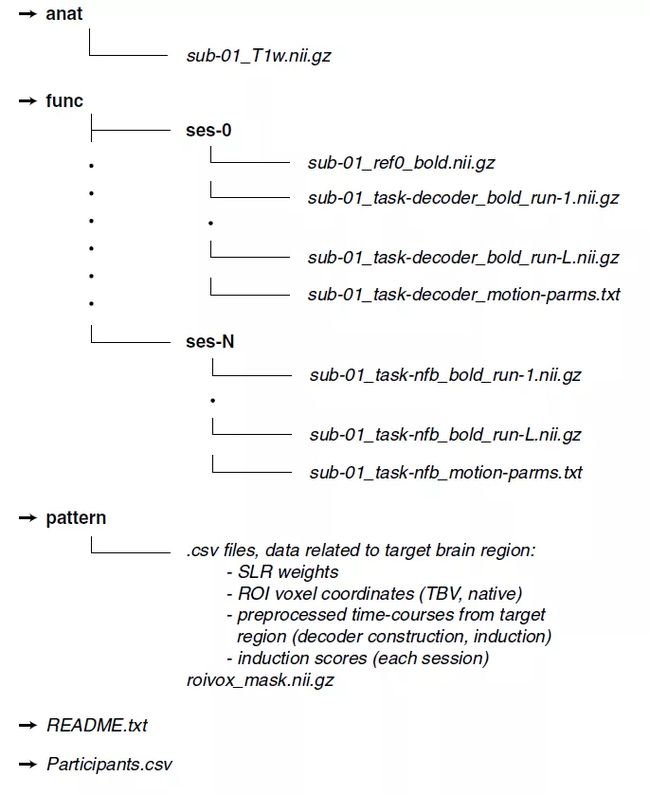
图 14. 数据集结构和内容
对高分辨率的解剖学扫描进行涂抹处理,以确保结构数据的适当匿名化。使用统计参数映射(SPM)对图像进行了偏差校正。使用统计参数绘图(SPM)工具箱(https://www.fil.ion.ucl.ac.uk/spm/)对图像进行偏差校正,并使用 FreeSurfer 套件的自动涂抹工具进行涂抹。图 15 为一个受试者的图像结果示例。

图 15. 受试者结构扫描的匿名化(污损)处理示例
鉴于 DecNef 方法的细粒度、高空间分辨率的要求,用于在线反馈计算的大脑图像的功能排列需要具备非常高的会话间一致性。图像必须与原始解码器的结构对齐,而且这种对齐必须在(子)体素水平上是精确的。即使是微小的头部运动也很容易破坏这一前提条件,导致不完善的解码和反馈得分计算。为了满足这一要求,所有的研究都要求实时监测传入的大脑功能图像与原始解码器结构中的模板之间的对齐情况。尽管使用 Turbo BrainVoyager(TBV,Brain Innovation)实时校正头部运动,但并不能保证校正后的图像在解码方面是有意义的,尤其是在突然出现明显位移时。因此,在实时神经反馈实验中,对原始 DICOM 图像进行了以下处理步骤。首先,在诱导期测量的功能图像使用 TBV 进行三维运动校正。第二,从解码器识别的每个体素中提取信号强度的时间序列,并将其移位 6 秒以考虑到血流动力学延迟。第三,从时间过程中去除线性趋势,并使用从每次 fMRI 运行开始后 10 秒测量的信号强度对每个体素的信号时间过程进行 Z-score 归一化处理。第四,计算反馈分数的数据样本是通过平均每个体素在诱导期的 BOLD 信号强度来创建的。
在目标体素的激活模式方面,控制数据质量的一个有效方法是首先计算它们的平均激活(用初始解码器构建会话的数据)。然后,在实时会话中,计算平均模式和传入活动模式之间的逐个相关性。这种方法确保了当体素的反应模式由于例如头部或身体运动而发生重大变化时,相关度的降低会迅速发生,从而可以被检测到。最佳水平的相关性水平应该在 r∈[0.85 1.00]的区间内,或 Fisher 变换的 z∈[1.26 Inf]。作者证实,所有的研究确实都能满足此条件(图 16)。平均来说,只有不到 2% 的实验的 z 值小于 1.26(研究 1:0.13%,研究 2:3.17%,研究 3:0.91%,研究 4:0.36%,研究 5:3.74%)。
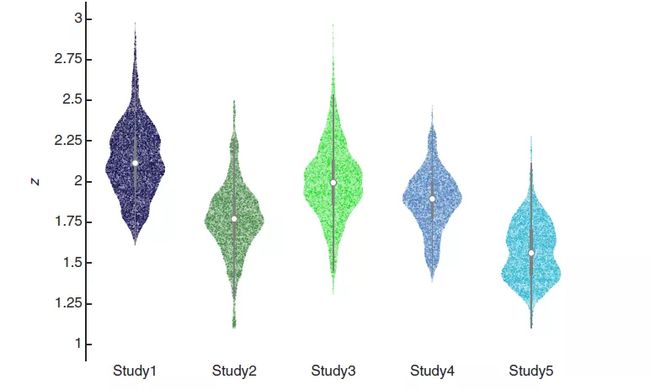
图 16. 平均活动模式和实时活动模式之间的费舍尔转换相关性(Fisher transformed correlation)。
较大值表明实时测量模式和解码器构造模式之间有更好的功能一致性。每个点代表一个实验的相关值。每个琴状图有 N(天)×M(受试者)×L(运行)×J(实验)个点。图中央的白圈代表中位数,粗灰线代表四分位数范围,细灰线代表相邻的数值。将 z<1.10 的数据点从图中删除
接下来,作者建立了头部运动和模式相关度之间的关系。作者使用 SPM12 计算了头部运动参数,得出了 3 个平移参数和 3 个旋转参数。为了这个分析的目的,作者通过对相关的 3 个参数进行平均化处理来计算平均绝对旋转和平均绝对平移,在神经反馈实验中使用的 3 个 TR 来计算解码器的可能性和模式的关联性。作者将这两个头部运动指数(以毫米为单位)与所有研究中汇集的 Fisher 转换后的相关系数(即模式相关度)进行了对比(如图 17 所示)。为了进行统计分析,作者串联单次实验数据,使用线性混合效应(linear mixed effects,LME)模型进行分析(按照 Wilkinson 符号,指定为 y ~ 1 + m + (1 | st) + (1 + st | prt);其中 y:模式相关性,1:截距,m:运动参数,st:实验研究,prt:受试者)。具体来说,这些 LME 模型的设计是将运动作为固定效应,实验研究作为随机效应和协变量,个体受试者作为随机效应而嵌套在实验研究中。
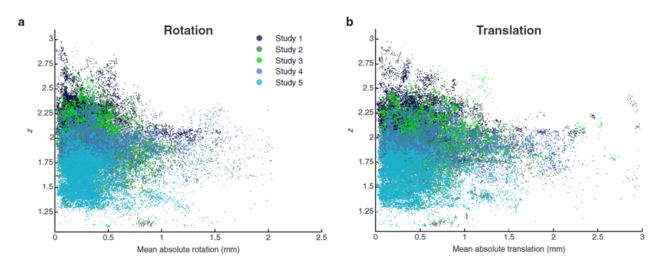
图 17. 模式相关性与头部运动的关系。
头部运动被计算为三维方向上的旋转(a)或三维方向上的平移(b),并与 Fisher 转换后的模式相关系数成图。使用不同颜色绘制来自不同研究的数据点。每个数据点表征一个特定受试者、运行和实验
最后,其他的生理噪声源(如心跳或呼吸)也会影响用于实时解码的多体素活动模式。这些来源在本研究中没有直接测量,因此作者只能猜测它们的影响。如果它们对所有体素的影响是相对均匀的,作者预计对模式相关的测量几乎没有影响,因为体素之间的关系将保持基本不变。如果各体素之间存在不均匀的影响,作者认为模式相关性会受到类似于头部运动的影响。人们可能会担心,在第一种情况下,将无法检测到数据的噪声失真,从而有可能造成反馈给受试者的目标真实性失效。但由于所有体素的活动首先经过基线归一化处理,然后通过计算体素的活动模式与权重向量之间的点积来确定反馈似然,因此重要的是体素的模式(体素活动之间的 "差异")。由此,作者指出,由于 MVPA 的特殊性,额外的噪声源不太可能在不影响模式相关度的情况下显著影响体素活动模式的信息内容。
4、小结
本文探讨了基于统计学中 ML 的 fMRI 分析方法。其中, 第一篇文章介绍了基于 SVM 的多变量模式分析在基于人脑功能磁共振成像(fMRI)的特定任务状态解码中的应用。具体的,作者引入一个 DNN 分类器,通过读取与任务相关的 4D fMRI 信号,有效解码并映射个人正在进行的大脑任务状态。DNN 的分层结构使其能够学习比传统机器学习方法更复杂的输出函数,并且可以进行端到端的训练,进而提升了大规模数据集中 fMRI 解码的准确度水平。第二篇文章具体探讨的是应用深度学习系统从人类的功能磁共振成像(fMRI)重建人脸图像。利用 VAE-GAN 模型,学习多体素 fMRI 激活模式和 1024 个潜在维度之间的简单线性映射。然后将这一映射应用于新的测试图像,将 fMRI 模式转化为 VAE 潜在编码,并将编码重建为人脸。最后一篇文章发布了一个大型的、可公开访问的神经影像学数据库,该数据库中的数据是由解码神经反馈(Decoded neurofeedback,DecNef)实验训练得到的,除了面向临床的研究外,该数据库还可以作为系统和认知神经科学的一个重要范式来研究大脑的基本功能。这一数据库的发布为推动解码神经反馈的研究发展提供了良好的数据基础。
ML 已经证明在图像处理和识别的广泛用途。利用 ML 连接 fMRI 图像,可以分类人脑正在观察和思考的状态,甚至重建正在联想的人脸内容。神经科学家正在借助机器学习技术解码人类大脑的活动、理解人类大脑的趋势方兴未艾,帮助我们更好的了解我们的大脑迷宫。
本文参考引用的部分文献:
[1] https://uxdesign.cc/how-neuroscientists-are-reading-and-decoding-human-thoughts-380474d0e8c1
[2] Xiaoxiao Wang, etc al. Decoding and mapping task states of the human brain via deep learning. Hum Brain Mapp. 2020 Apr 15; 41(6): 1505–1519. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7267978/
[3] Van Essen, D. C., Smith, S. M., Barch, D. M., Behrens, T. E., Yacoub, E., Ugurbil, K., & Consortium, W.U.-M.H. (2013). The WU-Minn human connectome project: An overview. NeuroImage, 80, 62–79. https://doi.org/10.1016/j.neuroimage.2013.05.041
[4] Springenberg, J.T., Dosovitskiy, A., Brox, T., Riedmiller, M. (2014). Striving for simplicity: The all convolutional net. arXiv:1412.6806.
[5] Cox, R. W. (1996). AFNI: Software for analysis and visualization of functional magnetic resonance neuroimages. Computers and Biomedical Research, 29, 162–173. https://doi.org/10.1006/cbmr.1996.0014
[6] Fischl, B. (2012). FreeSurfer. NeuroImage, 62, 774–781. https://doi.org/10.1016/j.neuroimage.2012.01.021
[7] Rufin VanRullen &Leila Reddy, Reconstructing faces from fMRI patterns using deep generative neural networks, Communications Biology volume 2, Article number: 193 (2019) , https://www.nature.com/articles/s42003-019-0438-y
[8] Liu, Z., Luo, P., Wang, X. & Tang, X. Deep learning face attributes in the wild. In Proc. International Conference on Computer Vision (ICCV) (2015).
[9] Cortese A , Tanaka S C , Amano K , et al. The DecNef collection, fMRI data from closed-loop decoded neurofeedback experiments[J]. Scientific Data, 2021, 8(1):65.
[10] Taschereau-Dumouchel, V., Cortese, A., Lau, H. & Kawato, M. Conducting decoded neurofeedback studies. Soc. Cogn. Affect. Neurosci. nsaao63 (2020).
分析师介绍:
本文作者为Wu Jiying,工学博士,毕业于北京交通大学,曾分别于香港中文大学和香港科技大学担任助理研究员和研究助理,现从事电子政务领域信息化新技术研究工作。主要研究方向为模式识别、计算机视觉,爱好科研,希望能保持学习、不断进步。