自动化运维之k8s——kubernetes存储、Configmap配置管理、Secret配置管理、Volumes配置管理、kubernetes调度、PV PVC、kubernetes访问控(未完待续)
一、Configmap配置管理
1、Configmap概念
Configmap用于保存配置数据,以键值对形式存储。
configMap 资源提供了向 Pod 注入配置数据的方法。
旨在让镜像和配置文件解耦,以便实现镜像的可移植性和可复用性。
典型的使用场景:
(1)填充环境变量的值
(2)设置容器内的命令行参数
(3)填充卷的配置文件
2、Configmap创建方式
创建ConfigMap的方式有4种:
使用字面值创建
使用文件创建
使用目录创建
编写configmap的yaml文件创建
(1)使用字面值创建
$ kubectl create configmap my-config --from-literal=key1=config1 --from-literal=key2=config2
(2)使用文件创建
(3)使用目录创建
(4)编写configmap的yaml文件
二、Secret配置管理
三、Volumes配置管理
官方文档:卷 | Kubernetesvolume abstraction solves both of these problems. -- Container 中的文件在磁盘上是临时存放的,这给 Container 中运行的较重要的应用 程序带来一些问题。问题之一是当容器崩溃时文件丢失。kubelet 会重新启动容器, 但容器会以干净的状态重启。 第二个问题会在同一 Pod 中运行多个容器并共享文件时出现。 Kubernetes 卷(Volume) 这一抽象概念能够解决这两个问题。阅读本文前建议你熟悉一下 Pods。背景 Docker 也有 卷(Volume) 的概念,但对它只有少量且松散的管理。 Docker 卷是磁盘上或者另外一个容器内的一个目录。 Docker 提供卷驱动程序,但是其功能非常有限。Pod can use any number of volume types simultaneously. Ephemeral volume types have a lifetime of a pod, but persistent volumes exist beyond the lifetime of a pod. When a pod ceases to exist, Kubernetes destroys ephemeral volumes; however, Kubernetes does not destroy persistent volumes. https://kubernetes.io/zh/docs/concepts/storage/volumes/
https://kubernetes.io/zh/docs/concepts/storage/volumes/
使用statefullset部署mysql主从集群:
运行一个有状态的应用程序 | Kubernetes本页展示如何使用 StatefulSet 控制器运行一个有状态的应用程序。此例是多副本的 MySQL 数据库。 示例应用的拓扑结构有一个主服务器和多个副本,使用异步的基于行(Row-Based) 的数据复制。说明: 这不是生产环境下配置。 尤其注意,MySQL 设置都使用的是不安全的默认值,这是因为我们想把重点放在 Kubernetes 中运行有状态应用程序的一般模式上。 准备开始 你必须拥有一个 Kubernetes 的集群,同时你的 Kubernetes 集群必须带有 kubectl 命令行工具。 建议在至少有两个节点的集群上运行本教程,且这些节点不作为控制平面主机。 如果你还没有集群,你可以通过 Minikube 构建一个你自己的集群,或者你可以使用下面任意一个 Kubernetes 工具构建: Katacoda 玩转 Kubernetes 要获知版本信息,请输入 kubectl version. 您需要有一个带有默认StorageClass的动态持续卷供应程序,或者自己静态的提供持久卷来满足这里使用的持久卷请求。 本教程假定你熟悉 PersistentVolumes 与 StatefulSet, 以及其他核心概念,例如 Pod、 服务 与 ConfigMap. 熟悉 MySQL 会有所帮助,但是本教程旨在介绍对其他系统应该有用的常规模式。 您正在使用默认命名空间或不包含任何冲突对象的另一个命名空间。 教程目标 使用 StatefulSet 控制器部署多副本 MySQL 拓扑架构。 发送 MySQL 客户端请求 观察对宕机的抵抗力 扩缩 StatefulSet 的规模 部署 MySQL MySQL 示例部署包含一个 ConfigMap、两个 Service 与一个 StatefulSet。https://kubernetes.io/zh/docs/tasks/run-application/run-replicated-stateful-application/

踩坑:
mysql.yaml文件中创建这个pvc时,因为没有指定“storageclass”类,导致创建失败。通过之前的“nfs-client-provisioner.yaml”文件中,新建一个这个类的名称,就可以了 。
mysql.yamlwen文件中:
出现故障时:
nfs-client-provisioner.yaml文件中:新建“nfs-client”
除此之外还有一种方法,就是设置一个默认的存储类,就不需要在mysql.yaml中特别指定了。





#新开一个mysql的pod
kubectl run demo -it --image=mysql:5.7 --restart=Never -- bash
#进入pod
kubectl exec mysql-1 -c mysql -it -- bash
四、PV PVC
四、kubernetes调度
调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod。调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行。
kube-scheduler 是 Kubernetes 集群的默认调度器,并且是集群控制面的一部分。如果你真的希望或者有这方面的需求,kube-scheduler 在设计上是允许你自己写一个调度组件并替换原有的 kube-scheduler。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、亲和以及反亲和要求、数据局域性、负载间的干扰等等。
默认策略可以参考:https://kubernetes.io/zh/docs/concepts/scheduling/kube-scheduler/
调度框架:https://kubernetes.io/zh/docs/concepts/configuration/scheduling-framework/
#向node节点server3中添加标签disktype=ssd
kubectl label nodes server3 disktype=ssd
#删除node节点server3中disktype的标签
kubectl label nodes server3 disktype-
亲和与反亲和
将 Pod 分配给节点 | Kubernetes https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/
https://kubernetes.io/zh/docs/concepts/scheduling-eviction/assign-pod-node/
node的亲和性:
pod的亲和性:
pod 亲和性和反亲和性
podAffinity 主要解决POD可以和哪些POD部署在同一个拓扑域中的问题(拓扑域用主机标签实现,可以是单个主机,也可以是多个主机组成的cluster、zone等。)
podAntiAffinity主要解决POD不能和哪些POD部署在同一个拓扑域中的问题。它们处理的是Kubernetes集群内部POD和POD之间的关系。
Pod 间亲和与反亲和在与更高级别的集合(例如 ReplicaSets,StatefulSets,Deployments 等)一起使用时,它们可能更加有用。可以轻松配置一组应位于相同定义拓扑(例如,节点)中的工作负载。
下线节点(在master端):
kubectl cordon server4 #禁用调度 kubectl drain server4 #驱离节点 kubectl drain server4 --ignore-daemonsets #强制驱离节点 kubectl delete nodes server4 #删除节点恢复节点(在slave端):
systemctl restart kubelet.service #重启kubelet服务
五、kubernetes访问控制
kubernetes API 访问控制:
分为三个阶段:认证、授权、访问控制
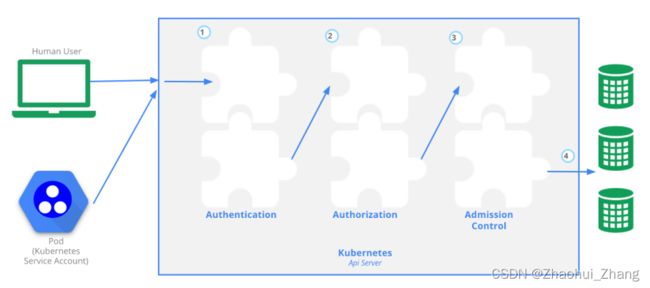
具体细节如下所示:
每个阶段任意一种方式通过即可进入下一阶段。

Authentication(认证)
认证方式现共有8种,可以启用一种或多种认证方式,只要有一种认证方式通过,就不再进行其它方式的认证。通常启用X509 Client Certs和Service Accout Tokens两种认证方式。
Kubernetes集群有两类用户:由Kubernetes管理的Service Accounts (服务账户)和(Users Accounts) 普通账户。k8s中账号的概念不是我们理解的账号,它并不真的存在,它只是形式上存在。
Authorization(授权)
必须经过认证阶段,才到授权请求,根据所有授权策略匹配请求资源属性,决定允许或拒绝请求。授权方式现共有6种,AlwaysDeny、AlwaysAllow、ABAC、RBAC、Webhook、Node。默认集群强制开启RBAC。
Admission Control(准入控制)
用于拦截请求的一种方式,运行在认证、授权之后,是权限认证链上的最后一环,对请求API资源对象进行修改和校验。
用户认证:
用户认证:
创建UserAccount:
# cd /etc/kubernetes/pki/
# openssl genrsa -out test.key 2048
# openssl req -new -key test.key -out test.csr -subj "/CN=test"
# openssl x509 -req -in test.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out test.crt -days 365
# openssl x509 -in test.crt -text -noout
$ kubectl config set-credentials test --client-certificate=/etc/kubernetes/pki/test.crt --client-key=/etc/kubernetes/pki/test.key --embed-certs=true
$ kubectl config view
$ kubectl config set-context test@kubernetes --cluster=kubernetes --user=test
$ kubectl config use-context test@kubernetes #切换为test用户身份
$ $ kubectl get pod
Error from server (Forbidden): pods is forbidden: User "test" cannot list resource "pods" in API group "" in the namespace "default"
此时用户通过认证,但还没有权限操作集群资源,需要继续添加授权。
用户授权:
RBAC(Role Based Access Control):基于角色访问控制授权。
允许管理员通过Kubernetes API动态配置授权策略。RBAC就是用户通过角色与权限进行关联。
RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可。
RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding。
RBAC的三个基本概念:
Subject:被作用者,它表示k8s中的三类主体, user, group, serviceAccount
Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
RoleBinding:定义了“被作用者”和“角色”的绑定关系。
Role 和 ClusterRole
Role是一系列的权限的集合,Role只能授予单个namespace 中资源的访问权限。 ClusterRole 跟 Role 类似,但是可以在集群中全局使用。
