腾讯云宋翔:Kubernetes集群利用率提升实践

嘉宾 | 宋翔
出品 | CSDN云原生
2022年7月7日,国内首次由信通院、腾讯云、FinOps 产业标准工作组联合策划的《原动力 x 云原生正发声 降本增效大讲堂》第三期直播上,腾讯云容器技术专家宋翔以“Kubernetes集群利用率提升实践”为主题,从利用率提升背景、常见集群负载优化思路以及负载提升及稳定性优化三个方面进行了详细分享。
宋翔负责腾讯超大规模自研业务上云的容器平台TKEx研发设计,将Docker、Kubernetes、Istio等云原生技术内部落地,助力腾讯QQ、在线教育、腾讯会议等海量业务的云原生容器化改造。本文整理自宋翔的分享。
![]()
利用率提升背景
利用率提升的大背景可以归纳为4个字——降本增效。通常来说,集群的利用率低会导致成本居高不下。集群、应用等配置,使用不合理,可能无法持续提升集群资源利用率,导致恶性循环。
资源不合理的原因主要有以下几点:
-
集群管理员无法准确评估集群规模
-
配置的集群Buffer不合理,Node资源冗余。
-
-
用户Pod资源配置不合理
-
Pod实际利用率低,配置要求高,导致集群调度满了,但利用率无法提升。
-
若想要深入探究集群低负载的原因,可以从两种情况着手分析。
情况1:Pod Resource Setting
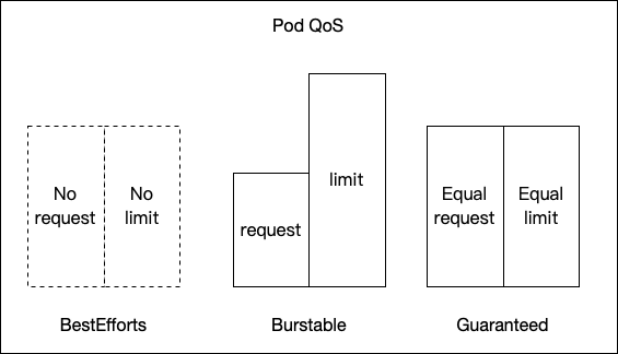
如上图所示,Pod QoS分级有三种。
-
BestEfforts模式下,Pod不设置Request值和Limit值。因为QoS优先级过低,所以在当前的实际应用场景中,几乎都不采用该设置模式。
-
Guaranteed模式要求用户设置相同的Request值与Limit值,虽然该模式具有较强的稳定性,但无法有效提升集群资源利用率。
-
最常使用的是Burstable模式,该模式下用户设置Request值与Limit值,同时要求Request值小于Limit值,通过二者数值的调整可以实现实际场景下利用率的提升。
情况2:Node分配Pod资源

一个Node节点具有一定的Capacity,实际上这些资源并不能够全部被Pod所使用。其中Node需要预留部分资源给操作系统和Kubelet。除此以外的Node剩余可调度资源可以提供给Pod进行调度。
通常情况下,Node节点上会剩余一些碎片资源,这些资源无法满足待调度Pod的要求,这便造成了节点资源的浪费。
通过以上两种情况,可以总结出造成节点资源不足的两个原因。
第一,节点Pod调度不充分。
-
集群Node资源常年冗余,Pod调度不充分;
-
少数HPA扩容场景时,Pod调度水位较高,但是日常又恢复低水位,导致日常预留Buffer过多。
第二,Pod设置不合理。
-
一般用户难以估算Request/Limit值;
-
用户更倾向过于保守的Request/Limit值;
-
为满足短暂(周期)峰值设置较高的Limit值;
-
不合理的镜像导致需要较大Request,进而导致Pod本身常年低负载。
![]()
常见集群负载优化方案思路
1. 用户篇
优化思路
第一,优化Pod配置。

-
利用历史数据进行Request、Limit调整;
-
用户在资源分析页面,利用Crane推荐值;
-
调整Pod类型为相对规整的资源类型;
-
优化程序和镜像。
第二,设置合理的HPA。
-
根据历史数据,推荐用户设置合理的HPA范围和阈值;
-
基于Crane EHPA算法修正HPA触发条件;
-
梯度扩容减少扩容频率,提高利用效率。
第三,设置合理的CronHPA。
-
对于周期性明显的业务,可以设置定时周期扩缩容;
-
在节假日、活动促销时,可以提前设置时间段扩容。
第四,根据用户的策略,设置适当的VPA。
腾讯医疗服务案例

从上图可以看出,上午时段流量上涨迅速且每周五具有HPV疫苗抢购活动,所以需要在该时段进行提前自动扩容设置。
同时,根据低峰期、高峰期、平峰期所需要的节点数(分别为2、18、8),用户可以结合HPA和CronHPA做简单的调整——将实例范围设置为2-30,CPU使用率达到Limit值的50%时触发策略。

通过以上一系列操作,相比未开始HPA时,成本可以有效减少60%,达到“降本”的目的。
2. 平台篇
优化思路
前面已提到,Node资源并不能够全部被Pod所使用,需要预留部分资源给操作系统和Kubelet,同时还会产生无法满足Pod调度要求的碎片资源。那么在这种情况下,该如何充分提高利用率呢?
第一,动态Pod压缩。

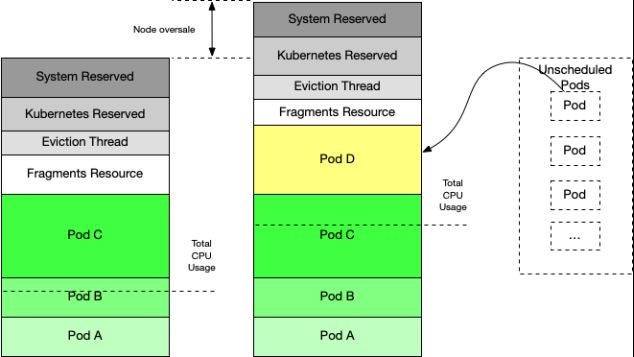
如上图所示,我们可以看到Pod被分配至节点A、B、C上,其中Pod A、Pod B的CPU Usage较低,这种情况下可以对Pod A、Pod B进行压缩,将其余待调度的Pod放置在该节点,以实现平均CPU负载提升的目的。
需要特别注意的是,在线业务没有优先级之分,每一个Pod都非常重要,不能因为其中某一个Pod占用多数资源或可能造成其他资源异常就对其进行驱逐。
同时,做资源压缩的前提是用户已设置Request值与Limit值,且二者初始值一般相等。这可以保证用户可使用的最大值不变,在对Request值进行压缩时,一个节点可以容纳更多的Pod。
此外,起初可以设置全局默认压缩比,随后可根据历史数据进行行态调试,以达到最佳值。
第二,Node节点超卖。
如上图所示,假设左侧节点为30核,若能通过一系列的手段让Kubelet、Kubernetes调度器认为该节点为60核,那是不是就能够调度更多的Pod呢?
该如何去做呢?分两个阶段:
-
设置全局默认超卖比;
-
根据历史数据、实时数据动态改变超卖比。

第三,碎片整理。
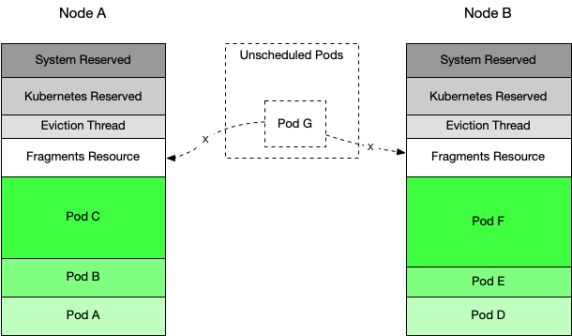
如上图,我们可以看到节点A、B的资源均不满足未调度Pod G的需求,且节点B中的Pod E可以调度到节点A中,腾挪空间。
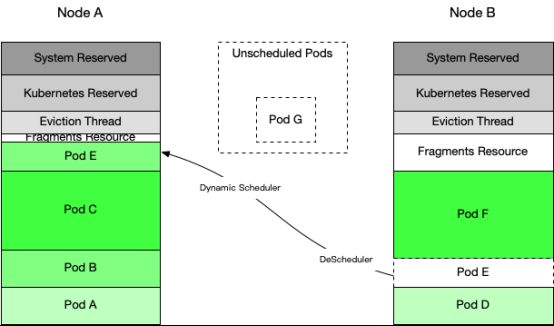

这种情况下,可以Pod E从节点B调度至节点A ,以此增加节点B的空闲资源来满足未调度的Pod G的需求。这就是碎片资源整理的过程。
第四,在离线混部。
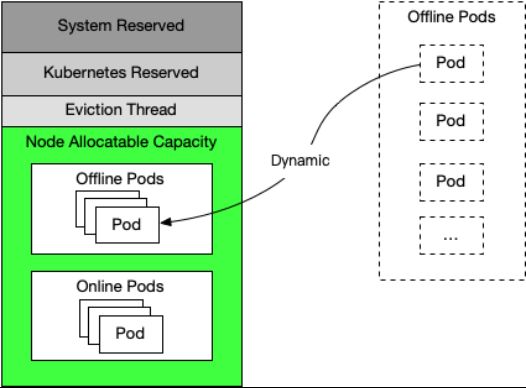
当平台规模较大或在线、离线业务均具有的情况下,一般都需要使用在离线混部的方式提升资源利用率。

其实现逻辑较为简单:当集群资源充足时,动态地将离线任务调度到空闲节点上;当节点资源接近高负载阈值时,优先驱逐离线任务。
![]()
负载提升和稳定性优化
通过各种手段提升集群利用率的同时,也会带来相应的负面问题:
-
引起Node节点高负载,影响服务质量;
-
Node节点负载不均;
-
剩余剩余资源不足导致Pod 横向度失败。
针对以上负面问题,通常需要使用扩容及稳定性相关的手段来解决。
第一,两级扩容机制。
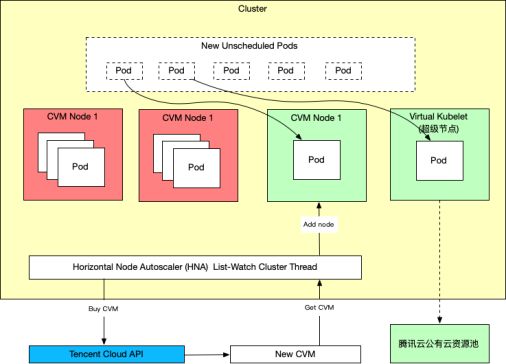
-
HNA: 当集群负载(装箱率)达到阈值(如85%)时,会触发节点自动扩缩容,来增加Node节点;
-
超级节点:当工作负载引发大量扩容、集群资源不足而导致Pod突增时,利用超级节点(通过Virtual Kubelet加入集群的虚拟Node)直接将Pod扩容到Virtual Kubelet节点上,超级节点的底层直接使用腾讯云公有云资源池创建弹性Pod。
第二,两级动态超卖。

通常情况况下,Pod压缩与Node超卖两种手段需同时使用。Pod压缩已实现从静态到动态的优化,其压缩比(Request/limit)可以根据历史状态进行动态修改。
同样,Node超卖也实现了由静态向动态的升级,Node节点可以根据实时负载进行动态调整,以防止节点负载过高。
第三,动态调度。
动态调度机制可以实现保证Node节点的资源均衡,避免不同Node节点负载不均的现象。
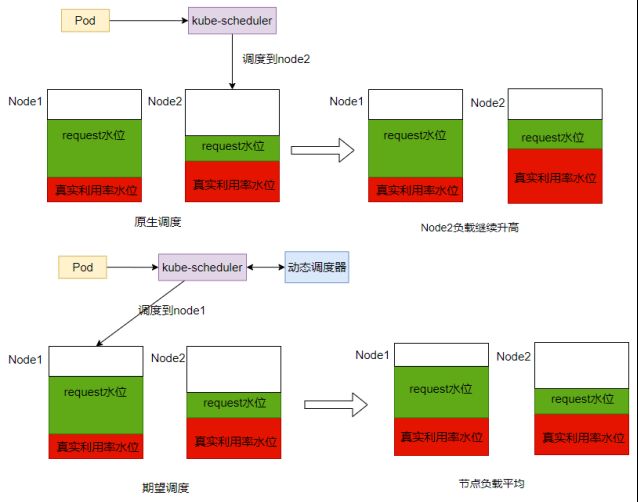
上图可以看到,原生调度为静态调度且Node2空闲资源较多,那么根据静态调度策略,会将新的Pod调度到Node2节点中。但经过动态调度的算法优化,实际上会将Pod调度到Node1节点上,这是什么原因呢?
这是因为Node1节点的真是利用率更低所致的,将Pod调度至Node1上会提高Node的Pod利用率,进而使各节点的平均负载相近。

上图是动态调度机制的原理,Extend NodeScorer会根据不同时段的信息参数对Node进行打分,Kube-scheduler调度器可获取这些参数信息进而将新增Pod调度至实际内存使用更低的节点上。
第四,动态驱逐。

当Node负载不均或Node利用率过高时,大概率会对节点上运行的Pod资源产生影响。这种情况下,我们可以根据节点当前的状态信息以及节点上Pod的实际利用率对Pod进行动态驱逐。这里的参考维度是多样的,一般包括:CPU、Memory、FD、Inode等,且不同业务针对参数的权重与指标也存在差异。
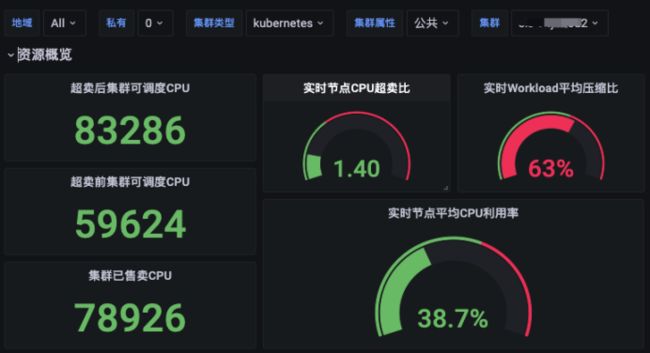
上图是某一在线业务集群的状态,可以清晰看到在经过超卖及压缩后,该集群的节点平均利用率可达38.7%。

节点负载分布(未采用动态调度及动态驱逐)

节点负载分布(采用动态调度及动态驱逐)
通过以上两图对比,我们可以看到:在未采用动态调度及动态驱逐时,节点负载不均衡同时方差值较大。而在采用了动态调度及动态驱逐后,节点负载便会趋于稳定,异常Node数目减少,资源利用率得到有效提高。
![]()
总结
本文结合腾讯应用实践,分享了Kubernetes集群利用率提升的思路和实现方式,包括两级扩容机制、两级动态超卖、动态调度、动态驱逐。欢迎一起交流。
【原动力×云原生正发声降本增效大讲堂】第二期聚焦全场景在离线混部、K8s GPU资源效率提升、K8s资源拓扑感知调度主题,分别在7月28日、8月4日、8月11日晚20:00-21:00进行。点击『此处』进入活动专题,带你体验云原生降本增效实践案例、了解如何解决企业用云痛点、掌握降本增效关键技能……