【聚类2】原型聚类
文章目录
- 1. 原型聚类
-
- 1.1 k均值算法(K-Means)
-
- 1.1.1 最小化平方误差
- 1.1.2 k均值算法伪代码
- 1.2 学习向量量化
-
- 1.2.2 学习向量量化算法伪代码
- 1.2.4 如何更新原型向量(原型向量更新原则)
- 1.3 高斯混合聚类
-
- 1.3.2 高斯分布
- 1.3.3 贝叶斯公式
- 1.3.4 概率密度函数(多元高斯分布的一般形式)
- 1.3.5 高斯混合分布(全概率公式)
- 1.3.7 极大释然估计
- 1.3.8 高斯混合分布公式,模型参数 { ( α i , μ i , Σ i ) ∣ 1 ≤ i ≤ k } \{(\alpha_i,\mu_i,Σ_i)|1\leq i\leq k\} {(αi,μi,Σi)∣1≤i≤k}的求解
- 1.3.9 高斯混合聚类算法伪代码
1. 原型聚类
概念
- "原型:"
"原型"是指样本空间中具有代表性的点。
- "别名:"
1)基于原型的聚类
2)英文:prototype-based clustering
- "此类算法的原理:"
算法先对原型进行初始化,然后对原型进行迭代更新求解
- "常见的原型聚类算法:"
1. k均值算法(k-means)
2. 学习向量量化(LVQ)
3. 高斯混合聚类
算法讲解
1.1 k均值算法(K-Means)
1.1.1 最小化平方误差
概 念 : 概念: 概念:
\ \ \ \ \ \ \ \ \ \ {} 刻 画 了 簇 内 样 本 围 绕 簇 均 值 向 量 的 紧 密 程 度 , 值 越 小 则 簇 内 样 本 相 似 度 越 高 刻画了簇内样本围绕簇均值向量的紧密程度,值越小则簇内样本相似度越高 刻画了簇内样本围绕簇均值向量的紧密程度,值越小则簇内样本相似度越高
前 提 : 前提: 前提:
\ \ \ \ \ \ \ \ \ \ {} 样 本 集 D = { x 1 , x 2 , . . . , x m } 样本集D=\{x_1,x_2,...,x_m\} 样本集D={x1,x2,...,xm}
\ \ \ \ \ \ \ \ \ \ {} 簇 划 分 C = { C 1 , C 2 , . . . , C k } 簇划分C=\{C_1,C_2,...,C_k\} 簇划分C={C1,C2,...,Ck}
\ \ \ \ \ \ \ \ \ \ {} 簇 C i 的 均 值 向 量 : u i = 1 ∣ C i ∣ ∑ x ∈ C i x 簇C_i的均值向量:u_i=\frac{1}{|C_i|}\sum_{x\in C_i}x 簇Ci的均值向量:ui=∣Ci∣1∑x∈Cix
公 式 : 公式: 公式:
\ \ \ \ \ \ \ \ \ \ {} E = ∑ i = 1 k ∑ x ∈ C i ∣ ∣ x − u i ∣ ∣ 2 2 E=\sum_{i=1}^k\sum_{x\in C_i}||x-u_i||_2^2 E=∑i=1k∑x∈Ci∣∣x−ui∣∣22
最 优 解 : 最优解: 最优解:
\ \ \ \ \ \ \ \ \ \ {} 最 小 化 E 不 好 求 : 最 优 解 需 考 察 样 本 集 所 有 可 能 的 簇 划 分 ( N P 问 题 ) 最小化E不好求:最优解需考察样本集 所有可能的簇划分(NP问题) 最小化E不好求:最优解需考察样本集所有可能的簇划分(NP问题)
\ \ \ \ \ \ \ \ \ \ {} N P 问 题 : 找 一 个 解 很 困 难 , 但 验 证 一 个 解 很 容 易 ( 片 面 理 解 哈 ) NP问题:找一个解很困难,但验证一个解很容易(片面理解哈) NP问题:找一个解很困难,但验证一个解很容易(片面理解哈)
迭 代 法 : 迭代法: 迭代法:
\ \ \ \ \ \ \ \ \ \ {} k 均 值 算 法 采 用 了 贪 心 策 略 , 通 过 “ 迭 代 优 化 ” 来 近 似 求 解 k均值算法采用了贪心策 略,通过“迭代优化”来近似求解 k均值算法采用了贪心策略,通过“迭代优化”来近似求解
1.1.2 k均值算法伪代码
输 入 : 输入: 输入:
\ \ \ \ \ \ \ \ \ \ {} 样 本 集 D = x 1 , x 2 , . . . , x m 样本集D = {x_1,x_2,...,x_m} 样本集D=x1,x2,...,xm
\ \ \ \ \ \ \ \ \ \ {} 聚 类 簇 数 k 聚类簇数k 聚类簇数k
过 程 : 过程: 过程:
\ \ \ \ \ \ \ \ \ \ {} 从 D 中 随 机 选 择 k 个 样 本 作 为 初 始 均 值 变 量 u 1 , u 2 , . . . , u k 从D中随机选择k个样本作为初始均值变量{u_1,u_2,...,u_k} 从D中随机选择k个样本作为初始均值变量u1,u2,...,uk
\ \ \ \ \ \ \ \ \ \ {} r e p e a t repeat repeat
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 令 C i = ∅ ( 1 ≤ i ≤ k ) 令Ci = \emptyset (1\leq i\le k) 令Ci=∅(1≤i≤k)
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} f o r j = 1 , 2 , . . . , m d o for\ j = 1,2,...,m\ do for j=1,2,...,m do
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 计 算 样 本 x j 与 各 均 值 向 量 u i ( 1 ≤ i ≤ k ) 的 距 离 : d j i = ∣ ∣ x j − u i ∣ ∣ 2 ; 计算样本x_j与各均值向量u_i(1\leq i\le k)的距离:d_{ji}=||x_j-u_i||_2; 计算样本xj与各均值向量ui(1≤i≤k)的距离:dji=∣∣xj−ui∣∣2;
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 根 据 距 离 最 近 的 均 值 向 量 确 定 x j 的 簇 标 记 : λ j = m i n i ∈ { 1 , 2 , . . . , k } d j i 根据距离最近的均值向量确定x_j的簇标记:\lambda_j=min_{i\in\{1,2,...,k\}}d_{ji} 根据距离最近的均值向量确定xj的簇标记:λj=mini∈{1,2,...,k}dji
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 将 样 本 x j 划 入 相 应 的 簇 : C λ j = C λ j ⋃ { x j } 将样本x_j划入相应的簇:C_{\lambda_j}=C_{\lambda_j}\bigcup\{x_j\} 将样本xj划入相应的簇:Cλj=Cλj⋃{xj}
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} e n d f o r end\ for end for
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} f o r i = 1 , 2 , . . . , k d o for\ i=1,2,...,k\ do for i=1,2,...,k do
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 计 算 新 均 值 向 量 : u i ′ = 1 ∣ C i ∣ ∑ x i ∈ C i x 计算新均值向量:u'_i=\frac{1}{|C_i|}\sum_{x_i\in C_i}x 计算新均值向量:ui′=∣Ci∣1∑xi∈Cix
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} i f u i ′ ≠ u i t h e n if\ u'_i\neq u_i\ then if ui′=ui then
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 将 当 前 均 值 向 量 u i 更 新 为 u i ′ 将当前均值向量u_i更新为u'_i 将当前均值向量ui更新为ui′
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} e l s e else else
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 保 持 当 前 均 值 向 量 不 变 保持当前均值向量不变 保持当前均值向量不变
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} e n d i f end\ if end if
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} e n d f o r end\ for end for
\ \ \ \ \ \ \ \ \ \ {} until
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 当前均值向量均未更新
输 出 : 输出: 输出:
\ \ \ \ \ \ \ \ \ \ {} 簇划分C = {C1,C2,…,Ck}
- 1.1.3 k均值算法注意
- "最大运行轮数" + "最小调整幅度"
1)为避免运行时间过长,通常设置一个"最大运行轮数"
或"最小调整幅度",
2)若达到最大轮数或调整幅度小于阂值,则停止运行.
- 1.1.4 k-means聚类的缺点
- "2维k-means模型:"
1)以每个簇的中心为圆心,簇中点到簇中心点的欧氏距离最大值为半径画一个圆。
2)k-means要求这些簇的形状必须是圆形的。
3)k-means模型拟合出来的簇(圆形)与实际数据分布(可能是椭圆)差别很大。
4)应用中缺少鲁棒性(在异常和危险情况下系统生存的能力)。
- 1.1.5 k均值算法例子
【D】

【k = 3】
【步骤】
第 一 步 : 随 机 选 择 第一步:随机选择 第一步:随机选择
算 法 开 始 时 随 机 选 取 三 个 样 本 x 6 , x 12 , x 27 \ \ \ \ \ \ \ \ \ \ \ 算法开始时随机选取三个样本x_6,x_{12},x_{27} 算法开始时随机选取三个样本x6,x12,x27
即 , u 1 = ( 0.403 ; 0.237 ) , u 2 = ( 0.343 ; 0.099 ) , u 3 = ( 0.532 ; 0.472 ) \ \ \ \ \ \ \ \ \ \ \ 即,u_1=(0.403;0.237),u_2=(0.343;0.099),u_3=(0.532;0.472) 即,u1=(0.403;0.237),u2=(0.343;0.099),u3=(0.532;0.472)
第 二 步 : 考 察 样 本 第二步:考察样本 第二步:考察样本
例 : x 1 = ( 0.697 ; 0.460 ) \ \ \ \ \ \ \ \ \ \ \ 例:x_1=(0.697;0.460) 例:x1=(0.697;0.460)
一 般 用 欧 式 距 离 \ \ \ \ \ \ \ \ \ \ \ 一般用欧式距离 一般用欧式距离
d 1 = ∑ i = 1 2 ∣ ∣ x 1 i − u 1 i ∣ ∣ 2 \ \ \ \ \ \ \ \ \ \ \ d_1=\sum_{i=1}^2||x_{1i}-u_{1i}||_2 d1=∑i=12∣∣x1i−u1i∣∣2
d 1 = ( 0.697 − 0.403 ) 2 + ( 0.460 − 0.237 ) 2 = 0.369 \ \ \ \ \ \ \ \ \ \ \ d_1=\sqrt{(0.697-0.403)^2+(0.460-0.237)^2}=0.369 d1=(0.697−0.403)2+(0.460−0.237)2=0.369
d 2 = ( 0.697 − 0.343 ) 2 + ( 0.460 − 0.099 ) 2 = 0.506 \ \ \ \ \ \ \ \ \ \ \ d_2=\sqrt{(0.697-0.343)^2+(0.460-0.099)^2}=0.506 d2=(0.697−0.343)2+(0.460−0.099)2=0.506
d 3 = ( 0.697 − 0.532 ) 2 + ( 0.460 − 0.472 ) 2 = 0.166 \ \ \ \ \ \ \ \ \ \ \ d_3=\sqrt{(0.697-0.532)^2+(0.460-0.472)^2}=0.166 d3=(0.697−0.532)2+(0.460−0.472)2=0.166
因 此 x 1 将 划 入 簇 C 3 中 \ \ \ \ \ \ \ \ \ \ \ 因此x_1将划入簇C_3中 因此x1将划入簇C3中
第 三 步 : 划 分 样 本 第三步:划分样本 第三步:划分样本
C 1 = { x 5 , x 6 , x 7 , x 8 , x 9 , x 10 , x 13 , x 14 , x 15 , x 17 , x 18 , x 19 , x 20 , x 23 } \ \ \ \ \ \ \ \ \ \ \ C_1=\{x_5,x_6,x_7,x_8,x_9,x_{10},x_{13},x_{14},x_{15},x_{17},x_{18},x_{19},x_{20},x_{23}\} C1={x5,x6,x7,x8,x9,x10,x13,x14,x15,x17,x18,x19,x20,x23}
C 2 = { x 11 , x 12 , x 16 } \ \ \ \ \ \ \ \ \ \ \ C_2=\{x_{11},x_{12},x_{16}\} C2={x11,x12,x16}
C 3 = { x 1 , x 2 , x 3 , x 4 , x 21 , x 22 , x 24 , x 25 , x 26 , x 27 , x 28 , x 29 , x 30 } \ \ \ \ \ \ \ \ \ \ \ C_3=\{x_1,x_2,x_3,x_4,x_{21},x_{22},x_{24},x_{25},x_{26},x_{27},x_{28},x_{29},x_{30}\} C3={x1,x2,x3,x4,x21,x22,x24,x25,x26,x27,x28,x29,x30}
第 四 步 : 更 新 均 值 向 量 第四步:更新均值向量 第四步:更新均值向量
公 式 : u i ′ = 1 ∣ C i ∣ ∑ x ∈ C i x \ \ \ \ \ \ \ \ \ \ \ 公式:u'_i=\frac{1}{|C_i|}\sum_{x\in C_i}x 公式:ui′=∣Ci∣1∑x∈Cix
u 1 ′ = 1 14 ∑ x ∈ C 1 x \ \ \ \ \ \ \ \ \ \ \ u'_1=\frac{1}{14}\sum_{x\in C_1}x u1′=141∑x∈C1x
u 1 ′ = 1 14 ∗ [ ( 0.556 ; 0.215 ) + ( 0.403 ; 0.237 ) + ( 0.481 ; 0.149 ) + ( 0.437 ; 0.211 ) + ( 0.666 ; 0.091 ) + ( 0.243 ; 0.267 ) + ( 0.639 ; 0.161 ) + ( 0.657 ; 0.198 ) + ( 0.360 ; 0.370 ) + ( 0.719 ; 0.103 ) + ( 0.359 ; 0.188 ) + ( 0.339 ; 0.241 ) + ( 0.282 ; 0.257 ) + ( 0.483 ; 0.312 ) ] = ( 0.473 ; 0.214 ) \ \ \ \ \ \ \ \ \ \ \ u'_1=\frac{1}{14}*[(0.556;0.215)+(0.403;0.237)+(0.481;0.149)+(0.437;0.211)+(0.666;0.091)+(0.243;0.267)+(0.639;0.161)+(0.657;0.198)+(0.360;0.370)+(0.719;0.103)+(0.359;0.188)+(0.339;0.241)+(0.282;0.257)+(0.483;0.312)]=(0.473;0.214) u1′=141∗[(0.556;0.215)+(0.403;0.237)+(0.481;0.149)+(0.437;0.211)+(0.666;0.091)+(0.243;0.267)+(0.639;0.161)+(0.657;0.198)+(0.360;0.370)+(0.719;0.103)+(0.359;0.188)+(0.339;0.241)+(0.282;0.257)+(0.483;0.312)]=(0.473;0.214)
u 2 ′ = 1 3 ∑ x ∈ C 2 x = ( 0.394 , 0.066 ) \ \ \ \ \ \ \ \ \ \ \ u'_2=\frac{1}{3}\sum_{x\in C_2}x=(0.394,0.066) u2′=31∑x∈C2x=(0.394,0.066)
u 3 ′ = 1 13 ∑ x ∈ C 3 x = ( 0.623 , 0.388 ) \ \ \ \ \ \ \ \ \ \ \ u'_3=\frac{1}{13}\sum_{x\in C_3}x=(0.623,0.388) u3′=131∑x∈C3x=(0.623,0.388)
因 为 u i ′ ≠ u ′ , 所 以 更 新 均 值 向 量 \ \ \ \ \ \ \ \ \ \ \ 因为u'_i \neq u',所以更新均值向量 因为ui′=u′,所以更新均值向量
第 五 步 : 重 复 , 当 簇 划 分 C i 相 同 时 , 停 止 第五步:重复,当簇划分C_i相同时,停止 第五步:重复,当簇划分Ci相同时,停止
1.2 学习向量量化
- 1.2.1 概念
"英文:"
Learning Vector Quantization,简称LVQ
"原理:"
1)与k均值算法类似,也是试图找到一组原型向量来刻画聚类结构
2)LVQ假设数据样本带有类别标记,学习过程中利用这些监督信息来辅助聚类
"数学描述:"
给定样本集D={(x1,y1),...,(xm,ym)},
每个样本(xj),有n个属性描述的特征向量(xj1,xj2,...,xjn),
样本的标记(yj)。
"LVQ的目标:"
学得一组n维原型向量{p1,p2,...,pn},每个原型向量代表一个聚类簇,簇标记ti属于y
1.2.2 学习向量量化算法伪代码
输 入 : 输入: 输入:
\ \ \ \ \ \ \ \ \ \ {} 样 本 集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) } 样本集D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\} 样本集D={(x1,y1),(x2,y2),...,(xm,ym)}
\ \ \ \ \ \ \ \ \ \ {} 原 型 向 量 个 数 q , 各 原 型 向 量 预 设 的 类 别 标 记 t 1 , t 2 , . . . , t q 原型向量个数q,各原型向量预设的类别标记{t_1,t_2,...,t_q} 原型向量个数q,各原型向量预设的类别标记t1,t2,...,tq
\ \ \ \ \ \ \ \ \ \ {} 学 习 率 η ∈ ( 0 , 1 ) 学习率\ \eta\in (0,1) 学习率 η∈(0,1)
过 程 : 过程: 过程:
\ \ \ \ \ \ \ \ \ \ {} 初 始 化 一 组 原 型 向 量 { p 1 , p 2 , . . . , p q } 初始化一组原型向量\{p_1,p_2,...,p_q\} 初始化一组原型向量{p1,p2,...,pq}
\ \ \ \ \ \ \ \ \ \ {} r e p e a t repeat repeat
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 从 样 本 集 D 中 随 机 选 取 样 本 ( x j , y j ) 从样本集D中随机选取样本(x_j,y_j) 从样本集D中随机选取样本(xj,yj)
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 计 算 样 本 x j 与 p i ( 1 ≤ i ≤ q ) 的 距 离 : d j i = ∣ ∣ x j − p i ∣ ∣ 2 计算样本x_j与p_i(1\leq i\leq q)的距离:dji = ||x_j-p_i||_2 计算样本xj与pi(1≤i≤q)的距离:dji=∣∣xj−pi∣∣2
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 找 出 与 x j 距 离 最 近 的 原 型 向 量 p i ∗ , i ∗ = a r g m i n i ∈ { 1 , 2 , . . . , q } d j i 找出与x_j距离最近的原型向量p_{i^*},i^*=arg\ min_{i\in \{1,2,...,q\}}dji 找出与xj距离最近的原型向量pi∗,i∗=arg mini∈{1,2,...,q}dji
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} i f y j = t i ∗ t h e n if\ y_j=t_{i^*}\ then if yj=ti∗ then
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} p ′ = p i ∗ + η ( x j − p i ∗ ) p'=p_{i^*}+\eta(x_j-p_{i^*}) p′=pi∗+η(xj−pi∗)
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} e l s e else else
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} p ′ = p i ∗ − η ( x j − p i ∗ ) p'=p_{i^*}-\eta(x_j-p_{i^*}) p′=pi∗−η(xj−pi∗)
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} e n d i f end\ if end if
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 将 原 型 向 量 p i ∗ 更 新 为 p ′ 将原型向量p_{i^*}更新为p' 将原型向量pi∗更新为p′
\ \ \ \ \ \ \ \ \ \ {} u n t i l 满 足 停 止 条 件 : 最 大 轮 转 数 或 最 小 调 整 幅 度 until\ 满足停止条件:最大轮转数或最小调整幅度 until 满足停止条件:最大轮转数或最小调整幅度
输 出 : 输出: 输出:
\ \ \ \ \ \ \ \ \ \ {} 原 型 向 量 { p 1 , p 2 , . . . , p q } 原型向量\{p_1,p_2,...,p_q\} 原型向量{p1,p2,...,pq}
- 1.2.3 学习向量量化算法注意
"原理:"
算法对原型向量进行迭代优化。
"过程:"
1)在每一轮选代中,算法随机选取一个有标记训练样本。
2)找出与其距离最近的原型向量。
3)更新原型变量。
"更新原理:"
根据两者的"类别标记是否一致"来对原型向量进行相应的更新。
1.2.4 如何更新原型向量(原型向量更新原则)
一 、 对 样 本 x j , 若 最 近 的 原 型 向 量 p i ∗ 与 x j 的 类 别 标 记 相 同 , 则 让 p i ∗ 向 x j 的 方 向 靠 拢 。 一、对样本x_j,若最近的原型向量p_{i^*}与x_j的类别标记相同,则让p_{i^*}向x_j的方向靠拢。 一、对样本xj,若最近的原型向量pi∗与xj的类别标记相同,则让pi∗向xj的方向靠拢。
\ \ \ \ \ \ \ \ \ \ {} 新 原 型 向 量 : 新原型向量: 新原型向量:
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} p ′ = p i ∗ + η ( x j − p i ∗ ) , p'=p_{i^*}+\eta(x_j-p_{i^*}), p′=pi∗+η(xj−pi∗),
\ \ \ \ \ \ \ \ \ \ {} p ′ 与 x j 之 间 的 距 离 为 : p'与x_j之间的距离为: p′与xj之间的距离为:
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} ∣ ∣ p ′ − x j ∣ ∣ 2 = ∣ ∣ p i ∗ + η ( x j − p i ∗ ) − x j ∣ ∣ 2 ||p'-x_j||_2=||p_{i^*}+\eta(x_j-p_{i^*})-x_j||_2 ∣∣p′−xj∣∣2=∣∣pi∗+η(xj−pi∗)−xj∣∣2
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ \ \ {} = ( 1 − η ) ∣ ∣ p i ∗ − x j ∣ ∣ 2 =(1-\eta)||p_{i^*}-x_j||_2 =(1−η)∣∣pi∗−xj∣∣2
\ \ \ \ \ \ \ \ \ \ {} 令 学 习 率 η ∈ ( 0 , 1 ) : 令学习率\eta\in (0,1): 令学习率η∈(0,1):
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 则 原 型 向 量 p i ∗ , 在 更 新 为 p ′ 之 后 , 将 更 接 近 x j 则原型向量p_{i^*},在更新为p'之后,将更接近x_j 则原型向量pi∗,在更新为p′之后,将更接近xj
{}
{}
二 、 对 样 本 x j , 若 最 近 的 原 型 向 量 p i ∗ 与 x j 的 类 别 标 记 不 同 , 则 让 p i ∗ 向 x j 的 方 向 远 离 。 二、对样本x_j,若最近的原型向量p_{i^*}与x_j的类别标记不同,则让p_{i^*}向x_j的方向远离。 二、对样本xj,若最近的原型向量pi∗与xj的类别标记不同,则让pi∗向xj的方向远离。
\ \ \ \ \ \ \ \ \ \ {} 新 原 型 向 量 : 新原型向量: 新原型向量:
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} p ′ = p i ∗ − η ( x j − p i ∗ ) , p'=p_{i^*}-\eta(x_j-p_{i^*}), p′=pi∗−η(xj−pi∗),
\ \ \ \ \ \ \ \ \ \ {} p ′ 与 x j 之 间 的 距 离 为 : p'与x_j之间的距离为: p′与xj之间的距离为:
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} ∣ ∣ p ′ − x j ∣ ∣ 2 = ∣ ∣ p i ∗ + η ( x j − p i ∗ ) − x j ∣ ∣ 2 ||p'-x_j||_2=||p_{i^*}+\eta(x_j-p_{i^*})-x_j||_2 ∣∣p′−xj∣∣2=∣∣pi∗+η(xj−pi∗)−xj∣∣2
\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ \ \ {} = ( 1 + η ) ∣ ∣ p i ∗ − x j ∣ ∣ 2 =(1+\eta)||p_{i^*}-x_j||_2 =(1+η)∣∣pi∗−xj∣∣2
\ \ \ \ \ \ \ \ \ \ {} 令 学 习 率 η ∈ ( 0 , 1 ) : 令学习率\eta\in (0,1): 令学习率η∈(0,1):
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 则 原 型 向 量 p i ∗ , 在 更 新 为 p ′ 之 后 , 将 更 远 离 x j 则原型向量p_{i^*},在更新为p'之后,将更远离x_j 则原型向量pi∗,在更新为p′之后,将更远离xj
- 1.2.5 Voronoi 剖分(Voronoi Tessellation)
已 知 : 已知: 已知:
\ \ \ \ \ \ \ \ \ \ {} 在 学 得 一 组 原 型 向 量 { p 1 , p 2 , . . . , p q } 后 , 即 可 实 现 对 样 本 空 间 X 的 簇 划 分 在学得一组原型向量\{p_1,p_2,...,p_q\}后,即可实现对样本空间X的簇划分 在学得一组原型向量{p1,p2,...,pq}后,即可实现对样本空间X的簇划分
结 论 : 结论: 结论:
\ \ \ \ \ \ \ \ \ \ {} 对 任 意 样 本 x , 它 将 被 划 入 与 其 距 离 最 近 的 原 型 向 量 所 代 表 的 簇 中 对任意样本x,它将被划入与其距离最近的原型向量所代表的簇中 对任意样本x,它将被划入与其距离最近的原型向量所代表的簇中
换 言 之 : 换言之: 换言之:
\ \ \ \ \ \ \ \ \ \ {} 每 个 原 型 向 量 p i 定 义 了 与 之 相 关 的 一 个 区 域 R i , 每个原型向量p_i定义了与之相关的一个区域R_i, 每个原型向量pi定义了与之相关的一个区域Ri,
\ \ \ \ \ \ \ \ \ \ {} 该 区 域 中 每 个 样 本 与 p i 的 距 离 不 大 于 它 与 其 他 原 型 向 量 p i ′ ( i ′ ≠ i ) 的 距 离 。 该区域中每个样本与 p_i的距离不大于它与其他原型向量p_{i'}(i'\neq i)的距离。 该区域中每个样本与pi的距离不大于它与其他原型向量pi′(i′=i)的距离。
数 学 描 述 : 数学描述: 数学描述:
\ \ \ \ \ \ \ \ \ \ {} R i = { x ∈ X ∣ ∣ ∣ x − p i ∣ ∣ 2 ≤ ∣ ∣ x − p i ′ ∣ ∣ 2 , i ′ ≠ i } R_i=\{x\in X|\ ||x-p_i||_2\leq||x-p_{i'}||_2,i'\neq i\} Ri={x∈X∣ ∣∣x−pi∣∣2≤∣∣x−pi′∣∣2,i′=i}
V o r o n o i 剖 分 : Voronoi剖分: Voronoi剖分:
\ \ \ \ \ \ \ \ \ \ {} 对 样 本 空 间 X 的 簇 划 分 { R 1 , R 2 , . . . , R q } , 该 划 分 通 常 称 为 ′ ′ V o r o n o i 剖 分 ′ ′ 对样本空间X的簇划分\{R_1,R_2,...,R_q\},该划分通常称为''Voronoi剖分'' 对样本空间X的簇划分{R1,R2,...,Rq},该划分通常称为′′Voronoi剖分′′
- 1.2.6 学习向量量化算法例子
【D】
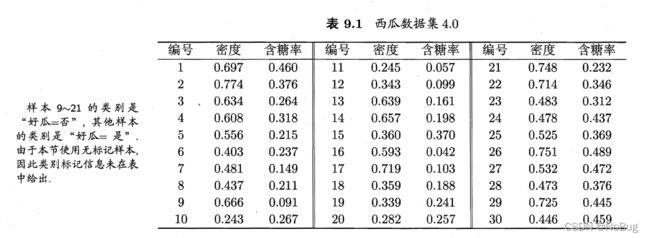
【q = 5】
即,学习目标找到5个原型向量 p 1 , p 2 , p 3 , p 4 , p 5 p_1,p_2,p_3,p_4,p_5 p1,p2,p3,p4,p5
令,其对应的类别标记分别为 c 1 , c 2 , c 3 , c 4 , c 5 c_1,c_2,c_3,c_4,c_5 c1,c2,c3,c4,c5
【 η = 0.1 \eta=0.1 η=0.1】
【步骤】
第 一 步 : 原 型 向 量 随 机 初 始 化 第一步:原型向量随机初始化 第一步:原型向量随机初始化
\ \ \ \ \ \ \ \ \ \ {} 根 据 样 本 的 类 别 标 记 和 簇 的 预 设 类 别 标 记 对 原 型 向 量 进 行 随 机 初 始 化 根据样本的类别标记和簇的预设类别标记对原型向量进行随 机初始化 根据样本的类别标记和簇的预设类别标记对原型向量进行随机初始化
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 假 定 初 始 化 为 样 本 : { x 5 , x 12 , x 18 , x 23 , x 29 } 假定初始化为样本:\{x_5,x_{12},x_{18},x_{23},x_{29}\} 假定初始化为样本:{x5,x12,x18,x23,x29}
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} 对 应 的 原 型 向 量 为 : { p 1 , p 2 , p 3 , p 4 , p 5 } 对应的原型向量为:\{p_1,p_2,p_3,p_4,p_5\} 对应的原型向量为:{p1,p2,p3,p4,p5}
第 二 步 : 随 机 选 取 样 本 第二步:随机选取样本 第二步:随机选取样本
\ \ \ \ \ \ \ \ \ \ {} 例 如 : x 1 = ( 0.697 ; 0.460 ) 例如:x_1=(0.697;0.460) 例如:x1=(0.697;0.460)
第 三 步 : 计 算 该 样 本 与 原 型 向 量 的 距 离 第三步:计算该样本与原型向量的距离 第三步:计算该样本与原型向量的距离
\ \ \ \ \ \ \ \ \ \ {} d 1 , 5 = ∣ ∣ x 1 − x 5 ∣ ∣ 2 = ( 0.697 − 0.556 ) 2 + ( 0.460 − 0.215 ) 2 = 0.283 d_{1,5}=||x_1-x_5||_2=\sqrt{(0.697-0.556)^2+(0.460-0.215)^2}=0.283 d1,5=∣∣x1−x5∣∣2=(0.697−0.556)2+(0.460−0.215)2=0.283
\ \ \ \ \ \ \ \ \ \ {} d 1 , 12 = ∣ ∣ x 1 − x 12 ∣ ∣ 2 = 0.506 d_{1,12}=||x_1-x_{12}||_2=0.506 d1,12=∣∣x1−x12∣∣2=0.506
\ \ \ \ \ \ \ \ \ \ {} d 1 , 18 = ∣ ∣ x 1 − x 18 ∣ ∣ 2 = 0.434 d_{1,18}=||x_1-x_{18}||_2=0.434 d1,18=∣∣x1−x18∣∣2=0.434
\ \ \ \ \ \ \ \ \ \ {} d 1 , 23 = ∣ ∣ x 1 − x 23 ∣ ∣ 2 = 0.260 d_{1,23}=||x_1-x_{23}||_2=0.260 d1,23=∣∣x1−x23∣∣2=0.260
\ \ \ \ \ \ \ \ \ \ {} d 1 , 29 = ∣ ∣ x 1 − x 29 ∣ ∣ 2 = 0.032 d_{1,29}=||x_1-x_{29}||_2=0.032 d1,29=∣∣x1−x29∣∣2=0.032
第 四 步 : 更 新 原 型 向 量 第四步:更新原型向量 第四步:更新原型向量
\ \ \ \ \ \ \ \ \ \ {} L V Q 更 新 p 5 得 到 新 原 型 向 量 LVQ更新p_5得到新原型向量 LVQ更新p5得到新原型向量
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} p ′ = p 5 + η ( x 1 − p 5 ) p'=p5+\eta(x_1-p_5) p′=p5+η(x1−p5)
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} p ′ = x 29 + η ( x 1 − x 29 ) p'=x_{29}+\eta(x_1-x_{29}) p′=x29+η(x1−x29)
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} p ′ = ( 0.725 ; 0.445 ) + 0.1 ∗ ( ( 0.697 ; 0.460 ) − ( 0.725 ; 0.445 ) ) p'=(0.725;0.445)+0.1*((0.697;0.460)-(0.725;0.445)) p′=(0.725;0.445)+0.1∗((0.697;0.460)−(0.725;0.445))
\ \ \ \ \ \ \ \ \ \ {} \ \ \ \ \ \ \ \ \ \ {} p ′ = ( 0.722 ; 0.442 ) p'=(0.722;0.442) p′=(0.722;0.442)
第 五 步 : 重 复 操 作 , 可 以 设 置 最 大 轮 转 数 或 最 小 幅 度 第五步:重复操作,可以设置最大轮转数或最小幅度 第五步:重复操作,可以设置最大轮转数或最小幅度
1.3 高斯混合聚类
- 1.3.1 概念
- "英文:"
1)Mixture-of-Gaussion cluster
2)高斯混合模型:GMM
- "原理:"
1)与k均值,LVQ用原型向量来刻画聚类结构不同,
2)高斯混合聚类采用概率模型来表达聚类原型。
3)可以看做是k-means模型的一个优化。
- "涉及知识点:"
1)高斯分布
2)贝叶斯公式
3)极大似然法
4)聚类
注:
下面将简单介绍这些知识点。
1.3.2 高斯分布
a)概念:
- "高斯分布即正态分布"
最熟知的就是:"一元正态分布"
- "一元正态分布"
1)曲线下的面积为1
b)指数函数:
e x p ( x ) : 表 示 e 的 x 次 方 exp(x):表示e的x次方 exp(x):表示e的x次方
c)一元正态分布标准形式:
P ( x ) = 1 2 π σ e x p ( − ( x − μ ) 2 2 σ 2 ) P(x) = \frac{1}{\sqrt{2\pi\sigma}}exp(-\frac{(x-\mu)^2}{2\sigma^2}) P(x)=2πσ1exp(−2σ2(x−μ)2)
d)一元正态分布曲线:
e)记作:
N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2)
f)二元高斯分布标准形式:
p ( x ) = ∑ i = 1 n 1 2 π e x p ( − 1 2 x i 2 ) p(x)=\sum_{i=1}^n\frac{1}{2\pi}exp(-\frac{1}{2}x_i^2) p(x)=i=1∑n2π1exp(−21xi2)
g)多元高斯分布的一般形式:
p ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e x p ( − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) ) p(x)=\frac{1}{(2\pi)^\frac{n}{2}|Σ|^{\frac{1}{2}}}exp(-\frac{1}{2}(x-\mu)^TΣ^{-1}(x-\mu)) p(x)=(2π)2n∣Σ∣211exp(−21(x−μ)TΣ−1(x−μ))
μ \mu μ是n维均值向量
Σ Σ Σ是n × n \times n ×n的协方差矩阵
1.3.3 贝叶斯公式
例子
假设,有三个箱子X、Y、Z,箱子里有红、黄、蓝色的球若干。
事 件 A : 把 手 伸 向 一 个 箱 子 准 备 抽 取 球 。
事 件 B : 从 某 个 箱 子 里 抽 出 一 个 球 。
概率乘法公式:
P ( A B ) = P ( A ) P ( B ∣ A ) P(AB)=P(A)P(B|A) P(AB)=P(A)P(B∣A)
P ( B ∣ A ) : 在 事 件 A 发 生 的 前 提 下 , 事 件 B 发 生 的 概 率 P(B|A):在事件A发生的前提下,事件B发生的概率 P(B∣A):在事件A发生的前提下,事件B发生的概率
随 机 抽 一 个 球 , 从 Y 箱 抽 到 黄 球 的 概 率 是 多 少 ? 随机抽一个球,从Y箱抽到黄球的概率是多少? 随机抽一个球,从Y箱抽到黄球的概率是多少?
全概率公式:
P ( B ) = P ( A 1 ) P ( B ∣ A 1 ) + . . . + P ( A n ) P ( B ∣ A n ) P(B)=P(A_1)P(B|A_1)+...+P(A_n)P(B|A_n) P(B)=P(A1)P(B∣A1)+...+P(An)P(B∣An)
P ( B ) = ∑ i = 1 n P ( A i ) P ( B ∣ A i ) P(B)=\sum_{i=1}^nP(A_i)P(B|A_i) P(B)=i=1∑nP(Ai)P(B∣Ai)
随 机 抽 一 个 球 , 抽 到 黄 球 的 概 率 是 多 少 ? 随机抽一个球,抽到黄球的概率是多少? 随机抽一个球,抽到黄球的概率是多少?
贝叶斯公式:
P ( A i ∣ B ) = P ( A i ) P ( B ∣ A i ) ∑ j = 1 n P ( A j ) P ( B ∣ A j ) P(A_i|B)=\frac{P(A_i)P(B|A_i)}{\sum_{j=1}^nP(A_j)P(B|A_j)} P(Ai∣B)=∑j=1nP(Aj)P(B∣Aj)P(Ai)P(B∣Ai)
已 知 随 机 抽 到 黄 球 , 求 这 个 黄 球 是 从 Y 箱 的 概 率 是 多 少 ? 已知随机抽到黄球,求这个黄球是从Y箱的概率是多少? 已知随机抽到黄球,求这个黄球是从Y箱的概率是多少?
P ( A ∣ B ) = P ( A ) P ( B ∣ A ) P ( B ) = P ( A B ) P ( B ) P(A|B) =\frac{P(A)P(B|A)}{P(B)}= \frac{P(AB)}{P(B)} P(A∣B)=P(B)P(A)P(B∣A)=P(B)P(AB)
P ( B ) 为 先 验 概 率 , 表 示 每 种 类 别 分 布 的 概 率 P(B)为先验概率,表示每种类别分布的概率 P(B)为先验概率,表示每种类别分布的概率
P ( B ∣ A ) 为 类 条 件 概 率 , 表 示 在 某 种 类 别 前 提 下 , 某 事 发 生 的 概 率 P(B|A)为类条件概率,表示在某种类别前提下,某事发生的概率 P(B∣A)为类条件概率,表示在某种类别前提下,某事发生的概率
P ( A ∣ B ) 为 后 验 概 率 , 表 示 某 事 发 生 了 , 并 且 它 属 于 某 一 类 别 的 概 率 P(A|B)为后验概率,表示某事发生了,并且它属于某一类别的概率 P(A∣B)为后验概率,表示某事发生了,并且它属于某一类别的概率
( 后 验 概 率 越 大 , 说 明 某 事 物 属 于 这 个 类 别 的 可 能 性 越 大 , 我 们 越 有 理 由 把 它 归 到 这 个 类 别 下 。 ) (后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。) (后验概率越大,说明某事物属于这个类别的可能性越大,我们越有理由把它归到这个类别下。)
1.3.4 概率密度函数(多元高斯分布的一般形式)
前 提 : 前提: 前提:
\ \ \ \ \ \ \ \ \ \ {} 对 n 维 样 本 空 间 X 中 的 随 机 向 量 x , 若 x 服 从 高 斯 分 布 对n维样本空间X中的随机向量x,若x服从高斯分布 对n维样本空间X中的随机向量x,若x服从高斯分布
公 式 : 公式: 公式:
\ \ \ \ \ \ \ \ \ \ {} P ( x ) = 1 ( 2 π ) n 2 ∣ Σ ∣ 1 2 e − 1 2 ( x − μ ) T Σ − 1 ( x − μ ) P(x)=\frac{1}{(2\pi)^{\frac{n}{2}}|Σ|^{\frac{1}{2}}}e^{-\frac{1}{2}(x-\mu)^TΣ^{-1}(x-\mu)} P(x)=(2π)2n∣Σ∣211e−21(x−μ)TΣ−1(x−μ)
解 释 : 解释: 解释:
\ \ \ \ \ \ \ \ \ \ {} u : n 维 均 值 向 量 u:n维均值向量 u:n维均值向量
\ \ \ \ \ \ \ \ \ \ {} Σ : n × n 协 方 差 矩 阵 Σ:n\times n协方差矩阵 Σ:n×n协方差矩阵
记 作 : 记作: 记作:
\ \ \ \ \ \ \ \ \ \ {} P ( x ∣ μ , Σ ) P(x|\mu,Σ) P(x∣μ,Σ)
\ \ \ \ \ \ \ \ {} ( 上 述 公 式 : 更 能 表 示 与 相 应 参 数 的 依 赖 关 系 ) (上述公式:更能表示与相应参数的依赖关系) (上述公式:更能表示与相应参数的依赖关系)
1.3.5 高斯混合分布(全概率公式)
公 式 : 公式: 公式:
\ \ \ \ \ \ \ \ \ \ {} P M ( x ) = ∑ i = 1 k α i P ( x ∣ μ i , Σ i ) PM(x)=\sum_{i=1}^k\alpha_iP(x\ |\mu_i,Σ_{i}) PM(x)=∑i=1kαiP(x ∣μi,Σi)
解 释 : 解释: 解释:
\ \ \ \ \ \ \ \ \ \ {} 该 分 布 共 由 k 个 混 合 成 分 组 成 , 每 个 混 合 成 分 对 应 一 个 高 斯 分 布 。 该分布共由k个混合成分组成,每个混合成分对应一个高斯分布。 该分布共由k个混合成分组成,每个混合成分对应一个高斯分布。
\ \ \ \ \ \ \ \ \ \ {} α i > 0 为 相 应 的 混 合 系 数 , ∑ i = 1 k α i = 1 \alpha_i>0为相应的混合系数,\sum_{i=1}^k\alpha_i=1 αi>0为相应的混合系数,∑i=1kαi=1
\ \ \ \ \ \ \ \ \ \ {} α i 就 是 上 文 中 的 P ( A i ) , α i = P ( μ i , Σ i ) \alpha_i就是上文中的P(A_i),\alpha_i=P(\mu_i,Σ_i) αi就是上文中的P(Ai),αi=P(μi,Σi)
- 1.3.6 高斯混合聚类的步骤
第一步:原型样本的生成
(原型样本生成的过程由高斯混合分布给出:)
首先,根据 α 1 , . . . , α k \alpha_1,...,\alpha_k α1,...,αk定义的先验分布选择高斯混合成分。
然后,根据被选择的混合成分的概率密度函数进行采样。
最终,生成相应的样本。
(举例:以训练集D = { x 1 , x 2 , . . . , x m x_1,x_2,...,x_m x1,x2,...,xm}为例:)
令,随机变量 z j ∈ { 1 , 2 , . . . , k } z_j\in \{1,2,...,k\} zj∈{1,2,...,k}表示生成样本 x j x_j xj的高斯回合成分。
得, z j z_j zj的先验概率P(B):
P ( z j = i ) 对 应 于 α i ( i = 1 , 2 , . . . , k ) P(z_j=i)对应于\alpha_i(i=1,2,...,k) P(zj=i)对应于αi(i=1,2,...,k)
再得, z j z_j zj的后验分布P(A|B):
P M ( z j = i ∣ x j ) = P ( z j = i ) P M ( x j ∣ z j = i ) P M ( x j ) PM(z_j=i|x_j)=\frac{P(z_j=i)PM(x_j|z_j=i)}{PM(x_j)} PM(zj=i∣xj)=PM(xj)P(zj=i)PM(xj∣zj=i)
代换 α i : \alpha_i: αi:
P M ( z j = i ∣ x j ) = α i P ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l P ( x j ∣ μ i , Σ i ) PM(z_j=i|x_j)=\frac{\alpha_iP(x_j|\mu_i,Σ_i)}{\sum_{l=1}^k\alpha_lP(x_j|\mu_i,Σ_i)} PM(zj=i∣xj)=∑l=1kαlP(xj∣μi,Σi)αiP(xj∣μi,Σi)
γ j i : \gamma_{ji}: γji:
P M ( z j = i ∣ x j ) 就 是 样 本 x j 由 第 i 个 高 斯 混 合 成 分 生 成 的 后 验 概 率 , 简 记 : γ j i PM(z_j=i|x_j)就是样本x_j由第i个高斯混合成分生成的后验概率,简记:\gamma_{ji} PM(zj=i∣xj)就是样本xj由第i个高斯混合成分生成的后验概率,简记:γji
第二步:簇划分
当高斯混合分布已知时,高斯混合聚类将把样本集D划分为k个簇C={ C 1 , C 2 , . . . , C k C_1,C_2,...,C_k C1,C2,...,Ck}
每个样本 x j x_j xj的簇标记 λ j : \lambda_j: λj:
λ j = a r g m a x γ j i , i ∈ { 1 , 2 , . . . , k } \lambda_j=arg\ max\ \gamma_{ji},i\in \{1,2,...,k\} λj=arg max γji,i∈{1,2,...,k}
最后:总结
从原型聚类的角度来看:
1)高斯混合聚类是采用概率模型(高斯分布)对原型进行刻画簇
2)划分则由原型对应的后验概率来确定。
1.3.7 极大释然估计
极大释然估计是什么?
极大释然估计详解
1.3.8 高斯混合分布公式,模型参数 { ( α i , μ i , Σ i ) ∣ 1 ≤ i ≤ k } \{(\alpha_i,\mu_i,Σ_i)|1\leq i\leq k\} {(αi,μi,Σi)∣1≤i≤k}的求解
- 1.3.8.1 求解参数的总思想
给定样本集 D:
1. 先采用极大似然估计,即最大化(对数)似然
2. 再用EM算法,迭代优化,求解参数
- 1.3.8.2 最大化(对数)似然函数
L L ( D ) = l n ( ∏ i = 1 m P M ( x j ) ) LL(D)=ln(\prod_{i=1}^mPM(x_j)) LL(D)=ln(i=1∏mPM(xj))
= ∑ j = 1 m l n ( ∑ i = 1 k α i P ( x j ∣ μ i , Σ i ) ) \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ =\sum_{j=1}^mln(\sum_{i=1}^k\alpha_i P(x_j|\mu_i,Σ_i)) =j=1∑mln(i=1∑kαiP(xj∣μi,Σi))
符 号 “ ∏ ” 是 连 乘 符 号 符号“∏”是连乘符号 符号“∏”是连乘符号
∏ i = 1 k α i = α 1 ∗ α 2 ∗ . . . ∗ α k \prod_{i=1}^kα_i=α_1*α_2*...*α_k ∏i=1kαi=α1∗α2∗...∗αk
- 1.3.8.3 EM算法迭代优化
首先:
1 ≤ i ≤ k 1\leq i\leq k 1≤i≤k
α i = P ( μ i , Σ i ) \alpha_i=P(\mu_i,Σ_i) αi=P(μi,Σi)
γ j i = α i P ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l P ( x j ∣ μ i , Σ i ) \gamma_{ji}=\frac{\alpha_iP(x_j|\mu_i,Σ_i)}{\sum_{l=1}^k\alpha_lP(x_j|\mu_i,Σ_i)} γji=∑l=1kαlP(xj∣μi,Σi)αiP(xj∣μi,Σi)
第一步: L L ( D ) μ i ′ = 0 LL(D)'_{\mu_i}=0 LL(D)μi′=0
L L ( D ) μ i ′ = ∂ L L ( D ) ∂ μ i = ∑ j = 1 m [ l n ( ∑ i = 1 k α i P ( x j ∣ μ i , Σ i ) ) ] μ i ′ = ∑ j = 1 m ∑ i = 1 k [ α i P ( x j ∣ μ i , Σ i ) ] u i ′ ∑ i = 1 k α i P ( x j ∣ μ i , Σ i ) = ∑ j = 1 m ∑ i = 1 k { ( α i ) u i ′ P ( x j ∣ μ i , Σ i ) + α i P ( x j ∣ μ i , Σ i ) μ i ′ } ∑ i = 1 k α i P ( x j ∣ μ i , Σ i ) = ( 最 大 化 似 然 函 数 对 μ i 求 导 , 好 难 , 待 续 。 直 接 看 结 果 ) = ∑ j = 1 m α i P ( x j ∣ μ i , Σ i ) ∑ l = 1 k α l P ( x j ∣ μ l , Σ l ) ( x j − μ i ) = 0 \begin{aligned} LL(D)'_{\mu_i} &= \frac{\partial LL(D)}{\partial \mu_i}\\[6pt] &=\sum_{j=1}^m[ln(\sum_{i=1}^k\alpha_i P(x_j|\mu_i,Σ_i))]'_{\mu_i}\\[6pt] &=\sum_{j=1}^m\frac{\sum_{i=1}^k[\alpha_i P(x_j|\mu_i,Σ_i)]'_{u_i}}{\sum_{i=1}^k\alpha_i P(x_j|\mu_i,Σ_i)}\\[6pt] &=\sum_{j=1}^m\frac{\sum_{i=1}^k\{(\alpha_i){'_{u_i}}P(x_j|\mu_i,Σ_i)+\alpha_i P(x_j|\mu_i,Σ_i)'_{\mu_i}\}}{\sum_{i=1}^k\alpha_i P(x_j|\mu_i,Σ_i)}\\[6pt] &=(最大化似然函数对\mu_i求导,好难,待续。直接看结果)\\[6pt] &=\sum_{j=1}^m\frac{\alpha_iP(x_j|\mu_i,Σ_i)}{\sum_{l=1}^k\alpha_l P(x_j|\mu_l,Σ_l)}(x_j-\mu_i) = 0\\[6pt] \end{aligned} \\[6pt] LL(D)μi′=∂μi∂LL(D)=j=1∑m[ln(i=1∑kαiP(xj∣μi,Σi))]μi′=j=1∑m∑i=1kαiP(xj∣μi,Σi)∑i=1k[αiP(xj∣μi,Σi)]ui′=j=1∑m∑i=1kαiP(xj∣μi,Σi)∑i=1k{(αi)ui′P(xj∣μi,Σi)+αiP(xj∣μi,Σi)μi′}=(最大化似然函数对μi求导,好难,待续。直接看结果)=j=1∑m∑l=1kαlP(xj∣μl,Σl)αiP(xj∣μi,Σi)(xj−μi)=0
第二步:简化
L L ( D ) μ i ′ = ∑ j = 1 m γ j i ( x j − μ i ) = 0 \begin{aligned} LL(D)'_{\mu_i} &=\sum_{j=1}^m\gamma_{ji}(x_j-\mu_i)=0\\[6pt] \end{aligned} \\[6pt] LL(D)μi′=j=1∑mγji(xj−μi)=0
第三步:得 μ i \mu_i μi
μ i = ∑ j = 1 m γ j i x j ∑ j = 1 m γ j i \mu_i=\frac{\sum_{j=1}^m\gamma_{ji}x_j}{\sum_{j=1}^m\gamma_{ji}} μi=∑j=1mγji∑j=1mγjixj
第四步: L L ( D ) Σ i ′ = 0 LL(D)'_{Σ_i}=0 LL(D)Σi′=0
步 骤 待 续 步骤待续 步骤待续
第五步:得 Σ i Σ_i Σi
Σ i = ∑ j = 1 m γ j i ( x j − μ i ) ( x j − u i ) T ∑ j = 1 m γ j i Σ_i=\frac{\sum_{j=1}^m\gamma_{ji}(x_j-\mu_i)(x_j-u_i)^T}{\sum_{j=1}^m\gamma_{ji}} Σi=∑j=1mγji∑j=1mγji(xj−μi)(xj−ui)T
第五步:得 α i \alpha_i αi

1.3.9 高斯混合聚类算法伪代码

- 1.3.10 高斯混合聚类例子
【样本集D】

【令高斯混合成分的个数 k = 3】
【步骤】
