Pyspark图计算:GraphFrames的安装及其常用方法
Spark版本:V3.2.1
还没写完,持续补充
Python 没有 GraphX API,以后也不会有。但可以在Pyspark中使用graphframes,它提供了基于 Dataframe 的图形处理。本篇博客主要介绍Graphframes的安装及其使用方法。
1. GraphFrames的安装
graphframes的官网地址:https://spark-packages.org/package/graphframes/graphframes
在命令行窗口使用如下命令安装graphframes:
pyspark --packages graphframes:graphframes:0.8.2-spark3.2-s_2.12
上述命令中,graphframes的版本与spark版本的对应关系可以从graphframes的官网上找到:

命令执行成功后会直接进入pyspark编辑界面,在代码中引入graphframes即可检测是否安装成功,具体如下:

同样也可以使用如下命令安装graphframes:
pip install graphframes
之后需要将graphframes对应的jar包安装到spark下的jars包文件中。如果不安装该jar包,在使用graphframes会报错:Py4JJavaError: An error occurred while calling o327.loadClass.java.lang.ClassNotFoundException:org.graphframes.GraphFramePythonAPI
jar包安装路径

2. graphframes的使用
2.1 构建graph
from pyspark.sql.types import *
from pyspark.sql import SparkSession
=from pyspark import SparkContext, SparkConf
import os
import pandas as pd
from graphframes import GraphFrame
os.environ['SPARK_HOME'] ='/Users/sherry/documents/spark/spark-3.2.1-bin-hadoop3.2'
spark_conf = SparkConf().setAppName('Python_Spark_WordCount')\
.setMaster('local[2]')
sc = SparkContext(conf=spark_conf)
spark=SparkSession.builder.appName("graph").getOrCreate()
edges=sc.textFile(r'/Users/sherry/Downloads/edges')
edges=edges.map(lambda x:x.split('\t'))
edges_df=spark.createDataFrame(edges,['src','dst'])
nodes=sc.textFile(r'/Users/sherry/Downloads/nodes')
nodes=nodes.map(lambda x:[x])
nodes_df=spark.createDataFrame(nodes,['id'])
graph=GraphFrame(nodes_df, edges_df)
这里要注意以下几点:
- GraphFrames(v,e)中的顶点v和边e必须都是DataFrame;
- v代表节点,其对应的DataFrame中必须有名叫“id”的列;
- e代表边,其对应的DataFrame中必须有名叫“src”和“dst”的列;
2.2 针对点、边的操作
- 节点的度、入度和出度(其返回的结果都是DataFrame)
graph.degrees.show(5)
graph.inDegrees.show(5)
graph.outDegrees.show(5)

- 过滤节点和边形成新的图
#抽取原图中有顶点编号小于5000的点发出的边组成的图
g1=graph.filterEdges(func.expr('int(src)')<5000)
#抽取原图中顶点编号小于5000的所有的点组成的图
g2=graph.filterVertices(func.expr('int(id)')<5000)
filterEdges()和filterVertices()方法中的过滤条件condition会分别与graph.edges、graph.vertices关联起来。
- 删除图中的孤立节点dropIsolatedVertices()并形成新的图
g3=g2.dropIsolatedVertices()
2.3 常用算法
- bfs():按广度优先搜索算法查找从源点到目标节点的路径。具体用法举例如下:
vertices=[(1,'A'),(2,'B'),(3,'C'),(4,'D'),
(5,'E'),(6,'F'),(7,'G'),(8,'H'),(9,'I')]
edges=[(1,2),(1,6),(2,3),(2,7),(2,9),(3,4),(3,9),
(4,5),(4,7),(4,8),(4,9),(5,6),(5,8),(7,6),(7,8)]
vertices=spark.createDataFrame(vertices,['id','name'])
edges=spark.createDataFrame(edges,['src','dst'])
graph=GraphFrame(vertices, edges)
root=graph.bfs('id=1','id=4')
构建的graph结果如下:
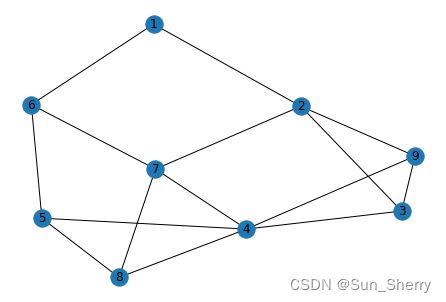
而root的结果如下,沿着e0->e1->e2就可以从节点1到节点4。

这里要注意bfs()中的fromExpr和toExpr用来确定广度优先搜索的源点和目标点(关于其写法,目前还没有找到相关资料)。