Flink源码解析系列--StreamPartitioner(流分区器)
本文的Flink源码版本为: 1.15-SNAPSHOT,读者可自行从Github clone.
StreamPartitioner抽象类
@Internal
public abstract class StreamPartitioner
implements ChannelSelector>>, Serializable {
private static final long serialVersionUID = 1L;
// 持有output channel数量
protected int numberOfChannels;
@Override
public void setup(int numberOfChannels) {
this.numberOfChannels = numberOfChannels;
}
// 是否采用广播的形式
@Override
public boolean isBroadcast() {
return false;
}
// 拷贝方法
public abstract StreamPartitioner copy();
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
final StreamPartitioner that = (StreamPartitioner) o;
return numberOfChannels == that.numberOfChannels;
}
@Override
public int hashCode() {
return Objects.hash(numberOfChannels);
}
// 决定了作业恢复时候上游遇到扩缩容的话,需要处理哪些上游状态保存的数据
public SubtaskStateMapper getUpstreamSubtaskStateMapper() {
return SubtaskStateMapper.ARBITRARY;
}
// 同上,但关注的是下游扩缩容
public abstract SubtaskStateMapper getDownstreamSubtaskStateMapper();
// isPointwise方法决定了上游和下游的对应关系。
// false表示没有指向性,上游和下游没有明确的对应关系
// true表示上游和下游存在对应关系
public abstract boolean isPointwise();
}
isPointwise 主要用来标记该分类器是否是"点对点"的分配模式,Flink 数据的分配模式分为2类:
public enum DistributionPattern {
ALL_TO_ALL,
POINTWISE
}
ALL_TO_ALL 代表上游的每个 subtask 需要和下游的每个 subtask 连接,而 POINTWISE 代表上游的每个 subtask 和下游的1个或多个 subtask 连接。
StreamPartitioner抽象类继承了ChannelSelector接口,其关键方法为selectChannel,用户需要继承StreamPartitioner抽象类,自定义实现selectChannel方法来控制元素的分流行为。
public interface ChannelSelector {
// 定义输出 channel 的数量
void setup(int numberOfChannels);
// 返回选择的 channel 索引编号,这个方法决定的上游的数据需要写入到哪个 channel 中
// 对于 broadcast 广播类型算子,不需要实现该方法
// 传入的参数为记录数据流中的元素,该方法需要根据元素来推断出需要发送到的下游 channel
int selectChannel(T record);
// 返回是否为广播类型
// 广播类型指的是上游数据发送给所有下游channel
boolean isBroadcast();
}
ChannelSelector接口的泛型为SerializationDelegate
public class SerializationDelegate implements IOReadableWritable {
private T instance;
private final TypeSerializer serializer;
public SerializationDelegate(TypeSerializer serializer) {
this.serializer = serializer;
}
public void setInstance(T instance) {
this.instance = instance;
}
public T getInstance() {
return this.instance;
}
@Override
public void write(DataOutputView out) throws IOException {
this.serializer.serialize(this.instance, out);
}
@Override
public void read(DataInputView in) throws IOException {
throw new IllegalStateException("Deserialization method called on SerializationDelegate.");
}
}
StreamRecord定义了流中的记录:
@Internal
public final class StreamRecord extends StreamElement {
// 记录持有的 value
private T value;
// 记录持有的 timestamp,其实就是 event time
private long timestamp;
// 记录是否持有 timestamp
private boolean hasTimestamp;
......
public long getTimestamp() {
if (hasTimestamp) {
return timestamp;
// 若没有event time,则返回 Long.MIN_VALUE 作为 event time
} else {
return Long.MIN_VALUE;
}
}
......
}
继承类
StreamPartitioner的继承实现类主要有:

下面依次看一下它们的方法实现,重点关注selectChannel方法。
GlobalPartitioner
@Override
public int selectChannel(SerializationDelegate> record) {
// 元素全部发送到下游的第1个 channel
return 0;
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.FIRST;
}
@Override
public boolean isPointwise() {
return false;
}
GlobalPartitioner 上游的每个分区数据均发送到下游的第1个分区。
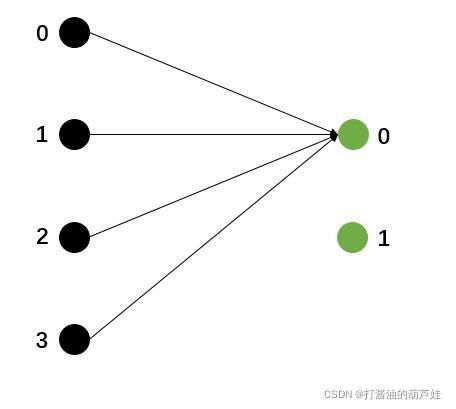
ForwardPartitioner
@Override
public int selectChannel(SerializationDelegate> record) {
return 0;
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
@Override
public SubtaskStateMapper getUpstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
@Override
public boolean isPointwise() {
return true;
}
可以看到,ForwardPartitioner 的 selectChannel 方法和 GlobalPartitioner 完全一致。
那这俩有啥区别呢?众所周知,FLink 会将任务的执行计划分为 StreamGraph–>JobGraph–>ExecutionGraph。而 StreamingJobGraphGenerator 类就是实现 StreamGraph 转化为 JobGraph。该类会调用 partitioner 的 isPointwise() 方法,根据 partitioner 是 POINTWISE (点对点)分配模式还是 ALL_TO_ALL (多对多)分配模式,去分配上游某个分区所对应的下游分区范围。
if (partitioner.isPointwise()) {
jobEdge =
downStreamVertex.connectNewDataSetAsInput(
headVertex, DistributionPattern.POINTWISE, resultPartitionType);
} else {
jobEdge =
downStreamVertex.connectNewDataSetAsInput(
headVertex, DistributionPattern.ALL_TO_ALL, resultPartitionType);
}
而 ForwardPartitioner 要求上下游的并行度是一致,该种情况下,上游的每个分区只对应下游的1个分区,所以 selectChannel 的算法实现为 return 0 就容易理解了。

BroadcastPartitioner
@Override
public int selectChannel(SerializationDelegate> record) {
throw new UnsupportedOperationException(
"Broadcast partitioner does not support select channels.");
}
@Override
public SubtaskStateMapper getUpstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
@Override
public boolean isPointwise() {
return false;
}
BroadcastPartitioner 默认上游每个分区的数据会发送给下游的全部分区,所以不需要实现具体的分区逻辑。
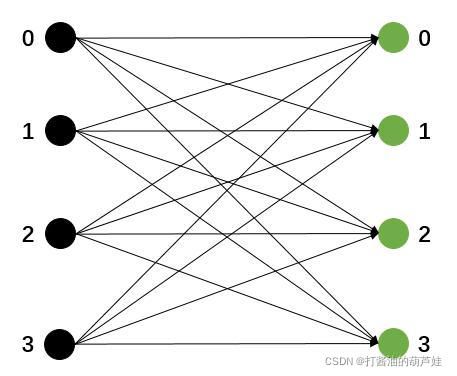
RebalancePartitioner
@Override
public void setup(int numberOfChannels) {
super.setup(numberOfChannels);
// 上游的某分区第1条数据发到下游的哪个分区是随机的
nextChannelToSendTo = ThreadLocalRandom.current().nextInt(numberOfChannels);
}
@Override
public int selectChannel(SerializationDelegate> record) {
// 在下游分区上依次轮询
nextChannelToSendTo = (nextChannelToSendTo + 1) % numberOfChannels;
return nextChannelToSendTo;
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.ROUND_ROBIN;
}
@Override
public boolean isPointwise() {
return false;
}
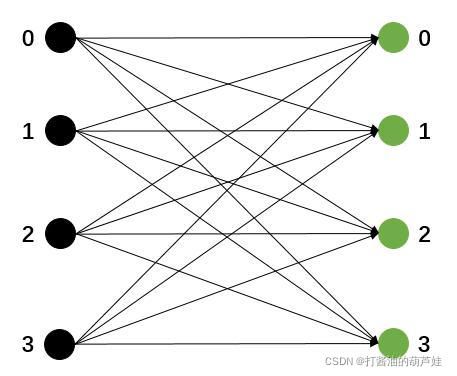
上下游连接关系上跟 BroadcastPartitioner 是类似的,但数据量不一样,比如上游分区0来了5条数据{a, b, c, d, e}。
BroadcastPartitioner 时,上游分区0会把这5条数据发送给下游的每个分区。

RebalancePartitioner 时,上游分区0会把这5条数据轮询得发送给下游的各个分区。

RescalePartitioner
private int nextChannelToSendTo = -1;
@Override
public int selectChannel(SerializationDelegate> record) {
if (++nextChannelToSendTo >= numberOfChannels) {
nextChannelToSendTo = 0;
}
return nextChannelToSendTo;
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
@Override
public SubtaskStateMapper getUpstreamSubtaskStateMapper() {
return SubtaskStateMapper.UNSUPPORTED;
}
@Override
public boolean isPointwise() {
return true;
}
RescalePartitioner 的 selectChannel 方法实现跟 RebalancePartitioner 基本一样,也是在下游的分区上轮询。
区别主要有2点:
- RescalePartitioner 上游每个分区的第1条数据是发送给下游的第1个分区的,而 RebalancePartitioner 是随机选择的;
- RescalePartitioner 的分区模式是 POINTWISE,即点对点模式。
假设上游分区为2,下游分区为4时,当使用 RescalePartitioner 时,上游每个分区只需轮询发给下游 2 个分区。
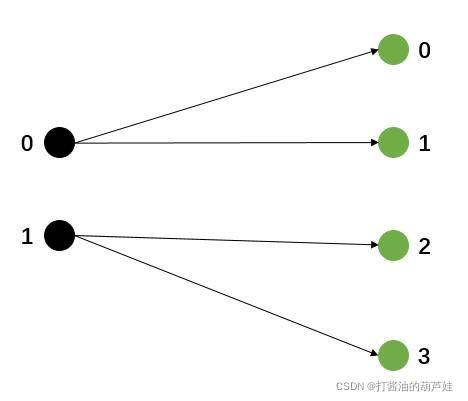
RescalePartitioner 可以增加 TaskManager 的数据本地性,TaskManager 可以直接从本地的上游算子获取所需的数据,减少了网络 IO 过程,提高了性能。但其数据均衡性不如 RebalancePartitioner,因为 RebalancePartitioner 是 ALL_TO_ALL 模式的,对应下游所有分区,是真正的轮询。
ShufflePartitioner
private Random random = new Random();
@Override
public int selectChannel(SerializationDelegate> record) {
// 随机选择下游的某个分区
return random.nextInt(numberOfChannels);
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.ROUND_ROBIN;
}
@Override
public boolean isPointwise() {
return false;
}
KeyGroupStreamPartitioner
private final KeySelector keySelector;
private int maxParallelism;
public KeyGroupStreamPartitioner(KeySelector keySelector, int maxParallelism) {
Preconditions.checkArgument(maxParallelism > 0, "Number of key-groups must be > 0!");
this.keySelector = Preconditions.checkNotNull(keySelector);
this.maxParallelism = maxParallelism;
}
public int getMaxParallelism() {
return maxParallelism;
}
@Override
public int selectChannel(SerializationDelegate> record) {
K key;
try {
key = keySelector.getKey(record.getInstance().getValue());
} catch (Exception e) {
throw new RuntimeException(
"Could not extract key from " + record.getInstance().getValue(), e);
}
return KeyGroupRangeAssignment.assignKeyToParallelOperator(
key, maxParallelism, numberOfChannels);
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.RANGE;
}
public static int assignKeyToParallelOperator(Object key, int maxParallelism, int parallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
return computeOperatorIndexForKeyGroup(
maxParallelism, parallelism, assignToKeyGroup(key, maxParallelism));
}
public static int computeOperatorIndexForKeyGroup(
int maxParallelism, int parallelism, int keyGroupId) {
return keyGroupId * parallelism / maxParallelism;
}
public static int assignToKeyGroup(Object key, int maxParallelism) {
Preconditions.checkNotNull(key, "Assigned key must not be null!");
return computeKeyGroupForKeyHash(key.hashCode(), maxParallelism);
}
public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) {
return MathUtils.murmurHash(keyHash) % maxParallelism;
}
KeyGroupStreamPartitioner 分区器主要和 KeyGroupRange 有关,关于 KeyGroupRange 是啥?,读者可参阅我写的另外2篇博客:
Flink源码解析系列–SubtaskStateMapper枚举类
Flink的State扩容机制
基本逻辑是,当上游某个分区数据到达时,首先 key.hashCode() 进行第1次哈希,然后通过 MathUtils.murmurHash(keyHash) 进行第2次哈希,最大并行度取余得到 keyGroupid,最后 keyGroupId * parallelism / maxParallelism 获得下游分区的 index。
BinaryHashPartitioner
private GeneratedHashFunction genHashFunc;
private transient HashFunction hashFunc;
private String[] hashFieldNames;
public BinaryHashPartitioner(GeneratedHashFunction genHashFunc, String[] hashFieldNames) {
this.genHashFunc = genHashFunc;
this.hashFieldNames = hashFieldNames;
}
@Override
public StreamPartitioner copy() {
return this;
}
@Override
public int selectChannel(SerializationDelegate> record) {
// 将数据的 hash 值和下游分区数取余,得到下游分区的 index
return MathUtils.murmurHash(getHashFunc().hashCode(record.getInstance().getValue()))
% numberOfChannels;
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.FULL;
}
@Override
public boolean isPointwise() {
return false;
}
private HashFunction getHashFunc() {
if (hashFunc == null) {
try {
hashFunc = genHashFunc.newInstance(Thread.currentThread().getContextClassLoader());
genHashFunc = null;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
return hashFunc;
}
CustomPartitionerWrapper
Partitioner partitioner;
KeySelector keySelector;
public CustomPartitionerWrapper(Partitioner partitioner, KeySelector keySelector) {
this.partitioner = partitioner;
this.keySelector = keySelector;
}
@Override
public int selectChannel(SerializationDelegate> record) {
K key;
try {
key = keySelector.getKey(record.getInstance().getValue());
} catch (Exception e) {
throw new RuntimeException("Could not extract key from " + record.getInstance(), e);
}
return partitioner.partition(key, numberOfChannels);
}
@Override
public SubtaskStateMapper getDownstreamSubtaskStateMapper() {
return SubtaskStateMapper.FULL;
}
@Override
public boolean isPointwise() {
return false;
}
顾名思义,CustomPartitionerWrapper 为自定义分区器,需要用户传入自定义的 keySelector 和 partitioner。
- keySelector 用于根据 record 提取出分区的 key。
- partitioner 用于自定义分区行为。
本文到此结束,感谢阅读!