Linux学习日记8——文件IO函数
学习视频链接:
黑马程序员-Linux系统编程_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1KE411q7ee?p=52&spm_id_from=pageDriver
https://www.bilibili.com/video/BV1KE411q7ee?p=52&spm_id_from=pageDriver
目录
一、系统调用(内核提供的函数)
二、open / close 函数
2.1 linux 下查看 open 命令
2.2 函数原型
2.3 操作
2.4 O_CREAT
2.5 O_TRUNC
2.6 常见错误
三、read / write 函数
3.1 函数原型
3.2 查看函数用法
3.3 实现拷贝操作
3.4 与 C 语言标准 IO 库比较
3.5 库函数与系统调用
一、系统调用(内核提供的函数)
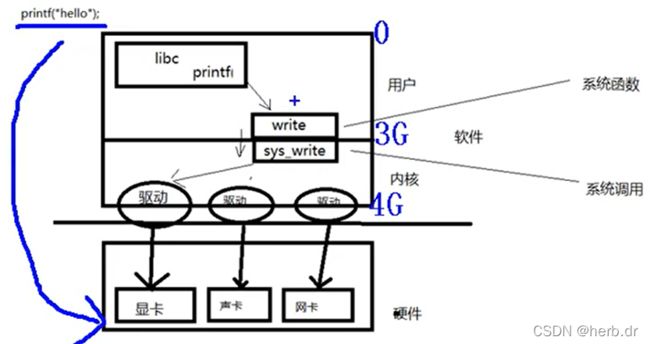
只有系统调用才能进内核空间,才能调用驱动程序,驱动硬件工作。
二、open / close 函数
2.1 linux 下查看 open 命令
man 2 open
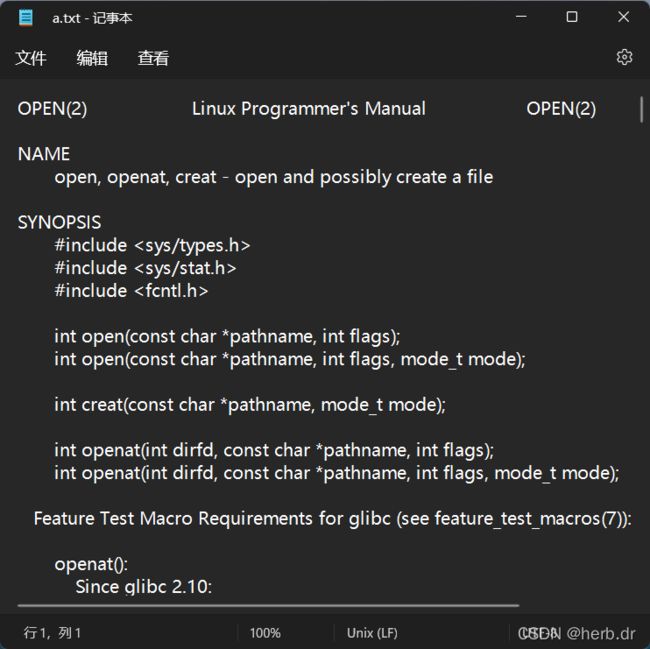
2.2 函数原型
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
int close(int fd);
1、int open(const char *pathname, int flags);
pathname:路径名
flags:三个参数 O_RDONLY,O_WRONLY,O_RDWR
| O_APPEND | O_CREAT | O_EXCL | O_TRUNC | O_NONBLOCK |
| 追加 | 创建 | 是否存在 | 截断 | 非阻塞 |
return:函数执行正确 返回新的文件描述符(整数),错误 返回 -1 并且 errno 被设置成相应的值
2、int open(const char *pathname, int flags, mode_t mode);
mode_t mode:8 进制整形,用来设置权限(权限大于当前用户 umask 时,会让文件权限变成 umask 对应的权限)
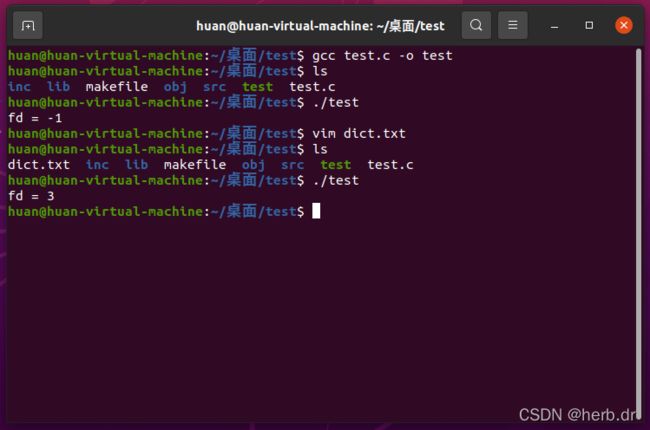
2.3 操作
新建一个 C 语言程序
把光标移动到函数上,键入 2K 跳转到函数定义

发现使用 open 需要 3 个头文件,其中前两个可以简写为一个头文件:unistd.h

测试运行
2.4 O_CREAT
删除 dict.txt,修改 C 程序源码

权限与设定的 644 是一样的

2.5 O_TRUNC
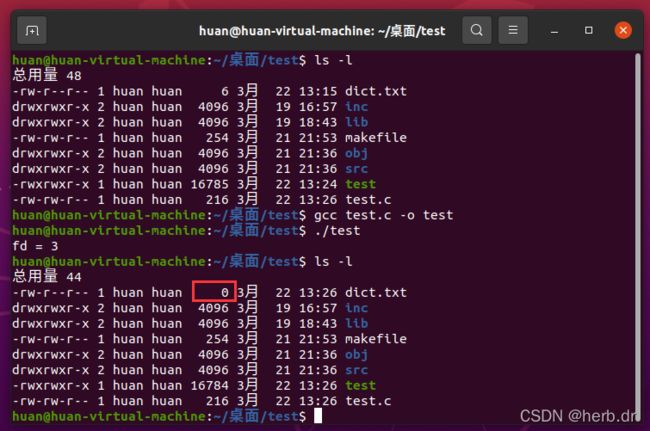
往 dict.txt 里面添加一点东西

修改C语言文件

文件被清空了
2.6 常见错误
1、文件不存在错误
errno 记录着错误数字,把错误数字传入到 strerror 中返回错误信息

查看更多的 strerror 用法可以使用 linux 命令 man(strerror)
2、以写方式打开只读文件
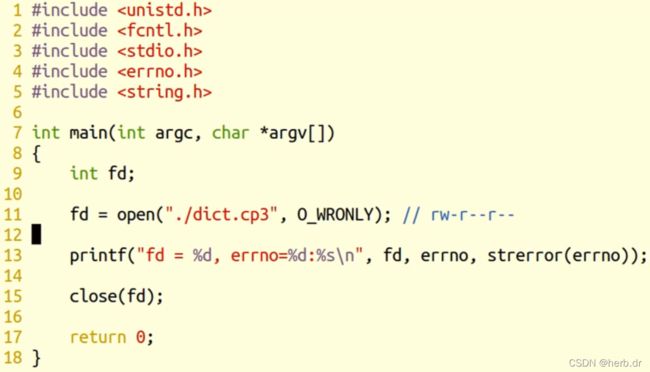
运行结果:

3、以只写文件打开目录
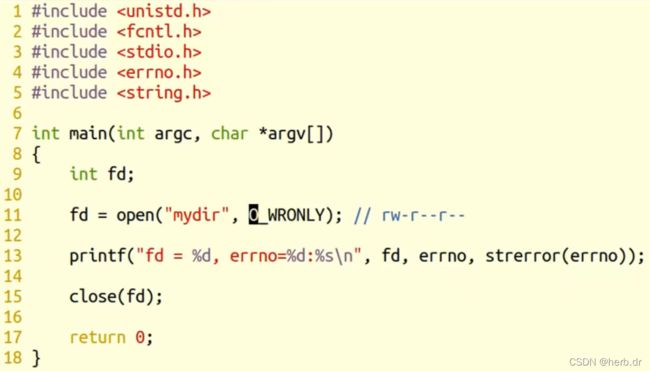
运行结果:

三、read / write 函数
3.1 函数原型
ssize_ t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
3.2 查看函数用法
1、man 2 read

fd:文件描述符
buf:保存数据的缓冲区
count:缓冲区的大小
返回值:成功返回实际读到的字节数,读到文末返回 0,失败返回 -1 并且 errno 被设置成相应的值
2、man 2 write
ssize_t write(int fd, const void *buf, size_t count);
fd:文件描述符
buf:待写出数据的缓冲区
count:实际要写出的内容的大小
返回值:成功返回写入的字节数,失败赶回 -1 并且 errno 被设置成相应的值
3.3 实现拷贝操作
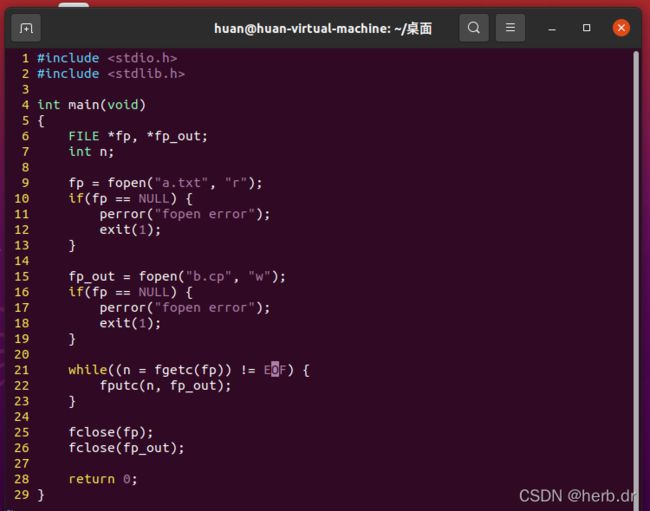
1、C 语言代码
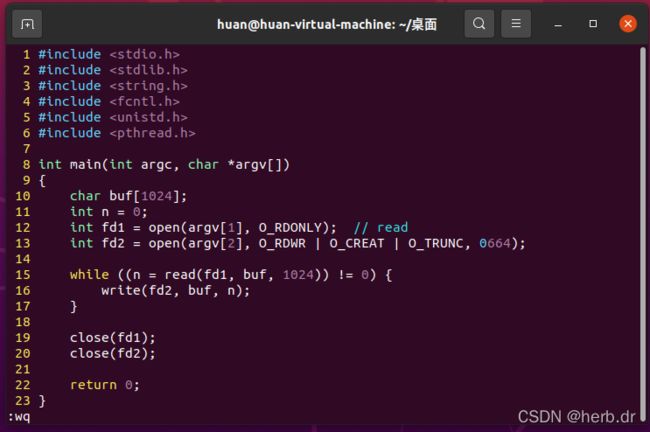
运行结果:

2、添加错误信息

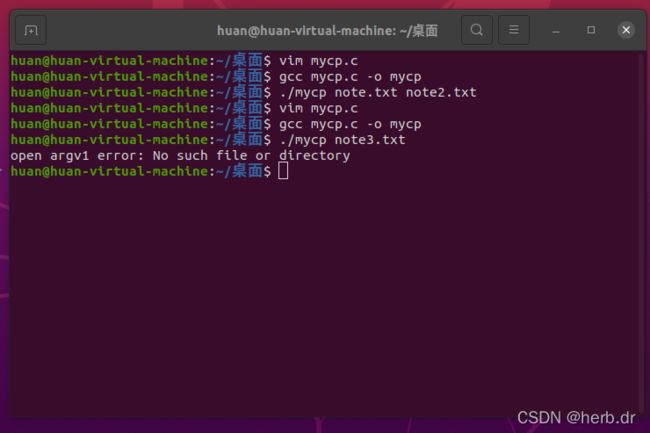
3.4 与 C 语言标准 IO 库比较
1、执行原理
C语言标准库函数 fputc 函数调用了系统函数 write 函数执行写操作
2、使用标准库函数和 read write 读写速度对比
(1) 准备这三个文件


2、编译执行两个C语言文件,比较他们的拷贝速度
发现使用标准 IO 库函数执行拷贝命令稍微快一点

3、查看这两个函数执行时候调用了多少次 read 和 write
strace ./a_cp_b
发现执行了很多次 read 和 write ,每次读写 4096 个字节


执行用系统调用函数编写的 C 程序
每次读写5个字节,所以更慢

4、结果分析
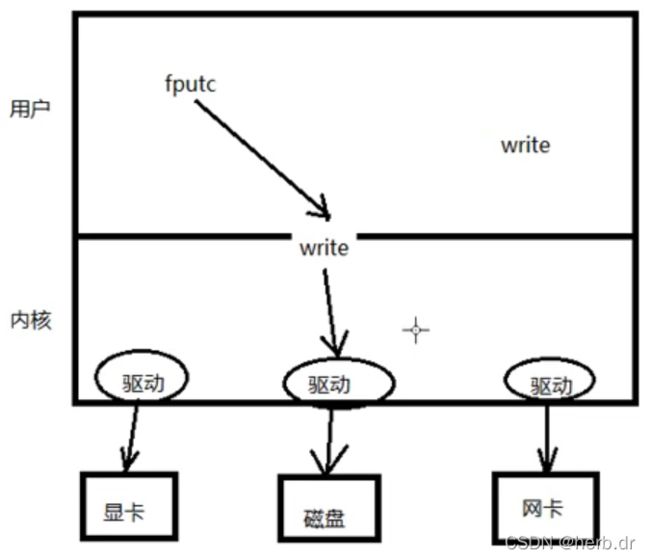
我们调用系统函数,系统直接就执行对应的指令,调用 C语言标准 IO库的时候,如下图:

C语言库中有用户级别的缓冲,虽然表现在程序上的是一次读取一个字节,但是在 fputc 函数中有一个缓冲区,当缓冲区达到 4096 个字节的时候才会调用系统函数执行 read 和 write,这个被称为预读入缓输出。
5、结论
即使学了系统调用,能使用库函数的时候尽量使用库函数。有的时候不想使用缓输出的机制,可以使用系统调用。
3.5 库函数与系统调用
未使用系统调用的库函数,其执行效率通常要比系统调用的高。因为使用系统调用时,需要上下文的切换及状态转换(用户态转向核心态)