机器学习之朴素贝叶斯
机器学习之朴素贝叶斯
- 1 朴素贝叶斯
- 2 朴素贝叶斯应用
- 3 代码实现贝努力朴素贝叶斯
- 4 代码实现高斯朴素贝叶斯
- 5 代码实现多项式朴素贝叶斯
- 6 总结
前言:主要介绍朴素贝叶斯的概念、公式,以及代码实现贝努利、高斯、多项式朴素贝叶斯。
1 朴素贝叶斯
- 朴素贝叶斯(Naive Bayes)是一个非常简单,但是实用性很强的分类模型。朴素贝叶斯分类器的构造基础是贝叶斯理论。
- 联合概率:是指两件事情同时发生的概率,一般对于X和Y来说,对应的联合概率记为P(XY)。
- 条件概率:表示为在Y发生的条件下,发生X的概率。记为P(X∣Y)。
- 贝叶斯公式:
 ,其中W为特征向量,C为预测的类别。
,其中W为特征向量,C为预测的类别。
2 朴素贝叶斯应用
| id | 刮北风 | 闷热 | 多云 | 预报有雨 | 真下雨? |
|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 1 | 0 |
| 2 | 1 | 1 | 1 | 0 | 1 |
| 3 | 0 | 1 | 1 | 0 | 1 |
| 4 | 0 | 0 | 0 | 1 | 0 |
| 5 | 0 | 1 | 1 | 0 | 1 |
| 6 | 0 | 1 | 0 | 1 | 0 |
| 7 | 1 | 0 | 0 | 1 | 0 |
注意:0代表否,1代表是。
我们可以使用上述公式依次计算出真下雨的概率,这里不再计算。我们可以通过代码使用贝努利、高斯、多项式来完成计算。
3 代码实现贝努力朴素贝叶斯
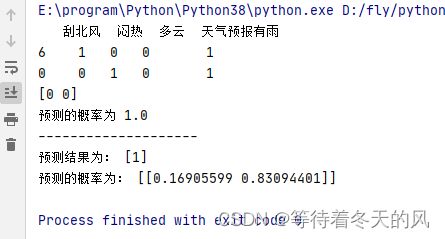
为了方便继续使用上述数据进行预测,数据截图如下:

代码实现:
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.naive_bayes import BernoulliNB
def naviebayes():
# 读取数据
data = pd.read_csv("train_2.csv")
# 取出数据当中的特征值和目标值
y = data['真下雨?'] #目标值
x = data[['刮北风', '闷热','多云','天气预报有雨']] #特征值
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
#贝努力朴素贝叶斯
clf = BernoulliNB()
clf.fit(x_train, y_train)
y_predict = clf.predict(x_test)
print(x_test)
print(y_predict)
print("预测的概率为",clf.score(x_test, y_test))
print("--------------------")
Next_Day = [[0, 0, 1, 0]]
pre = clf.predict(Next_Day)
pre2 = clf.predict_proba(Next_Day)
print("预测结果为:", pre)
# 输出模型预测的分类概率
print("预测的概率为:", pre2)
if __name__ == '__main__':
naviebayes()
截图:
4 代码实现高斯朴素贝叶斯
代码实现:
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.naive_bayes import GaussianNB
def naviebayes():
# 读取数据
data = pd.read_csv("train_2.csv")
# 取出数据当中的特征值和目标值
y = data['真下雨?'] #目标值
x = data[['刮北风', '闷热','多云','天气预报有雨']] #特征值
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
#高斯朴素贝叶斯
gnb = GaussianNB()
gnb.fit(x_train, y_train)
y_predict = gnb.predict(x_test)
print(x_test)
print(y_predict)
print("预测的概率为",gnb.score(x_test, y_test))
print("--------------------")
Next_Day = [[0, 0, 1, 0]]
pre = gnb.predict(Next_Day)
pre2 = gnb.predict_proba(Next_Day)
print("预测结果为:", pre)
# 输出模型预测的分类概率
print("预测的概率为:", pre2)
if __name__ == '__main__':
naviebayes()
截图:

5 代码实现多项式朴素贝叶斯
代码如下:
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
import pandas as pd
def naviebayes():
# 读取数据
data = pd.read_csv("train_2.csv")
# 取出数据当中的特征值和目标值
y = data['真下雨?'] #目标值
x = data[['刮北风', '闷热','多云','天气预报有雨']] #特征值
# 进行数据分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 多项式朴素贝叶斯
mlt = MultinomialNB(alpha=1.0)
mlt.fit(x_train, y_train)
y_predict = mlt.predict(x_test)
print(x_test)
print(y_predict)
print("准确率为:", mlt.score(x_test, y_test))
print("--------------------")
Next_Day = [[0, 0, 1, 0]]
pre = mlt.predict(Next_Day)
pre2 = mlt.predict_proba(Next_Day)
print("预测结果为:", pre)
# 输出模型预测的分类概率
print("预测的概率为:", pre2)
if __name__ == '__main__':
naviebayes()
截图:

6 总结
通过对比贝努力、高斯、多项式的结果,预测的准确率不一样,所以我们在开发使用的时候,一定要注意区分这几类。