图像检测:深度学习基础
选择合适的目标函数
均方误差

交叉熵
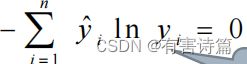
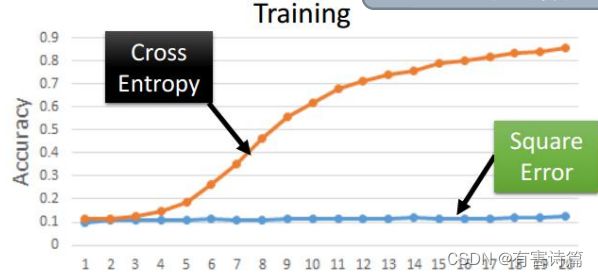
交叉熵与均方误差
可以想象为交叉熵目标函数的最优值搜索空间的地形更陡,更有利于快速的找到最优值

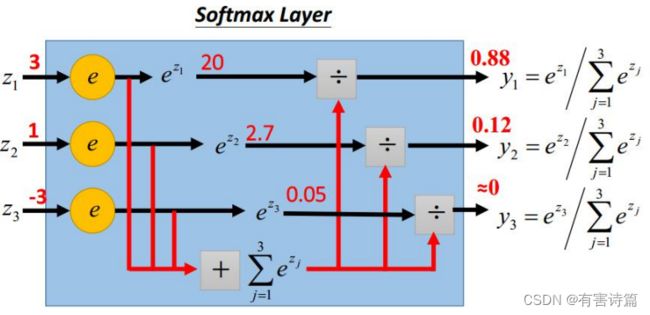
Softmax层
softmax层的作用是突出最大值并转换成概率的形式
梯度消失的直观解释
神经元的激活函数采用Sigmoid函数,则大部分情况下|W|<1,而Sigmoid的导数小于0.25


激活函数
2006年,人们(Hinton等)用RBM预训练的方式解决梯度消失的问题,到了2015年,使用ReLU激活函数

- 计算速度快
- 有生物依据
- 能解决梯度消失问题
采用ReLU激活函数后
一些单元的输出成了0,而另一些则成了完全线性的单元
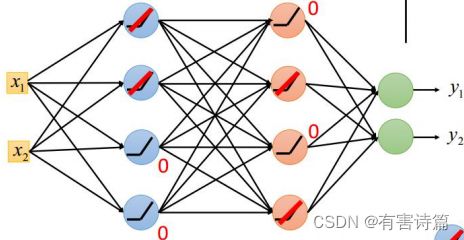
避免了调整各层权重时的梯度消失的问题
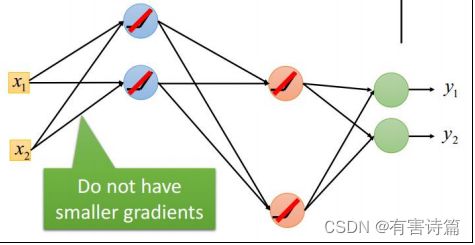
学习步长
学习步长是个难题,若学习步长过大,则目标函数可能不降低,但若学习步长过小,则训练过程可能非常缓慢。解决:训练几轮后就按一些因素调整步长。

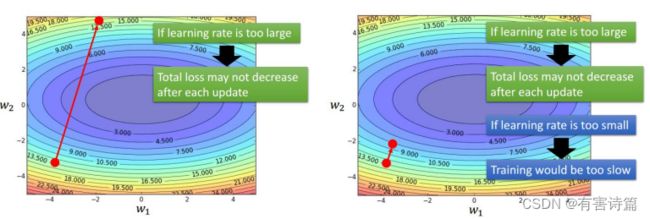
SGD的问题
learning rate不易确定,如果选择的太小,收敛速度会很慢;如果太大,loss function就会在极小值处不停地震荡甚至偏离。每个参数的learning rate都是相同的,如果数据是稀疏的,则希望对出现频率低的特征进行大一点的更新。深层神经网络之所以比较难训练,并不是因为容易进入局部最小,而是因为学习过程容易陷入到马鞍面中,在这种区域中,所有方向的梯度值都几乎是0。
Momentum(动量)
Momentum借用了物理中的动量概念,即,前几次的梯度也会参与运算。为了表示动量,引入了一个新的变量v。v是之前的梯度的累加,但每一回合都有一定的衰减。前后梯度方向一致时,能够加速学习;前后梯度方向不一致时,能够一直震荡。
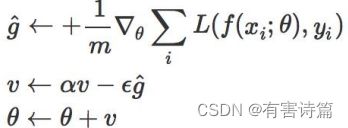
Nesterov Momentum
对Momentum的一种改进,先对参数进行估计,然后适应估计后的参数来计算误差

Adagrad
应该为不同参数设置不同的学习步长。梯度越小,则学习步长越大,反之亦然。

RMSprop
RMSprop是一种改进的Adagrad,通过引入一个衰减系数,让r每回合都衰减一定比例。这种方法很好的解决了Adagrad过早结束的问题,适合处理非平稳目标,对于RNN效果很好
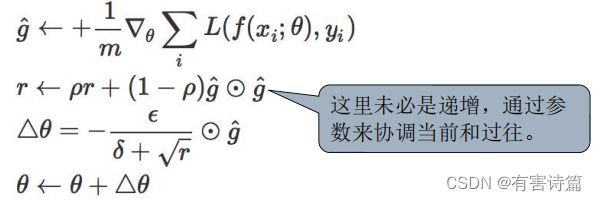
Adam
Adam这个名字来源于adaptive moment estimation 自适应矩估计,Adam本质是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率
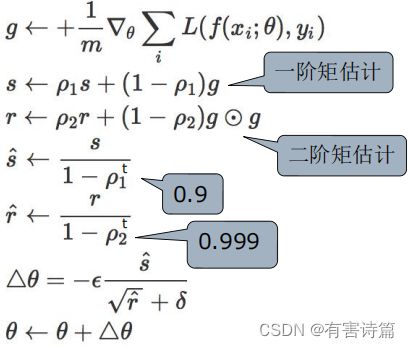
各种梯度下降算法的比较
左:在MNIST上训练多层卷积网络
右:在CIFAR10上训练卷积神经网络
如果数据是稀疏的,就用自适应方法,即Adagrad, Adadelta, RMSprop, Adam。RMSprop, Adadelta,Adam在很多情况下的效果是相似的。通常,Adam是最好的选择。很多论文里都会用SGD,没有momentum等。SGD虽然也能达到极小值,但是比其它算法用的时间长,而且可能会被困在鞍点。SGD相对稳定——据说老司机都是开手动挡的。
关于算法选择的建议
- 首先,各大算法孰优孰劣并无定论。 如果刚入门,优先考虑SGD+Nesterov Momentum或者Adam.
- 选择熟悉的算法: 这样可以更加熟练地利用经验进行调参。
- 充分了解数据: 如果模型是非常稀疏的,那么优先考虑自适应学习率的算法
- 根据需求来选择: 在模型设计实验过程中,要快速验证新模型的效果,可以先用Adam;在模型上线或者结果发布之前,可以用精调的SGD进行模型的极致优化。
- 先用小数据集进行实验: 有论文研究指出,随机梯度下降算法的收敛速度和数据集的大小的关系不大。因此可以先用一个具有代表性的小数据集进行实验。
- 考虑不同算法的组合。 先用Adam进行快速下降,而后在换到SGD进行充分的调优。
- 数据集一定要充分的打散: 这样在使用自适应学习率算法的时候,可以避免某些特征集中出现,而导致的有时学习过度、有时学习不足,使得下降方向出现偏差的问题。
- 训练过程中持续监控训练数据和验证数据上的目标函数值以及精度或者AUC等指标的变化情况。 对训练数据的监控是要保证模型进行了充分的训练;对验证数据的监控是为了避免出现过拟合。
- 制定一个合适的学习率衰减策略。 可以使用定期衰减策略,比如每过多少个epoch就衰减一次;或者利用精度或者AUC等性能指标来监控。
BatchNormalization的由来
在CNN训练时,绝大多数都采用基于mini-batch的随机梯度下降算法为基础的算法进行训练;随着输入数据的不断变化,及网络中参数不断调整,网络的各层输入数据的分布则会不断变化,则各层在训练的过程中就需要不断的改变以适应这种新的数据分布,从而造成网络训练困难,难以拟合的问题。
Batch Normalization
在每次SGD时,通过mini-batch来对activation做规范化操作,使得结果(输出信号各个维度)的均值为0,方差为1。最后的scale and shift操作则是为了让因训练所需而可以加入的BN能够有可能还原最初的输入

避免过拟合
只要在训练集中图片中稍加一些噪声,学习机就不能做出正确的判断。过拟合的根本原因:权重参数太多,而样本量不足。避免过拟合方法:早起停止训练,权重衰减,Dropout
早期停止训练
当目标函数在“验证集”上不在减小时,训练就应该停止了。不能一味追求“训练集”的误差减小

权重衰减
有些权重是“无用的”
原梯度下降公式:

经过权重衰减后的公式

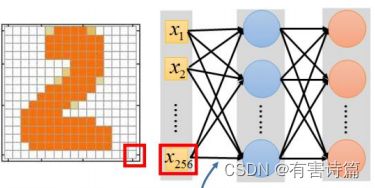
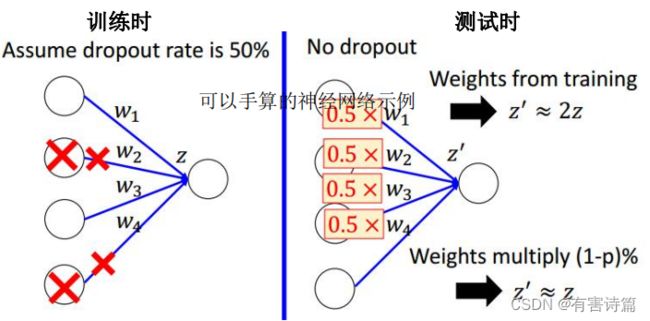
Dropout
每次更新参数前,按一定的比例删减部分神经元,删减后整个网络变得更瘦,本质上,Dropout就是用一小块数据来训练一系列“子网络”;Dropout是集成学习的一种
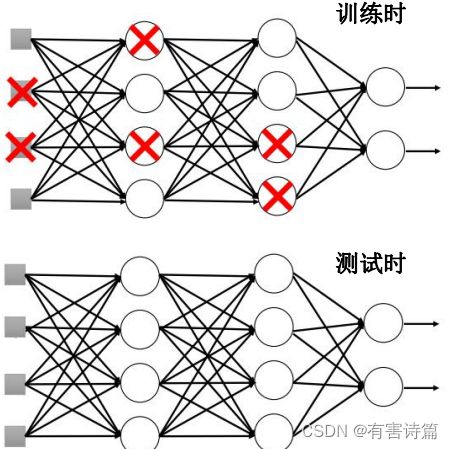
测试时,使用所有的神经元,且权重应根据删减比例缩小
卷积神经网络(CNN)
CNN的基本组件: 卷积层(Convolutional layer),激活函数,池化层(平均池化,最大化池化),全连接层。

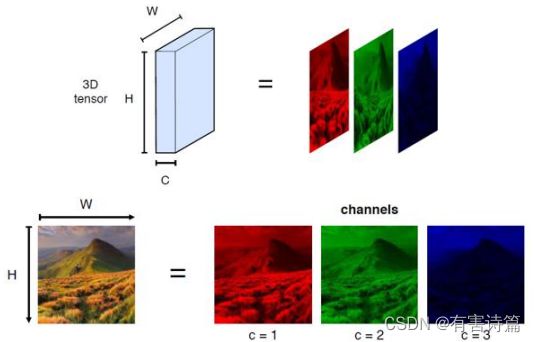
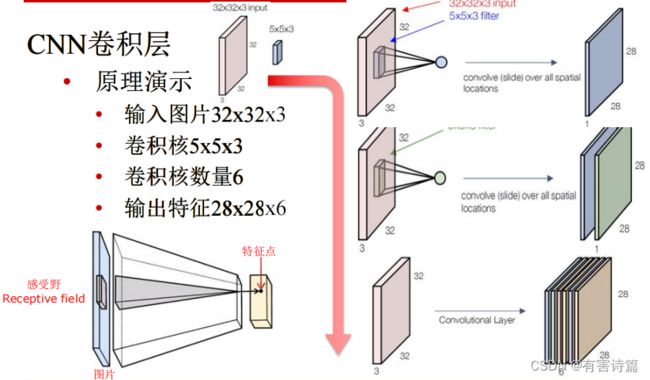
CNN卷积层
3通道(RGB)输入图片→3D tensor
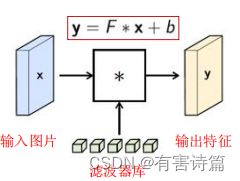
3D滤波层/卷积核:以扫描的方式,对图像做卷积。每层含有多个核,每个核对应一个输出通道。提取局部特征,权重参数需要学习。


超参数:滤波器/卷积核数量,核尺寸,步长,零填充
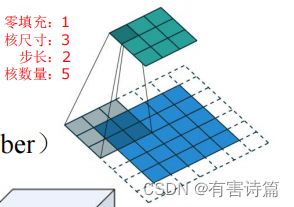

尺寸计算:

原理演示
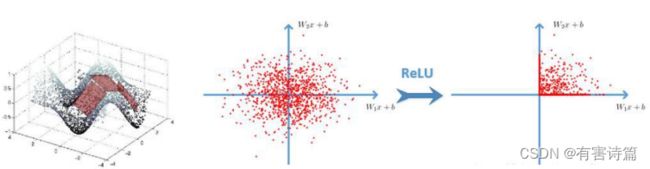
非线性激活函数:sigmoid,ReLU

ReLU激活函数: 分段线性函数,无饱和问题,明显减轻梯度消失问题,深度网络能够进行优化的关键
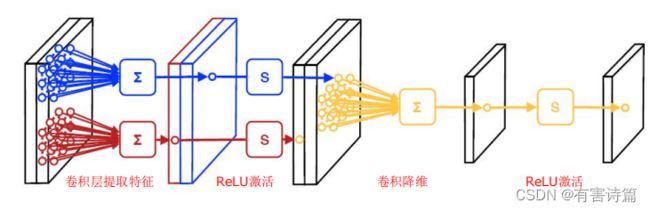
卷积步长大于1,有降维作用
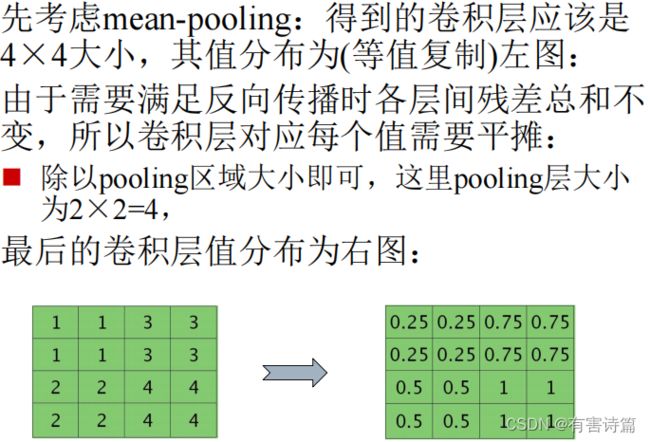
**CNN池化层:**作用:特征融合,降维,五参数需要学习,超参数:尺寸,步长。

Softmax层:指数归一化函数,将一个实数值向量压缩到(0,1),所有元素和为1.
最后一个全连接层对接1000-way的softmax层,得出1000类标签的概率值,用于构建loss
池化层的误差反向传播


卷积层运算
假设我们要处理如下卷积操作:
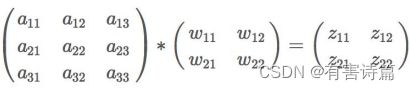
这个操作完全不同于全连接层的操作,可以把卷积操作表示成下面的等式:
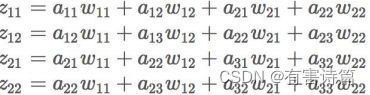
卷积操作一般是要卷积核旋转180度再相乘的,但由于CNN中的卷积参数本来就是训练过程“学”出来的,所以旋转不旋转,关系其实不大
**卷积层运算的展开表示:**左边青色的神经元表示a11到a33,中间橙色的表示z11到z22。注意:青色和橙色神经元之间的权值连接用了不同的颜色标出,紫色线表示W11,蓝色线表示w12,依此类推。

卷积层的误差反向传播




第L-1层某个通道图,大小为3x3,第L层有2个特征核,核大小为2x2,则在前向传播卷积时第L层会有2个大小为2X2的卷积图
假设两个卷积核分别为:

反向传播求误差敏感项时,假设已经知道第L层2个卷积图的残差。

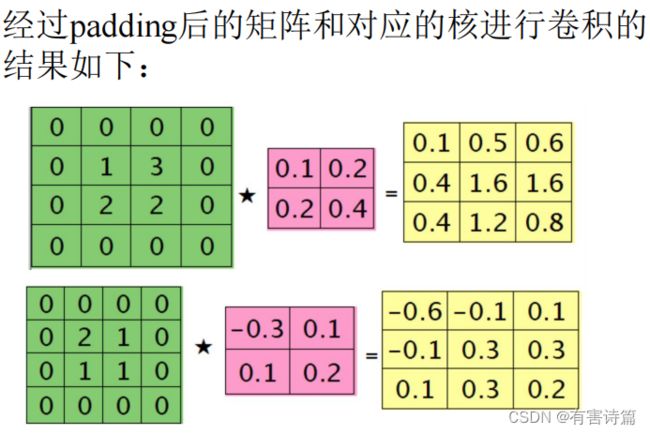
第L-1层中每个通道图对应有自己的残差,其计算依据为第L层所有的特征和的贡献之和。即,求第i个通道的残差是需要将第L层的所有核都计算一遍,然后求和。本质上还是BP算法,只不过这里是有重叠的,第L-1层中某个点会对第L层中的多个点有影响。

