MongoDB+集成SpringBoot+索引+并发优化 - 基于《MongoDB进阶与实战:唐卓章》
文章目录
- MongoDB - 基于《MongoDB进阶与实战:唐卓章》
-
- 一、首次安装
-
- 服务安装
- 配置文件修改
- 可视化工具
- Docker部署
- 二、基本使用
-
- 2.1 概念解析
- 2.2 MongoShell增删改查
-
- 创建集合
- 删除集合
- 插入/更新/删除/查询文档
- Limit/Skip/Sort(排序)/Aggregate(聚合)
- 2.3 索引基础
- 2.4 数据模型(BSON)
- 2.5 SpringBoot集成
- 2.6 审计实现
- 2.7 异步驱动
- 2.8 监听接口
- 2.9 自定义序列化方式
-
- 去掉_class属性
- 实体类中属性为对象的处理
- 三、架构部署(一)
-
- 3.1 集群
-
- 简述
- 实时复制
- 复制延迟/数据回滚
- 初始化同步
- 集群部署
- 3.2 分片
- 3.3 性能基准
-
- WiredTiger缓存引擎介绍
- 性能监控工具
- 压力测试工具YCSB
- nmon监视服务器性能
- 3.4 索引高级
-
- 覆盖索引
- explain
- 待补充.....
- 四、并发处理
-
- 4.1 内置锁
- 4.2 MVCC
- 4.3 Java实现MongoDB分布式锁
- 4.4 应用设计
- 五、高级特性
-
- 5.1 待补充
- 六、架构管理(二)
-
- 6.1 安全管理
-
- 角色(roles)管理
- 6.2 高可用
- 6.3 数据治理
- over
MongoDB - 基于《MongoDB进阶与实战:唐卓章》
| 文章目录 |
|---|
| MongoDB 官方网址 Community Download | MongoDB |
| MongoDB 教程 | 菜鸟教程 (runoob.com) |
| 了解 MongoDB 看这一篇就够了【华为云分享】_华为云官方博客-CSDN博客 |
| MongoDB CRUD操作 - MongoDB-CN-Manual (mongoing.com) |
一、首次安装
服务安装
CentOS
## 安装依赖
yum -y install libcurl openssl
## 从官网下载包,安装
wget -i -c https://repo.mongodb.org/yum/redhat/7/mongodb-org/5.0/x86_64/RPMS/mongodb-org-server-5.0.3-1.el7.x86_64.rpm
rpm -ivh mongodb-org-server-5.0.3-1.el7.x86_64.rpm
## 启动
systemctl restart mongod
systemctl status mongod
然后来看看它的默认端口27017

配置文件修改
vim /etc/mongod.conf

可视化工具
MongoDB Compass Download | MongoDB
就无脑安装,没啥说明的,可惜的是好像没有CentOS版本,所以我装了Windows版
开始连接
Docker部署
Docker 安装 MongoDB | 菜鸟教程 (runoob.com)
二、基本使用
通过Linux命令行进入数据
root@9ac1e753f9ba:/# mongo
MongoDB shell version v5.0.3
connecting to: mongodb://127.0.0.1:27017/?compressors=disabled&gssapiServiceName=mongodb
Implicit session: session { "id" : UUID("93ea0c3d-6584-4668-b716-b13f27a88622") }
MongoDB server version: 5.0.3
================
Warning: the "mongo" shell has been superseded by "mongosh",
which delivers improved usability and compatibility.The "mongo" shell has been deprecated and will be removed in
an upcoming release.
We recommend you begin using "mongosh".
For installation instructions, see
https://docs.mongodb.com/mongodb-shell/install/
================
Welcome to the MongoDB shell.
For interactive help, type "help".
For more comprehensive documentation, see
https://docs.mongodb.com/
Questions? Try the MongoDB Developer Community Forums
https://community.mongodb.com
---
The server generated these startup warnings when booting:
2021-11-12T04:57:02.666+00:00: Access control is not enabled for the database. Read and write access to data and configuration is unrestricted
2021-11-12T04:57:02.666+00:00: /sys/kernel/mm/transparent_hugepage/enabled is 'always'. We suggest setting it to 'never'
2021-11-12T04:57:02.666+00:00: /sys/kernel/mm/transparent_hugepage/defrag is 'always'. We suggest setting it to 'never'
---
---
Enable MongoDB's free cloud-based monitoring service, which will then receive and display
metrics about your deployment (disk utilization, CPU, operation statistics, etc).
The monitoring data will be available on a MongoDB website with a unique URL accessible to you
and anyone you share the URL with. MongoDB may use this information to make product
improvements and to suggest MongoDB products and deployment options to you.
To enable free monitoring, run the following command: db.enableFreeMonitoring()
To permanently disable this reminder, run the following command: db.disableFreeMonitoring()
---
> show dbs
admin 0.000GB
config 0.000GB
local 0.000GB
>
2.1 概念解析
宏观SQL与MongoDB
| SQL术语/概念 | MongoDB术语/概念 | 解释/说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
聚合(aggregate)
数据统计,类似于SQL中的count(*)
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", num_tutorial : { s u m : " sum : " sum:"likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", num_tutorial : { a v g : " avg : " avg:"likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", num_tutorial : { m i n : " min : " min:"likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", num_tutorial : { m a x : " max : " max:"likes"}}}]) |
| $push | 将值加入一个数组中,不会判断是否有重复的值。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", url : { p u s h : " push: " push:"url"}}}]) |
| $addToSet | 将值加入一个数组中,会判断是否有重复的值,若相同的值在数组中已经存在了,则不加入。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", url : { a d d T o S e t : " addToSet : " addToSet:"url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", first_url : { f i r s t : " first : " first:"url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{KaTeX parse error: Expected '}', got 'EOF' at end of input: …roup : {_id : "by_user", last_url : { l a s t : " last : " last:"url"}}}]) |
2.2 MongoShell增删改查
创建集合
## 语法 name名称 options可选参数
db.createCollection(name, options)
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。 当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值,即字节数。 如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
删除集合
## delete collectionName
db.collection.drop()
## show All collection
show collections
插入/更新/删除/查询文档
插入
## insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据
db.COLLECTION_NAME.insert(document)
## 如果 _id 主键存在则更新数据,如果不存在就插入数据
db.collection.insertOne()
db.collection.replaceOne()
## 插入多个文档
db.collection.insertMany()
更新
## query : update的查询条件,类似sql update查询内where后面的
## update : update的对象和一些更新的操作符(如$,$inc...)等,也可以理解为sql update查询内set后面的
## upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入
## multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新
## writeConcern :可选,抛出异常的级别
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
删除
## query :(可选)删除的文档的条件
## justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档
## writeConcern :(可选)抛出异常的级别
db.collection.remove(
<query>,
{
justOne: <boolean>,
writeConcern: <document>
}
)
查询
## query :可选,使用查询操作符指定查询条件
## projection :可选,使用投影操作符指定返回的键。查询时返回文档中所有键值, 只需省略该参数即可(默认省略)
db.collection.find(query, projection)
## 易读格式
db.col.find().pretty()
条件依赖
| 操作 | 格式 | 范例 | RDBMS中的类似语句 |
|---|---|---|---|
| 等于 | {} |
db.col.find({"by":"菜鸟教程"}).pretty() |
where by = '菜鸟教程' |
| 小于 | { |
db.col.find({"likes":{$lt:50}}).pretty() |
where likes < 50 |
| 小于或等于 | { |
db.col.find({"likes":{$lte:50}}).pretty() |
where likes <= 50 |
| 大于 | { |
db.col.find({"likes":{$gt:50}}).pretty() |
where likes > 50 |
| 大于或等于 | { |
db.col.find({"likes":{$gte:50}}).pretty() |
where likes >= 50 |
| 不等于 | { |
db.col.find({"likes":{$ne:50}}).pretty() |
where likes != 50 |
Limit/Skip/Sort(排序)/Aggregate(聚合)
- Limit/Skip 就是类似于SQL中的limit,显示多少行,跳过多少行
- Sort() 指定某个字段进行排序,就是order by
- Aggregate() 统计平均值的,类似于count(*)
2.3 索引基础
-
按字段数量分类,分为单键索引和组合索引(或复合索引)
-
按字段类型,可以分为主键索引和非主键索引
-
索引节点与物理记录的对应方式来分,可以分为聚簇索引和非聚簇索引
-
按照索引的特性不同,又可以分为唯一索引、稀疏索引、文本索引、地理空间索引等
底层也是B+树的结构,但是跟其他NoSQL不一样的是,它可以跟普通的SQL数据库一样进行**explain()**调优
## 语法格式
db.collection.createIndex(keys, options)
## Key 为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 “background” 可选参数。 “background” 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | **3.0+版本已废弃。**在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
## 查看集合索引
db.col.getIndexes()
## 查看集合索引大小
db.col.totalIndexSize()
## 删除集合所有索引
db.col.dropIndexes()
## 删除集合指定索引
db.col.dropIndex("索引名称")
另外,还有条件索引,文本索引,模糊索引
接下来看看索引优化怎么玩
db.demo_collection_test.explain().find({"title":"标题"})
{ explainVersion: '1',
queryPlanner:
{ namespace: 'demodb01.demo_collection_test',
indexFilterSet: false,
parsedQuery: { title: { '$eq': '标题' } },
queryHash: '6E0D6672',
planCacheKey: '1953B8BB',
maxIndexedOrSolutionsReached: false,
maxIndexedAndSolutionsReached: false,
maxScansToExplodeReached: false,
## 表示获胜的计划
winningPlan:
{
## 扫描形式,stage=COLLSCAN则说明这是一个全表扫描
stage: 'FETCH',
inputStage:
{
## 未能命中索引结果,会显示 COLLSCAN
## 命中索引的结果,使用 IXSCAN
## 出现了内存排序,显示为 SORT
stage: 'IXSCAN',
keyPattern: { title: 1 },
indexName: 'title_1',
isMultiKey: false,
multiKeyPaths: { title: [] },
isUnique: false,
isSparse: false,
isPartial: false,
indexVersion: 2,
direction: 'forward',
indexBounds: { title: [ '["标题", "标题"]' ] } } },
rejectedPlans: [] },
command:
{ find: 'demo_collection_test',
filter: { title: '标题' },
'$db': 'demodb01' },
serverInfo:
{ host: '9ac1e753f9ba',
port: 27017,
version: '5.0.3',
gitVersion: '657fea5a61a74d7a79df7aff8e4bcf0bc742b748' },
serverParameters:
{ internalQueryFacetBufferSizeBytes: 104857600,
internalQueryFacetMaxOutputDocSizeBytes: 104857600,
internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,
internalDocumentSourceGroupMaxMemoryBytes: 104857600,
internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,
internalQueryProhibitBlockingMergeOnMongoS: 0,
internalQueryMaxAddToSetBytes: 104857600,
internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600 },
ok: 1 }
2.4 数据模型(BSON)
BSON(Binary JSON)是二进制版本的JSON,有如下数据类型
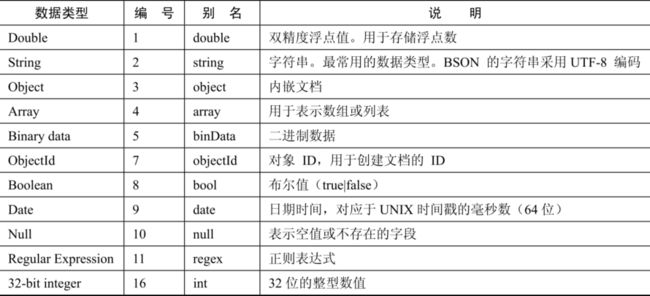

为什么MongoDB需要用到这种数据模型呢?因为在部分数据表示的场景下,默认的JSON数据类型虽然能应对大部分的场景,但是总有一些是不太方便进行表示的,所以引入了BSON作为辅助,其实,在整个mongoDB中,都是使用JSON+BSON作为数据存储格式的
还有一个固定集合的数据类型,放在后面针对SpringBoot进行操作使用
2.5 SpringBoot集成
依赖导入
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.20version>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.13version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<version>2.2.2.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<version>2.2.2.RELEASEversion>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-mongodbartifactId>
<version>2.2.13.RELEASEversion>
dependency>
application.yaml
server:
port: 18081
spring:
data:
mongodb:
uri: mongodb://192.168.247.173:27017/demodb01
application:
name: mongodb-test-01
封装实体类
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import java.io.Serializable;
@Document(collection = "demo_collection_test")
@Data
@AllArgsConstructor
@NoArgsConstructor
public class DemoEntity implements Serializable {
@Id
private Long id;
private String title;
private String description;
}
玩起来
import com.ljm.common.ToResult;
import com.ljm.entity.DemoEntity;
import com.mongodb.client.result.DeleteResult;
import org.springframework.data.mongodb.core.MongoTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.util.List;
@RestController
@RequestMapping("/test")
public class TestController {
@Resource
private MongoTemplate mongoTemplate;
@RequestMapping("/saveOrMongo")
public ToResult saveOrMongo() {
// 插入数据
DemoEntity demoEntity = new DemoEntity(1001L, "我是标题", "我是描述信息");
mongoTemplate.save(demoEntity);
return new ToResult("saveOrMongo", "ok");
}
@RequestMapping("/getOrMongo")
public ToResult getOrMongo() {
// 查询所有
List<DemoEntity> templateAll = mongoTemplate.findAll(DemoEntity.class);
return new ToResult("getOrMongo", templateAll);
}
@RequestMapping("/removeOrMongo")
public ToResult removeOrMongo() {
// 获取集合名称
String collectionName = mongoTemplate.getCollectionName(DemoEntity.class);
DemoEntity demoEntity = new DemoEntity();
demoEntity.setId(1001L);
// delete
DeleteResult result = mongoTemplate.remove(demoEntity, collectionName);
return new ToResult("getOrMongo", result);
}
}
2.6 审计实现
我们可能需要对数据写一些审计字段
-
数据在什么时间创建
-
数据由谁创建
-
数据最近一次发生变化的时间
-
数据最近一次的修改者
我们可以在实体类上加多几个审计字段,或者加AOP,但是那样代码量有点大,所以SpringData提供了非常便利的审计(auditing)功能,这个功能需要在启动类上加注解@EnableMongoAuditing开启
写好审计类,让普通实体类继承于它
import lombok.Data;
import org.springframework.data.annotation.CreatedBy;
import org.springframework.data.annotation.CreatedDate;
import org.springframework.data.annotation.LastModifiedBy;
import org.springframework.data.annotation.LastModifiedDate;
import java.time.LocalDateTime;
/**
* 审计类
*
* @author 李家民
*/
@Data
public class AuditEnt {
/**
* 创建时间
*/
@CreatedDate
private LocalDateTime createdDate;
/**
* 最后修改时间
*/
@LastModifiedDate
private LocalDateTime updatedDate;
/**
* 创建者
*/
@CreatedBy
private String createdBy;
/**
* 最后修改者
*/
@LastModifiedBy
private String updatedBy;
}
除了启动类,@EnableMongoAuditing也可以在包含@Configuration的配置类中添加。,在开启审计功能后,框架在保存审计类对象时,会自动对注解的字段进行注入
-
对于@CreatedDate和@LastModifiedDate注解的字段会采用当前的时间值
-
对于@CreatedBy、@LastModifiedBy注解的字段则通过
AuditorAware接口处理
import org.springframework.data.domain.AuditorAware;
import org.springframework.stereotype.Component;
import java.util.Optional;
@Component
public class AuditAwareImpl implements AuditorAware {
@Override
public Optional getCurrentAuditor() {
// 对于CreatedBy和LastModifiedBy注解的字段的自动注入
// return Optional.empty();
return Optional.of("我是李家民");
}
}
2.7 异步驱动
引入依赖
<dependency>
<groupId>org.mongodbgroupId>
<artifactId>mongodb-driver-reactivestreamsartifactId>
<version>4.3.4version>
dependency>
做这个比较麻烦的可能是,做两个客户端,同步/异步,感觉不如用Future
2.8 监听接口
MongoDB Java Driver从3.1版本起开始增加了CommandListener接口用于支持对于命令操作的监听
import com.mongodb.event.CommandFailedEvent;
import com.mongodb.event.CommandListener;
import com.mongodb.event.CommandStartedEvent;
import com.mongodb.event.CommandSucceededEvent;
import org.springframework.context.annotation.Configuration;
@Configuration
public class TestListener implements CommandListener {
@Override
public void commandStarted(CommandStartedEvent commandStartedEvent) {
// 监听命令启动事件
}
@Override
public void commandSucceeded(CommandSucceededEvent commandSucceededEvent) {
// 监听命令完成事件
}
@Override
public void commandFailed(CommandFailedEvent commandFailedEvent) {
// 监听命令失败事件
}
}
另外,我们还可以通过标准的JMX的监视接口,实现监视驱动的连接数
2.9 自定义序列化方式
去掉_class属性
如果是通过注解@Document实现映射的实体类,在MongoDB中都会出现一个叫_class的字段,里面包含的是该实体类的全限定名路径,其实有些多余,是可以去掉的,通过定制TypeMapper的实现来去掉它,在配置类中进行处理
@Bean
MappingMongoConverter mappingMongoConverter(
MongoDbFactory factory,
MongoMappingContext context,
MongoCustomConversions conversions
){
DefaultDbRefResolver defaultDbRefResolver = new DefaultDbRefResolver(factory);
MappingMongoConverter mongoConverter = new MappingMongoConverter(defaultDbRefResolver, context);
mongoConverter.setCustomConversions(conversions);
// 构造 DefaultMongoTypeMapper 把typeKey设置为空
mongoConverter.setTypeMapper(new DefaultMongoTypeMapper(null));
return mongoConverter;
}
实体类中属性为对象的处理
就是当我们的实体类里面有属性是对象的情况下(且这个对象可能还是键值对的数据结构),就需要进行处理,大概流程如下
- 做两个静态类,实现
Converter接口,分别处理读转换和写转换 - 在
MongoCustomConversions这个Bean中进行注册
自行百度,不写了困了,我先睡一觉
三、架构部署(一)
3.1 集群
简述
集群内部使用Raft选举算法来决定主从关系,但是,如果存在偶数集群节点的情况下可能出现平票
如果希望避免平票结果的产生,最好使用奇数个节点成员,比如3个或5个。当然,在MongoDB副本集的实现中,对于平票问题已经提供了解决方案:
为选举定时器增加少量的随机时间偏差,这样避免各个节点在同一时刻发起选举,提高成功率
使用仲裁者角色,该角色不做数据复制,也不承担读写业务,仅仅用来投票
| 角色名称 | 作用 |
|---|---|
| Primary | 主节点,其接收所有的写请求,然后把修改同步到所有备节点。一个副本集只能有一个主节点,当主节点“挂掉”后,其他节点会重新选举出来一个主节点 |
| Secondary | 备节点,与主节点保持同样的数据集。当主节点“挂掉”时,参与竞选主节点 |
| Arbiter | 仲裁者节点,该节点只参与投票,不能被选为主节点,并且不从主节点中同步数据,是一个可选项的节点 |
| Priority0 | 优先级为0的节点,该节点永远不会被选举为主节点,也不会主动发起选举 |
| Hidden | 隐藏节点,具备Priority0的特性,即不能被选为主节点(Priority为0),同时该节点对客户端不可见。由于隐藏节点不会接受业务访问,因此可通过隐藏节点做一些数据备份、离线计算的任务,这并不会影响整个副本集 |
| Delayed | 延迟节点,必须同时具备隐藏节点和Priority0的特性,并且其数据落后于主节点一段时间,该时间是可配置的。由于延迟节点的数据比主节点落后一段时间,当错误或者无效的数据写入主节点时,可通过延迟节点的数据来恢复到之前的时间点 |
| Vote0 | 无投票权的节点,必须同时设定为Priority0节点。由于一个副本集中最多只有7个投票成员,因此多出来的成员则必须将其vote属性值设置为0,即这些成员将无法参与投票 |
集群副本集的模式有这几种
-
PSS
一主两备
-
PSA
一个主节点、一个备节点和一个仲裁者节点
-
PSH
一个主节点、一个备节点和一个隐藏节点
实时复制
主备节点之间同步数据是用oplog来操作的,这是一个固定集合,也可以看作是一个先入先出(FIFO)的缓冲队列
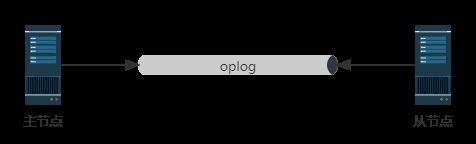
主节点(生产者)不断地往里面写入增量日志,写满多出来的,先入先出删除,而从节点(消费者)不断地pull拉取
一个oplog结构如下

字段解释

其中,ts字段描述了oplog产生的时间戳,可称之为optime,optime是备节点实现增量日志同步的关键,每一条oplog记录都描述了一次数据的原子性变更,对于oplog来说,必须保证是幂等性的
复制延迟/数据回滚
因为oplog集合是一个固定集合,先入先出的,如果从节点复制的不够快,就会导致有部分记录没有保存到而被冲刷,一旦时间撕裂过大就会导致更严重的问题,所以需要采取一些措施
-
增加oplog的容量大小,并保持对复制窗口的监视
-
通过一些扩展手段降低主节点的写入速度
-
优化主备节点之间的网络
- 避免字段使用太大的数组(可能导致oplog膨胀)
oplog集合的大小可以通过参数replication.oplogSizeMB设置,对于64位系统来说,oplog的默认值为
oplogSizeMB = min(磁盘可用空间 * 5% , 50GB)
但是,由于上述的情况始终是无法完全避免的,所以我们就提出数据回滚的概念
当副本集中的主节点宕机时,备节点会重新选举成为新的主节点。那么,当旧的主节点重新加入时,必须回滚掉之前的一些“脏日志数据”,以保证数据集与新的主节点一致。主备复制集合的差距越大,发生大量数据回滚的风险就越高
这些由旧主节点回滚的数据会被写到单独的rollback目录下,必要的情况下仍然可以恢复这些数据
初始化同步
在开始时,备节点仍然需要向主节点获得一份全量的数据用于建立基本快照,这个过程就称为初始化同步(initial sync)
我们来看看整个同步的过程
- 备节点记录主节点的同步时间戳optime=t1
- 从主节点上复制所有非local数据库的集合数据,同时创建这些集合上的索引
- 备节点fork出一个线程,将集合复制过程中的增量oplog(t1之后产生)也复制到本地
上述描述的是主从之间的同步,但是实际上,备节点之间也可以进行同步,这里不再阐述细节
集群部署
baidu.com
就不写了,大概流程是
- 配置好相应的公共文件mongo.conf,启动时使用–replSet集群模式
- 进入shell进行配置,做一个变量,把所有节点的地址信息写进去
- 启动集群,开始进入数据复制状态
| 命令 | |
|---|---|
| db.isMaster | 查看副本集的节点信息 |
| rs.status | 对复制成员的监视,members一列体现了所有副本集成员的状态 |
| rs.printReplicationInfo | 查看当前节点oplog的情况 |
| rs.printSlaveReplicationInfo | 所有备节点成员的同步延迟情况 |
3.2 分片
分片(shard)是指在将数据进行水平切分之后,将其存储到多个不同的服务器节点上的一种扩展方式
不写了不写了,baidu.com
3.3 性能基准
WiredTiger缓存引擎介绍
理想情况下,MongoDB可以提供近似内存式的读写性能
WiredTiger引擎实现了数据的二级缓存,第一层是操作系统的页面缓存,第二层则是引擎提供的内部缓存
而在当数据发生写入时,MongoDB并不会立即持久化到磁盘上,而是先在内存中记录这些变更,之后通过CheckPoint机制将变化的数据写入磁盘,所以在单机下,保证数据可靠性的机制分成两个部分
- CheckPoint(检查点)机制:MongoDB每60s建立一次CheckPoint,当建立CheckPoint时,WiredTiger会在内存中建立所有数据的一致性快照,并将该快照覆盖的所有数据变化一并进行持久化(fsync),成功之后,内存中数据的修改才得以真正保存
- Journal日志:如果开启了Journal日志,那么WiredTiger会将每个写操作的redo日志写入Journal缓冲区,该缓冲区会频繁地将日志持久化到磁盘上
默认情况下,WiredTiger会对集合数据和索引使用压缩算法,当页面被写入磁盘时执行压缩,而从磁盘中读入缓存时对页面进行解压
- 对集合采用块压缩
- 对索引采用前缀压缩
性能监控工具
-
mongostat:查看当前的QPS/内存使用/连接数
123123
-
mongotop:查看数据库的热点表
123123
-
Profiler:记录、分析MongoDB的详细操作日志,可以设置开启级别

## 开启日志等级 db.setProfilingLevel(2) { was: 0, slowms: 100, sampleRate: 1, ok: 1 } ## 查看日志 db.system.profile.find() { op: 'update', ns: 'demodb01.demo_collection_test', command: { q: { _id: 1001 }, u: { _id: 1001, title: '我是标题', description: '我是描述信息' }, multi: false, upsert: true }, keysExamined: 1, docsExamined: 1, nMatched: 1, nModified: 1, nUpserted: 0, keysInserted: 0, keysDeleted: 0, numYield: 0, locks: { ParallelBatchWriterMode: { acquireCount: { r: 1 } }, ReplicationStateTransition: { acquireCount: { w: 1 } }, Global: { acquireCount: { w: 1 } }, Database: { acquireCount: { w: 1 } }, Collection: { acquireCount: { w: 1 } }, Mutex: { acquireCount: { r: 1 } } }, flowControl: { acquireCount: 1, timeAcquiringMicros: 2 }, millis: 0, planSummary: 'IDHACK', execStats: { stage: 'UPDATE', nReturned: 0, executionTimeMillisEstimate: 0, works: 2, advanced: 0, needTime: 1, needYield: 0, saveState: 0, restoreState: 0, isEOF: 1, nMatched: 1, nWouldModify: 1, nWouldUpsert: 0, inputStage: { stage: 'IDHACK', nReturned: 1, executionTimeMillisEstimate: 0, works: 1, advanced: 1, needTime: 0, needYield: 0, saveState: 1, restoreState: 1, isEOF: 1, keysExamined: 1, docsExamined: 1 } }, ts: 2021-11-14T08:37:15.597Z, client: '192.168.247.1', allUsers: [], user: '' }
不写了,还有好几个
压力测试工具YCSB
是一个Java写的,雅虎提供的用于云服务的压测工具
nmon监视服务器性能
yum -y install nmon
3.4 索引高级
MongoDB和elasticsearch一样,都是用B+树和聚簇索引/非聚簇索引
覆盖索引
是一种查询优化的行为
我们知道,在一棵二级索引的B+树上,索引的值存在于树的叶子节点上,因此,如果我们希望查询的字段被包含在索引中,则直接查找二级索引树就可以获得,而不需要再次通过_id索引查找出原始的文档,可以减少一次对最终文档数据的检索操作(该操作也被称为回表)。大部分情况下,二级索引树常驻在内存中,覆盖索引式的查询可以保证一次检索行为仅仅发生在内存中,即避免了对磁盘的I/O操作,这对于性能的提升有显著的效果。
实际场景:我只查询索引的字段实现覆盖索引优化,不用去进行磁盘I/O的动作(索引的值存在于树的叶子节点上)
explain
有三种执行模式
- queryPlanner:默认的模式,仅进行查询计划分析,输出计划中的阶段信息
- executionStats:执行模式,在查询计划分析后,将按照winningPlan执行查询并统计过程信息
- allPlansExecution:全计划执行模式,将执行所有计划(包括winningPlan和rejectPlans),并返回全部的过程统计信息
待补充…
还有使用图形化界面进行索引优化的
索引优化原则
- 使用前缀匹配
- 避免低效的操作符
- 使用覆盖索引优化
- 高基数优先原则
- 控制索引的数量
- 避免设计过长的数组索引
- 避免创建重复的索引
- 删除无用的索引
- 避免深度分页
- 避免一次性返回大量结果集
- 谨防内存排序
- 避免大量的扫描
- 为索引预留足够的内存
四、并发处理
4.1 内置锁
MongoDB采用多粒度锁机制,针对不同层级的数据库对象进行加锁
- Global 全局
- Database 数据库
- Collection 集合
- Document 文档(WiredTiger引擎内部使用乐观锁方式实现)
同时,针对不同的读写方式,又分为如下几种锁类型
-
读锁(R),代表共享锁(S)
-
写锁(W),代表排它锁(X)
-
意向读锁(r),代表意向的共享锁(IS)
-
意向写锁(w),代表意向的排它锁(IX)
MongoDB锁的兼容

接下来解释一下什么叫意向锁,此时我们需要更新某种表的某一条记录,需要经过的流程有
- Global 增加意向写锁
- Database 增加意向写锁
- Collection 增加意向写锁
- 对这一行记录执行更新(乐观锁)
如果这个时候,有其他操作进入
- 对其他行记录执行更新,不同用户文档的写操作便不会产生互斥了(同一集合的意向写锁可以存在多个)
- 修改表名,对Collection增加写锁(互斥,必须要等该表下的操作进行结束)
常见操作对应的锁

可以通过命令db.currentOp()查看锁的状态,并且在某些情况下,锁会出现让步(例如某些操作过于长时间未执行完成)
4.2 MVCC
MVCC(Multi Version Concurrency Control)的多版本并发控制,是行级锁的一种妥协
是目前数据库中使用最广泛的一种经典机制,包括MongoDB、MySQL、PostGreSQL等流行数据库都在使用
4.3 Java实现MongoDB分布式锁
这个问题我想了一下,有如下几种解决方案
- 原生的MongoDB处理
- Zookeeper
- Redis
我比较推崇用Redis,数据驻于内存,性能高,并且有分布式锁框架,支持重入
4.4 应用设计
三范式,批处理。。。。
五、高级特性
5.1 待补充
1
六、架构管理(二)
6.1 安全管理
角色(roles)管理
MongoDB 4.0 角色(roles)详解_m0_37867491的CSDN博客
数据库用户角色(Database User Roles)
- read : 授权User只读数据的权限,允许用户读取指定的数据库
- readWrite 授权User读/写数据的权限,允许用户读/写指定的数据库
数据库管理角色(Database Admininstration Roles)
- dbAdmin:在当前的数据库中执行管理操作,如索引的创建、删除、统计、查看等
- dbOwner:在当前的数据库中执行任意操作,增、删、改、查等
- userAdmin :在当前的数据库中管理User,创建、删除和管理用户
备份和还原角色(Backup and Restoration Roles)
- backup
- restore
跨库角色(All-Database Roles)
- readAnyDatabase:授权在所有的数据库上读取数据的权限,只在admin 中可用
- readWriteAnyDatabase:授权在所有的数据库上读写数据的权限,只在admin 中可用
- userAdminAnyDatabase:授权在所有的数据库上管理User的权限,只在admin中可用
- dbAdminAnyDatabase: 授权管理所有数据库的权限,只在admin 中可用
集群管理角色(Cluster Administration Roles)
- clusterAdmin:授权管理集群的最高权限,只在admin中可用
- clusterManager:授权管理和监控集群的权限
- clusterMonoitor:授权监控集群的权限,对监控工具具有readonly的权限
- hostManager:管理server
超级角色(super master Roles)
- root :超级账户和权限,只在admin中可用
6.2 高可用
1
6.3 数据治理
1