Redis之Redis集群、持久化到mysql、与mysql数据同步
一、Redis集群
1.Redis集群介绍及环境搭建
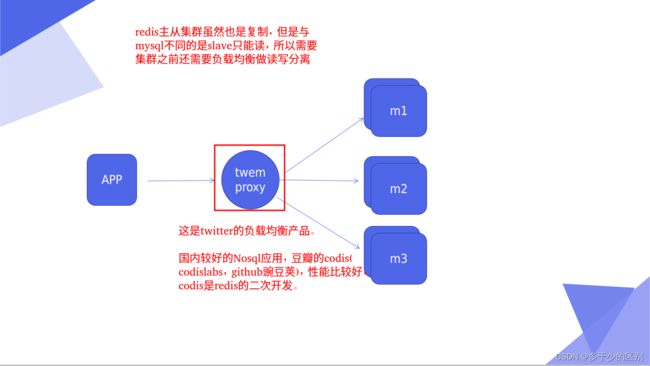
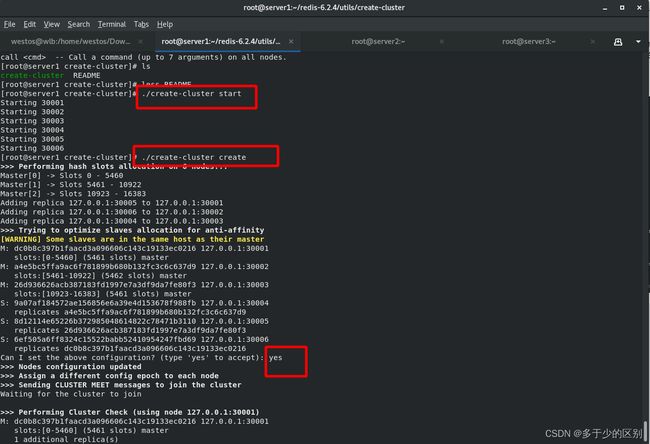
 redis集群需要开多个redis实例,如果每个实例开一台虚拟机的话,需要的资源太多了,所以下面用源码自带的脚本在一台主机上开多个实例并组建集群。
redis集群需要开多个redis实例,如果每个实例开一台虚拟机的话,需要的资源太多了,所以下面用源码自带的脚本在一台主机上开多个实例并组建集群。
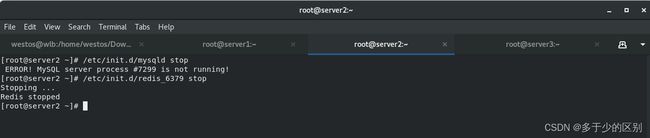
关闭之前实验的sentinel,因为redis集群自带高可用。
先关闭之前实验所创建的redis实例以及mysql。

使用源码自带的脚本创建多个redis实例
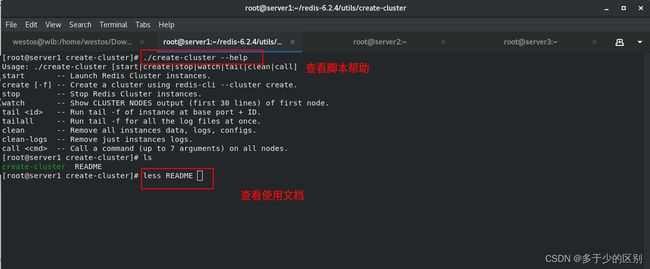
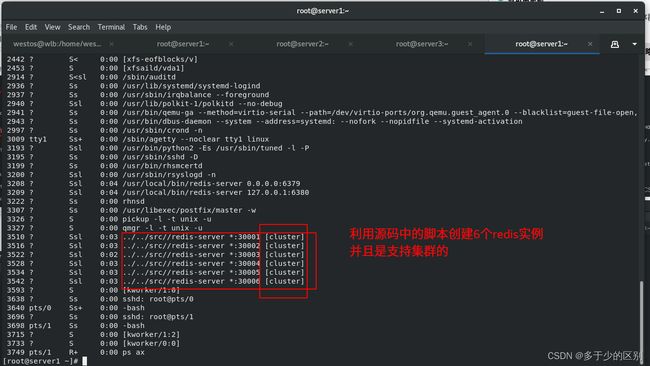
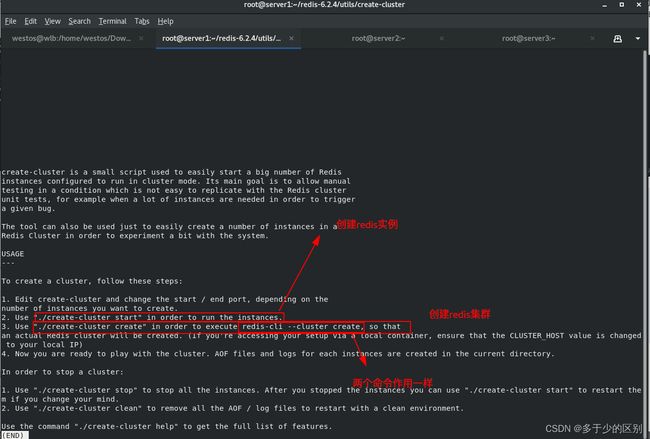 创建6个redis实例可以理解为6个节点(不想开太多虚拟机,所以在一个主机上创建了6个实例),再利用create命令组成集群
创建6个redis实例可以理解为6个节点(不想开太多虚拟机,所以在一个主机上创建了6个实例),再利用create命令组成集群
六个redis实例组成3组一主一从架构
2.redis集群管理
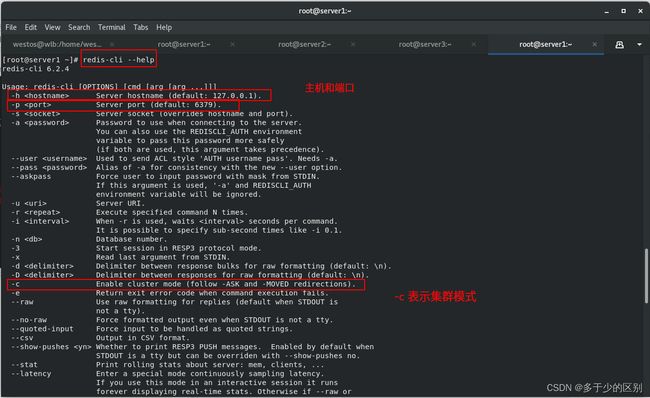
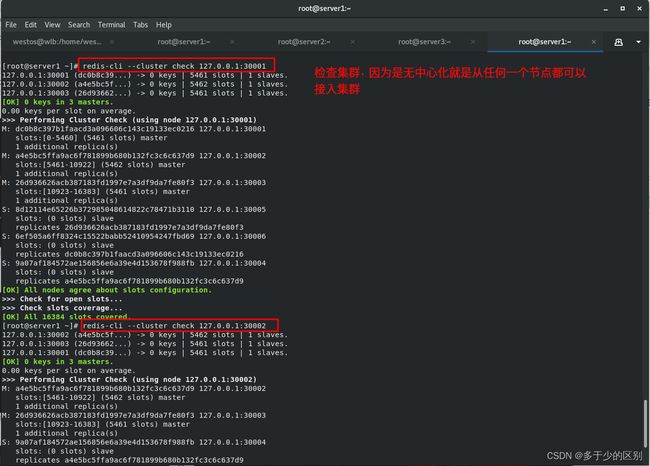
通过redis-cli命令接入集群以及管理集群
[root@server1 ~]# redis-cli -c -p 30001 #接入集群
127.0.0.1:30001>
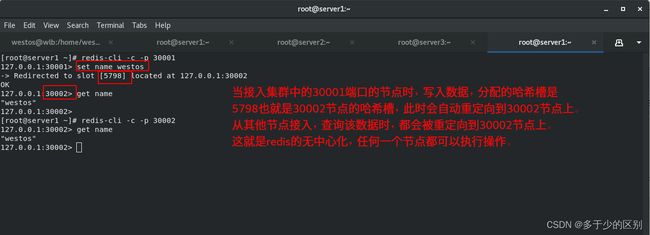
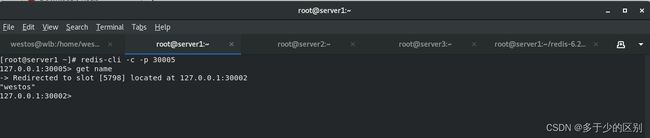
redis集群是无中心化,也就是说从任何一个节点都可以接入集群

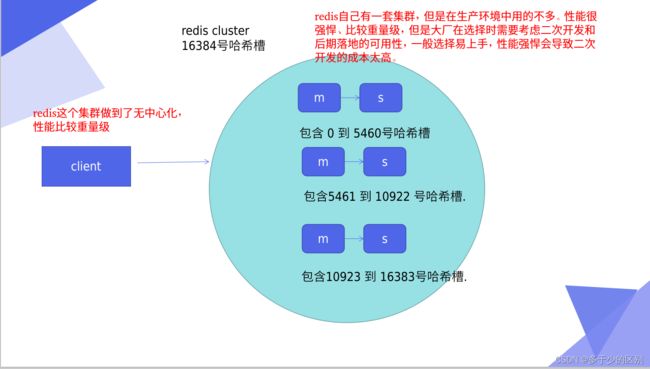
Redis集群介绍
Redis集群是无中心化,从任何一个节点都可以接入集群。整个集群维护了16384个哈希槽(也就是存数据的地方),16384个哈希槽默认由集群中的master节点平分,也可以自己定义。
Redis 集群的数据分片
Redis 集群没有使用一致性hash, 而是引入了 哈希槽的概念.
Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来决定放置哪个槽.集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:
- 节点 A 包含 0 到 5500号哈希槽.
- 节点 B 包含5501 到 11000 号哈希槽.
- 节点 C 包含11001 到 16384号哈希槽.
这种结构很容易添加或者删除节点. 比如如果我想新添加个节点D, 我需要从节点 A, B, C中得部分槽到D上. 如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可. 由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态.

注意当这16384个哈希槽,任何一个出现了问题,导致集群哈希槽不完整,集群就不可用。好在集群自带了负载均衡和高可用,也不需要做读写分离,因为任何一个节点都可以读写,只要在外层加一层负载均衡就行,nginx、hproxy七层或者lvs四层负载均衡,不需要做端口转发。
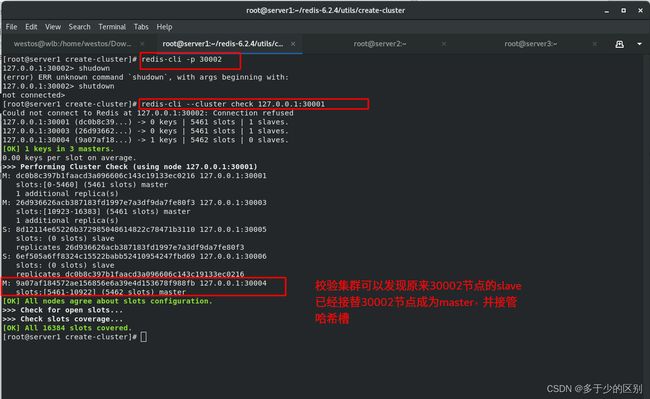
停掉master节点,再校验集群
 使用脚本,重启实例
使用脚本,重启实例
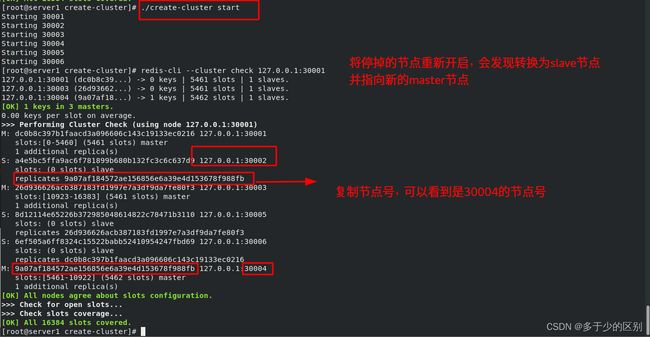
当主从节点都挂掉时,哈希槽将不再完整,集群不可用。
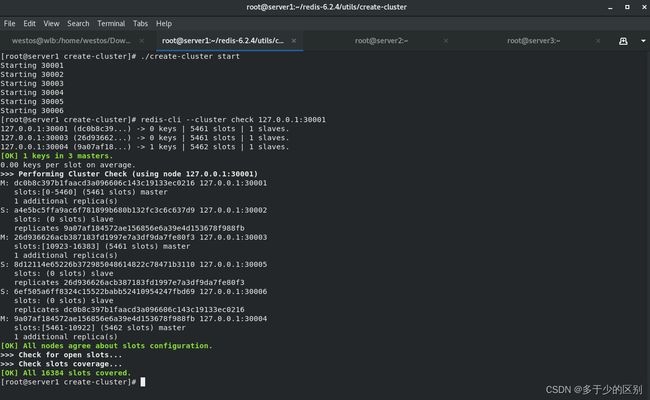
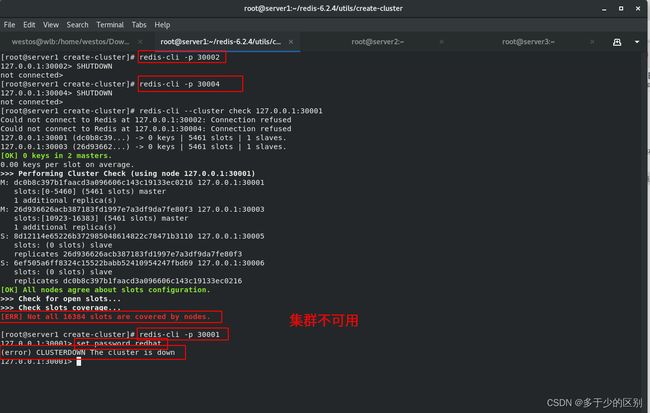 恢复集群
恢复集群
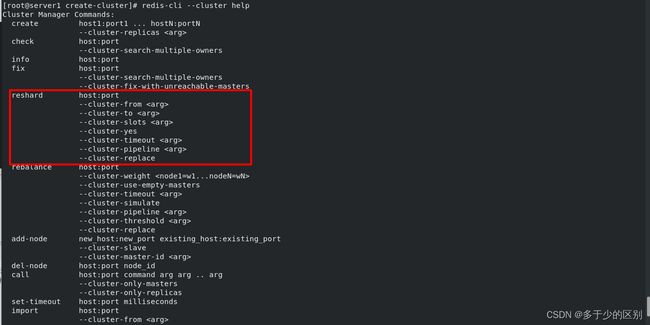
3.扩展redis集群节点并分配哈希槽
修改脚本增加两个节点
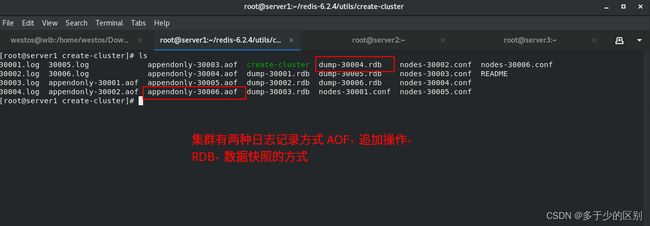
appendonly类似于mysql的二进制日志追加的方式,RDB用于主从复制是一个内存快照
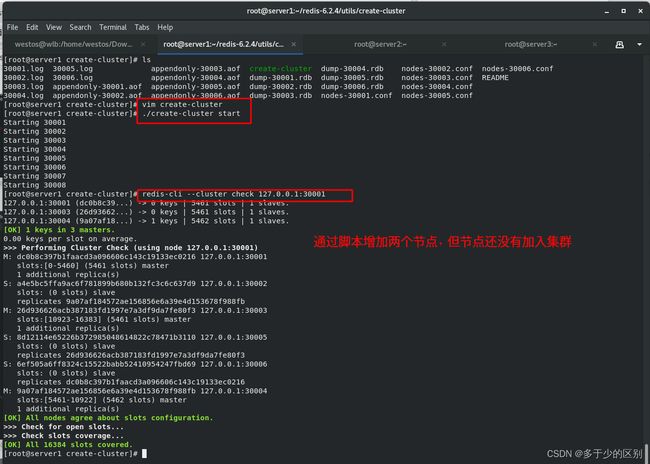
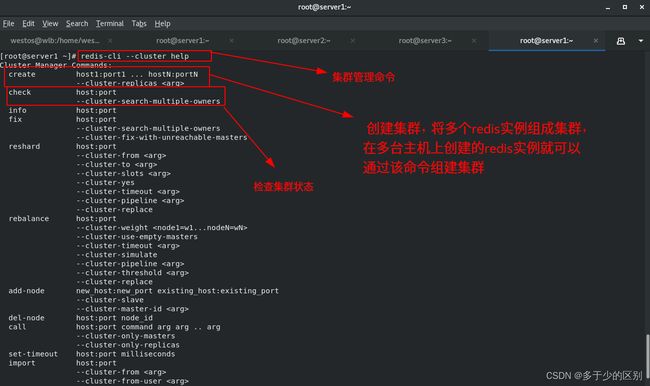
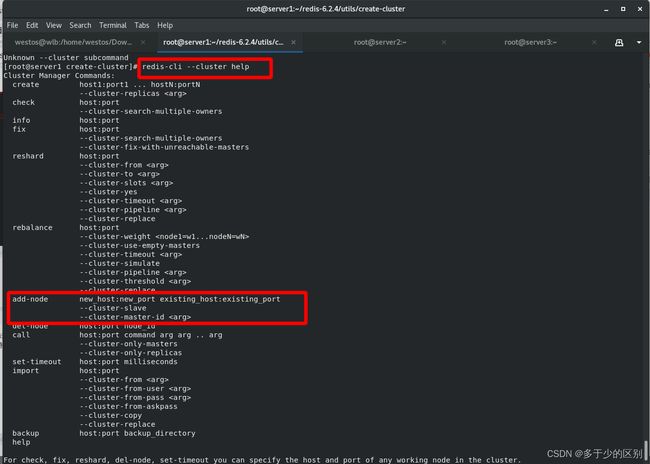
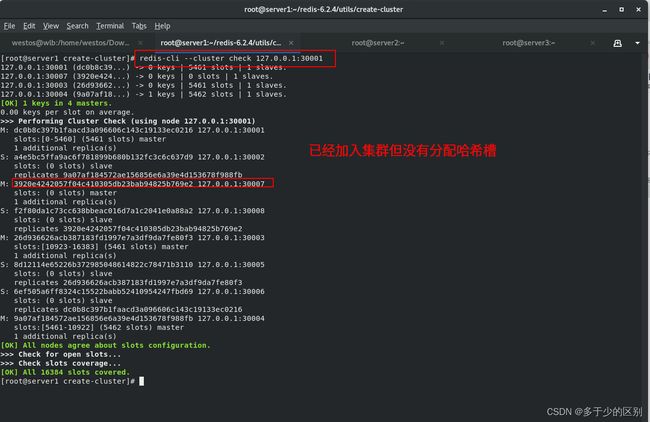
将节点添加到集群
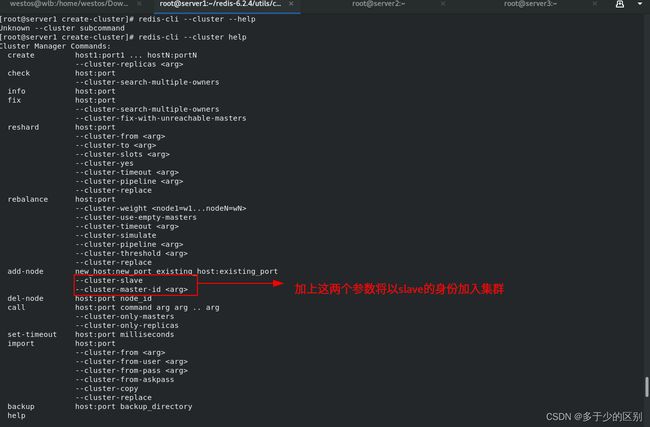
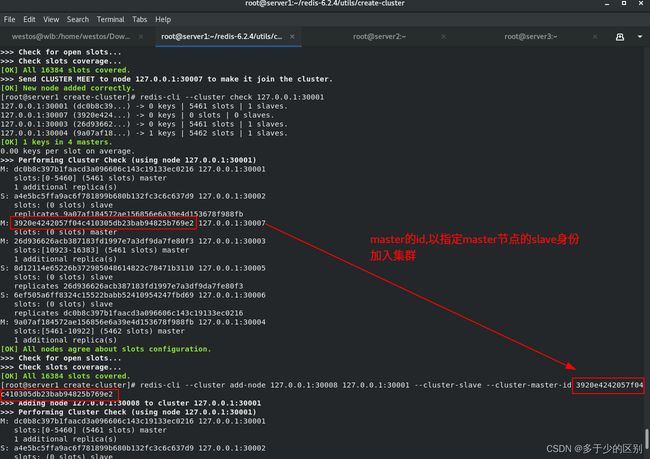
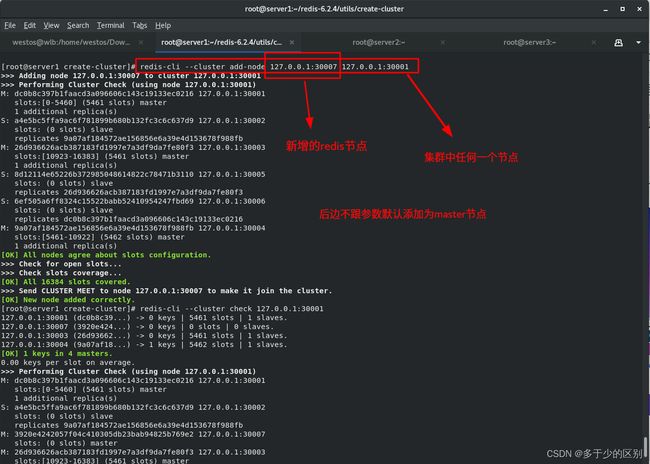 将30008节点以30007节点slave的身份加入集群
将30008节点以30007节点slave的身份加入集群
从集群中其他节点迁移哈希槽给新master节点


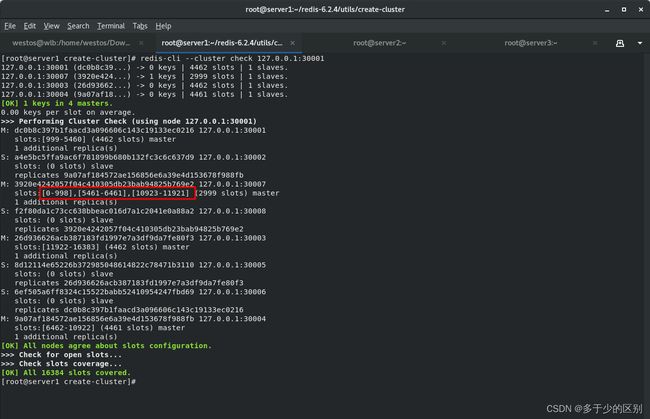
在不同节点上搭建并使用Redis集群方法

回收集群
关闭slave节点,并清除节点

二、redis持久化
Redis的数据是全部存储在内存中的,如果机器突然GG,那么数据就会全部丢失,因此需要有持久化机制来保证数据不会因为宕机而丢失。Redis 提供了以下几种不同的持久化方案。
- 利用 RDB 持久化在指定的时间间隔生成数据集的时间点快照(point-in-time );
- 利用 AOF(Append Only File) 持久化将服务器收到的所有写操作命令记录下来,并在服务器重新启动的时候,利用这些命令来恢复数据集。AOF 的命令使用的是与 Redis 本身协议的命令一致,通过追加的方式将数据写入备份文件中,同时当备份文件过大时,Redis 也能对备份文件进行重压缩。
- 如果仅希望数据只在数据库运行时存在,那么还可以完全禁用掉持久化机制;
- Redis还可以同时使用 AOF 持久化和 RDB 持久化。在这种情况下,当 AOF 重启时,会优先使用 AOF 文件去恢复原始数据。因为 AOF 中保存的数据通常比 RDB 中保存的数据更加完整。
RDB 持久化方案与 AOF 持久化方案之间的异同
RDB 持久化
RDB(Redis Database) 通过快照的形式将数据保存到磁盘中。所谓快照,可以理解为在某一时间点将数据集拍照并保存下来。Redis 通过这种方式可以在指定的时间间隔或者执行特定命令时将当前系统中的数据保存备份,以二进制的形式写入磁盘中,默认文件名为dump.rdb。
RDB 的触发有三种机制,执行save命令;执行bgsave命令;在redis.config中配置自动化。
三种机制相关介绍
RDB的优劣
优势:
- RDB 是一个非常紧凑(compact)的文件(保存二进制数据),它保存了 Redis 在某个时间点上的数据集。 这种文件非常适合用于进行备份: 比如说,你可以在最近的 24 小时内,每小时备份一次 RDB 文件,并且在每个月的每一天,也备份一个 RDB 文件。 这样的话,即使遇上问题,也可以随时将数据集还原到不同的版本;
- RDB 非常适用于灾难恢复(disaster recovery):它只有一个文件,并且内容都非常紧凑,可以(在加密后)将它传送到别的数据中心;
- RDB 可以最大化 Redis 的性能:父进程在保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作;
- RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快
劣势:- 如果业务上需要尽量避免在服务器故障时丢失数据,那么 RDB 并不适合。 虽然 Redis 允许在设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 由于 RDB 文件需要保存整个数据集的状态, 所以这个过程并不快,可能会至少 5 分钟才能完成一次 RDB 文件保存。 在这种情况下, 一旦发生故障停机, 就可能会丢失好几分钟的数据
- 每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时,造成服务器在某某毫秒内停止处理客户端; 如果数据集非常巨大,并且 CPU 时间非常紧张的话,那么这种停止时间甚至可能会长达整整一秒。 虽然 AOF 重写也需要进行 fork() ,但无论 AOF 重写的执行间隔有多长,数据的耐久性都不会有任何损失。
AOF 持久化
RDB 持久化是全量备份,比较耗时,所以Redis就提供了一种更为高效地AOF(Append Only-file)持久化方案,简单描述它的工作原理:AOF日志存储的是Redis服务器指令序列,AOF只记录对内存进行修改的指令记录。
在服务器从新启动时,Redis就会利用 AOF 日志中记录的这些操作从新构建原始数据集。
Redis会在收到客户端修改指令后,进行参数修改、逻辑处理,如果没有问题,就立即将该指令文本存储到 AOF 日志中,也就是说,先执行指令才将日志存盘。这点不同于 leveldb、hbase等存储引擎,它们都是先存储日志再做逻辑处理
AOF 的触发配置
AOF也有不同的触发方案,这里简要描述以下三种触发方案:
always:每次发生数据修改就会立即记录到磁盘文件中,这种方案的完整性好但是IO开销很大,性能较差;everysec:在每一秒中进行同步,速度有所提升。但是如果在一秒内宕机的话可能失去这一秒。可以在redis.config中进行配置,appendonly no改换为yes,再通过注释或解注释appendfsync配置需要的方案内的数据;no:默认配置,即不使用 AOF 持久化方案。
AOF 重写机制
随着Redis的运行,AOF的日志会越来越长,如果实例宕机重启,那么重放整个AOF将会变得十分耗时,而在日志记录中,又有很多无意义的记录,比如我现在将一个数据 incr 一千次,那么就不需要去记录这1000次修改,只需要记录最后的值即可。所以就需要进行 AOF 重写。
Redis 提供了bgrewriteaof指令用于对AOF日志进行重写,该指令运行时会开辟一个子进程对内存进行遍历,然后将其转换为一系列的 Redis 的操作指令,再序列化到一个日志文件中。完成后再替换原有的AOF文件,至此完成。
fsync 函数
在将AOF配置为appendfsync everysec之后,Redis在处理一条命令后,并不直接立即调用write将数据写入 AOF 文件,而是先将数据写入AOF buffer(server.aof_buf)。调用write和命令处理是分开的,Redis只在每次进入epoll_wait之前做 write 操作。
Redis另外的两种策略,一个是永不调用 fsync,让操作系统来决定合适同步磁盘,操作系统默认是30s,这样做很不安全;另一个是来一个指令就调用 fsync 一次,这种导致结果非常慢。这两种策略在生产环境中基本都不会使用,了解一下即可。
AOF 的优势
- AOF 持久化的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多也只会丢失掉一秒钟内的数据;
- AOF 文件是一个只进行追加操作的日志文件(append only log), 因此对 AOF 文件的写入不需要进行 seek(用于移动文件读取指针到指定位置) , 即使日志因为某些原因而包含了未写入完整的命令(比如写入时磁盘已满,写入中途停机,等等), redis-check-aof 工具也可以轻易地修复这种问题。
- Redis 可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写: 重写后的新 AOF 文件包含了恢复当前数据集所需的最小命令集合。 整个重写操作是绝对安全的,因为 Redis 在创建新 AOF 文件的过程中,会继续将命令追加到现有的 AOF 文件里面,即使重写过程中发生停机,现有的 AOF 文件也不会丢失。 而一旦新 AOF 文件创建完毕,Redis 就会从旧 AOF 文件切换到新 AOF 文件,并开始对新 AOF 文件进行追加操作。
- AOF 文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析(parse)也很轻松。 导出(export) AOF 文件也非常简单: 举个例子, 如果你不小心执行了 FLUSHALL 命令, 但只要 AOF 文件未被重写, 那么只要停止服务器, 移除 AOF 文件末尾的 FLUSHALL 命令, 并重启 Redis , 就可以将数据集恢复到 FLUSHALL 执行之前的状态。
AOF 的缺点- 对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积
- 根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。 在一般情况下, 每秒 fsync 的性能依然非常高, 而关闭 fsync 可以让 AOF 的速度和 RDB 一样快, 即使在高负荷之下也是如此。 不过在处理巨大的写入载入时,RDB 可以提供更有保证的最大延迟时间(latency)。
- AOF 在过去曾经发生过这样的 bug : 因为个别命令的原因,导致 AOF 文件在重新载入时,无法将数据集恢复成保存时的原样。
混合持久化
重启 Redis 时,如果使用 RDB 来恢复内存状态,会丢失大量数据。而如果只使用 AOF 日志重放,那么效率又太过于低下。Redis 4.0 提供了混合持久化方案,将 RDB 文件的内容和增量的 AOF 日志文件存在一起。这里的 AOF 日志不再是全量的日志,而是自 RDB 持久化开始到持久化结束这段时间发生的增量 AOF 日志,通常这部分日志很小。
于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志,就可以完全替代之前的 AOF 全量重放,重启效率因此得到大幅提升。
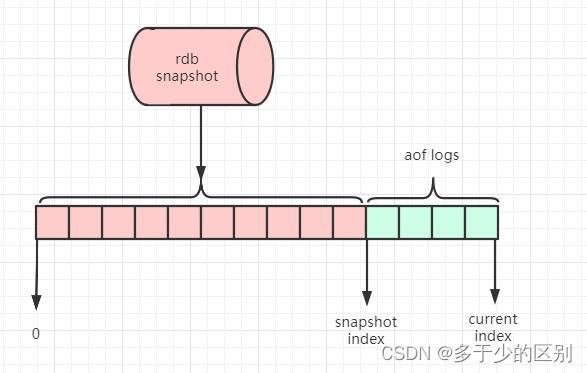
redis持久化:
- RDB 快照存储(默认)
- AOF 以追加的方式保存所有写操作
- save 900 1 #当有一条Keys数据被改变时,900秒刷新到Disk一次
- save 300 10 #当有10条Keys数据被改变时,300秒刷新到Disk一次
- save 60 10000 #当有10000条Keys数据被改变时,60秒刷新到Disk一次
- appendonly yes #启用AOF持久化方式
- appendfsync everysec #每秒钟强制写入磁盘一次
Redis持久化官方介绍
redis和mysql数据同步,我们要做的是从redis里读数据,写数据往mysql数据库里写,当redis里没有的时候从数据库里加载
几种redis与mysql整合的方案
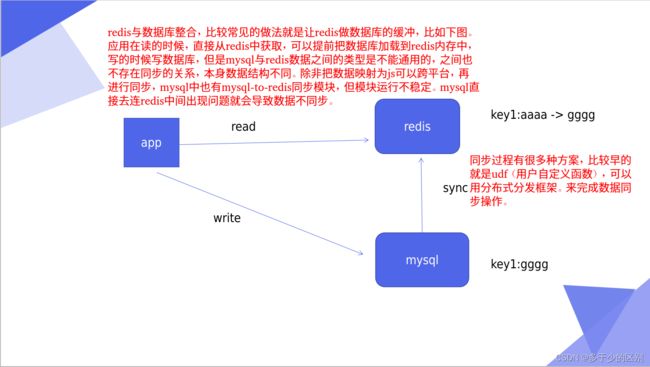
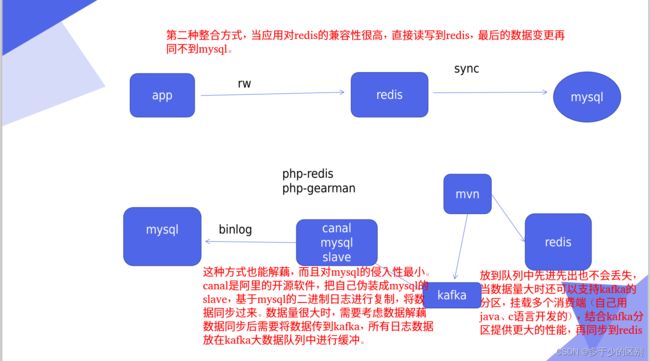
redis与mysql整合有很多种设计方法,在大厂的实际生产环境中因为数据量庞大所以通常会做解藕,也就是微服务会更加灵活,适合企业的敏捷开发(Devops),但是解藕也意味着复杂度增加,因为原来是一个整体分成了不同的块、组件,不同的组件进行切分、解藕,运维成本也会相应增加。
以下实验案例对数据库版本又要求,因为UDF函数的设计方式要给数据库编译一个json-object模块,mysql5.7以后的版本自带该模块,会有冲突,所以将数据库版本降一下。因为之前在server1上搭建lamp架构时,源码编译的php编本比较高,比系统自带的php-mysql、php-redis模块版本高,在新的节点server3上搭建lamp架构。
redis作mysql数据库的缓存架构
| 主机 | 用途 |
|---|---|
| server2 | 搭建redis服务 |
| server3 | 搭建lamp架构 |
| server4 | 搭建mariadb服务 |
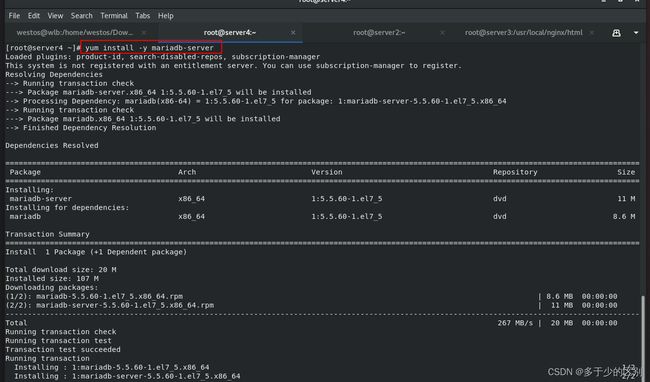
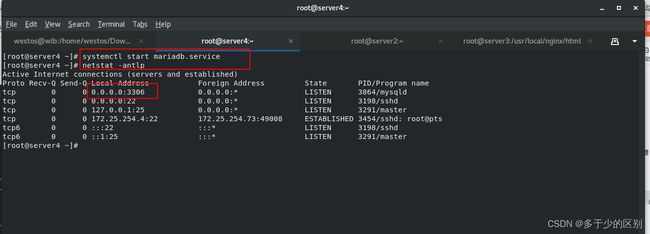
1.server4创建数据库服务
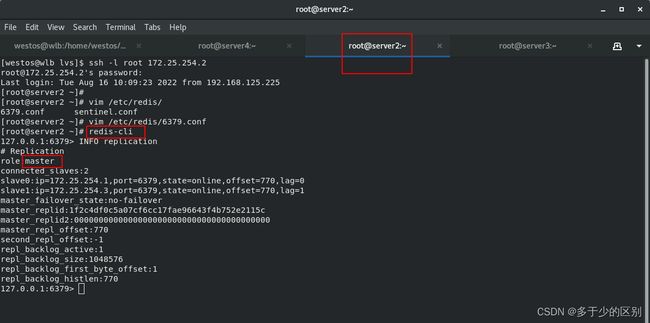
2.server2主机节点搭建redis服务(master状态)
3.server3搭建lamp架构
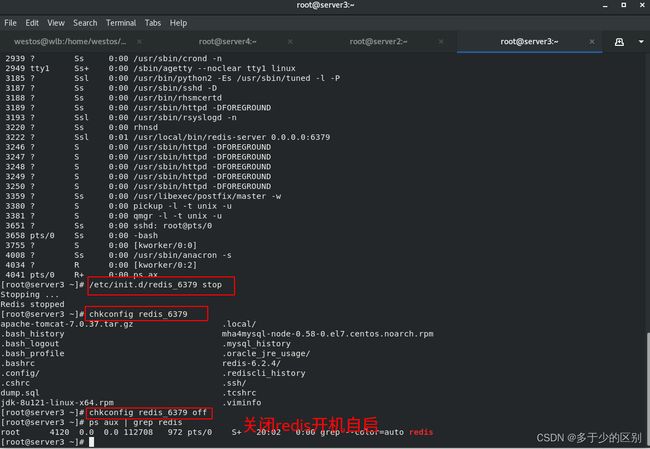
在server3上搭建带有php模块的lamp架构
重新源码编译nginx
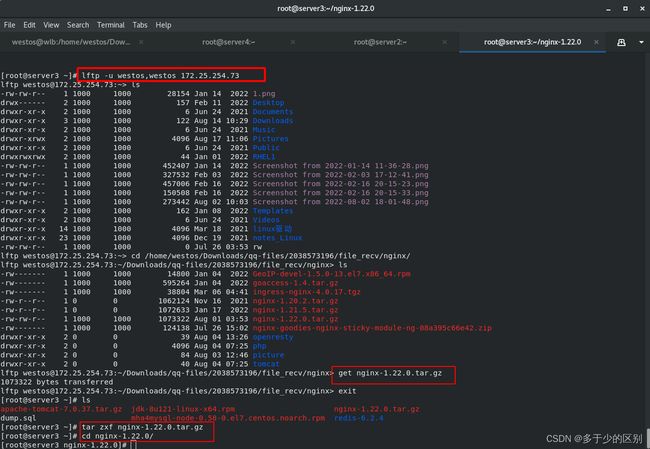 解决开发包依赖性
解决开发包依赖性
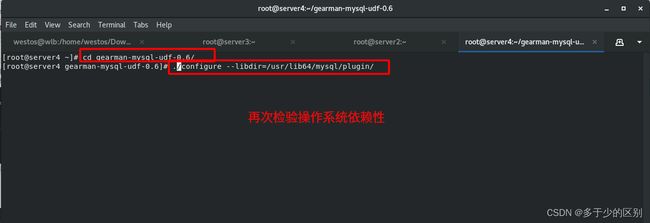
 检验操作系统的依赖性
检验操作系统的依赖性
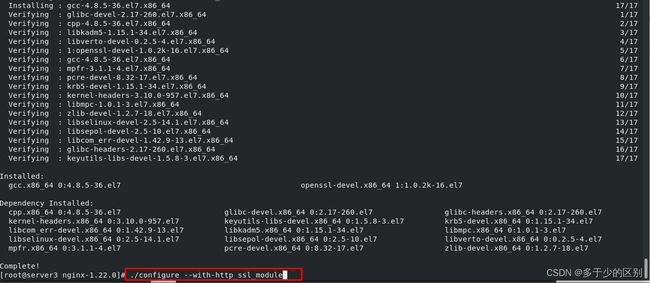
源码编译安装
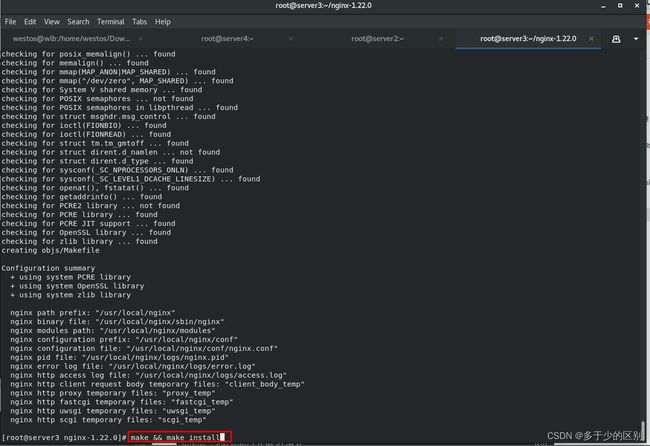
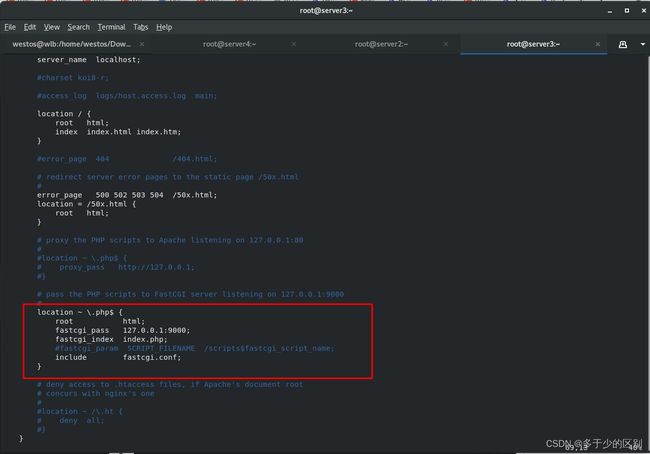
修改nginx的配置文件,启动Nginx服务
安装php
安装php-fpm

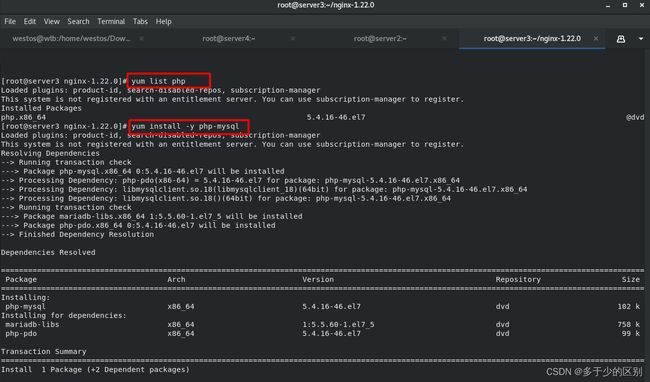
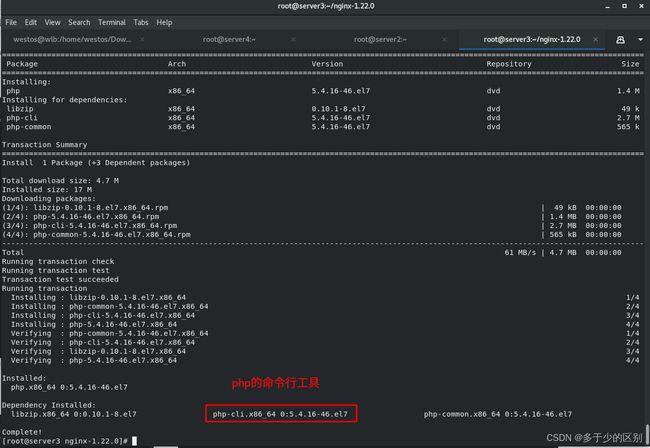 安装php-mysql模块
安装php-mysql模块
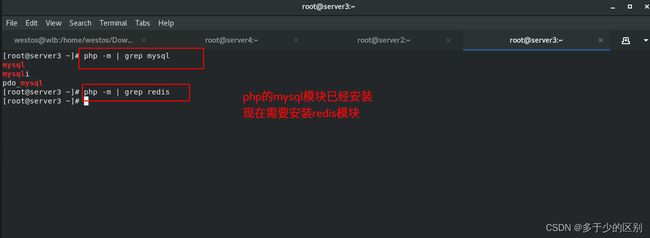

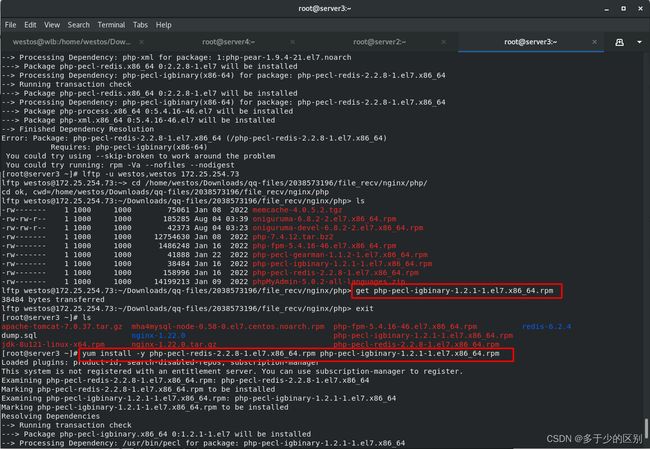
在nginx发布目录下放置php发布页面
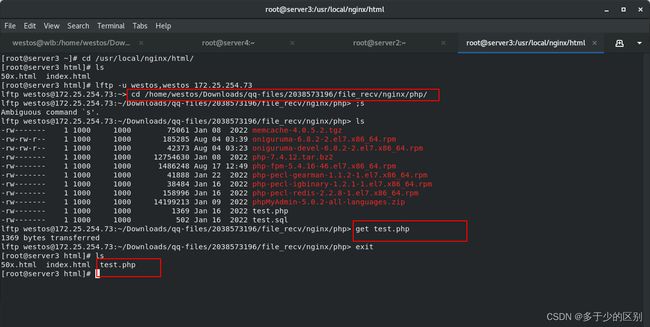

 开启php-fpm
开启php-fpm
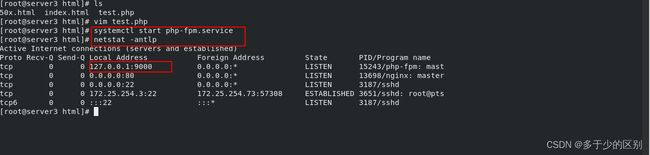
4.server4(mysql数据库)导入数据并对redis用户进行授权
server4上通过test.sql导入数据库,以下是test.sql中的内容:
use test;
CREATE TABLE `test` (`id` int(7) NOT NULL AUTO_INCREMENT, `name` char(8) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `test` VALUES (1,'test1'),(2,'test2'),(3,'test3'),(4,'test4'),(5,'test5'),(6,'test6'),(7,'test7'),(8,'test8'),(9,'test9');
#DELIMITER $$
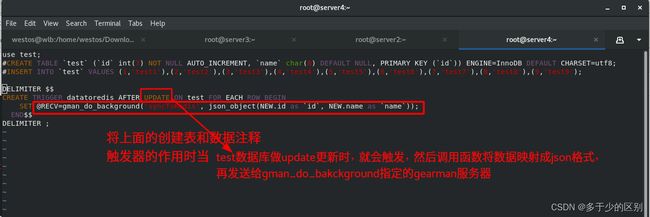
#CREATE TRIGGER datatoredis AFTER UPDATE ON test FOR EACH ROW BEGIN
# SET @RECV=gman_do_background('syncToRedis', json_object(NEW.id as `id`, NEW.name as `name`));
# END$$
#DELIMITER
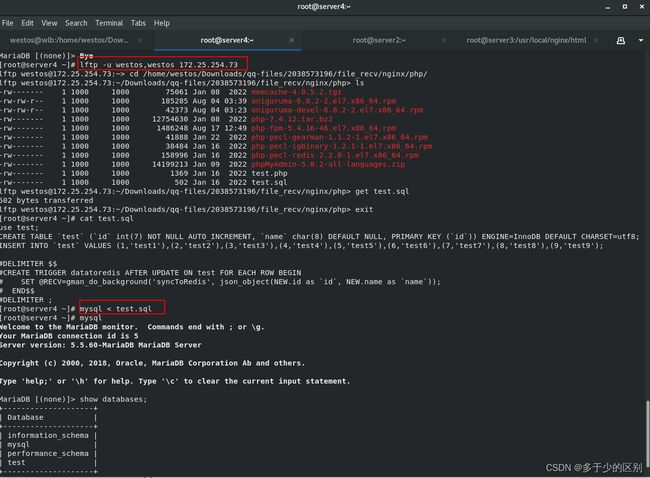
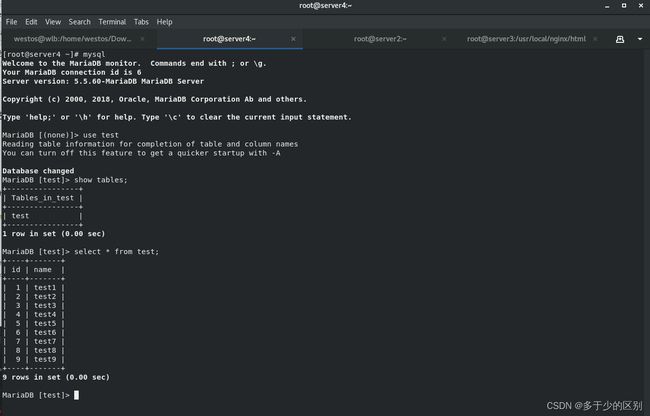
数据库建立redis用户并进行授权
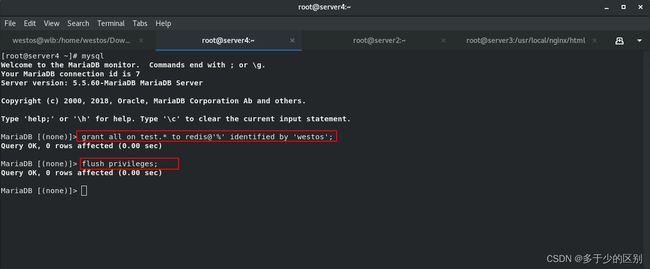
5.浏览器访问测试
第一次访问可以看到是从数据库中取到的数据

修改数据库中的数据可以发现redis中的数据并没有同步,因为只要redis中已经有了数据就不会从再从数据库中取
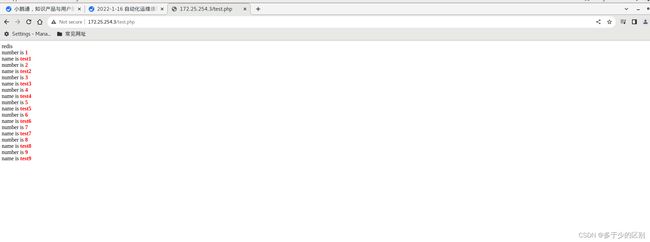
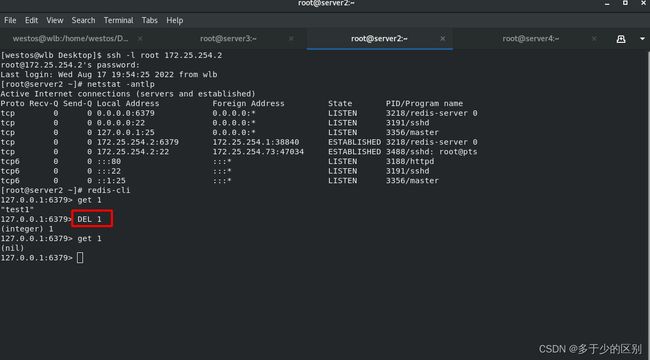
当删除redis中的数据时,客户端通过浏览器发起请求,查询redis中没有,就会转向后端数据库查询,命中后会返回数据到客户端,同时将数据存到redis,下次再请求该数据,将由redis直接返回数据到客户端,不再转到mysql。
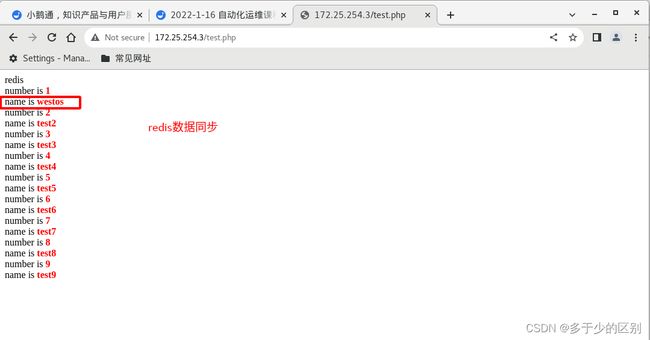 上面的案例已经完成了redis作为数据库的缓冲,但是数据库数据变更没有同步到redis,下面解决redis与数据库的数据同步问题
上面的案例已经完成了redis作为数据库的缓冲,但是数据库数据变更没有同步到redis,下面解决redis与数据库的数据同步问题
6、结合gearmand实现redis与数据库数据同步
gearmand简介
Gearmand 是一个用来把工作委派给其它机器、分布式的调用更适合做某项工作的机器、并发的做某项工作在多个调用间做负载均衡、或用来调用其它语言的函数的系统。
简单来讲,就是客户端程序把请求提交给 gearmand,gearmand 会把请求转发给合适的 worker 来处理这个请求,最后还通过 gearmand 返回结果。
运行流程:
Client --> Job --> Worker
1、Client 请求发起者,客户端程序可以是任何一种语言,C 、PHP 、Perl 、Python 等。
2、Job 请求调度者,负载协调把 Client 发出的请求转发给合适的 Worker。
3、Worker 请求处理者,处理 Job 分发来的请求,可以是任何一种语言。
gearmand的安装与使用示例
运行流程图
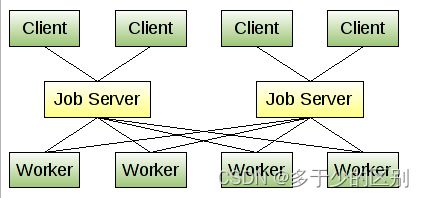
Client:任务发起者
Job:任务分配者
Worker:任务处理者
支持 mysql、pq、sqlit、brizzle、memcachedb做持久化存储
可开启多个进程,支持failover(自动故障转移)
首先需要给数据库安装两个外部的函数,这对数据库有一定的侵入性
会有安全性问题,现在大都选择侵入性低的软件,比如阿里的canal通过将自身伪装成mysql的slave,通过mysql主从复制实现,对数据库主库没有任何的侵入性。这只是将数据从mysql同步过来,但是如何同步到redis需要编码写客户端,从kafka大数据队列中消费。
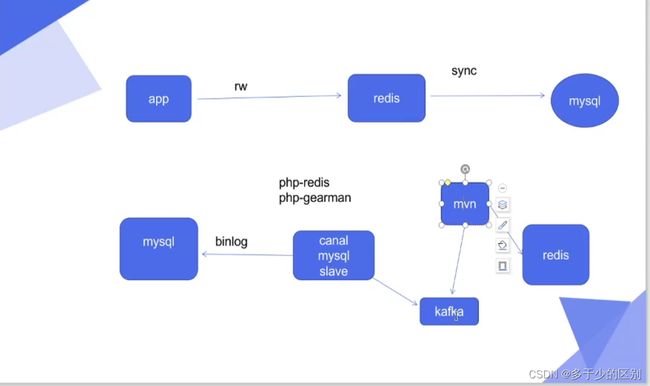
不建议mysql更新的数据由mysql的plugin直接同步到redis,不做解藕数据量大时,会容易出问题,中间最好由分布式的分发框架来做同步。
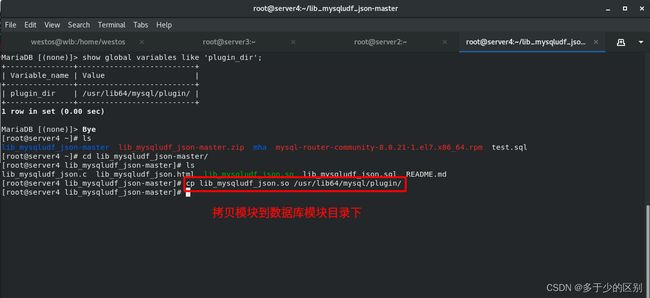
下载安装 lib_mysqludf_json库函数,添加到数据库的plugin模块中
lib_mysqludf_json UDF 库函数将关系数据映射为 JSON 格式。通常,数据库中的数据映射为 JSON 格式,是通过程序来转换的。mysql数据与redis数据不同,一个是关系型数据,一个是非关系型,JSON是跨平台的,所以将数据映射为 JSON 格式。
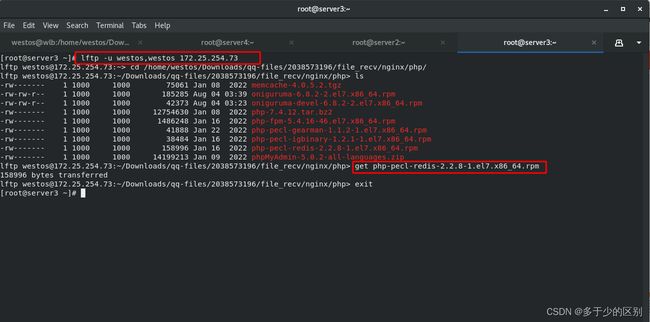
库函数安装包下载位置
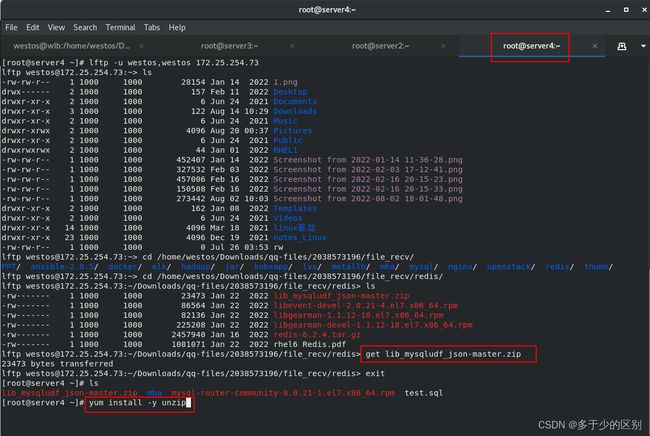
库函数需要编译,安装gcc和mariadb-devel
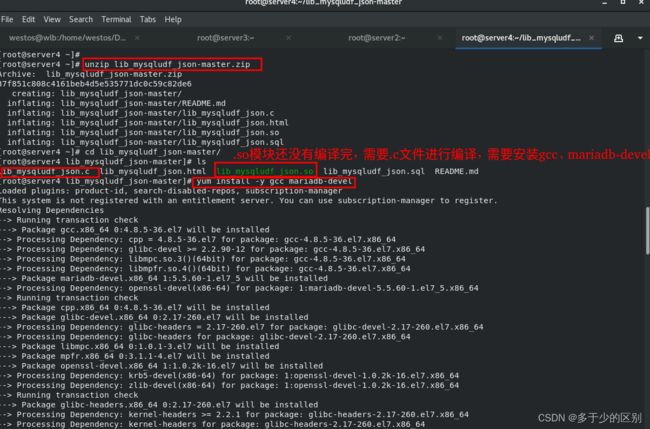
如果数据库用的mysql,则下载mysql-devel开发包,最新的mysql有原生的json,会冲突,所以用的系统自带的mariadb。
编译的是mysql-udf函数,作用是当mysql更新完数据后,将数据映射成可以跨平台的json数据
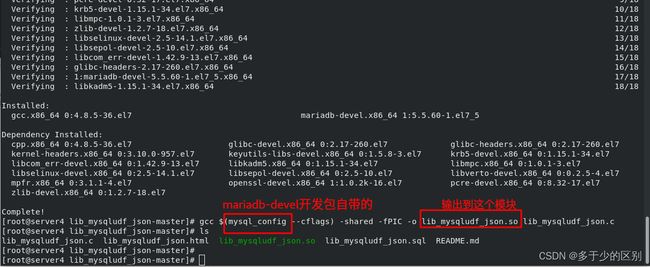
进入数据库,查看数据库模块所在位置
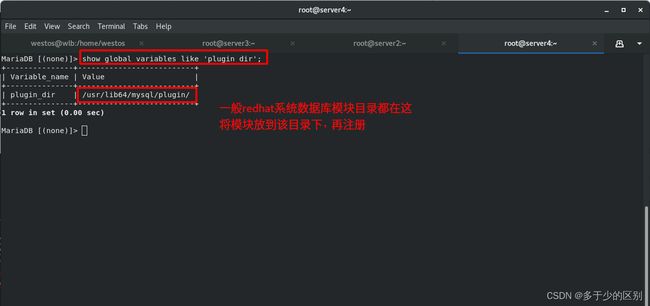
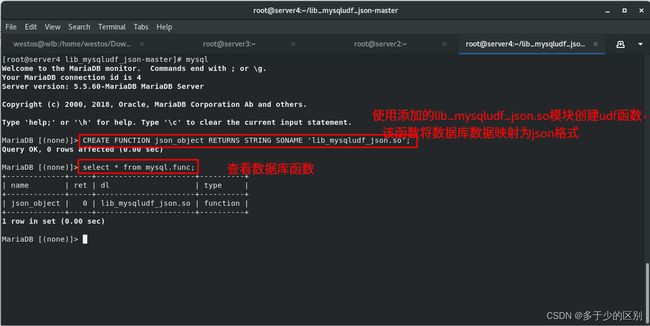
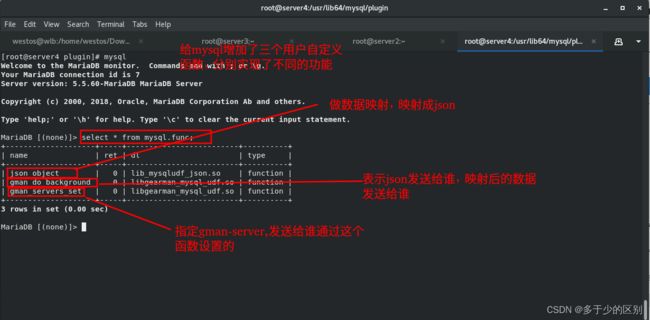
 注册 UDF 函数
注册 UDF 函数
安装 gearman-mysql-udf
这个插件是用来管理调用 Gearman 的分布式的队列,mysql直接同步到mysql数据库不稳定,当数据量大时,如果出现数据连接故障,将导致数据不一致。采用分布式的方式对数据进行解藕,类似阿里的canel作用。
数据库直接更新redis不合适,中间需要解藕,通常生产环境数据量比较庞大,会通过大数据队列kafka实现数据解藕。下面的案例使用一个简单的分布式框架实现解藕,需要自己编写消费端代码。
解决依赖性
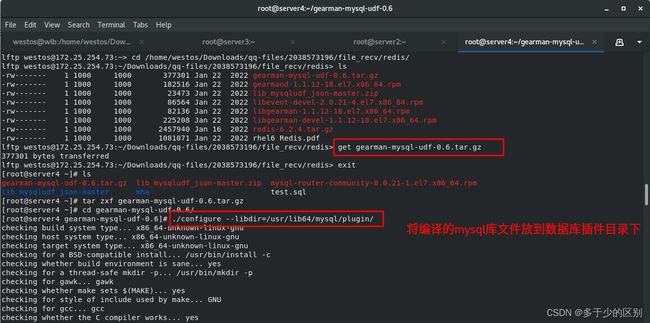
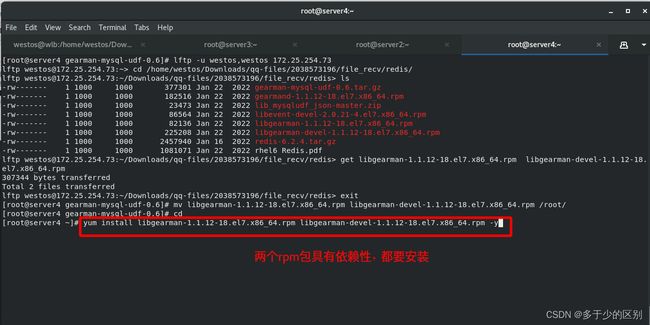
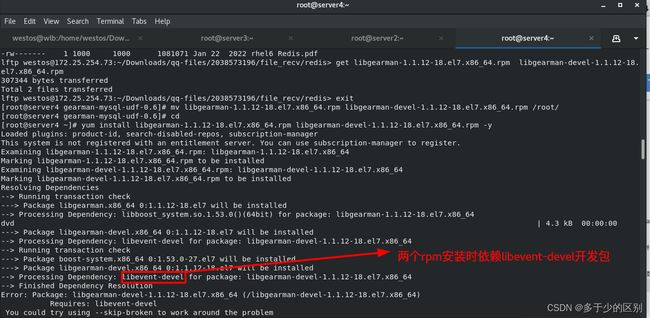

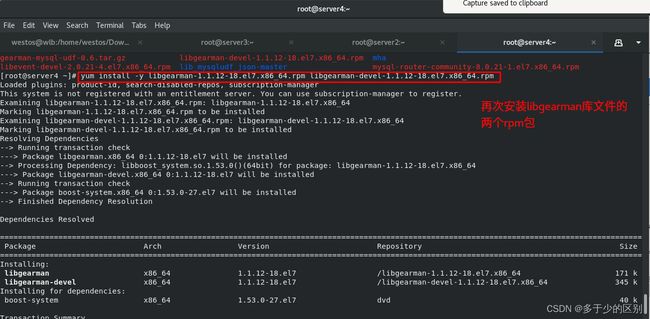
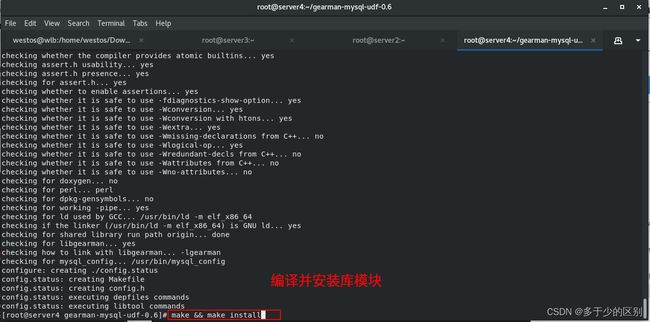
 编译并安装数据库模块
编译并安装数据库模块
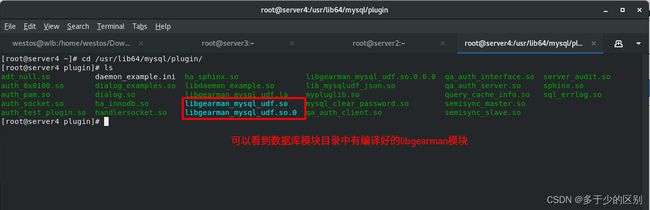
利用编译好的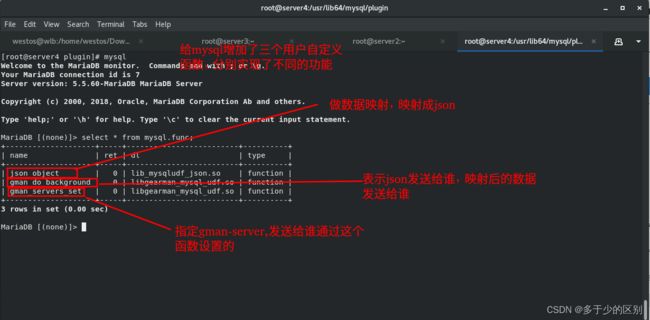
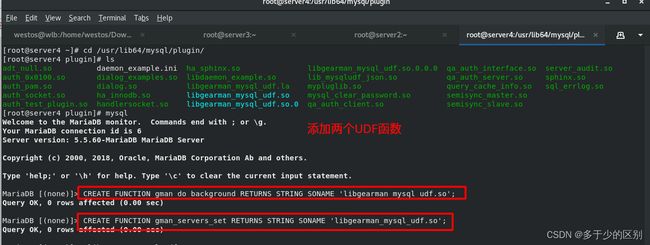
模块注册UDF函数
 查看数据库函数
查看数据库函数
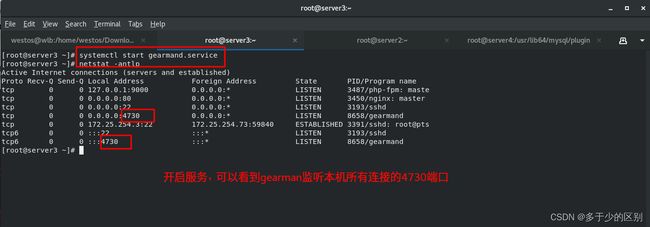
在server3(Lamp架构端主机)安装gearman-server,也就是服务器端gearmand。

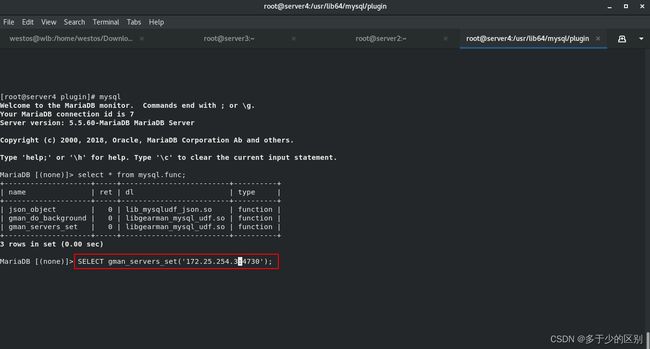
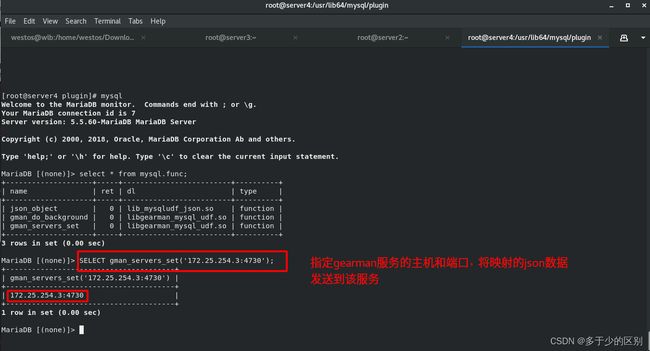
数据库(servre4)指定 gearman 的服务信息
 数据库创建触发器,由触发器调用创建的自定义函数,当数据库更改时就激活触发器,由触发器依次调用三个自定义函数。
数据库创建触发器,由触发器调用创建的自定义函数,当数据库更改时就激活触发器,由触发器依次调用三个自定义函数。
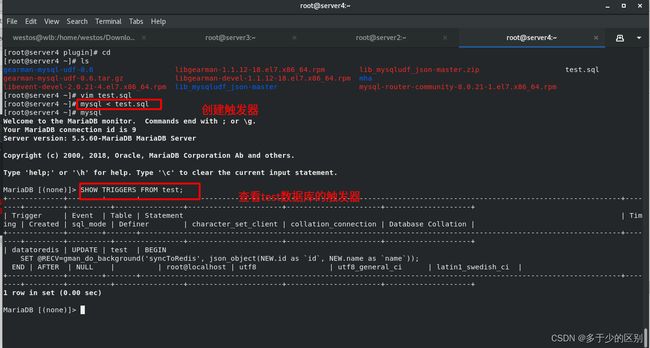 server3的gearman服务端收到数据后,需要分发给woker,也就是消费端。服务端就相当于消息队列,需要消费端去消费队列中的数据。
server3的gearman服务端收到数据后,需要分发给woker,也就是消费端。服务端就相当于消息队列,需要消费端去消费队列中的数据。

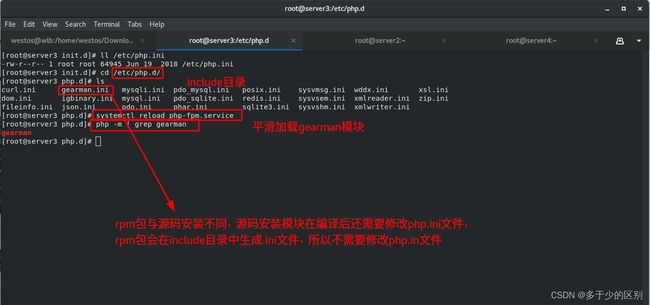
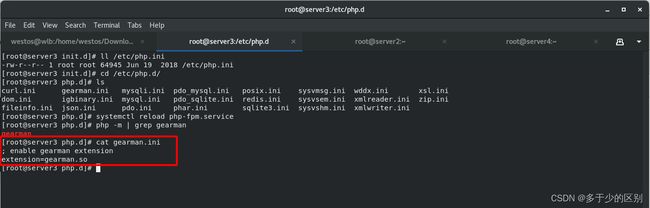
php添加gearman模块
 php平滑加载geatman模块
php平滑加载geatman模块
php执行worker.php 并打入后台:

 测试:
测试:
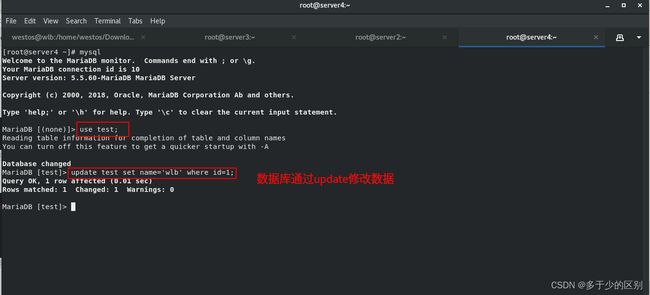
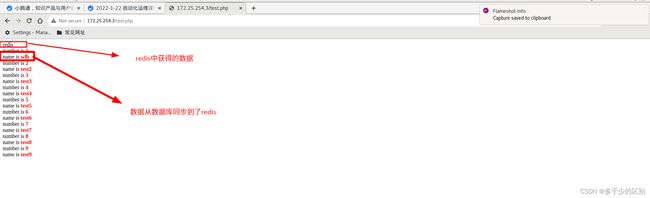
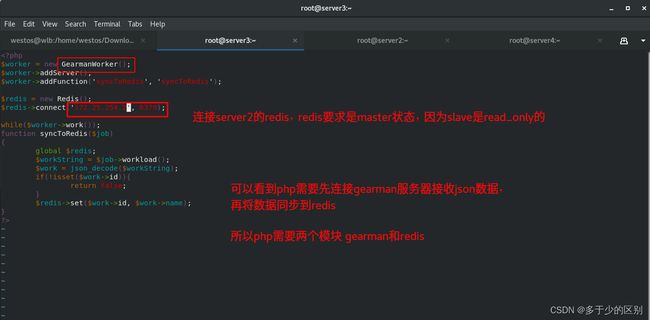
上述案例redis以异步方式同步mysql中的数据。只要application将数据写到mysql中,mysql触发器检测到更新,先将数据映射为json,再通过Gearman将数据分配到woker消费端,woker将数据同步到redis。然后读取的话,就直接从redis中进行读取。这就是redis作为mysql缓存的架构。