【HDFS】记一次由JN性能瓶颈导致的NN频繁宕机异常
记一次由JN性能瓶颈导致的NN频繁宕机异常
- 前言
- 正文
-
- 问题排查
-
- Ambari页面
- NN日志排查
- GC日志排查
- JN日志排查
- 复现准备
- 问题分析
-
- edits发送过久
- 接入监控
- 问题复现
- 问题结论
- 结语
前言
某年某月某日开始,测试环境的NameNode开始频繁宕机,基本上是每天都会稳定触发此问题;第一次查的时候看到和JN通信发生超时,然后就宕机了,但是当时JN服务又是正常的,遂没太上心,重启完事,结果后面又继续出此问题,所以还是进行排查顺便记录一下;
正文
问题排查
Ambari页面
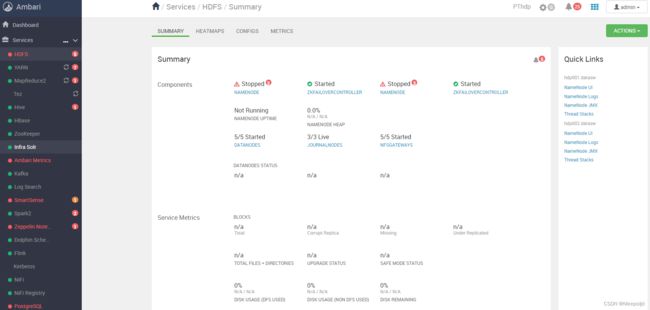
2022年8月2日,上午查看测试环境Ambari,再次发现NameNode惨死,两个无一幸免,JN正常,其他服务正常,至少能够得到这些信息:
- ZKFC没有异常,说明HA自动切换没有生效,否则这个时间应该至少存活一个NN;
- 其他服务至少服务还在,这说明不大可能是ZK等组件导致的问题;
NN日志排查
进一步查看日志,NameNode日志中,最新的内容为7月31日13:44:37打印,看样子已经宕机几天了,报错信息依旧是和JN的交互超时:
2022-07-31 13:44:37,603 FATAL namenode.FSEditLog (JournalSet.java:mapJournalsAndReportErrors(390)) - Error: recoverUnfinalizedSegments failed for required journal (JournalAndStream(mgr=QJM to [10.0.0.10:8485, 10.0.0.31:8485, 10.0.0.29:8485], stream=null))
java.io.IOException: Timed out waiting 120000ms for a quorum of nodes to respond.
at org.apache.hadoop.hdfs.qjournal.client.AsyncLoggerSet.waitForWriteQuorum(AsyncLoggerSet.java:137)
at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.recoverUnclosedSegment(QuorumJournalManager.java:366)
at org.apache.hadoop.hdfs.qjournal.client.QuorumJournalManager.recoverUnfinalizedSegments(QuorumJournalManager.java:462)
at org.apache.hadoop.hdfs.server.namenode.JournalSet$6.apply(JournalSet.java:616)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.mapJournalsAndReportErrors(JournalSet.java:385)
at org.apache.hadoop.hdfs.server.namenode.JournalSet.recoverUnfinalizedSegments(JournalSet.java:613)
at org.apache.hadoop.hdfs.server.namenode.FSEditLog.recoverUnclosedStreams(FSEditLog.java:1602)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.startActiveServices(FSNamesystem.java:1216)
at org.apache.hadoop.hdfs.server.namenode.NameNode$NameNodeHAContext.startActiveServices(NameNode.java:1887)
at org.apache.hadoop.hdfs.server.namenode.ha.ActiveState.enterState(ActiveState.java:61)
at org.apache.hadoop.hdfs.server.namenode.ha.HAState.setStateInternal(HAState.java:64)
at org.apache.hadoop.hdfs.server.namenode.ha.StandbyState.setState(StandbyState.java:49)
at org.apache.hadoop.hdfs.server.namenode.NameNode.transitionToActive(NameNode.java:1746)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.transitionToActive(NameNodeRpcServer.java:1723)
at org.apache.hadoop.ha.protocolPB.HAServiceProtocolServerSideTranslatorPB.transitionToActive(HAServiceProtocolServerSideTranslatorPB.java:107)
at org.apache.hadoop.ha.proto.HAServiceProtocolProtos$HAServiceProtocolService$2.callBlockingMethod(HAServiceProtocolProtos.java:4460)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:524)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1025)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:876)
at org.apache.hadoop.ipc.Server$RpcCall.run(Server.java:822)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2682)
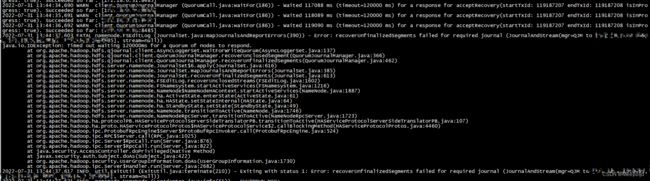
此前已经对这个超时的限制做过更改,由60000ms增加到120000ms,还是报错,显然报错的真正原因不该是超时;
GC日志排查
GC的排查其实很没头绪,本身也不是Java开发出身,先看一下异常时候的GC日志信息:
2022-07-31T13:24:18.129+0800: 3077.295: [GC (Allocation Failure) 2022-07-31T13:24:18.130+0800: 3077.296: [ParNew: 559914K->7729K(619328K), 0.0381639 secs] 878007K->326039K(5436224K), 0.0394059 secs] [Times: user=0.14 sys=0.08, real=0.04 secs]
2022-07-31T13:30:25.153+0800: 3444.319: [GC (Allocation Failure) 2022-07-31T13:30:25.154+0800: 3444.319: [ParNew: 558257K->7597K(619328K), 0.0387003 secs] 876567K->326074K(5436224K), 0.0400017 secs] [Times: user=0.14 sys=0.06, real=0.04 secs]
2022-07-31T13:36:32.007+0800: 3811.173: [GC (Allocation Failure) 2022-07-31T13:36:32.008+0800: 3811.174: [ParNew: 558125K->7656K(619328K), 0.0398682 secs] 876602K->326431K(5436224K), 0.0411169 secs] [Times: user=0.17 sys=0.05, real=0.04 secs]
Heap
par new generation total 619328K, used 427107K [0x0000000670000000, 0x000000069a000000, 0x000000069a000000)
eden space 550528K, 76% used [0x0000000670000000, 0x000000068999e890, 0x00000006919a0000)
from space 68800K, 11% used [0x00000006919a0000, 0x000000069211a3e8, 0x0000000695cd0000)
to space 68800K, 0% used [0x0000000695cd0000, 0x0000000695cd0000, 0x000000069a000000)
concurrent mark-sweep generation total 4816896K, used 318774K [0x000000069a000000, 0x00000007c0000000, 0x00000007c0000000)
Metaspace used 53735K, capacity 54794K, committed 54948K, reserved 1097728K
class space used 5499K, capacity 5742K, committed 5856K, reserved 1048576K
各种GC (Allocation Failure)看起来没什么太大的异常,FullGC都没看到,但是个人感觉最后两行的内容是有蹊跷的:
![]()
于是我去查了一下这种日志的分析方法,如果感兴趣可以去看一下这个博文Understanding Metaspace and Class Space GC Log Entries,对我这里的案例来说,Metaspace的非类committed空间是54948K-5856K=49092K,而capacity容量的值是54794K-5742K=49052K,此时我的猜想是可能是如下两种:
- 这里是Metaspace满了触发了FullGC,但是,即使FullGC后也无法满足要求,然后就崩了;
- FullGC在进行,但是超时了,导致和JN交互超时,毕竟运行日志一直打印超时;
不过后来又咨询了一些研发人员,大家认为这样的可能性不大,因为如果是GC的问题,理应在GC日志的最后打印出OOM之类的报错信息,但是现在是没有的,如果是Metaspace的问题,也会有类似的信息;
JN日志排查
NN的日志中,明确报错了具体是哪个JN节点连接超时,name直接去JN节点在进一步分析JN日志,看看有没有头绪:
2022-07-31 13:40:24,066 INFO timeline.HadoopTimelineMetricsSink (AbstractTimelineMetricsSink.java:getCurrentCollectorHost(291)) - No live collector to send metrics to. Metrics to be sent will be discarded. This message will be skipped for the next 20 times.
2022-07-31 13:40:54,559 INFO server.JournalNodeSyncer (JournalNodeSyncer.java:syncWithJournalAtIndex(231)) - Syncing Journal /0.0.0.0:8485 with XXXXXXX:8485, journal id: hdfsCluster
2022-07-31 13:42:37,126 INFO server.Journal (Journal.java:updateLastPromisedEpoch(346)) - Updating lastPromisedEpoch from 79 to 80 for client XXXXXX ; journal id: hdfsCluster
2022-07-31 13:42:37,128 INFO server.Journal (Journal.java:scanStorageForLatestEdits(205)) - Scanning storage FileJournalManager(root=/hadoop/hdfs/journal/hdfsCluster)
2022-07-31 13:42:37,165 INFO server.Journal (Journal.java:scanStorageForLatestEdits(211)) - Latest log is EditLogFile(file=/hadoop/hdfs/journal/hdfsCluster/current/edits_inprogress_0000000000119187207,first=0000000000119187207,last=0000000000119187208,inProgress=true,hasCorruptHeader=false) ; journal id: hdfsCluster
2022-07-31 13:42:37,579 INFO server.Journal (Journal.java:getSegmentInfo(740)) - getSegmentInfo(119187207): EditLogFile(file=/hadoop/hdfs/journal/hdfsCluster/current/edits_inprogress_0000000000119187207,first=0000000000119187207,last=0000000000119187208,inProgress=true,hasCorruptHeader=false) -> startTxId: 119187207 endTxId: 119187208 isInProgress: true ; journal id: hdfsCluster
2022-07-31 13:42:37,579 INFO server.Journal (Journal.java:prepareRecovery(784)) - Prepared recovery for segment 119187207: segmentState { startTxId: 119187207 endTxId: 119187208 isInProgress: true } lastWriterEpoch: 79 lastCommittedTxId: 119187207 ; journal id: hdfsCluster
2022-07-31 13:42:37,648 INFO server.Journal (Journal.java:getSegmentInfo(740)) - getSegmentInfo(119187207): EditLogFile(file=/hadoop/hdfs/journal/hdfsCluster/current/edits_inprogress_0000000000119187207,first=0000000000119187207,last=0000000000119187208,inProgress=true,hasCorruptHeader=false) -> startTxId: 119187207 endTxId: 119187208 isInProgress: true ; journal id: hdfsCluster
2022-07-31 13:42:37,648 INFO server.Journal (Journal.java:acceptRecovery(872)) - Skipping download of log startTxId: 119187207 endTxId: 119187208 isInProgress: true: already have up-to-date logs ; journal id: hdfsCluster
2022-07-31 13:42:37,649 WARN util.AtomicFileOutputStream (AtomicFileOutputStream.java:close(96)) - Unable to delete tmp file /hadoop/hdfs/journal/hdfsCluster/current/paxos/119187207.tmp
2022-07-31 13:42:37,650 INFO server.Journal (Journal.java:acceptRecovery(905)) - Accepted recovery for segment 119187207: segmentState { startTxId: 119187207 endTxId: 119187208 isInProgress: true } acceptedInEpoch: 80 ; journal id: hdfsCluster
2022-07-31 13:44:04,066 INFO timeline.HadoopTimelineMetricsSink (AbstractTimelineMetricsSink.java:getCurrentCollectorHost(291)) - No live collector to send metrics to. Metrics to be sent will be discarded. This message will be skipped for the next 20 times.

依旧是没什么有用的信息。难道有所遗漏吗?
复现准备
由于没有确定问题原因,复现并不容易,鉴于该异常在近日屡次触发,于是直接将服务重启,等待其再次触发,这次重启后,在Active的NN节点部署gc采集,准备进一步确认GC是否产生了影响,主要是以下两条命令:
nohup jstat -gcutil 167646 2s>> /home/lijiadong/hdfs_logs/gc/gc_percent.log &
nohup jstat -gc 167646 2s>> /home/lijiadong/hdfs_logs/gc/gc_size.log &
主要是想验证下上面我的猜想;
问题分析
edits发送过久
言归正传,实际上,针对NameNode的日志,遗漏了一些关键信息:
2022-07-31 13:39:51,968 WARN client.QuorumJournalManager (IPCLoggerChannel.java:call(417)) - Took 57363ms to send a batch of 1 edits (17 bytes) to remote journal 172.18.2.29:8485
由于这是一个WARN的日志,我之前并没有关注;看起来这是在发送edit操作到远程JN节点的时候,花费的时间的警告,这个警告级别的日志,在问题发生前屡次打印,会不会是问题出在这块?
如果是的话,那以我的经验来说,最大概率问题处在磁盘IO或者网络IO上;所以先从这两方面着手分析
接入监控
既然要对主机指标做分析,接下来要做的就是能够实时捕捉具体的指标,方便后续分析,于是将测试环境接入我的Prometheus监控起来;
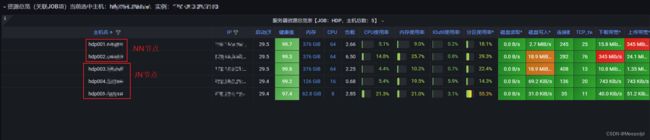
其实在我把监控部署上去时,我大概有一点推测了,可以看到,JN的三个节点中,有一个是高配物理机,而剩下两台是低配虚拟机,NN的日志里,屡次报Took edit时长久的正好就是两虚拟机节点,很大概率是硬件配置导致的了。
问题复现
很幸运,服务重启后,当晚20:00时分,Active NN发生宕机,随后主机切换;
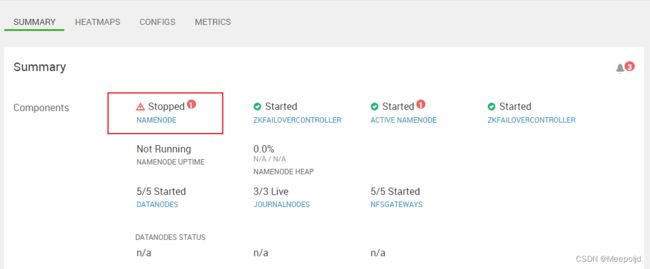
第一时间查看20:00左右的监控指标,首先是物理机节点,从监控指标来看,确实在问题时间点出现了波动,但是都是负载往低处走,不大可能触发性能瓶颈:
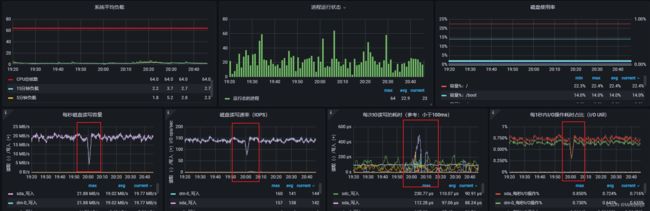
接下来是两台虚拟机的监控图,:
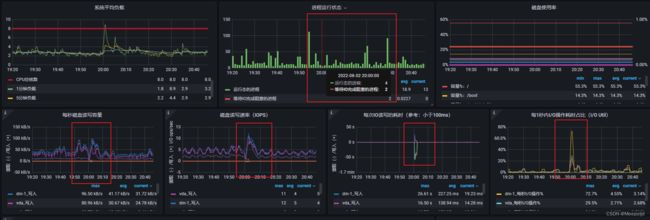
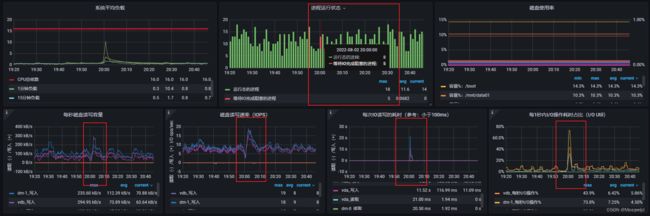
终于逮到这个异常点了,可以看到问题时间点,有两个JN节点出现明显的IO瓶颈,IO操作耗时达到几十秒,这简直就不能用了,而且存在等待IO的进程;
问题结论
从上面的分析可以得出大概的结论了,JN节点有两台是虚拟机,这两台虚拟机存在IO性能瓶颈,一旦触发瓶颈,就会导致NN与其进行网络远程通信做数据读写出现延迟,然后就是NN的一些判断超时的逻辑,超出阈值后就宕机了。
后续可以在继续对IO高的问题做进一步排查,不过把磁盘性能拉上去显然是最好的选择。
结语
故障,往往会由各种原因导致,如何运用自己掌握的能力进行故障排查才是一名运维最需要的能力。