【进阶版】机器学习之EM经典算法原理+代码(11)
目录
-
- 欢迎订阅本专栏,持续更新中~
-
- 本专栏前期文章介绍!
- 机器学习配套资源推送
- 进阶版机器学习文章更新~
- 点击下方下载高清版学习知识图册
- EM算法
-
- EM算法思想
- EM算法数学推导
- EM算法流程
- 贝叶斯网络
-
- 先定义E步和M步
- 再定义迭代过程,输入参数,返回结果
- Python实现(模拟2个正态分布的均值估计)
- 每文一语
欢迎订阅本专栏,持续更新中~
本专栏包含大量代码项目,适用于毕业设计方向选取和实现、科研项目代码指导,每一篇文章都是通过原理讲解+代码实战进行思路构建的,如果有需要这方面的指导可以私信博主,获取相关资源及指导!
本专栏前期文章介绍!
机器学习算法知识、数据预处理、特征工程、模型评估——原理+案例+代码实战
机器学习之Python开源教程——专栏介绍及理论知识概述
机器学习框架及评估指标详解
Python监督学习之分类算法的概述
数据预处理之数据清理,数据集成,数据规约,数据变化和离散化
特征工程之One-Hot编码、label-encoding、自定义编码
卡方分箱、KS分箱、最优IV分箱、树结构分箱、自定义分箱
特征选取之单变量统计、基于模型选择、迭代选择
机器学习八大经典分类万能算法——代码+案例项目开源、可直接应用于毕设+科研项目
机器学习分类算法之朴素贝叶斯
【万字详解·附代码】机器学习分类算法之K近邻(KNN)
《全网最强》详解机器学习分类算法之决策树(附可视化和代码)
机器学习分类算法之支持向量机
机器学习分类算法之Logistic 回归(逻辑回归)
机器学习分类算法之随机森林(集成学习算法)
机器学习分类算法之XGBoost(集成学习算法)
机器学习分类算法之LightGBM(梯度提升框架)
机器学习自然语言、推荐算法等领域知识——代码案例开源、可直接应用于毕设+科研项目
【原理+代码】Python实现Topsis分析法(优劣解距离法)
机器学习推荐算法之关联规则(Apriori)——支持度;置信度;提升度
机器学习推荐算法之关联规则Apriori与FP-Growth算法详解
机器学习推荐算法之协同过滤(基于用户)【案例+代码】
机器学习推荐算法之协同过滤(基于物品)【案例+代码】
预测模型构建利器——基于logistic的列线图(R语言)
基于surprise模块快速搭建旅游产品推荐系统(代码+原理)
机器学习自然语言处理之英文NLTK(代码+原理)
机器学习之自然语言处理——中文分词jieba库详解(代码+原理)
机器学习之自然语言处理——基于TfidfVectorizer和CountVectorizer及word2vec构建词向量矩阵(代码+原理)
机器学习配套资源推送
专栏配套资源推荐——部分展示(有需要可去对应文章或者评论区查看,可做毕设、科研参考资料)
自然语言处理之文本分类及文本情感分析资源大全(含代码及其数据,可用于毕设参考!)
基于Word2Vec构建多种主题分类模型(贝叶斯、KNN、随机森林、决策树、支持向量机、SGD、逻辑回归、XGBoost…)
基于Word2Vec向量化的新闻分本分类.ipynb
智能词云算法(一键化展示不同类型的词云图)运行生成HTML文件
协同过滤推荐系统资源(基于用户-物品-Surprise)等案例操作代码及讲解
Python机器学习关联规则资源(apriori算法、fpgrowth算法)原理讲解
机器学习-推荐系统(基于用户).ipynb
机器学习-推荐系统(基于物品).ipynb
旅游消费数据集——包含用户id,用户评分、产品类别、产品名称等指标,可以作为推荐系统的数据集案例
进阶版机器学习文章更新~
【进阶版】机器学习之基本术语及模评估与选择概念总结(01)
【进阶版】机器学习之模型性能度量及比较检验和偏差与方差总结(02)
【进阶版】机器学习之特征工程介绍及优化方法引入(03)
【进阶版】机器学习之特征降维、超参数调优及检验方法(04)
【进阶版】机器学习之线性模型介绍及过拟合欠拟合解决方法岭回归、loss回归、elasticnet回归(05)
【进阶版】机器学习之决策树知识与易错点总结(06)
【进阶版】机器学习之神经网络与深度学习基本知识和理论原理(07)
【进阶版】机器学习与深度学习之前向传播与反向传播知识(08)
【进阶版】机器学习之支持向量机细节回顾及原理完善(09)
【进阶版】机器学习之贝叶斯分类器细节回顾及原理完善(10)
前期我们对机器学习的基础知识,从基础的概念到实用的代码实战演练,并且系统的了解了机器学习在分类算法上面的应用,同时也对机器学习的准备知识有了一个相当大的了解度,而且还拓展了一系列知识,如推荐算法、文本处理、图像处理。以及交叉学科的应用,那么前期你如果认真的了解了这些知识,并加以利用和实现,相信你已经对机器学习有了一个“量”的认识,接下来的,我将带你继续学习机器学习学习,并且全方位,系统性的了解和深入机器学习领域,达到一个“质”的变化。
点击下方下载高清版学习知识图册
机器学习Python算法知识点大全,包含sklearn中的机器学习模型和Python预处理的pandas和numpy知识点

上篇主要介绍了贝叶斯分类器,从贝叶斯公式到贝叶斯决策论,再到通过极大似然法估计类条件概率,贝叶斯分类器的训练就是参数估计的过程。
朴素贝叶斯则是“属性条件独立性假设”下的特例,它避免了假设属性联合分布过于经验性和训练集不足引起参数估计较大偏差两个大问题,最后介绍的拉普拉斯修正将概率值进行平滑处理。
本篇将介绍另一个当选为数据挖掘十大算法之一的EM算法。
EM算法
EM(Expectation-Maximization)算法是一种常用的估计参数隐变量的利器,也称为“期望最大算法”,是数据挖掘的十大经典算法之一。
EM算法主要应用于训练集样本不完整即存在隐变量时的情形(例如某个属性值未知),通过其独特的“两步走”策略能较好地估计出隐变量的值。
EM算法思想
EM是一种迭代式的方法,它的基本思想就是:若样本服从的分布参数θ已知,则可以根据已观测到的训练样本推断出隐变量Z的期望值(E步),若Z的值已知则运用最大似然法估计出新的θ值(M步)。
重复这个过程直到Z和θ值不再发生变化。
简单来讲:假设我们想估计A和B这两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。

现在再来回想聚类的代表算法K-Means:【首先随机选择类中心=>将样本点划分到类簇中=>重新计算类中心=>不断迭代直至收敛】,不难发现这个过程和EM迭代的方法极其相似,事实上,若将样本的类别看做为“隐变量”(latent variable)Z,类中心看作样本的分布参数θ,K-Means就是通过EM算法来进行迭代的,与我们这里不同的是,K-Means的目标是最小化样本点到其对应类中心的距离和,上述为极大化似然函数。
EM算法数学推导
当样本属性值都已知时,我们很容易通过极大化对数似然,接着对每个参数求偏导计算出参数的值。但当存在隐变量时,就无法直接求解,此时我们通常最大化已观察数据的对数“边际似然”(marginal likelihood)。

这时候,通过边缘似然将隐变量Z引入进来,对于参数估计,现在与最大似然不同的只是似然函数式中多了一个未知的变量Z,也就是说我们的目标是找到适合的θ和Z让L(θ)最大,这样我们也可以分别对未知的θ和Z求偏导,再令其等于0。
然而观察上式可以发现,和的对数(ln(x1+x2+x3))求导十分复杂,那能否通过变换上式得到一种求导简单的新表达式呢?这时候 Jensen不等式就派上用场了,先回顾一下高等数学凸函数的内容:
Jensen’s inequality:过一个凸函数上任意两点所作割线一定在这两点间的函数图象的上方。理解起来也十分简单,对于凸函数f(x)‘’>0,即曲线的变化率是越来越大单调递增的,所以函数越到后面增长越厉害,这样在一个区间下,函数的均值就会大一些了。

因为ln(*)函数为凹函数,故可以将上式“和的对数”变为“对数的和”,这样就很容易求导了。

接着求解Qi和θ:首先固定θ(初始值),通过求解Qi使得J(θ,Q)在θ处与L(θ)相等,即求出L(θ)的下界;然后再固定Qi,调整θ,最大化下界J(θ,Q)。不断重复两个步骤直到稳定。通过jensen不等式的性质,Qi的计算公式实际上就是后验概率:

通过数学公式的推导,简单来理解这一过程:固定θ计算Q的过程就是在建立L(θ)的下界,即通过jenson不等式得到的下界(E步);固定Q计算θ则是使得下界极大化(M步),从而不断推高边缘似然L(θ)。从而循序渐进地计算出L(θ)取得极大值时隐变量Z的估计值。
EM算法也可以看作一种“坐标下降法”,首先固定一个值,对另外一个值求极值,不断重复直到收敛。这时候也许大家就有疑问,问什么不直接这两个家伙求偏导用梯度下降呢?这时候就是坐标下降的优势,有些特殊的函数,例如曲线函数z=y2+x2+x^2y+xy+…,无法直接求导,这时如果先固定其中的一个变量,再对另一个变量求极值,则变得可行。

EM算法流程
看完数学推导,算法的流程也就十分简单了,这里有两个版本,周志华老师的介绍十分简洁;版本二来自于大牛的博客。结合着数学推导,自认为版本二更具有逻辑性,两者唯一的区别就在于版本二多出了红框的部分
版本一:

版本二:
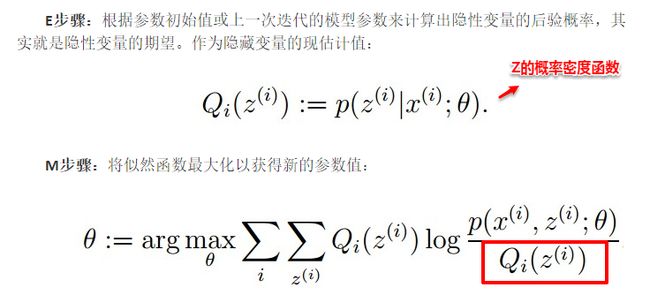
详细的举一个例子:
两枚硬币A和B,假定随机抛掷后正面朝上概率分别为PA,PB。为了估计这两个硬币朝上的概率,咱们轮流抛硬币A和B,每一轮都连续抛5次,总共5轮:
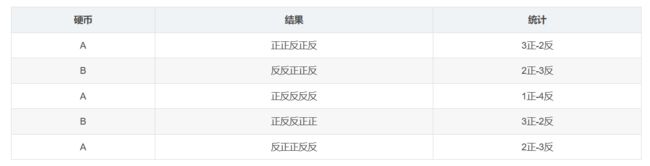
硬币A被抛了15次,在第一轮、第三轮、第五轮分别出现了3次正、1次正、2次正,所以很容易估计出PA,类似的,PB也很容易计算出来(真实值),如下:
P A = ( 3 + 1 + 2 ) / 15 = 0.4 ; P B = ( 2 + 3 ) / 10 = 0.5 PA = (3+1+2)/ 15 = 0.4; PB= (2+3)/10 = 0.5 PA=(3+1+2)/15=0.4;PB=(2+3)/10=0.5
问题来了,如果我们不知道抛的硬币是A还是B呢(即硬币种类是隐变量),然后再轮流抛五轮,得到如下结果:

现在我们的目标没变,还是估计PA和PB,需要怎么做呢?
显然,此时我们多了一个硬币种类的隐变量,设为z,可以把它认为是一个5维的向量(z1,z2,z3,z4,z5),代表每次投掷时所使用的硬币,比如z1,就代表第一轮投掷时使用的硬币是A还是B。
- 但是,这个变量z不知道,就无法去估计PA和PB,所以,我们必须先估计出z,然后才能进一步估计PA和PB。
- 可要估计z,我们又得知道PA和PB,这样我们才能用极大似然概率法则去估计z,这不是鸡生蛋和蛋生鸡的问题吗,如何破?
答案就是先随机初始化一个PA和PB,用它来估计z,然后基于z,还是按照最大似然概率法则去估计新的PA和PB,然后依次循环,如果新估计出来的PA和PB和我们真实值差别很大,直到PA和PB收敛到真实值为止。
我们不妨这样,先随便给PA和PB赋一个值,比如:
硬币A正面朝上的概率PA = 0.2
硬币B正面朝上的概率PB = 0.7
然后,我们看看第一轮抛掷最可能是哪个硬币。
如果是硬币A,得出3正2反的概率为
0.2 ∗ 0.2 ∗ 0.2 ∗ 0.8 ∗ 0.8 = 0.00512 0.2 ∗ 0.2 ∗ 0.2 ∗ 0.8 ∗ 0.8 = 0.00512 0.2∗0.2∗0.2∗0.8∗0.8=0.00512
如果是硬币B,得出3正2反的概率为
0.7 ∗ 0.7 ∗ 0.7 ∗ 0.3 ∗ 0.3 = 0.03087 0.7 ∗ 0.7 ∗ 0.7 ∗ 0.3 ∗ 0.3 = 0.03087 0.7∗0.7∗0.7∗0.3∗0.3=0.03087
然后依次求出其他4轮中的相应概率。做成表格如下:

按照最大似然法则:
第1轮中最有可能的是硬币B
第2轮中最有可能的是硬币A
第3轮中最有可能的是硬币A
第4轮中最有可能的是硬币B
第5轮中最有可能的是硬币A
我们就把概率更大,即更可能是A的,即第2轮、第3轮、第5轮出现正的次数2、1、2相加,除以A被抛的总次数15(A抛了三轮,每轮5次),作为z的估计值,B的计算方法类似。然后我们便可以按照最大似然概率法则来估计新的PA和PB。
P A = ( 2 + 1 + 2 ) / 15 = 0.33 PA = (2+1+2)/15 = 0.33 PA=(2+1+2)/15=0.33
P B = ( 3 + 3 ) / 10 = 0.6 PB =(3+3)/10 = 0.6 PB=(3+3)/10=0.6
就这样,不断迭代 不断接近真实值,这就是EM算法的奇妙之处。
可以期待,我们继续按照上面的思路,用估计出的PA和PB再来估计z,再用z来估计新的PA和PB,反复迭代下去,就可以最终得到PA = 0.4,PB=0.5,此时无论怎样迭代,PA和PB的值都会保持0.4和0.5不变,于是乎,我们就找到了PA和PB的最大似然估计。

贝叶斯网络
贝叶斯网络(Bayesian network),又称信念网络(Belief Network),或有向无环图模型(directed acyclic graphical model),是一种概率图模型。它是一种模拟人类推理过程中因果关系的不确定性处理模型,其网络拓朴结构是一个有向无环图(DAG)。

贝叶斯网络的有向无环图中的节点表示随机变量 X 1 , X 2 , . . . , X n {X_1,X_2,...,X_n} X1,X2,...,Xn
它们可以是可观察到的变量,或隐变量、未知参数等。认为有因果关系(或非条件独立)的变量或命题则用箭头来连接。
若两个节点间以一个单箭头连接在一起,表示其中一个节点是“因(parents)”,另一个是“果(children)”,两节点就会产生一个条件概率值。
例如,假设节点E直接影响到节点H,即E→H,则用从E指向H的箭头建立结点E到结点H的有向弧(E,H),权值(即连接强度)用条件概率P(H|E)来表示,如下图所示:
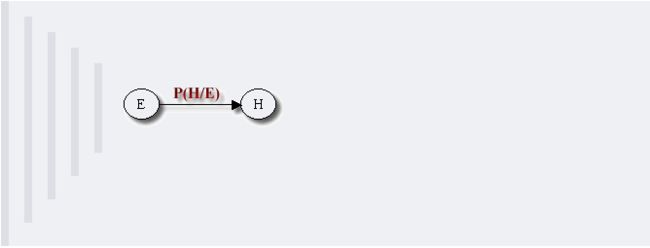
简言之,把某个研究系统中涉及的随机变量,根据是否条件独立绘制在一个有向图中,就形成了贝叶斯网络。
其主要用来描述随机变量之间的条件依赖,用圈表示随机变量(random variables),用箭头表示条件依赖(conditional dependencies)。
此外,对于任意的随机变量,其联合概率可由各自的局部条件概率分布相乘而得出:

先定义E步和M步
import math
def cal_mu(w,p,q,xi):
return w * math.pow(p, xi) * math.pow(1 - p, 1 - xi) / \
float(w * math.pow(p, xi) * math.pow(1 - p, 1 - xi) +
(1 - w) * math.pow(q, xi) * math.pow(1 - q, 1 - xi))
def e_step(w,p,q,x):
mu=[cal_mu(w,p,q,xi) for xi in x]
return mu
def m_step(mu,x):
w=sum(mu)/len(mu)
p=sum([mu[i]*x[i] for i in range(len(mu))])/sum(mu)
q=sum([(1-mu[i])*x[i] for i in range(len(mu))])/\
sum([1-mu[i] for i in range(len(mu))])
return [w,p,q]
再定义迭代过程,输入参数,返回结果
def run(x,w,p,q,maxiteration):
for i in range(maxiteration):
mu=e_step(w,p,q,x)
print(i,[w,p,q])
if [w,p,q]==m_step(mu,x):
break
else:
[w,p,q]=m_step(mu,x)
print([w,p,q])
if __name__=="__main__":
x = [1, 1, 0, 1, 0, 0, 1, 0, 1, 1]
[w,p,q]=[0.4,0.6,0.7]
run(x,w,p,q,100)

Python实现(模拟2个正态分布的均值估计)
import math
import copy
import numpy as np
import matplotlib.pyplot as plt
isdebug = False
# 指定k个高斯分布参数,这里指定k=2。注意2个高斯分布具有相同均方差Sigma,分别为Mu1,Mu2。
def ini_data(Sigma,Mu1,Mu2,k,N):
global X
global Mu
global Expectations
X = np.zeros((1,N))
Mu = np.random.random(2)
Expectations = np.zeros((N,k))
for i in xrange(0,N):
if np.random.random(1) > 0.5:
X[0,i] = np.random.normal()*Sigma + Mu1
else:
X[0,i] = np.random.normal()*Sigma + Mu2
if isdebug:
print "***********"
print u"初始观测数据X:"
print X
# EM算法:步骤1,计算E[zij]
def e_step(Sigma,k,N):
global Expectations
global Mu
global X
for i in xrange(0,N):
Denom = 0
for j in xrange(0,k):
Denom += math.exp((-1/(2*(float(Sigma**2))))*(float(X[0,i]-Mu[j]))**2)
for j in xrange(0,k):
Numer = math.exp((-1/(2*(float(Sigma**2))))*(float(X[0,i]-Mu[j]))**2)
Expectations[i,j] = Numer / Denom
if isdebug:
print "***********"
print u"隐藏变量E(Z):"
print Expectations
# EM算法:步骤2,求最大化E[zij]的参数Mu
def m_step(k,N):
global Expectations
global X
for j in xrange(0,k):
Numer = 0
Denom = 0
for i in xrange(0,N):
Numer += Expectations[i,j]*X[0,i]
Denom +=Expectations[i,j]
Mu[j] = Numer / Denom
# 算法迭代iter_num次,或达到精度Epsilon停止迭代
def run(Sigma,Mu1,Mu2,k,N,iter_num,Epsilon):
ini_data(Sigma,Mu1,Mu2,k,N)
print u"初始:" , Mu
for i in range(iter_num):
Old_Mu = copy.deepcopy(Mu)
e_step(Sigma,k,N)
m_step(k,N)
print i,Mu
if sum(abs(Mu-Old_Mu)) < Epsilon:
break
if __name__ == '__main__':
run(6,40,20,2,1000,1000,0.0001)
plt.hist(X[0,:],50)
plt.show()
本代码用于模拟k=2个正态分布的均值估计。其中ini_data(Sigma,Mu1,Mu2,k,N)函数用于生成训练样本,此训练样本时从两个高斯分布中随机生成的,其中高斯分布a均值Mu1=40、均方差Sigma=6,高斯分布b均值Mu2=20、均方差Sigma=6,生成的样本分布如下图所示。由于本问题中实现无法直接冲样本数据中获知两个高斯分布参数,因此需要使用EM算法估算出具体Mu1、Mu2取值。

在图1的样本数据下,在第11步时,迭代终止,EM估计结果为:
- Mu=[ 40.55261688 19.34252468]
每文一语
生活要么大胆尝试,要么什么都不是