U-Net网络变形综述
U-Net网络变形综述
U-Net and its variants for Medical Image Segmentation : A short review
Abstract
本文简要回顾了U-Net及其变体在医学图像分割中的应用。据我们所知,对任何一位临床医生,无论是放射科医生还是病理学家来说,检查医学图像都不是一件容易的工作。分析医学图像是进行无创诊断的唯一方法。分割感兴趣区域在医学图像中具有重要意义,是诊断的关键。本文还对医学图像分割的发展进行了鸟瞰。还讨论了深层神经结构的挑战和成功。以下是不同的混合架构是如何建立在视觉识别任务的强大技术之上的。最后,我们将看到医学图像分割(MIS)目前面临的挑战和未来的发展方向。
1. Introduction
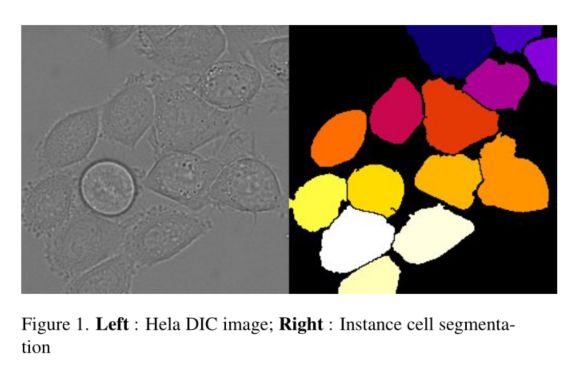
首先让我们理解为什么我们需要在医学图像中进行分割。在过去的几十年里,人们一直在使用图像进行疾病诊断。迄今为止,医疗实践中使用的医学图像模式有十几种,例如X射线、磁共振成像(MRI)、计算机断层扫描(CT)、超声波等。每种图像模式都是根据采集速度、图像分辨率和患者舒适度来选择的。一旦获得图像,临床医生将仔细检查图像,并试图找到疾病和可能的原因。这一过程通常需要几个小时到几天的时间,这取决于问题的复杂性,还需要专家临床医生和技术人员参与。例如,病理学家将查看大型数字病理图像,识别不同类型的组织区域,并寻找他感兴趣的异常区域。放射科医生可以检查不同器官的大小,以检查它们是否正常或需要治疗。眼科医生可能想在你的视网膜图像中寻找血块或脂质。所有这些任务都需要确定感兴趣的区域,例如眼科医生对发现血管泄漏感兴趣。分割是一个临床医生执行的隐性任务,但没有提及。这就是为什么医学图像分割(MIS)对临床医生有很大帮助。差分干涉对比显微镜图像和分割细胞的示例如图1所示。医生希望跟踪细胞以了解其发育,因此他们希望识别和分割细胞,这是一项分割和检测任务。
用机器把这项繁琐的任务自动化,最后的决定将由临床医生做出。早在20世纪80年代,医学图像中的图像分割就已经出现了。到2014年初,通过各种方法进行了图像分割,一些简单的方法有基于直方图阈值的分割、基于聚类的分割、均值漂移分割、图割分割。每种简单的分割方法都有各自的优缺点。但它们在医学图像分割中的应用受到限制。这些方法最好的一点是,它们不需要任何训练,这意味着它们不依赖于数据。在大多数情况下,这些通用的分割算法不适用于医学图像分割。即使对手头的任务进行微调,也几乎没有任何可接受的分割结果。
Deep learning从2010年开始获得关注,并在图像分类方面取得了显著的改进任务和性能优于现有的先进水平。这一成功主要归功于大数据集的可用性和GPU的计算能力。从2012年开始,卷积神经网络在分类、检测、分割等多种任务上都优于所有现有的传统图像处理方法。计算机视觉中的一般任务在大多数数据集上都达到了合理的性能,但在医学视觉任务中却不是这样。这主要是由于数据稀缺、数据偏差、创建标记数据集的成本。例如,一个根据美国医院的患者数据训练的检测糖尿病视网膜病变的模型可能对这些患者群体非常有效,在印度医院测试时表现非常差。由于当地患者特征、图像采集设备、测试计算机配置等原因,医院之间的许多事情都会发生变化。其中一个主要原因是训练集中的数据偏差。数据扩充是为了增加数据集的大小,这有助于学习方差,这是一个必不可少的步骤,除非我们有一个大的数据集。数据预处理是数据增强之前的一个步骤,可能涉及强度变换、标准化和重采样。
鉴于医学图像分割对临床医生和更快诊断的重要性,全球技术机构、医疗机构和研究实验室正在积极研究这一领域。
选择了一个简单的分类方案,介绍了几种流行的基于U-Net的深度神经网络。我们从一个普通的U-Net[6]开始,然后开始结合U-Net的skip connections, residuals, recurrent, attention mechanism and transformer variants。U-Net是用于不同医学图像分割任务的最流行的体系结构之一。自从U-Net发明以来,许多变体都建立在这个基础上。U-Net++[7]有更多嵌套的skip connections,这有助于语义学习和平滑的梯度流。R2U网络[1]是既有剩余连接又有循环连接的U网络。在下一节中,我们将了解这些方法是如何工作的,以及它们为什么适用于MIS。Attention U-Net[5]使用注意门来提高对感兴趣区域的注意。Trans U-Net[2]是U-Net和带有注意力模块的视觉转换器的混合网络。
2. Methodologies
在本节中,我们将简要介绍所选方法的想法,然后探讨它们的演变,以及为什么每种方法都适用于某些分割任务。
2.1. Old school segmentation
在本节中,我们将简要介绍一些在医学图像分割中得到应用的传统图像分割方法。基于阈值的分割涉及从直方图特征中找到合适的阈值,并用该阈值对图像进行二值化。这种方法不适合处理多类分割,也不能处理高度的强度变化。基于聚类的分割涉及将相似的像素分组成簇,并为每个簇指定一个颜色标签。K-means聚类是一种典型的聚类算法,它将图像分割成K个聚类。这种方法的主要缺点是需要事先知道聚类数。Mean-shift分割本质上是一种hill climbing algorithm(爬山)算法,它使用一个窗口(w)和窗口的平均值来爬山。属于山丘的所有像素都被指定给同一簇。图割分割是基于最大流和最小割算法的最复杂的分割算法。传统的分割算法对自然图像都有很好的分割效果,但在医学图像分割中表现不佳。在此,我们将简要介绍基于神经网络的医学图像分割方法。
2.2. U-Net 2015
U-Net[6](图2)是Ronneberger提出的卷积神经网络。它建立在编码器-解码器体系结构的基础上,该体系结构简单地是一个分层的下采样卷积层,然后是对称的上采样卷积层,此外,来自编码器网络的特征映射被连接到相应的解码器部分,以传递语义信息。左侧部分是收缩路径,称为编码器,因为它将高空间维度的信息编码为低维潜在表示。右半部分是扩展路径,称为解码器,它将低维潜在表示解码为高维分割映射。编码器包含带有3X3滤波器的卷积(conv)层,后跟线性激活函数ReLU(整流线性单元)。又是一个conv层,后面是ReLU。这个conv-relu conv-relu被称为conv-block。使用一个称为Max Pool的子采样层来降低特征地图的空间维度。编码器中的特征映射数量逐渐增加。解码器是一个对称的编码器网络,但它不是最大池,而是使用卷积或转置卷积来增加特征映射的空间维度。在整个解码器中,特征映射的数量逐渐减少。此外,编码器的特征会被裁剪,以适应解码器特征映射的尺寸,并连接起来。Softmax层用于按像素分类,从而生成分割图。U-Net是一个端到端的网络,通过交叉熵损失进行训练。
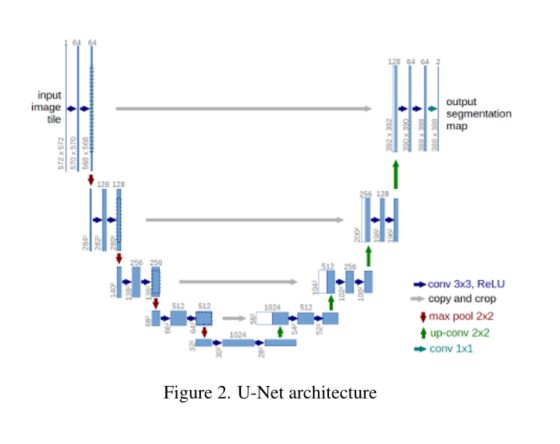
U-Net在医学图像分割中如此流行的原因是,通常在医疗任务中,数据的可用性是稀缺的,而使用少量数据进行学习的模型需要几个小时。令人惊讶的是,U-Net满足了确切的要求,它甚至优于其他方法,如图2所示。U-Net架构,图像数量非常少。当U-Net在35张部分注释的相衬光学显微镜图像上进行训练时,它的IoU(联合交叉)分数达到了0.92,这是2015年最好的。分割结果如第6页图1和图2的补充图所示。
2.3. U-Net++ 2019
U-Net++[7](图3)是一个嵌套的U-Net体系结构,densely connected[4],并受到densely connected。在MIS中,精确分割是一项严格的要求,否则会导致后续干预任务的性能不佳。Nested and dense skip connections 用于向解码器部分提供正确的语义和粗略分级的信息。这些密集的卷积连接最初是由Huang[4]提出的,它具有从之前所有层到当前层的前向连接。这些紧密的联系有助于消除梯度问题、特征重用、加强特征传播。作者介绍了深度监控,帮助学习不同级别的粗粒度和细粒度特征。在子网络的最后一层收集分割图,并向上采样到输入比例,以便进行深度监控。与U-Net的主要区别是
1)Convolutional layers in the skip pathways
2)Dense skip connections for gradient flow
3)Deep supervision
U-Net++在U-Net和wide U-Net上的平均IoU分数分别为3.9分和3.4分,这在很多情况下都是有益的。分割结果如第7页图3中的补充图所示。

2.4. R2U-Net 2018
R2U-Net[1](图4)是另一种U-Net变体,它建立在流行的剩余和循环技术之上。图3。U-Net++体系结构深度卷积网络在大多数计算机视觉任务中表现良好。但由于梯度传播问题,即消失梯度和爆炸梯度,叠加层有其局限性。为了解决消失梯度问题,引入了跳跃/身份连接。这只是定义为从上一个块到下一个块的标识连接,通过该连接跳过当前块操作。[3]微软亚洲研究院(Microsoft research Asia)引入了一种全新的构建深度网络的模式。从那时起,resnet被广泛应用于各种深度网络中。自过去30年以来,递归网络一直存在,但它们的真正应用只是在过去10年才开发出来的。递归网络及其变体主要用于序列数据,例如自然语言、语音信号等。递归网络具有从输出到输入的递归反馈连接。这种反复出现的联系最终将有助于学习顺序上下文。而剩余杠杆技术是建立在剩余杠杆技术之上的。U-Net中的每个卷积块都被一个循环残差块替换。R2U网络中使用了一种从编码器到解码器的更简单的功能串联,而不是普通U网络中使用的裁剪和复制。虽然参数数量相似,但R2U网络在实证实验中表现出一致的性能改进。作者在血管分割、皮肤损伤分割和肺损伤分割方面进行了实验,结果表明R2U的性能优于标准U-Net。通常使用Sørensen–骰子系数和Jaccard分数来评估分割,这两个系数分别是$DSC=\frac{2|X\cap Y|}{|X|+|Y|} $ 和$JS=\frac{|X\cap Y|}{|X|+|Y|} $ 。在皮肤癌病变分割方面,R2U-Net的骰子得分为0.86,标准U-Net的骰子得分为0.84。在视网膜血管分割和肺部病变分割中,R2U-Net的表现略好于标准U-Net。分割结果如第8、9、10页图4、5、6、7、8、9中的补充图所示。

2.5. Attention U-Net 2018
注意U-Net[5](图5)是一种混合结构,在跳跃路径中有注意门。这些注意门只会将显著特征传递给解码器,并抑制冗余信息,以便精确重建分割图。注意机制最初应用于语言任务,取得了巨大的成功,视觉任务也借鉴了注意机制的思想。从根本上说,注意力门有助于了解当地情况。有两种类型的注意门,一种是软注意,另一种是硬注意。软注意输出权重在0到1之间的输入加权组合,这是一个可微函数。注意U-Net在跳跃路径中使用软注意门。如果数据集在RoI的形状和大小上有很大的变化,前面讨论的模型将受到影响。注意门隐含地强调了显著的特征,并关注RoI。编码器和解码器之间还存在残余和密集连接,这与前面的方法中提到的有其自身的优点。注意门会带来额外的计算开销,但会提高分割精度。在CT82胰腺分割数据集上,Attention U-Net的骰子得分为81.48±6.23。在各种各样的任务中,注意力U-Net始终以微弱的优势超过香草U-Net。分割结果如第11页图10中的补充图所示。

2.6. Trans U-Net 2021
当形状和大小变化较大时,全卷积网络(FCN)表现出较弱的性能。Trans U-Net[2](图6)是一种基于视觉转换器(ViT)的架构。Transformer networks在语言翻译和语音翻译等序列到序列预测任务方面取得了显著的改进。Transformer包含多头自我关注模块,可提供全局自我关注。卷积神经网络具有内在的局部性。由于卷积是局部操作,U-Net无法学习全局空间依赖关系。仅使用变压器也是不可行的选择,因为缺少低级细节。作者指出,通过将U型网络和变压器相结合,我们可以实现这两种网络的优点。本质上,Transune是变压器和UNet的组合。在这项工作中,Transformer使用全局表示对贴片图像特征进行编码,而解码器将特征向上采样到原始图像尺寸。普通的U-Net编码器被基于CNN的特征提取器取代,然后是Transformer层。在向解码器传递之前,编码的CNN特征和转换器特征被适当地连接起来。这种编码方法有助于精确定位RoI。通过跳过连接在多个级别聚合功能。减少了欠分段和过拟合,更好的全局上下文学习了更好的语义信息。Trans U-Net通过MICCAI腹部标记挑战的30次腹部CT扫描进行评估,平均DSC为77.48,优于标准U-Net的74.68。作者还表明,Trans U-Net的表现一直优于最受关注的U-Net。分割结果如第11页图11中的补充图所示。

3. Discussion
再次提醒大家,我们的主要目标是开发一个精确的医学图像分割模型。任何MIS模型的目标都是在大多数医学图像模式中提供强大的分割能力。需要一种通用的健壮的MIS方法。
传统的分割算法无法推广到特定任务的MIS中。这些算法的主要优点是,它们根本不需要任何训练数据。在U-Net发展之前,完全卷积网络(FCN)没有特别注意网络设计,与传统方法相比,它取得了部分成功。MIS在U-Net之后才开始获得吸引力,它彻底改变了这个领域。UNet的主要贡献是
1)通用图像分割架构,可用于任意分割任务
2)提供适当的数据和训练时间,精确度高
3)与其他方法相比速度更快
4)即使训练数据非常有限,也能取得成功
5)在生物医学分割应用中特别成功
U-Net的唯一限制是它使用整个图像,因此当图像较大时,需要高GPU内存。
U-Net++和R2U-Net利用了强大的技术,比如在其他视觉任务中使用的剩余连接和密集连接。虽然这些方法略微提高了性能,但它们非常复杂。后来,注意力U-Net也有了轻微的改进,但它具有很高的复杂性和额外的计算开销。只有TransU Net在性能改善和变压器网络复杂性方面有合理的权衡。与U-Net相比,TransU-Net还需要更多的训练数据来显示合理的改进。虽然我们看到了U-Net的所有四种不同变体,但除TransU-Net之外,其他三种变体的性能提升幅度都很小。从2016年到2020年,管理信息系统的发展十分缓慢,只有变压器的出现才使其重新走上轨道。医学图像分割在一定程度上被临床医生和工程师所接受,但仍然存在许多挑战。他们是
1)有各种各样的医学图像可以进行分割
2)训练数据的可用性有限
3)噪音标签;不同临床图像注释者之间的注释偏差
4)缺少临床专家和机器学习研究人员之间的反馈沟通
很明显,神经架构是MIS成功的关键。因此,对MIS的自动神经架构搜索可以成为研究人员寻找更好的MIS的潜在方向。我们也知道,每个神经结构都是用一组超参数训练的,这导致了模型的成功。自动机器学习(AutoML)可以搜索正确的神经结构、数据增强技术、超参数、损失函数,这将引起研究人员的极大兴趣。模型解释是为了更好地理解模型并在其基础上进行构建。除了监督学习方法外,医学影像学中的自监督学习和弱监督学习也是处理弱标记和未标记数据的潜在方向。