模型评价指标(1)--混淆矩阵Confsion Matrix
目录
前言
混淆矩阵Confusion Matrix
基本概念
TP、FP、FN、TN关系:
公式及意义
混淆矩阵的pytorch实现
头文件
定义混淆矩阵类
使用Confusion Matrix进行分类模型的指标评价
最终实现
前言

相信自己!!!微步微步
资源链接:
1.程序源码已经打包在百度网盘了:
链接:https://pan.baidu.com/s/1dM4AySQ5tm0lEBrrhXqHnQ
提取码:1234
2.flower_data数据集:
链接:https://pan.baidu.com/s/12EwdqjFJkk22yZtd3DrRMg
提取码:1234
混淆矩阵Confusion Matrix
混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。混淆矩阵是评判模型结果的指标,属于模型评估的一部分。此外,混淆矩阵多用于判断分类器(Classifier)的优劣,适用于分类型的数据模型,如分类树(Classification Tree)、逻辑回归(Logistic Regression)、线性判别分析(Linear Discriminant Analysis)等方法。
基本概念
TP、FP、FN、TN关系:
| 混淆矩阵 |
真实值 |
||
| Positive |
Negative |
||
| 预测值 |
Positive |
TP |
FP |
| Negative |
FN |
TN |
|
- 真实值是positive,模型认为是positive的数量(True Positive=TP)
- 真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第二类错误(Type II Error)
- 真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第一类错误(Type I Error)
- 真实值是negative,模型认为是negative的数量(True Negative=TN)
公式及意义
| 指标 |
公式 |
意义 |
| 准确率 (ACC) |
|
模型正确分类样本数占总样本的比例(对所有的类别) |
| 精确率 (PPV) |
|
模型预测的所有positive中,预测正确的比例 |
| 灵敏度/召回率 (TPR) |
|
所有真实的positive中,模型预测正确的positive的比例 |
| 特异度 (TNR) |
|
所有真实的negative中,模型预测正确的negative的比例 |
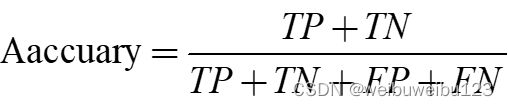



混淆矩阵的pytorch实现
头文件
import os
import json
import torch
from torchvision import transforms, datasets
import numpy as np
from tqdm import tqdm
import matplotlib.pyplot as plt
from prettytable import PrettyTable
定义混淆矩阵类
class ConfusionMatrix(object):
"""
注意,如果显示的图像不全,是matplotlib版本问题
本例程使用matplotlib-3.2.1(windows and ubuntu)绘制正常
需要额外安装prettytable库,PrettyTable 是python中的一个第三方库,可用来生成美观的ASCII格式的表格,十分实用。
"""
def __init__(self, num_classes: int, labels: list):
#1.初始化矩阵,表格的大小为num_classes * num_classes
#2.获取输入的种类类别
#3.获取输入的标签
self.matrix = np.zeros((num_classes, num_classes))
self.num_classes = num_classes
self.labels = labels
def update(self, preds, labels):
#1.将预测值preds和标签labels打包组合遍历
#2.得到预测值preds输出的类别,并且相应的类别数量+1
for p, t in zip(preds, labels):
self.matrix[p, t] += 1
def summary(self):
# calculate accuracy,计算正确率
sum_TP = 0
for i in range(self.num_classes):
#统计混淆矩阵对角线元素的和
sum_TP += self.matrix[i, i]
#ACC = TP / (TP + TN + FP + FN)
acc = sum_TP / np.sum(self.matrix)
print("the model accuracy is ", acc)
# precision, recall, specificity
table = PrettyTable()
table.field_names = ["", "Precision", "Recall", "Specificity"]
for i in range(self.num_classes):
TP = self.matrix[i, i]
FP = np.sum(self.matrix[i, :]) - TP
FN = np.sum(self.matrix[:, i]) - TP
TN = np.sum(self.matrix) - TP - FP - FN
Precision = round(TP / (TP + FP), 3) if TP + FP != 0 else 0.
Recall = round(TP / (TP + FN), 3) if TP + FN != 0 else 0.
Specificity = round(TN / (TN + FP), 3) if TN + FP != 0 else 0.
table.add_row([self.labels[i], Precision, Recall, Specificity])
print(table)
def plot(self):
matrix = self.matrix
print(matrix)
#颜色的变化从白色到蓝色
plt.imshow(matrix, cmap=plt.cm.Blues)
# 设置x轴坐标label
plt.xticks(range(self.num_classes), self.labels, rotation=45)
# 设置y轴坐标label
plt.yticks(range(self.num_classes), self.labels)
# 显示colorbar
plt.colorbar()
plt.xlabel('True Labels')
plt.ylabel('Predicted Labels')
plt.title('Confusion matrix')
# 在图中标注数量/概率信息
thresh = matrix.max() / 2
for x in range(self.num_classes):
for y in range(self.num_classes):
# 注意这里的matrix[y, x]不是matrix[x, y]
info = int(matrix[y, x])
plt.text(x, y, info,
verticalalignment='center',
horizontalalignment='center',
color="white" if info > thresh else "black")
plt.tight_layout()
plt.show()
使用Confusion Matrix进行分类模型的指标评价
使用改步骤进行分类的网络模型的混淆矩阵的绘制问题,所遵循的步骤如下:
a.定义数据的预处理部分程序
b.加载测试数据集
c.调用分类模型的网络
d.加载分类模型的权重,注意这里的预训练权重是已经训练好的,并且和你的训练的数据集相关。
e.加载分类模型的类别.json文件,并获取类别标签
f.建立混淆矩阵
g.进行验证集的测试,并且更新混淆矩阵的参数
h.调用混淆矩阵类中的成员函数summary和plot函数绘图
程序源码如下:
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
data_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
# image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
image_path = './flower_data'
assert os.path.exists(image_path), "data path {} does not exist.".format(image_path)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform)
batch_size = 2
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=batch_size, shuffle=False,
num_workers=2)
net = MobileNetV2(num_classes=5)
# load pretrain weights
model_weight_path = "./MobileNetV2.pth"
assert os.path.exists(model_weight_path), "cannot find {} file".format(model_weight_path)
net.load_state_dict(torch.load(model_weight_path, map_location=device))
net.to(device)
# read class_indict
json_label_path = './class_indices.json'
assert os.path.exists(json_label_path), "cannot find {} file".format(json_label_path)
json_file = open(json_label_path, 'r')
class_indict = json.load(json_file)
labels = [label for _, label in class_indict.items()]
confusion = ConfusionMatrix(num_classes=5, labels=labels)
net.eval()
with torch.no_grad():
for val_data in tqdm(validate_loader):
val_images, val_labels = val_data
outputs = net(val_images.to(device))
outputs = torch.softmax(outputs, dim=1)
outputs = torch.argmax(outputs, dim=1)
confusion.update(outputs.to("cpu").numpy(), val_labels.to("cpu").numpy())
confusion.plot()
confusion.summary()
mobileNetV2模型文件
from torch import nn
import torch
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
最终实现
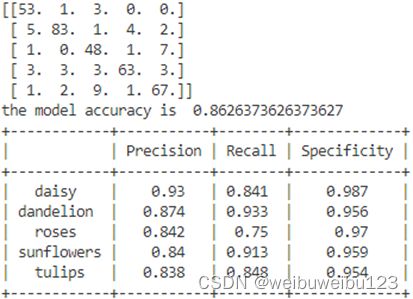
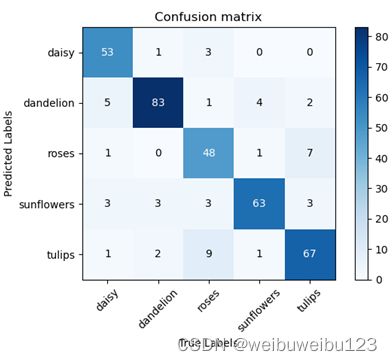
使用MobileNet_V2深度神经网络,进行测试,其中目录的权重文件MobileNetV2.pth是进行5次的训练得到,训练的数据集合为flower_data,共包含5个类别:“daisy、dandelion、roses、sunflowers、tulips”,目录中的modle.py文件为MobileNet_V2网络。目录结构如下图所示:
训练的结果如下,包括混淆矩阵,和plot显示的图形: