第二十天自然语言处理之传统技术
目 录
-
- 二、传统NLP处理技术
-
- 1. 中文分词
-
- 1)正向最大匹配法
- 2)逆向最大匹配法
- 3)双向最大匹配法
- 2. 词性标注
-
- 1)什么是词性标注
- 2)词性标注的原理
- 3)词性标注规范
- 4)经典序列模型:HMM
- 5)Jieba库词性标注
- 3. 命名实体识别(NER)
- 4. 关键词提取
-
- 1)TF-IDF算法
- 2)TextRank算法
- 3)关键词提取示例
二、传统NLP处理技术
1. 中文分词
中文分词是一项重要的基本任务,分词直接影响对文本语义的理解。分词主要有基于规则的分词、基于统计的分词和混合分词。基于规则的分词主要是通过维护词典,在切分语句时,将语句的每个子字符串与词表中的词语进行匹配,找到则切分,找不到则不切分;基于统计的分词,主要是基于统计规则和语言模型,输出一个概率最大的分词序列(由于所需的知识尚未讲解,此处暂不讨论);混合分词就是各种分词方式混合使用,从而提高分词准确率。下面介绍基于规则的分词。
1)正向最大匹配法
正向最大匹配法(Forward Maximum Matching,FMM)是按照从前到后的顺序对语句进行切分,其步骤为:
- 从左向右取待分汉语句的m个字作为匹配字段,m为词典中最长词的长度;
- 查找词典进行匹配;
- 若匹配成功,则将该字段作为一个词切分出去;
- 若匹配不成功,则将该字段最后一个字去掉,剩下的字作为新匹配字段,进行再次匹配;
- 重复上述过程,直到切分所有词为止。
2)逆向最大匹配法
逆向最大匹配法(Reverse Maximum Matching, RMM)基本原理与FMM基本相同,不同的是分词的方向与FMM相反。RMM是从待分词句子的末端开始,也就是从右向左开始匹配扫描,每次取末端m个字作为匹配字段,匹配失败,则去掉匹配字段前面的一个字,继续匹配。
3)双向最大匹配法
双向最大匹配法(Bi-directional Maximum Matching,Bi-MM)是将正向最大匹配法得到的分词结果和逆向最大匹配法得到的结果进行比较,然后按照最大匹配原则,选取词数切分最少的作为结果。双向最大匹配的规则是:
-
如果正反向分词结果词数不同,则取分词数量少的那个;
-
分词结果相同,没有歧义,返回任意一个;分词结果不同,返回其中单字数量较少的那个。
【示例1】正向最大匹配分词法
# 正向最大匹配分词示例
class MM(object):
def __init__(self):
self.window_size = 3
def cut(self, text):
result = [] # 分词结果
start = 0 # 起始位置
text_len = len(text) # 文本长度
dic = ["吉林", "吉林市", "市长", "长春", "春药", "药店"]
while text_len > start:
for size in range(self.window_size + start, start, -1): # 取最大长度,逐步比较减小
piece = text[start:size] # 切片
if piece in dic: # 在字典中
result.append(piece) # 添加到列表
start += len(piece)
break
else: # 没在字典中,什么都不做
if len(piece) == 1:
result.append(piece) # 单个字成词
start += len(piece)
return result
if __name__ == "__main__":
text = "吉林市长春药店"
tk = MM() # 实例化对象
result = tk.cut(text)
print(result)
执行结果:
['吉林市', '长春', '药店']
【示例2】逆向最大匹配分词法
# 逆向最大匹配分词示例
class RMM(object):
def __init__(self):
self.window_size = 3
def cut(self, text):
result = [] # 分词结果
start = len(text) # 起始位置
text_len = len(text) # 文本长度
dic = ["吉林", "吉林市", "市长", "长春", "春药", "药店"]
while start > 0:
for size in range(self.window_size, 0, -1):
piece = text[start-size:start] # 切片
if piece in dic: # 在字典中
result.append(piece) # 添加到列表
start -= len(piece)
break
else: # 没在字典中
if len(piece) == 1:
result.append(piece) # 单个字成词
start -= len(piece)
break
result.reverse()
return result
if __name__ == "__main__":
text = "吉林市长春药店"
tk = RMM() # 实例化对象
result = tk.cut(text)
print(result)
执行结果:
['吉林市', '长春', '药店']
【示例3】Jieba库分词
Jieba是一款开源的、功能丰富、使用简单的中文分词工具库,它提供了三种分词模式:
- 精确模式:试图将句子最精确地分词,适合文本分析
- 全模式:把句子中所有可以成词的词语分割出来,速度快,但有重复词和歧义
- 搜索引擎模式:在精确模式基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
使用Jieba库之前,需要进行安装:
pip install jieba==0.42.1
分词示例代码如下:
# jieba分词示例
import jieba
text = "吉林市长春药店"
# 全模式
seg_list = jieba.cut(text, cut_all=True)
for word in seg_list:
print(word, end="/")
print()
# 精确模式
seg_list = jieba.cut(text, cut_all=False)
for word in seg_list:
print(word, end="/")
print()
# 搜索引擎模式
seg_list = jieba.cut_for_search(text)
for word in seg_list:
print(word, end="/")
print()
执行结果:
吉林/吉林市/市长/长春/春药/药店/
吉林市/长春/药店/
吉林/吉林市/长春/药店/
【示例4】文本高频词汇提取
# 通过tf-idf提取高频词汇
import glob
import random
import jieba
# 读取文件内容
def get_content(path):
with open(path, "r", encoding="gbk", errors="ignore") as f:
content = ""
for line in f.readlines():
line = line.strip()
content += line
return content
# 统计词频,返回最高前10位词频列表
def get_tf(words, topk=10):
tf_dict = {}
for w in words:
if w not in tf_dict.keys():
tf_dict[w] = 1
else:
num = tf_dict[w]
num += 1
tf_dict[w] = num
# 倒序排列
new_list = sorted(tf_dict.items(), key=lambda x: x[1], reverse=True)
return new_list[:topk]
# 去除停用词
def get_stop_words(path):
with open(path, encoding="utf8") as f:
return [line.strip() for line in f.readlines()]
if __name__ == "__main__":
# 样本文件
fname = "d:\\NLP_DATA\\chap_3\\news\\C000008\\11.txt"
# 读取文件内容
corpus = get_content(fname)
# 分词
tmp_list = list(jieba.cut(corpus))
# 去除停用词
stop_words = get_stop_words("d:\\NLP_DATA\\chap_3\\stop_words.utf8")
split_words = []
for tmp in tmp_list:
if tmp not in stop_words:
split_words.append(tmp)
# print("样本:\n", corpus)
print("\n 分词结果: \n" + "/".join(split_words))
# 统计高频词
tf_list = get_tf(split_words)
print("\n top10词 \n:", str(tf_list))
执行结果:
分词结果:
焦点/个股/苏宁/电器/002024/该股/早市/涨停/开盘/其后/获利盘/抛/压下/略有/回落/强大/买盘/推动/下该/股/已经/再次/封于/涨停/主力/资金/积极/拉升/意愿/相当/强烈/盘面/解析/技术/层面/早市/指数/小幅/探低/迅速/回升/中石化/强势/上扬/带动/指数/已经/成功/翻红/多头/实力/之强/令人/瞠目结舌/市场/高度/繁荣/情形/投资者/需谨慎/操作/必竟/持续/上攻/已经/消耗/大量/多头/动能/盘中/热点/来看/相比/周二/略有/退温/依然/看到/目前/热点/效应/外扩散/迹象/相当/明显/高度/活跌/板块/已经/前期/有色金属/金融/地产股/向外/扩大/军工/概念/航天航空/操作/思路/短线/依然/需/规避/一下/技术性/回调/风险/盘中/切记/不可/追高
top10词:
[('已经', 4), ('早市', 2), ('涨停', 2), ('略有', 2), ('相当', 2), ('指数', 2), ('多头', 2), ('高度', 2), ('操作', 2), ('盘中', 2)]
2. 词性标注
1)什么是词性标注
词性是词语的基本语法属性,通常也称为词类。词性标注是判定给定文本或语料中每个词语的词性。有很多词语在不同语境中表现为不同的词性,这就为词性标注带来很大的困难。另一方面,从整体上看,大多数词语,尤其是实词,一般只有一到两个词性,其中一个词性的使用频率远远大于另一个。
2)词性标注的原理
词性标注最主要方法同分词一样,将其作为一个序列生成问题来处理。使用序列模型,根据输入的文本,生成一个对应的词性序列。
3)词性标注规范
词性标注要有一定的标注规范,如将名词、形容词、动词表示为"n", “adj”, "v"等。中文领域尚无统一的标注标准,较为主流的有北大词性标注集和宾州词性标注集。以下是北大词性标注集部分词性表示:

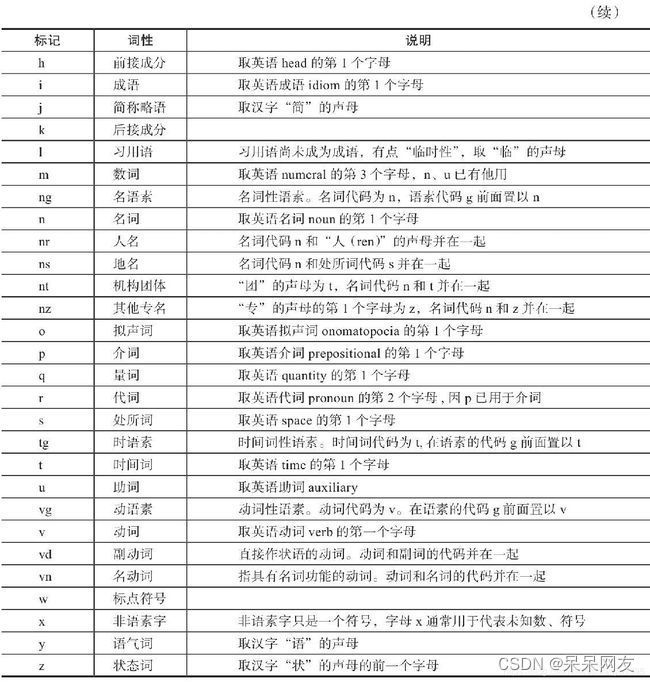
4)经典序列模型:HMM
隐马尔可夫模型(Hidden Markov Model,HMM)是关于时间序列的概率模型,描述一个隐藏的马尔可夫链随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程,是一个双随机过程序列模型。以下是一个双随机序列示例:
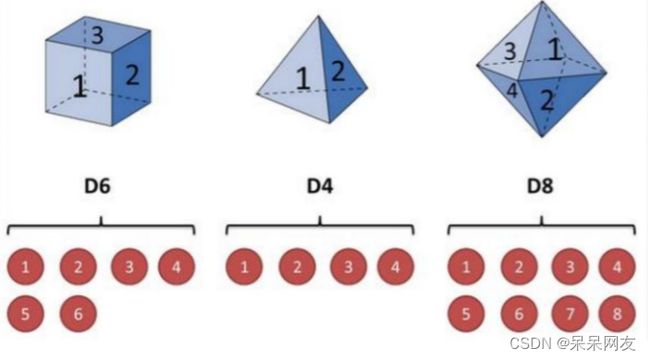

HMM模型包含三个要素:
- 初始概率: π = ( 0.2 , 0.4 , 0.4 ) \pi=(0.2, 0.4, 0.4) π=(0.2,0.4,0.4)
- 转移概率:在不同状态间转换的概率,例如: P A A = 0.8 , P A B = 0.1 , . . . P_{AA}=0.8, P_{AB}=0.1, ... PAA=0.8,PAB=0.1,...
- 转移矩阵:
A = [ 0.8 0.1 0.1 0.5 0.1 0.4 0.5 0.3 0.2 ] A = \left[ \begin{matrix} 0.8 \ \ 0.1 \ \ 0.1 \\ 0.5 \ \ 0.1 \ \ 0.4 \\ 0.5 \ \ 0.3 \ \ 0.2 \\ \end{matrix} \right] A=⎣ ⎡0.8 0.1 0.10.5 0.1 0.40.5 0.3 0.2⎦ ⎤
HMM模型的三个基本问题:
- 概率计算问题。给定初始 λ = ( A , B , π ) \lambda =(A, B, \pi) λ=(A,B,π)和观测序列,计算该模型观测序列出现的概率,概率计算问题使用前向算法、后向算法
- 学习问题。已知观测序列,估计模型参数 λ = ( A , B , π ) \lambda =(A, B, \pi) λ=(A,B,π),学习问题使用Baum-Welch算法
- 解码问题。已知模型参数 λ = ( A , B , π ) \lambda =(A, B, \pi) λ=(A,B,π)和观测序列,求条件概率最大的状态序列,解码问题使用Viterbi算法
HMM的应用:
-
语音识别:输入语音序列(观测序列),输出文字序列(隐藏序列)
-
分词:输入原始文本,输出分词序列
-
词性标记:输入词语列表,输出词性列表
5)Jieba库词性标注
Jieba库提供了词性标注功能,采用结合规则和统计的方式,具体为在词性标注的过程中,词典匹配和HMM共同作用。词性标注流程如下:
第一步:根据正则表达式判断文本是否为汉字;
第二步:如果判断为汉字,构建HMM模型计算最大概率,在词典中查找分出的词性,若在词典中未找到,则标记为"未知";
第三步:若不如何上面的正则表达式,则继续通过正则表达式进行判断,分别赋予"未知"、”数词“或"英文"。
【示例】Jieba库实现词性标注
import jieba.posseg as psg
def pos(text):
results = psg.cut(text)
for w, t in results:
print("%s/%s" % (w, t), end=" ")
print("")
text = "呼伦贝尔大草原"
pos(text)
text = "梅兰芳大剧院里星期六晚上有演出"
pos(text)
执行结果:
呼伦贝尔/nr 大/a 草原/n
梅兰芳/nr 大/a 剧院/n 里/f 星期六/t 晚上/t 有/v 演出/v
3. 命名实体识别(NER)
命名实体识别(Named Entities Recognition,NER)也是自然语言处理的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种自然语言处理技术必不可少的组成部分。其目的是识别语料中人名、地名、组织机构名等命名实体,实体类型包括3大类(实体类、时间类和数字类)和7小类(人名、地名、组织机构名、时间、日期、货币和百分比)。中文命名实体识别主要有以下难点:
(1)各类命名实体的数量众多。
(2)命名实体的构成规律复杂。
(2)嵌套情况复杂。
(4)长度不确定。
命名实体识别方法有:
(1)基于规则的命名实体识别。规则加词典是早期命名实体识别中最行之有效的方式。其依赖手工规则的系统,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断。这种方式可移植性差、更新维护困难等问题。
(2)基于统计的命名实体识别。基于统计的命名实体识别方法有:隐马尔可夫模型、最大熵模型、条件随机场等。其主要思想是基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于统计的方法对语料库的依赖比较大,而可以用来建设和评估命名实体识别系统的大规模通用语料库又比较少,这是该方法的一大制约。
(3)基于深度学习的方法。利用深度学习模型,预测词(或字)是否为命名实体,并预测出起始、结束位置。
(4)混合方法。将前面介绍的方法混合使用。
命名实体识别在深度学习部分有专门案例进行探讨和演示。
4. 关键词提取
关键词提取是提取出代表文章重要内容的一组词,对文本聚类、分类、自动摘要起到重要作用。此外,关键词提取还能使人们便捷地浏览和获取信息。现实中大量文本不包含关键词,自动提取关检测技术具有重要意义和价值。关键词提取包括有监督学习、无监督学习方法两类。
有监督关键词提取。该方法主要通过分类方式进行,通过构建一个较为丰富完整的词表,然后通过判断每个文档与词表中每个词的匹配程度,以类似打标签的方式,达到关键词提取的效果。该方法能获取较高的精度,但需要对大量样本进行标注,人工成本过高。另外,现在每天都有大量新的信息出现,固定词表很难将新信息内容表达出来,但人工实时维护词表成本过高。所以,有监督学习关键词提取方法有较明显的缺陷。
无监督关键词提取。相对于有监督关键词提取,无监督方法对数据要求低得多,既不需要人工维护词表,也不需要人工标注语料辅助训练。因此,在实际应用中更受青睐。这里主要介绍无监督关键词提取算法,包括TF-IDF算法,TextRank算法和主题模型算法。
1)TF-IDF算法
TF-IDF(Term Frequency-Inverse Document Frequency,词频-逆文档频率)是一种基于传统的统计计算方法,常用于评估一个文档集中一个词对某份文档的重要程度。其基本思想是:一个词语在文档中出现的次数越多、出现的文档越少,语义贡献度越大(对文档区分能力越强)。TF-IDF表达式由两部分构成,词频、逆文档频率。词频定义为:
T F i j = n j i ∑ k n k j TF_{ij} = \frac{n_{ji}}{\sum_k n_{kj}} TFij=∑knkjnji
其中, n i j n_{ij} nij表示词语i在文档j中出现的次数,分母 ∑ k n k j \sum_k n_{kj} ∑knkj表示所有文档总次数。逆文档频率定义为:
I D F i = l o g ( ∣ D ∣ ∣ D i ∣ + 1 ) IDF_i = log(\frac{|D|}{|D_i| + 1}) IDFi=log(∣Di∣+1∣D∣)
其中, ∣ D ∣ |D| ∣D∣为文档总数, D i D_i Di为文档中出现词i的文档数量,分母加1是避免分母为0的情况(称为拉普拉斯平滑),TF-IDF算法是将TF和IDF综合使用,表达式为:
T F − I D F = T F i j × I D F i = n j i ∑ k n k j × l o g ( ∣ D ∣ ∣ D i ∣ + 1 ) TF-IDF = TF_{ij} \times IDF_i =\frac{n_{ji}}{\sum_k n_{kj}} \times log(\frac{|D|}{|D_i| + 1}) TF−IDF=TFij×IDFi=∑knkjnji×log(∣Di∣+1∣D∣)
由公式可知,词频越大,该值越大;出现的文档数越多(说明该词越通用),逆文档频率越接近0,语义贡献度越低。例如有以下文本:
世界献血日,学校团体、献血服务志愿者等可到血液中心参观检验加工过程,我们会对检验结果进行公示,同时血液的价格也将进行公示。
以上文本词语总数为30,计算几个词的词频:
T F 献血 = 2 / 30 ≈ 0.067 T F 血液 = 2 / 30 ≈ 0.067 T F 进行 = 2 / 30 ≈ 0.067 T F 公示 = 2 / 30 ≈ 0.067 TF_{献血} = 2 / 30 \approx 0.067 \\ TF_{血液} = 2 / 30 \approx 0.067 \\ TF_{进行} = 2 / 30 \approx 0.067 \\ TF_{公示} = 2 / 30 \approx 0.067 TF献血=2/30≈0.067TF血液=2/30≈0.067TF进行=2/30≈0.067TF公示=2/30≈0.067
假设出现献血、血液、进行、公示文档数量分别为10、15、100、50,根据TF-IDF计算公式,得:
T F − I D F 献血 = 0.067 ∗ l o g ( 1000 / 10 ) = 0.067 ∗ 2 = 0.134 T F − I D F 血液 = 0.067 ∗ l o g ( 1000 / 15 ) = 0.067 ∗ 1.824 = 0.1222 T F − I D F 进行 = 0.067 ∗ l o g ( 1000 / 100 ) = 0.067 ∗ 1 = 0.067 T F − I D F 公示 = 0.067 ∗ l o g ( 1000 / 50 ) = 0.067 ∗ 1.30 = 0.08717 TF-IDF_{献血} = 0.067 * log(1000/10) = 0.067 * 2 = 0.134\\ TF-IDF_{血液} = 0.067 * log(1000/15) = 0.067 * 1.824 = 0.1222 \\ TF-IDF_{进行} = 0.067 * log(1000/100) = 0.067 * 1 = 0.067 \\ TF-IDF_{公示} = 0.067 * log(1000/50) = 0.067 * 1.30 = 0.08717 TF−IDF献血=0.067∗log(1000/10)=0.067∗2=0.134TF−IDF血液=0.067∗log(1000/15)=0.067∗1.824=0.1222TF−IDF进行=0.067∗log(1000/100)=0.067∗1=0.067TF−IDF公示=0.067∗log(1000/50)=0.067∗1.30=0.08717
“献血”、“血液”的TF-IDF值最高,所以为最适合这篇文档的关键词。
2)TextRank算法
与TF-IDF不一样,TextRank算法可以脱离于语料库,仅对单篇文档进行分析就可以提取该文档的关键词,这也是TextRank算法的一个重要特点。TextRank算法最早用于文档的自动摘要,基于句子维度的分析,利用算法对每个句子进行打分,挑选出分数最高的n个句子作为文档的关键句,以达到自动摘要的效果。
TextRank算法的基本思想来源于Google的PageRank算法,该算法是Google创始人拉里·佩奇和希尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析法,用于评价搜索系统各覆盖网页重要性的一种方法。随着Google的成功,该算法也称为其它搜索引擎和学术界十分关注的计算模型。
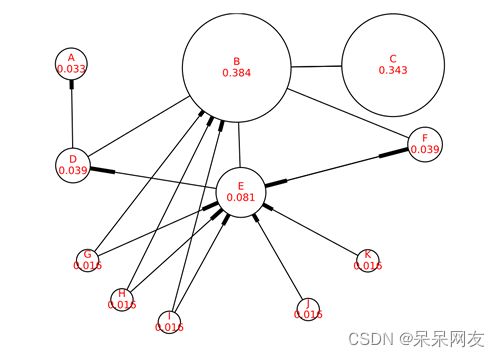
PageRank基本思想有两条:
- 链接数量。一个网页被越多的其它网页链接,说明这个网页越重要
- 链接质量。一个网页被一个越高权值的网页链接,也能表名这个网页越重要
基于上述思想,一个网页的PageRank计算公式可以表示为:
S ( V i ) = ∑ j ∈ I n ( V i ) ( 1 O u t ( V j ) × S ( V j ) ) S(V_i) = \sum_{j \in In(V_i)} \Bigg( \frac{1}{Out(V_j)} \times S(V_j) \Bigg) S(Vi)=j∈In(Vi)∑(Out(Vj)1×S(Vj))
其中, I n ( V i ) In(V_i) In(Vi)为 V i V_i Vi的入链集合, O u t ( V j ) Out(V_j) Out(Vj)为 V j V_j Vj的出链集合, ∣ O u t ( V j ) ∣ |Out(V_j)| ∣Out(Vj)∣为出链的数量。因为每个网页要将它自身的分数平均贡献给每个出链,则 ( 1 O u t ( V j ) × S ( V j ) ) \Bigg( \frac{1}{Out(V_j)} \times S(V_j) \Bigg) (Out(Vj)1×S(Vj))即为 V i V_i Vi贡献给 V j V_j Vj的分数。将所有入链贡献给它的分数全部加起来,就是 V i V_i Vi自身的得分。算法开始时,将所有页面的得分均初始化为1。
对于一些孤立页面,可能链入、链出的页面数量为0,为了避免这种情况,对公式进行了改造,加入了一个阻尼系数 d d d,这样,即使孤立页面也有一个得分。改造后的公式如下:
S ( V i ) = ( 1 − d ) + d × ∑ j ∈ I n ( V i ) ( 1 O u t ( V j ) × S ( V j ) ) S(V_i) = (1 - d) + d \times \sum_{j \in In(V_i)} \Bigg( \frac{1}{Out(V_j)} \times S(V_j) \Bigg) S(Vi)=(1−d)+d×j∈In(Vi)∑(Out(Vj)1×S(Vj))
以上就是PageRank的理论,也是TextRank的理论基础,不同于的是TextRank不需要与文档中的所有词进行链接,而是采用一个窗口大小,在窗口中的词互相都有链接关系。例如对下面的文本进行窗口划分:
世界献血日,学校团体、献血服务志愿者等可到血液中心参观检验加工过程,我们会对检验结果进行公示,同时血液的价格也将进行公示。
如果将窗口大小设置为5,则可得到如下计算窗口:
[世界,献血,日,学校,团体]
[献血,日,学校,团体,献血]
[日,学校,团体,献血,服务]
[学校,团体,献血,服务,志愿者]
……
每个窗口内所有词之间都有链接关系,如[世界]和[献血,日,学校,团体]之间有链接关系。得到了链接关系,就可以套用TextRank公式,计算每个词的得分,最后选择得分最高的N个词作为文档的关键词。
3)关键词提取示例
本案例演示了通过自定义TF-IDF、调用TextRank API实现关键字提取
# -*- coding: utf-8 -*-
import math
import jieba
import jieba.posseg as psg
from gensim import corpora, models
from jieba import analyse
import functools
import numpy as np
# 停用词表加载方法
def get_stopword_list():
# 停用词表存储路径,每一行为一个词,按行读取进行加载
# 进行编码转换确保匹配准确率
stop_word_path = '../data/stopword.txt'
with open(stop_word_path, "r", encoding="utf-8") as f:
lines = f.readlines()
stopword_list = [sw.replace('\n', '') for sw in lines]
return stopword_list
# 去除停用词
def word_filter(seg_list):
filter_list = []
for word in seg_list:
# 过滤停用词表中的词,以及长度为<2的词
if not word in stopword_list and len(word) > 1:
filter_list.append(word)
return filter_list
# 数据加载,pos为是否词性标注的参数,corpus_path为数据集路径
def load_data(corpus_path):
# 调用上面方式对数据集进行处理,处理后的每条数据仅保留非干扰词
doc_list = []
for line in open(corpus_path, 'r', encoding='utf-8'): # 循环读取一行(一行即一个文档)
content = line.strip() # 去空格
seg_list = jieba.cut(content) # 分词
filter_list = word_filter(seg_list) # 去除停用词
doc_list.append(filter_list) # 将分词后的内容添加到列表
return doc_list
# idf值统计方法
def train_idf(doc_list):
idf_dic = {}
tt_count = len(doc_list) # 总文档数
# 每个词出现的文档数
for doc in doc_list:
doc_set = set(doc) # 将词推入集合去重
for word in doc_set: # 词语在文档中
idf_dic[word] = idf_dic.get(word, 0.0) + 1.0 # 文档数加1
# 按公式转换为idf值,分母加1进行平滑处理
for word, doc_cnt in idf_dic.items():
idf_dic[word] = math.log(tt_count / (1.0 + doc_cnt))
# 对于没有在字典中的词,默认其仅在一个文档出现,得到默认idf值
default_idf = math.log(tt_count / (1.0))
return idf_dic, default_idf
# TF-IDF类
class TfIdf(object):
def __init__(self, idf_dic, default_idf, word_list, keyword_num):
"""
TfIdf类构造方法
:param idf_dic: 训练好的idf字典
:param default_idf: 默认idf值
:param word_list: 待提取文本
:param keyword_num: 关键词数量
"""
self.word_list = word_list
self.idf_dic, self.default_idf = idf_dic, default_idf # 逆文档频率
self.tf_dic = self.get_tf_dic() # 词频
self.keyword_num = keyword_num
# 统计tf值
def get_tf_dic(self):
tf_dic = {} # 词频字典
for word in self.word_list:
tf_dic[word] = tf_dic.get(word, 0.0) + 1.0
total = len(self.word_list) # 词语总数
for word, word_cnt in tf_dic.items():
tf_dic[word] = float(word_cnt) / total
return tf_dic
# 按公式计算tf-idf
def get_tfidf(self):
tfidf_dic = {}
for word in self.word_list:
idf = self.idf_dic.get(word, self.default_idf)
tf = self.tf_dic.get(word, 0)
tfidf = tf * idf # 计算TF-IDF
tfidf_dic[word] = tfidf
# 根据tf-idf排序,去排名前keyword_num的词作为关键词
s_list = sorted(tfidf_dic.items(), key=lambda x: x[1], reverse=True)
# print(s_list)
top_list = s_list[:self.keyword_num] # 切出前N个
for k, v in top_list:
print(k + ", ", end='')
print()
def tfidf_extract(word_list, keyword_num=20):
doc_list = load_data('../data/corpus.txt') # 读取文件内容
# print(doc_list)
idf_dic, default_idf = train_idf(doc_list) # 计算逆文档频率
tfidf_model = TfIdf(idf_dic, default_idf, word_list, keyword_num)
tfidf_model.get_tfidf()
def textrank_extract(text, keyword_num=20):
keywords = analyse.textrank(text, keyword_num)
# 输出抽取出的关键词
for keyword in keywords:
print(keyword + ", ", end='')
print()
if __name__ == '__main__':
global stopword_list
text = """在中国共产党百年华诞的重要时刻,在“两个一百年”奋斗目标历史交汇关键节点,
党的十九届六中全会的召开具有重大历史意义。全会审议通过的《决议》全面系统总结了党的百年奋斗
重大成就和历史经验,特别是着重阐释了党的十八大以来党和国家事业取得的历史性成就、发生的历史性变革,
充分彰显了中国共产党的历史自觉与历史自信。"""
stopword_list = get_stopword_list()
seg_list = jieba.cut(text) # 分词
filter_list = word_filter(seg_list)
# TF-IDF提取关键词
print('TF-IDF模型结果:')
tfidf_extract(filter_list)
# TextRank提取关键词
print('TextRank模型结果:')
textrank_extract(text)
执行结果:
TF-IDF模型结果:
历史, 中国共产党, 百年, 历史性, 华诞, 一百年, 奋斗目标, 交汇, 节点, 十九, 六中全会, 全会, 奋斗, 重大成就, 着重, 阐释, 十八, 党和国家, 成就, 变革,
TextRank模型结果:
历史, 历史性, 意义, 成就, 决议, 审议, 发生, 系统, 总结, 全面, 节点, 关键, 交汇, 召开, 具有, 全会, 取得, 事业, 自信, 变革,