CS231n-2022 Module1: 神经网络概要1:Setting Up the Architecture
目录
1. 前言
2. Quick intro
3. Modeling one neuron
3.1 神经元基本模型
3.2 Single neuron as a linear classifier
3.2.1 Binary Softmax classifier
3.2.2 Binary SVM classifier
3.2.3 Regularization interpretation
3.3 Commonly used activation functions
3.3.1 sigmoid
3.3.2 tanh
3.3.3 ReLU
3.3.4 Leaky ReLU
3.3.5 Maxout
3.3.6 TLDR:要点总结,扼要概述
4. Neural Network architectures
4.1 Layer-wise organization
4.2 Example feed-forward computation
4.3 Representational power
4.4 Setting number of layers and their sizes
5. Summary
1. 前言
本文编译自斯坦福大学的CS231n课程(2022) Module1课程中神经网络部分之一,参见:CS231n Convolutional Neural Networks for Visual Recognition https://cs231n.github.io/neural-networks-1/
https://cs231n.github.io/neural-networks-1/
本文(本系列)不是对原始课件网页内容的完全翻译,只是作为学习笔记的要点总结式的搬运,主要是自我参考。如果恰巧也对小伙伴们有所参考则纯属无心插柳^-^。
2. Quick intro
此前讨论过的线性分类器![]() 可以看作是单层神经网络。
可以看作是单层神经网络。
一个两层神经网络可以写成![]() 。
。
一个三层神经网络可以写成![]() ,更多层数的神经网络则依此类推。
,更多层数的神经网络则依此类推。
其中,W表示权重参数矩阵,x表示输入向量。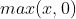 函数的目的是提供非线性,通常称为激励函数。如果没有这个非线性处理的话,则各层权重参数矩阵可以合并成为一个权重参数矩阵,相当于坍缩为一个单层神经网络(即线性分类器)了。函数不是唯一的能够提供非线性的激励函数,但是的确是最常用的一种,它在深度学习领域有一个正式的名称叫ReLU(Rectified Linear Unit)。
函数的目的是提供非线性,通常称为激励函数。如果没有这个非线性处理的话,则各层权重参数矩阵可以合并成为一个权重参数矩阵,相当于坍缩为一个单层神经网络(即线性分类器)了。函数不是唯一的能够提供非线性的激励函数,但是的确是最常用的一种,它在深度学习领域有一个正式的名称叫ReLU(Rectified Linear Unit)。
3. Modeling one neuron
3.1 神经元基本模型

左图:生物神经元模型;右图:数学模型
单个神经元的数学模型可以写成: ![]()
其中,函数 为非线性函数,通常被称为激励函数(activation function).
为非线性函数,通常被称为激励函数(activation function).
以常见的sigmoid函数作为激励函数例,如上所示的神经元的python代码实现例如下所示:
class Neuron(object):
# ...
def forward(self, inputs):
""" assume inputs and weights are 1-D numpy arrays and bias is a number """
cell_body_sum = np.sum(inputs * self.weights) + self.bias
firing_rate = 1.0 / (1.0 + math.exp(-cell_body_sum)) # sigmoid activation function
return firing_rate3.2 Single neuron as a linear classifier
对以上所示的单个神经元模型可以用作线性分类器。采用不同的损失函数对神经元输出(即sigmoid激励函数输出)进行处理可以得到不同的线性分类器。
3.2.1 Binary Softmax classifier
我们可以将![]() 理解为判定为其中一类的概率
理解为判定为其中一类的概率![]() ,相应地判定为另一类的概率即为:
,相应地判定为另一类的概率即为:![]() 。基于这一解释,我们就可以给出交叉熵损失(cross entropy loss)函数(其中
。基于这一解释,我们就可以给出交叉熵损失(cross entropy loss)函数(其中![]() 表示Indicator函数):
表示Indicator函数):
![]()
对交叉熵损失函数进行最优化就可以得到Binary Softmax Classifier(也称为logistic regression,不要被这个regression骗了,逻辑斯蒂回归实际上是指分类!)。由于sigmoid函数的值域为[0,1],所以分类器的输出(prediction)判决很简单,就看sigmoid函数输出是否大于0.5。
3.2.2 Binary SVM classifier
同样,如果采用max-margin hinge loss的话,则将得到一个SVM二分类器。
3.2.3 Regularization interpretation
从生物学的观点来看,在以上SVM/Softmax分类器中,正则化损失(regularization loss)可以理解为逐渐遗忘(gradual forgetting),因为它具有将权重参数向0的方向压缩的效果。
Summary:
A single neuron can be used to implement a binary classifier (e.g. binary Softmax or binary SVM classifiers)。一个二分类线性分类器可以用单一一个神经元实现。
3.3 Commonly used activation functions
提供非线性效应的激励函数在深度神经网络中起着不可或缺的作用。没有激励函数提供非线性效应,多层神经网络可以压缩为等价的单层神经网络,多层也就失去了意义,无法获得深度学习的能力。
常见的激励函数有如下一些:

左:Sigmoid;右:Tanh ;注意,两者的值域略有区别,前者是[0,1];后者是[-1,1]
3.3.1 sigmoid
![]()
由于sigmoid函数的值域范围恰好为[0,1],使得它的输出非常适合于用作概率性解释,所以在历史上曾经被广泛使用。但是,现在它已经基本上销声匿迹了。Sigmoid的主要缺陷是在sigmoid曲线的两端尾巴区域梯度非常小,很容导致在反向传播(back propagation)中有效信息的传播被抑制或甚至彻底打断。此外,Sigmoid曲线不是零对称(zero-centered)的,稍微有一点点不良影响。
3.3.2 tanh
tanh实际上可以有sigmoid变换而得:![]() .
.
tanh和sigmoid一样,也是在两端尾巴区域梯度非常小,但是它的值域是对称的。所以,通常来说,tanh比sigmoid更有实用价值。
3.3.3 ReLU
![]()
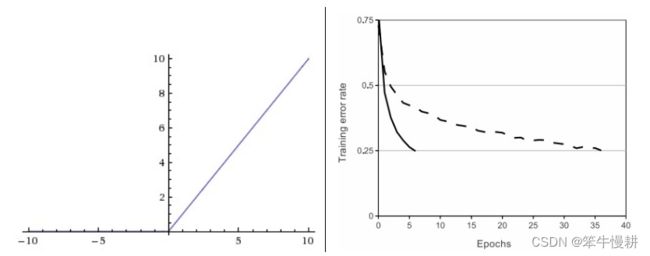 左:ReLU函数;右:ReLU所带来的收敛速度提升(6x! from Krizhevsky et al paper)示意图
左:ReLU函数;右:ReLU所带来的收敛速度提升(6x! from Krizhevsky et al paper)示意图
近年来ReLU变得非常流行,几乎可以看作是缺省的第一选项。
ReLU pros:(1)收敛速度非常快--参见上图右;(2)运算非常简单,仅仅是一个max! 与之相比,sigmoid和tanh涉及到指数运算,运算复杂度要远远大得多
ReLU cons: Unfortunately, ReLU units can be fragile during training and can “die”. ReLU在训练中可能会比较脆弱而且可能彻底“死”掉。For example, a large gradient flowing through a ReLU neuron could cause the weights to update in such a way that the neuron will never activate on any datapoint again. If this happens, then the gradient flowing through the unit will forever be zero from that point on. That is, the ReLU units can irreversibly die during training since they can get knocked off the data manifold(没看懂。。。^-^)。比如说,当学习率设置比较高时,你可能会发现高达40%的神经元节点都“死”掉了。通过适当地设置学习率可以缓解这一问题.
3.3.4 Leaky ReLU
为了解决ReLU容易“死”掉的问题,对ReLU的x<0的区间做一些调整,如下所示:
![]()
其中![]() 表示Indicator function,
表示Indicator function,  是一个比较小的常数。这样,在x<0的区间,输出不是0而是斜率为的斜线。遗憾的是,虽然有人报告用这种方法取得了较好的效果,但是并没有普遍性。因此这种激励函数的普遍的有效性仍然存疑。
是一个比较小的常数。这样,在x<0的区间,输出不是0而是斜率为的斜线。遗憾的是,虽然有人报告用这种方法取得了较好的效果,但是并没有普遍性。因此这种激励函数的普遍的有效性仍然存疑。
3.3.5 Maxout
除了以上以f(wTx+b)的函数形式体现的非线性激励函数,也有人建议其它形式的激励函数,其中一种比较流行的是由Goodfellow提出的名为Maxout的激励函数,它是对ReLU和Leaky ReLU的推广,其数学表达式如下所示:
![]()
ReLU和Leaky ReLU都是它的特殊形式,它保持了ReLU的有点,但是回避了ReLU容易“死”的缺点。当然这些优点是有代价的,这个代价就是它的参数个数直接翻倍了。
3.3.6 TLDR:要点总结,扼要概述
“What neuron type should I use?” Use the ReLU non-linearity, be careful with your learning rates and possibly monitor the fraction of “dead” units in a network. If this concerns you, give Leaky ReLU or Maxout a try. Never use sigmoid. Try tanh, but expect it to work worse than ReLU/Maxout.
使用ReLU几乎总是不错的选择,需要留意学习率的选择,以及神经网络中“死亡”节点的比率。如果“死亡”节点比率让你感到担忧,可以试一试Leaky ReLU或者Maxout。永远不要使用Sigmoid。Tanh可以试一试,但是一般来说它的表现不会比ReLU/Maxout好。
4. Neural Network architectures
4.1 Layer-wise organization
神经网络模型可以看作是有神经元节点构成的无环图(acyclic graph),并且通常以分层的形式表示。其中最基本最常见的是所谓的全连接层( fully-connected lashiyer):分属相邻两层的每一对节点都相连,而层内的节点则相互不连接。 示例如下:

左:2层神经网络;右:3层神经网络
Naming conventions. 约定俗成的命名规范
当我们谈论网络的层数,通常不把输入层计算进去(如上图所示),仅计入隐藏层和输出层。所以一个单层网络是指没有隐藏层,输入直接映射为输出。所以,也能听到人们会说logistic regression or SVMs 是特殊形式的单层神经网络。有人喜欢用“Artificial Neural Networks” (ANN) or “Multi-Layer Perceptrons” (MLP)来指称神经网络。很多人不喜欢神经网络与大脑之间的类比,所以他们会用units来替代neurons。
Output layer. 输出层
与隐藏层不同,输出层的节点通常不带激励函数,或者你可以认为它们是具有单位激励函数(linear identity activation function). This is because the last output layer is usually taken to represent the class scores (e.g. in classification), which are arbitrary real-valued numbers, or some kind of real-valued target (e.g. in regression).
Sizing neural networks.神经网络大小的衡量
人们通常用来衡量神经网络大小的参量有两个:神经元或者说节点个数;参数的个数。
如上图所示,左图所示模型有6个神经元节点(同样,不计入输入层),[3 x 4] + [4 x 2] = 20个权重weights参数以及 4 + 2 = 6 个biases参数,因此总共有26个可学习参数( learnable parameters)。
同样,右图所示3层神经网络有9个神经元, [3 x 4] + [4 x 4] + [4 x 1] = 12 + 16 + 4 = 32 weights and 4 + 4 + 1 = 9 biases, for a total of 41 learnable parameters。
现代卷积神经网络通常由十几层到甚至上百层(名副其实的深度学习!),可能会有上亿的可学习参数。
4.2 Example feed-forward computation
神经网络采取基于层的结构的一个主要原因在于它的计算可以基于矩阵运算以非常简洁又没的方式实现。上图所示的3层网络的feed-forward计算的示例代码如下所示:
# forward-pass of a 3-layer neural network:
f = lambda x: 1.0/(1.0 + np.exp(-x)) # activation function (use sigmoid)
x = np.random.randn(3, 1) # random input vector of three numbers (3x1)
h1 = f(np.dot(W1, x) + b1) # calculate first hidden layer activations (4x1)
h2 = f(np.dot(W2, h1) + b2) # calculate second hidden layer activations (4x1)
out = np.dot(W3, h2) + b3 # output neuron (1x1)
其中, W1[4x3],W2[4x4],W3[1x4],b1[4x1],b2[4x1],b3[1x1] 是神经网络的可学习参数,分别用对应维度的矩阵或者向量表示。其中Wx的维度是[终点层size, 起点层size](指各权重参数所对应的edge的终点层和起点层)而bx的维度是[终点层size,1]。这样,整个3层神经网络的前向计算仅仅是三个简单的矩阵乘法运算,中间再嵌入激励函数的作用而已。
值得注意的是,输入数据x不仅仅是可以代表一个样本数据的列向量,而且可以是代表一整个数据集的矩阵,其中每一列代表一个样本数据。即便x由1个数据样本扩张为整个数据集,以上运算表达式却并不需要修改,这正式矩阵运算的优美之所在。此外,在machine learning community,更常见的是用一个矩阵代表一个数据集,每一行代表一个样本数据。这样的话需要将以上运算整体上做一个转置。
另外,通常来说,最终输出层不需要激励函数。最终输出是一个实数值,在不同应用场景有其不同的物理含义。比如说在分类器中代表对应各类的class score。
The forward pass of a fully-connected layer corresponds to one matrix multiplication followed by a bias offset and an activation function.
4.3 Representational power
看待神经网络的一种观点是把它看作是定义了一个参数化的函数族,一个自然的问题是:神经网络的表现能力如何?有没有什么函数是无法用神经网络来近似建模的?
结论有点反直觉和惊人:至少拥有一个隐藏层的神经网络是 universal approximators(通用近似函数)。 也就是说, (e.g. see Approximation by Superpositions of Sigmoidal Function from 1989 (pdf), or this intuitive explanation from Michael Nielsen)给定任意的连续函数 和任意小数
和任意小数 ,存在这样的具有至少一个隐藏层的神经网络(表示为
,存在这样的具有至少一个隐藏层的神经网络(表示为 ),使得
),使得![]() 能够成立。换言之,神经网络能够近似任意函数。
能够成立。换言之,神经网络能够近似任意函数。
如果一个隐藏层就足以近似任意函数的话,那为什么实际应用中的神经网络通常都用很多很多层呢?答案是,拥有更多隐藏层的深度网络通过工作得比只有一层隐藏层的深度网络要工作得更好,这是一个经验性事实(empirical observation),虽然它们的理论上的表现能力是相同的。
顺便提一下,对于全连接神经网络(FNN, or DNN),虽然3层神经网络通常要远远好于2层神经网络,但是层数进一步增大时,好处变得越来越小,或者说层数增大带来的边际效应越来越小。与之相对的是,对于CNN(卷积神经网络)来说,十几层甚至数十层是很常见的。
4.4 神经网络是大一些好呢还是小一些好?
如前所述,神经网络越大它们的信息容量(capacity)越大,表现能力(representational power)越强。但是,神经网络太大(相对于训练数据集的大小而言)的话,容易发生过拟合(overfitting),导致其泛化(generalization)能力变低。
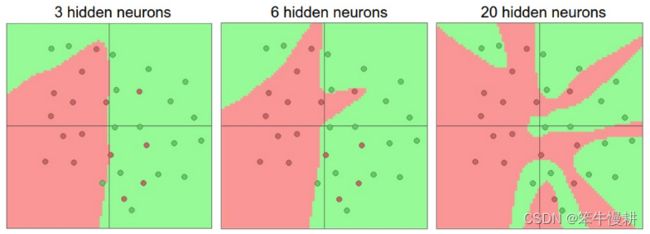
上图左、中、右分别是针对同一个数据集三个不同大小(分别具有3个、6个和20个隐藏节点)的神经网络的分类效果图。左图的分类决策边界最平滑,但是存在一些误判;中图的分类决策边界开始变得不规则,挽救一个错判;右图虽然正确地对所有样本都进行了正确分类,但是其分类决策边界已经极度扭曲,其代价将是极差得泛化能力,即面对新的样本几乎难以做出正确的分类决策。在极端情况下,当神经网络足够大(相对于数据集而言)神经网络能够“记住”每个训练样本的标签,因而可以在训练集上获得100%的准确率,而并不需要去真正地学习数据集的内在特征(underlaying characteristics),但是这样得到的模型显然没有什么使用意义。就好比一个学生具有超凡的记忆力和几近于零的理解能力,他能把他看到过的试卷的所有的题目的答案都精确地背下来,但是他去参加真正的考试,只要考试题没有出现他背下来的题目,他将毫无疑问将会考得一塌糊涂。
那是不是在只有较小的数据集的情况下,应该选择较小的神经网络呢?
并不是。
有很多技术可以用来防止过拟合,比如说,L2 regularization, dropout, input noise等等。下图所示为同样使用20个隐层神经元但是采用不同正则化强度时针对以上同样数据集时的分类表现,随着正则化强大增大,决策边界逐渐变得更加平滑,因而具有更好的泛化能力:
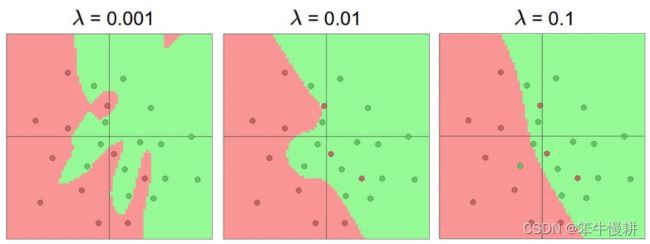
但是,仅此还不足以构成要选择大的神经网络而不选择小的神经网络的充分的理由。更加决定性的理由是:神经网络越小其性能的方差越大。换句话说,同样一个神经网络,针对同一数据集但是在不同随机初始条件下,重复训练多次,每次得到的性能的差异会很大。所以,规模较小的神经网络的训练就有点像轮盘赌一样,运气好可能得到很好的结果,运气不好可能得到很差的结果。而规模越大的神经网络,这个不同训练之间的性能的方差就越小,不必太担心运气的问题。
The takeaway is that you should not be using smaller networks because you are afraid of overfitting. Instead, you should use as big of a neural network as your computational budget allows, and use other regularization techniques to control overfitting.
要点是:不要因为容易过拟合而回避使用大的神经网络。尽量使用大的神经网络,然后采用正则化技术来控制过拟合!
5. Summary
本章中介绍了:
- 神经网络节点(神经元)的基本数学模型.
- 几种典型的激励函数,以及激励函数选择的基本原则。绝大多数情况选用ReLU即可
- 神经网络的层级结构以及全连接层
- 层级结构使得神经网络的运算可以很简洁优美地基于矩阵运算实现
- 神经网络的表现力。神经网络是所谓的universal function approximators(通用近似函数)。 当然神经网络的广泛使用与它们的这一性质并没有多大的关系。They are used because they make certain “right” assumptions about the functional forms of functions that come up in practice.
- 神经网络的表现能力通常与它们的大小相关联。但是大有大的难处和问题。比如说,神经网络越大可能越难训练,越容易出现过拟合等等。但是,尽量使用大的神经网络,然后采用正则化技术来控制过拟合。
Next:CS231n-2022 Module1: 神经网络概要2--Setting up the data and the loss