Rust实战系列-复合数据类型

本文是《Rust in action》学习总结系列的第三部分,更多内容请看已发布文章:
一、Rust实战系列-Rust介绍
二、Rust实战系列-基本语法
“
主要介绍复合数据类型,包括结构体、枚举,以及为类型添加函数,以类型安全的方式处理错误,使用特征(trait)定义并实现通用函数。
1. 通过普通函数实验 API
先看看使用已经学习的知识能够做些什么。以下示例代码列出了一些希望实现的函数,例如,打开、关闭文件。使用 String 的类型别名来模拟文件,包括文件名和其他内容。
为了简化,使用了属性( #![] 表示的内容 )来让编译器跳过部分检查,read 函数展示了如何定义没有返回值( -> ! )的函数。
#![allow(unused_variables)]// <1>
type File = String; // <2>
fn open(f: &mut File) -> bool {
true// <3>
}
fn close(f: &mut File) -> bool {
true// <3>
}
#[allow(dead_code)]// <4>
fn read(f: &mut File, save_to: &mutVec) -> ! { // <5>
unimplemented!() // <6>
}
fn main() {
letmut f1 = File::from("f1.txt"); // <7>
open(&mut f1);
//read(f1, vec![]); // <8>
close(&mut f1);
}
-
告诉编译器允许出现未使用的变量
-
创建类型别名,编译器不会区分 String 和 File,在源代码中会区分
-
暂时假设这两个函数总是执行成功
-
告诉编译器允许出现未使用的函数
-
使用 ! 告诉编译器函数无返回值,! 是 Rust 中特殊返回类型的一种,称为“Never”类型
-
如果遇到这个宏,程序会崩溃
-
由于 File 是 String 的类型别名,因此 “继承” 了 String 的所有方法
-
调用这个函数没有任何意义(程序会崩溃)
在示例代码中,这些新的内容需要理解:
(1) 还没有创建代表文件的持久化对象(字符串中可以编码的内容是有限的)
(2)没有实现 read() 函数(如果实现,如何处理失败的情况?)
(3)open() 和 close() 函数返回值为 bool 类型,也许可以返回更复杂的类型,包括错误信息(如果操作系统返回错误信息)
(4)函数都不是方法,从代码风格来看,调用 f.open() 而不是 open(f) 可能更好
接下来,将会基于这份代码一步步完善。
“
Rust 中的特殊返回类型:
如果刚接触,有些类型是难以理解的,因为这些类型是符号而不是文字。
(1)() :称为 “单元类型”,形式上是一个长度为 0 的元组,用来表达函数没有返回值。没有返回类型的函数返回 (),以分号( ; )结尾的表达式返回 ()。
隐式(不指定函数返回类型)地返回单元类型:
use std::fmt::Debug;
fn report(item: T) { // <1>
println!("{:?}", item); // <2>
}
-
item 可以是任意实现了 std::fmt::Debug 的类型
-
{:?} 语法使得 println! 宏使用 std::fmt::Debug 特征将 item 转换为可以打印的字符串
显示(函数返回类型为 () )地返回单元类型:
fn clear(text: &mutString) -> () {
*text = String::from(""); // <1>
}
- 使用空字符串替换 text 指向的值
“
(2)! :称为 “永不类型”,用来表示一个函数永远不会返回。
如果函数一定会崩溃,则永远不会返回:
fn dead_end() -> ! {
panic!("you have reached a dead end"); // <1>
}
- panic! 宏导致程序崩溃,函数永远不会返回。
使用死循环,函数永远不会返回:
fn forever() -> ! {
loop { // <1>
//...
};
}
- 除非包含 break 语句,否则函数永远不会返回
“
和“单元类型”一样,“永不类型”有时也会出现在错误提示中。如果函数声明的返回不是“永不类型”,但是在 loop 中没有 break 语句,Rust 编译器会提示类型不匹配。
2. 使用 struct 建立文件模型
如何表示想要建模的 File 呢?struct 允许创建由其他类型组成的复合类型,和其他编程语言类似。规定 File 包括文件名和数据内容。
接下来的示例代码会打印 File 信息,使用 Vec[u8] 代表数据内容,长度可自动增加,main() 函数显示了如何使用文件结构,例如,访问内容。
#[derive(Debug)]// <1>
struct File {
name: String,
data: Vec, // <2>
}
fn main() {
let f1 = File {
name: String::from("f1.txt"), // <3>
data: Vec::new(), // <3>
};
let f1_name = &f1.name; // <4>
let f1_length = &f1.data.len(); // <5>
println!("{:?}", f1);
println!("{} is {} bytes long", f1_name, f1_length);
}
-
允许 println! 宏打印 File,std::fmt::Debug 特征与宏中的 {:?} 一起工作,将 File 表示为可以打印的字符串
-
使用 Vec可以动态调整长度,方便模拟文件写入的情况
-
String::from() 允许从字符串内容(即切片)生成自有字符串
-
使用 vec! 宏来模拟一个空文件
-
通过点运算符 . 访问字段,使用引用避免在移动( move,转移所有权)后使用的问题
函数执行结果:
![]()
示例代码的详细分析:
(1)第 1-5 行定义了 File 结构,包括字段和对应的类型,还包括每个字段的生命周期(示例中省略了),当某个字段是另一个对象时,需要明确生命周期。
(2)第 8-11 行使用基本语法创建了一个 File 的实例,通常情况下,可以通过更方便的函数来创建。String::from() 是其中一个方法,接受另一个类型的值(字符串切片 &str ),并返回 String 实例,Vec::new() 则更常见。
(3)第 13-17 行演示了如何访问实例的字段。在前面添加 & 符号表示希望通过引用来访问这些数据。用 Rust 的说法,变量 f1_name 和 f1_length 正在借用( borrow )被引用的数据。
你可能已经注意到,File 结构实际上没向磁盘存储任何内容。如果对底层的工作方式感兴趣,可以看下图。两个字段(name 和 data)本身是由结构体创建的,如果对指针( ptr )不熟悉,可以认为是某个事先不知道的内存地址。
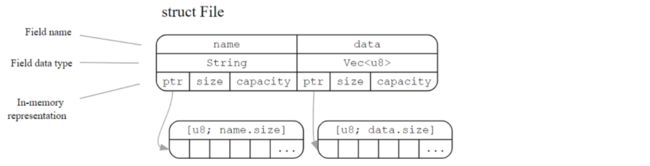
暂时没考虑和磁盘等持久化存储介质交互的过程。
“
newtype 模式:
有时,需要 type 关键词,当需要编译器将新的 type 作为独立的类型而不是别名时怎么办?使用 newtype。
newtype 模式将核心类型封装在单字段结构或元组中。
完善示例代码:
#[derive(PartialEq)]// <1>
struct Hostname(String); // <2>
fn main() {
let ordinary_string = String::from("localhost");
let host = Hostname ( ordinary_string.clone() );
if host == ordinary_string { // <3>
println!("huh?"); // <4>
};
}
-
PartialEq 使类型可以进行相等比较,称为 partial 是为了使某些类型能够描述相等无效的情况,例如浮点的“非数字”值
-
Hostname 是 newtype
-
这行不会编译,编译器认为 Hostname 和 String 是不同的类型
-
不会执行
编译输出:

接下来的示例实现读取文件内容的功能,假设函数总是执行成功,通过硬编码方式设置参数。
#![allow(unused_variables)]// <1>
#[derive(Debug)]// <2>
struct File {
name: String,
data: Vec,
}
“fn open(f: &mut File) -> bool { // <3>
true
}
fn close(f: &mut File) -> bool { // <3>
true
}
fn read(f: &File, save_to: &mutVec) -> usize { // <4>
letmut tmp = f.data.clone(); // <5>
let read_length = tmp.len();
save_to.reserve(read_length); // <6>
save_to.append(&mut tmp); // <7>
read_length
}
fn main() {
letmut f2 = File {
name: String::from("2.txt"),
data: vec![114, 117, 115, 116, 33],
};
letmut buffer: Vec = vec![];
open(&mut f2); // <8>
let f2_length = read(&f2, &mut buffer); // <8>
close(&mut f2); // <8>
let text = String::from_utf8_lossy(&buffer); // <9>
println!("{:?}", f2);
println!("{} is {} bytes long", &f2.name, f2_length);
println!("{}", text) // <10>
}
-
避免因 open() 和 close() 传入参数没被使用而出现警告
-
这使 File 能够与 println! 和同级别宏 fmt! 一起工作(在 main 中使用)
-
先不考虑这两个函数,只是假设执行成功
-
返回 读取的字节数
-
复制一份数据,save_to.append() 会缩小输入的 Vec
-
严格来说不是必须的,但了解一下很有用。用于确保有足够的空间存储输入的数据,并在按 字节 插入时尽量减少内存分配次数
-
在 save_to 缓冲区分配足够的空间来存储文件 f 的内容
-
读取文件的步骤
-
将 Vec转换为 String 类型,无效的 UTF-8 字节会被替换为 �
-
将内容 114、117、115、116 和 33 (ASCII 码[1])显示为单词
程序输出:
![]()
到目前为止,已经解决了两个问题:
“
(1) 没有创建代表文件的持久化对象 ✓
(2)没有实现 read() 函数 ✓
3. 通过 impl 为结构体添加方法
“方法” 是与某个对象耦合的函数。从语法的角度来看,只是不需要指定其中一个参数的函数。与调用 open() 并将一个 File 对象作为参数传入( read(f, buffer) )相比,方法允许对象使用点运算符 . 在函数调用 ( f.read(buffer) ) 时隐式传入对象参数。
Rust 与其他支持方法的编程语言不同:没有 class 关键字。用 struct 和 enum 创建的类型,在某些时候类似 class,但它们不支持继承,不使用 class 关键字是合理的。
Rust 使用 impl 代码块定义方法,和 struct (以及 enum)代码块是分开的,这和大多数面向对象语言在语法上存在差异。下图是比较:

- 实现 new() 方法简化对象创建操作
创建具有合理默认值的对象通过 new() 方法实现。每个 struct 都可以通过基本语法(指定每个字段的值)进行实例化,这很适合入门,但会导致代码冗长。
使用 new() 方法是 Rust 社区的一个惯例,与其他语言不同,new 不是一个关键字,也没有优先级。
两种创建对象方法的比较:

为了实现,需要完成 impl 代码块,示例代码如下:
#[derive(Debug)]
struct File {
name: String,
data: Vec,
}
impl File {
fn new(name: &str) -> File { // <1>
File { // <2>
name: String::from(name), // <2>
data: Vec::new(), // <2>
}
}
}
fn main() {
let f3 = File::new("f3.txt");
let f3_name = &f3.name; // <3>
let f3_length = f3.data.len();
println!("{:?}", f3);
println!("{} is {} bytes long", f3_name, f3_length);
}
-
由于 File::new() 只是一个正常的函数,需要告诉 Rust 函数返回 File 类型
-
File::new() 只是封装了创建对象的语法
-
struct 中的字段默认是私有的,但可以在定义该结构的模块中访问
使用 impl 改进上面的示例代码:
#![allow(unused_variables)]
#[derive(Debug)]
struct File {
name: String,
data: Vec,
}
impl File {
fn new(name: &str) -> File {
File {
name: String::from(name),
data: Vec::new(),
}
}
fn new_with_data(name: &str, data: &Vec) -> File { // <1>
letmut f = File::new(name);
f.data = data.clone();
f
}
fn read(self: &File, save_to: &mutVec) -> usize { // <2>
letmut tmp = self.data.clone();
let read_length = tmp.len();
save_to.reserve(read_length);
save_to.append(&mut tmp);
read_length
}
}
fn open(f: &mut File) -> bool { // <3>
true
}
fn close(f: &mut File) -> bool { // <3>
true
}
fn main() {
let f3_data: Vec = vec![114, 117, 115, 116, 33]; // <4>
letmut f3 = File::new_with_data("2.txt", &f3_data);
letmut buffer: Vec = vec![];
open(&mut f3);
let f3_length = f3.read(&mut buffer); // <5>
close(&mut f3);
let text = String::from_utf8_lossy(&buffer);
println!("{:?}", f3);
println!("{} is {} bytes long", &f3.name, f3_length);
println!("{}", text);
}
-
这种方法处理我们想要模拟的文件中预先存在数据的情况
-
f 参数已被替换为 self
-
研究错误处理之前,这两个地方可以保持原样
-
需要提供明确的类型,因为 vec! 不能通过函数边界推断类型
-
调用 read 函数的方式已经发生变化
4. 返回错误
在本章开始的问题中,有两点和错误处理有关。
“
(2)没有实现 read() 函数(如果实现,如何处理失败的情况?)
(3)open() 和 close() 函数返回值为 bool 类型,也许可以返回更复杂的类型,包括错误信息(如果操作系统返回错误信息)
出现这些问题是因为计算机硬件是不可靠的,即使忽略硬件故障,磁盘也可能是满的(不能继续写入内容),或者操作系统会告知没有权限删除某个特定的文件。本小节讨论提示错误的不同方法,首先是其他编程语言中常见的方法,然后是 Rust 中常用的方法。
- 修改已知的全局变量
最简单的方法是检查全局变量的值,尽管这样很容易出错,在系统编程中也很常见。
C 语言习惯在系统调用返回后检查 errno 的值,例如,close() 系统调用关闭一个文件描述符(代表文件的整数,由操作系统分配),可能修改 errno 的值。
POSIX 标准中讨论 close[2]() 系统调用的内容包括这部分:
“
如果 close() 被一个需要捕捉的信号打断,应该返回 -1,errno 设置为 EINTR,fildes[文件描述符] 的状态未指定。
如果在 close() 过程中读取或写入文件系统内容发生了 I/O 错误,会返回 -1,errno 设置为 EIO;如果返回这个错误,fildes 的状态未指定。
将 errno 设置为 EIO 或 EINTR 意味着将其设置为内部常数,具体数值是任意的,由操作系统定义。检查全局变量的 Rust 版本示例代码:
staticmut ERROR: i32 = 0; // <1>
// ...
fn main() {
letmut f = File::new("something.txt");
read(f, buffer);
unsafe { // <2>
if ERROR != 0 { // <3>
panic!("An error has occurred while reading the file ")
}
}
close(f);
unsafe { // <2>
if ERROR != 0 { // <3>
panic!("An error has occurred while closing the file ")
}
}
}
-
static mut 说成“mutable static”,是一个具有“静态生命周期”的全局变量(换句话说,在整个程序的生命周期内都可用)
-
访问和修改 static mut 变量需要使用 unsafe 代码块,这是避开 Rust 自带安全检查的方式
-
检查 ERROR 的值,依赖于 0 表示没有错误的约定
以下是使用这种处理模式的示例,运行代码的步骤如下:
cargo new --vcs none globalerror
cd globalerror
cargo add [email protected]
修改 src/main.rs 的内容为以下代码。示例代码中使用了一些新的语法,最重要的应该是 unsafe 关键词,具体将在后面章节讨论。只需要把 unsafe 看作是一个警告信号,而不是不安全的行为,不安全意味着和 C 语言的安全水平相同。
有一些其它补充的知识:
(1)可变的全局变量用 static mut 表示
(2)按照惯例,Rust 中的全局变量使用 ALL CAPS(全部大写)
(3)Rust 还包括一个 const 关键字,用于表示那些可能永远不会改变的值
use rand::{random}; // <1>
staticmut ERROR: isize = 0; // <2>
struct File; // <3>
#[allow(unused_variables)]
fn read(f: &File, save_to: &mutVec) -> usize {
if random() && random() && random() { // <4>
unsafe {
ERROR = 1; // <5>
}
}
0// <6>
}
#[allow(unused_mut)]// <7>
fn main() {
letmut f = File;
letmut buffer = vec![];
read(&f, &mut buffer);
unsafe { // <8>
if ERROR != 0 {
panic!("An error has occurred!")
}
}
}
-
导入 rand create 到本地文件
-
初始化 ERROR 为 0
-
创建占用 0 字节的类型代表真实的结构体
-
该函数 1/8 的概率返回 true
-
将 ERROR 设置为 1,通知系统的其他部分发生了错误
-
read 函数始终返回 0 字节
-
为了和其他代码保持一致,保持缓冲区的可变性,尽管这里并没有用到
-
访问 static mut 变量是不安全的操作
运行程序:
cargo run
运行结果(没有任何输出):
![]()
“
const 和 let 的区别:
用 let 定义的变量是不能修改的,那为什么 Rust 还要包含 const 关键字呢?
const 创建了编译时的常量,而 let 的值是在运行时创建的。
在编译器层面,let 更多指的是别名,而不是不可变性。在编译器术语中,别名是指在同一时间对内存中的同一位置有多个引用。用 let 声明的值是共享的。而用 let mut 声明的值则保证是唯一的。
这种区别使得“内部可变性”这一明显矛盾的概念在 Rust 中得以存在。某些类型,如 Rc,对外是不可变的,但是在访问时仍然会修改内部的值,Rc 维护着对自己的引用计数。
以下是代码的流程图,包括错误处理:
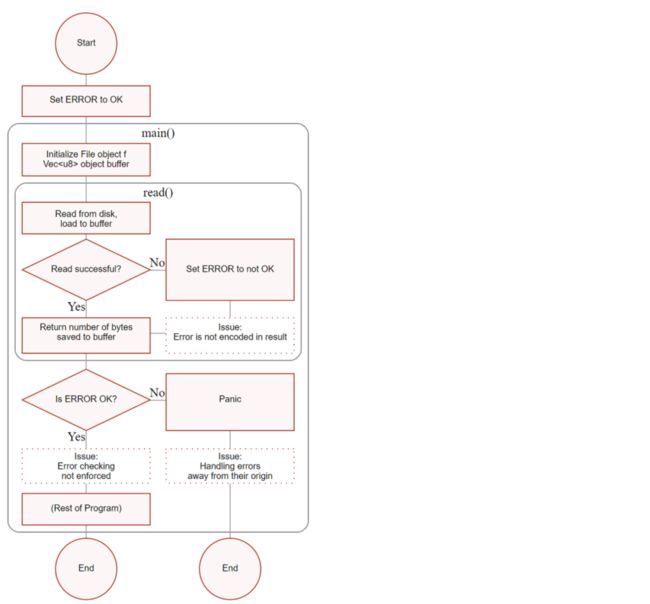
有经验的程序员知道,在系统调用过程中使用的全局变量 errno 通常会被操作系统修改。
这种编程风格在 Rust 中是不推荐的,因为不但省略了类型安全( errors 被编码为普通整数),而且当程序员忘记检查 errno 值时,会使得程序不稳定。然而,这也是一个重要的风格,因为:
(1)系统程序员可能需要与操作系统定义的全局值进行交互
(2)与 CPU 寄存器或其他低级硬件交互的软件需要习惯检查 errno 标志,以判断操作是否成功
- 使用 Result 返回类型
Rust 的错误处理方法是使用一个既能代表标准情况又能代表错误情况的类型,被称为 Result。Result 是通用的,有两种状态:Ok 和 Err,被应用在标准库中。
和前面的示例相比,以下示例代码有两个主要的变化:
(1)与文件系统交互的函数返回 Result
(2)当调用这些函数时,可以额外调用 unwrap() 函数,将 Ok(T) 展开得到 T
还有些额外变化对理解代码可能有帮助,但目前并不重要。open() 和 close() 现在对 File 参数有完整的所有权。虽然现在不需要深入解释,但它使文件参数能够被插入到 Ok(T) 中,因为 T 会被返回。与这个变化相关的是,变量 f4 现在被多次与函数调用的结果重新绑定。如果没有对 File 参数的所有权,会遇到使用了无效数据的问题。从某种意义上说,根据 open() 和 close() 的调用结果重新赋值,允许变量 f4 重新获得对 File 值的所有权。
运行代码的步骤:
cargo new --bin --vcs none fileresult
修改 Cargo.toml
[package]
name = "fileresult"
version = "0.1.0"
authors = ["Tim McNamara "]
edition = "2018"
[dependencies]
rand = "0.8"
修改 src/main.rs
use rand::prelude::*; // <1>
fn one_in(denominator: u32) -> bool { // <2>
thread_rng().gen_ratio(1, denominator) // <3>
}
#[derive(Debug)]
struct File {
name: String,
data: Vec,
}
impl File {
fn new(name: &str) -> File {
File { name: String::from(name), data: Vec::new() } // <4>
}
fn new_with_data(name: &str, data: &Vec) -> File {
letmut f = File::new(name);
f.data = data.clone();
f
}
fn read(self: &File, save_to: &mutVec) -> Result { // <5>
letmut tmp = self.data.clone();
let read_length = tmp.len();
save_to.reserve(read_length);
save_to.append(&mut tmp);
Ok(read_length) // <6>
}
}
fn open(f: File) -> Result {
if one_in(10_000) { // <7>
let err_msg = String::from("Permission denied");
returnErr(err_msg);
}
Ok(f)
}
fn close(f: File) -> Result {
if one_in(100_000) { // <8>
let err_msg = String::from("Interrupted by signal!");
returnErr(err_msg);
}
Ok(f)
}
fn main() {
let f4_data: Vec = vec![114, 117, 115, 116, 33];
letmut f4 = File::new_with_data("4.txt", &f4_data);
letmut buffer: Vec = vec![];
f4 = open(f4).unwrap(); // <9>
let f4_length = f4.read(&mut buffer).unwrap(); // <9>
f4 = close(f4).unwrap(); // <9>
let text = String::from_utf8_lossy(&buffer);
println!("{:?}", f4);
println!("{} is {} bytes long", &f4.name, f4_length);
println!("{}", text);
}
-
将 rand create 中的通用特征和类型导入本地文件(包括 thread_rng )
-
辅助函数,用于生成随机错误码
-
thread_rng() 创建了一个线程级的随机数生成器,其 gen_ratio(n, m) 方法返回概率为 n/m 的布尔值
-
风格的改变,缩短代码长度
-
Result
-
在这段代码中,虽然 read() 不会失败,仍然使用 Ok 包装 read_length,因为要返回 Result 类型
-
10000 次执行中返回 1 次错误
-
100000 次执行中返回 1 次错误
-
从 Ok 中展开得到 T
⚠️ 注意:在 Result 直接调用 .unwrap() 通常被认为是不好习惯,如果对 error 类型调用 .unwrap() 时,程序会崩溃,并且不会返回有用的错误信息。在后面的内容中,会遇到处理 error 的复杂机制。
使用 Result 提供了基于编译器的代码正确性检查:除非处理好边缘情况,否则代码不能编译通过。程序在运行期间只要出现 error 就会崩溃,这点已经明确。
什么是 Result 呢?Result 是 Rust 标准库定义的一个 enum 类型,和其他类型具有相同的地位,但通过社区约定和 Rust 语言的其他部分联系在一起。此时,你可能会问,什么是 enum 呢?
5. 定义和使用 enum(枚举类型)
enum(全称 enumeration )是可以代表多个已知变体的类型。通常,枚举被用来表示几个预先定义的已知选项,如扑克牌的花色或太阳系中的行星。
定义一个表示法国扑克牌花色的枚举类型:
enum Suit {
Clubs,
Spades,
Diamonds,
Hearts,
}
如果你还没使用过有枚举类型的编程语言,理解起来会有些困难。考虑创建一段用于解析日志的代码,每个日志事件都有一个名字,如“UPDATE”或“DELETE”,如果直接将这些值存储为字符串,当对字符串进行比较时,可能会出错。枚举类型使得开发者可以告诉编译器自定义事件代码,得到的警告信息类似这样:“你好,检测到已经考虑了 UPDATE 情况,但似乎忘记了 DELETE 情况,需要修复这个问题。”
以下示例代码展示了如何定义枚举类型并解析日志事件:
#[derive(Debug)]// <1>
enum Event {
Update, // <2>
Delete, // <2>
Unknown, // <2>
}
type Message = String; // <3>
fn parse_log(line: &'staticstr) -> (Event, Message) { // <4>
let parts: Vec<&str> = line.splitn(2, ' ').collect(); // <5>
if parts.len() == 1 { // <6>
return (Event::Unknown, String::from(line))
}
let event = parts[0]; // <7>
let rest = String::from(parts[1]); // <7>
match event {
"UPDATE" | "update" => (Event::Update, rest), // <8>
"DELETE" | "delete" => (Event::Delete, rest), // <8>
_ => (Event::Unknown, String::from(line)), // <9>
}
}
fn main() {
let log = "BEGIN Transaction XK342
UPDATE 234:LS/32231 {\"price\": 31.00} -> {\"price\": 40.00}
DELETE 342:LO/22111";
for line in log.lines() {
let parse_result = parse_log(line);
println!("{:?}", parse_result);
}
}
-
使此枚举可以通过自动生成的代码打印到屏幕
-
创建 Event 的三个变体,包括表示未识别事件(Unknown)的值
-
String 的别名,在当前 create 上下文中有效
-
用于解析行并转换为半结构化数据的函数
-
collect() 消耗一个迭代器(从 line.splitn()返回)并返回 Vec,line.splite(2, ’ ') 将 line 按空格分割,最多返回两个子字符串
-
如果 line.splitn() 没有将 log 分成两部分,则返回错误
-
将每部分内容赋值给一个变量,方便使用
-
匹配到已知事件(字符串)时,返回结构化数据
-
不能识别事件类型时,返回整行数据
使用枚举类型的小技巧:
(1)通常和 Rust 的 match 一起使用,构建健壮、可读的代码
(2)和 struct 一样,可以通过 impl 添加方法
(3)Rust 的枚举不只是一组常量,还可以在变量中包含数据,赋予类似 struct 的角色,以下是示例:
enum Suit {
Clubs,
Spades,
Diamonds,
Hearts, // <1>
}
enum Card {
King(Suit), // <2>
Queen(Suit), // <2>
Jack(Suit), // <2>
Ace(Suit), // <2>
Pip(Suit, usize), // <3>
}
-
最后一个元素也以逗号结尾,可以简化重构
-
脸牌(K,Q,J,A)有花色
-
点牌(1-10)有花色和等级
- 通过枚举类型管理内部状态
现在,已经知道如何定义和使用枚举类型,应用到模拟文件的案例中是非常有用的。接下来,扩展 File 类型,在被打开和关闭时改变状态。
#[derive(Debug,PartialEq)]
enum FileState {
Open,
Closed,
}
#[derive(Debug)]
struct File {
name: String,
data: Vec,
state: FileState,
}
impl File {
fn new(name: &str) -> File {
File { name: String::from(name), data: Vec::new(), state: FileState::Closed }
}
fn read(self: &File, save_to: &mutVec) -> Result {
ifself.state != FileState::Open {
returnErr(String::from("File must be open for reading"));
}
letmut tmp = self.data.clone();
let read_length = tmp.len();
save_to.reserve(read_length);
save_to.append(&mut tmp);
Ok(read_length)
}
}
fn open(mut f: File) -> Result {
f.state = FileState::Open;
Ok(f)
}
fn close(mut f: File) -> Result {
f.state = FileState::Closed;
Ok(f)
}
fn main() {
letmut f5 = File::new("5.txt");
letmut buffer: Vec = vec![];
if f5.read(&mut buffer).is_err() {
println!("Error checking is working");
}
f5 = open(f5).unwrap();
let f5_length = f5.read(&mut buffer).unwrap();
f5 = close(f5).unwrap();
let text = String::from_utf8_lossy(&buffer);
println!("{:?}", f5);
println!("{} is {} bytes long", &f5.name, f5_length);
println!("{}", text);
}
枚举类型能够保证软件的健壮性和可用性,如果需要使用字符串类型的数据(消息代码),可以考虑使用枚举类型。
6. 通过特征定义通用行为
“文件”的准确定义应该是与存储介质无关的,文件支持(至少)读写操作。专注于这两个功能使我们忽略实际发生读写操作的位置,可能是硬盘驱动器、内存缓存、网络或其他介质。
不管是“文件”是一个网络连接、机械硬盘,还是固态硬盘,都定义这样的规则:“如果将它们称为文件,就需要实现对应的功能。”
在前面的示例中,已经使用过特征,每次在函数定义时使用 #[derived (Debug)],就是为该类型实现了 Debug 特征。接下来,看看如何创建特征。
- 创建 Read 特征
“特征”使得编译器(和其他人)知道多个类型可能会执行相同的任务,使用 #[derive(Debug)] 的类型都能够通过 println! 宏(或具有相同功能的其它宏)被打印到控制台。允许多个类型实现“读”特性,可以实现代码的重用,并使 Rust 编译器在不带来额外开销的情况下实现抽象。
以下示例代码定义文件的 Read 特征,展示用于定义的 trait 关键字和将特征附加到特定类型的 impl 关键字之间的区别:
#![allow(unused_variables)]// <1>
#[derive(Debug)]
struct File; // <2>
trait Read { // <3>
fn read(self: &Self, save_to: &mutVec) -> Result; // <4>
}
impl Read for File {
fn read(self: &File, save_to: &mutVec) -> Result {
Ok(0) // <5>
}
}
fn main() {
let f = File{};
letmut buffer = vec!();
let n_bytes = f.read(&mut buffer).unwrap();
println!("{} byte(s) read from {:?}", n_bytes, f);
}
-
跳过函数中的“未使用变量”检查
-
定义 File 类型
-
为特征指定名称
-
特征代码块包括开发者实现函数必须遵循的类型签名(类似 C 语言的函数声明,规定函数参数和返回值的类型),伪类型 self 是最终实现 Read 的类型占位符
-
符合所需类型签名的简单返回值
在同一个文件定义特征并且实现,在上面这样的示例代码中很费劲,File 出现在 3 个代码块。但是,随着经验增加,许多常用特征会成为习惯。只要理解了 PartialEq 特征对一种类型的作用,也就理解了对其他类型的作用。
PartialEq 对类型有什么作用呢?它可以用 == 运算符进行比较,Partial 允许类型在两个完全匹配的值不应该视为相等的情况下进行比较,例如:浮点数的“非数字类型”和 SQL 的 NULL 值。
⚠️ 注意:如果你浏览了 Rust 社区的论坛和文档,可能会注意到他们已经形成了自己的英语语法变体。例如,当看到 “…T 是 Debug…”,他们是在说类型 T 实现了 Debug 特征。
- 为自定义类型实现 std::fmt::Display
println! 和其他的同一类宏都使用相同底层机制,println!、print!、write!、writeln! 和 format! 都依赖于 Display 和 Debug 特征。也就是说,这些宏依赖于程序员实现的特征,以便能够将 {} 转换为打印到控制台的内容。
以下示例的代码,说明了 Debug 特征的使用:
#[derive(Debug,PartialEq)]
enum FileState {
Open,
Closed,
}
#[derive(Debug)]
struct File {
name: String,
data: Vec,
state: FileState,
}
fn main() {
let f5 = File::new("f5.txt");
//...
println!("{:?}", f5); // <1>
}
- Debug 依赖于 ? 工作,如果其他类型实现了 Display 并通过 {} 来打印,则不能正常工作。Display 要求类型实现一个返回 fmt::Result 类型的 fmt 方法。
以下示例代码为 File 和与其关联的 FIleState 类型实现 std::fmt::Display 特征:
impl Display for FileState {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // <1>
match *self {
FileState::Open => write!(f, "OPEN"),
FileState::Closed => write!(f, "CLOSED"),
}
}
}
impl Display for File {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { // <1>
write!(f, "<{} ({})>", self.name, self.state) // <2>
}
}
-
要实现 std::fmt::Display,必须为类型定义 fmt 方法
-
通过 write! 宏来使用内部类型的 Display 实现是很常见的
以下示例展示了实现 Display 的 Struct 中的字段同样也需要实现 Display 的情况:
#![allow(dead_code)]// <1>
use std::fmt; // <2>
use std::fmt::{Display}; // <3>
#[derive(Debug,PartialEq)]
enum FileState {
Open,
Closed,
}
#[derive(Debug)]
struct File {
name: String,
data: Vec,
state: FileState,
}
impl Display for FileState {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
match *self {
FileState::Open => write!(f, "OPEN"), // <4>
FileState::Closed => write!(f, "CLOSED"), // <4>
}
}
}
impl Display for File {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "<{} ({})>", self.name, self.state) // <5>
}
}
impl File {
fn new(name: &str) -> File {
File {
name: String::from(name),
data: Vec::new(),
state: FileState::Closed,
}
}
}
fn main() {
let f6 = File::new("f6.txt");
//...
println!("{:?}", f6); // <6>
println!("{}", f6); // <7>
}
-
跳过和 FileState::Open 有关的警告
-
将 std::fmt crate 导入本地范围,以便使用 fmt::Result
-
将 Display 导入本地范围,避免在代码中使用 fmt:: 前缀( fmt::Display )
-
利用 write! 来完成这些工作,字符串已经实现了 Display,所以需要做的事情不多
-
可以在代码中依赖 FileState 的 Display 实现
-
Debug 的实现会打印出熟悉的信息,与其他 Debug 实现一样,File { … }
-
自定义 Display 实现会显示
在 Rust 中,特征(traint)有很多用途,是泛型系统和类型检查的基础。通过使用特征,Rust 可以实现大多数面向对象语言中的继承形式。
7. 暴露类型
多个自定义 create 可能会互相交互,为了方便维护,通常隐藏 create 的内部实现细节,向其它 create 暴露必要的内容。接下来会介绍如何通过 Rust 中的可用工具和 cargo 来使这个过程更容易。
- 保护私有数据
Rust 中的内容默认是私有(为了安全性)的,如果导入前面示例中的自定义 create 将不可用,解决这个问题需要用到 pub 关键字。
#[derive(Debug,PartialEq)]
pubenum FileState { // <1>
Open,
Closed,
}
#[derive(Debug)]
pubstruct File {
pub name: String,
data: Vec, // <2>
pub state: FileState,
}
impl File {
pubfn new(name: &str) -> File { // <3>
File {
name: String::from(name),
data: Vec::new(),
state: FileState::Closed
}
}
}
fn main() {
let f7 = File::new("f7.txt");
//...
println!("{:?}", f7);
}
-
如果枚举类型是公开的,那么枚举的可选字段也是公开的
-
如果其它 create 导入这个 create,File.data 仍然是私有的
-
即使 File 结构是公开的,它的方法也必须使用 pub 明确标记才是公共的
8. 创建内嵌文档(注释)
当软件系统越来越庞大,记录开发进展将非常重要,接下来将介绍如何为代码添加文档并生成 HTML 版本的内容。
以下示例是熟悉的代码内容,其中新增了一些以 /// 和 //! 开头的行。第一种形式更常见,生成的文档是紧随其后的内容。第二种形式是指当前项目(文件),按照惯例,只用于注释当前模块,但也可用于其它地方。
//! Simulating files one step at a time. // <1>
/// Represents a "file", which probably lives on a file system. // <2>
#[derive(Debug)]
pubstruct File {
name: String,
data: Vec,
}
impl File {
/// New files are assumed to be empty, but a name is required.
pubfn new(name: &str) -> File {
File {
name: String::from(name),
data: Vec::new(),
}
}
/// Returns the file's length in bytes.
pubfn len(&self) -> usize {
self.data.len()
}
/// Returns the file's name.
pubfn name(&self) -> String {
self.name.clone()
}
}
fn main() {
let f1 = File::new("f1.txt");
let f1_name = f1.name();
let f1_length = f1.len();
println!("{:?}", f1);
println!("{} is {} bytes long", f1_name, f1_length);
}
-
//! 用来指代当前项目,即刚被编译器输入的模块
-
/// 注解紧随其后的任何内容
- 使用 rustdoc 为单个源文件生成文档
在安装 Rust 的时候同时安装了叫 rustdoc 的命令行工具,rustdoc 像一个有特殊用途的 Rust 编译器,不产生可执行代码,而是产生内嵌文档的 HTML 版本。
以下步骤对上面的示例代码生成文档:
# 示例代码的文件名为 file-doc.rs
rustdoc file-doc.rs
此时,可以看到生成了 doc 目录:

从浏览器访问 index.html:
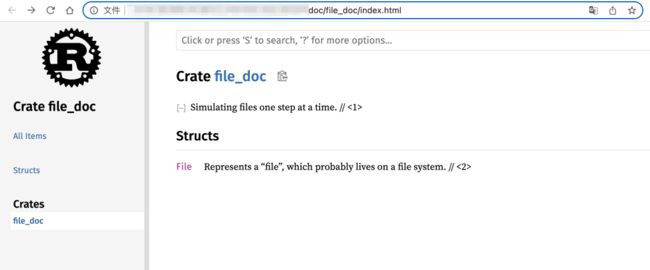
可以查看 File 结构的详细信息:
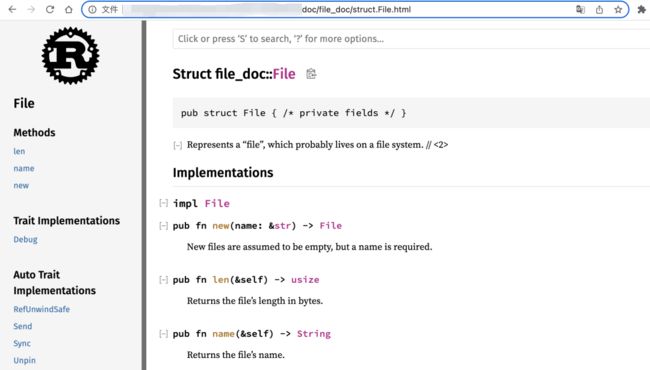
当项目规模变大,并且存在多个文件时,使用 rustdoc 手动生成文档效率是很低的,cargo 可以完成这些繁杂的工作。
- 使用 cargo 为 create 和相关的依赖生成文档
可以使用 cargo 将注释渲染为富文本,cargo 和 create 一起工作,而不是使用单个文件。以下是步骤将会创建名为 filebasics 的 create:
cargo new --bin filebasics
修改 src/main.rs 为上个实例的源代码。
生成文档:
cargo doc --open
使用 –open 参数会直接打开浏览器访问生成的文档:
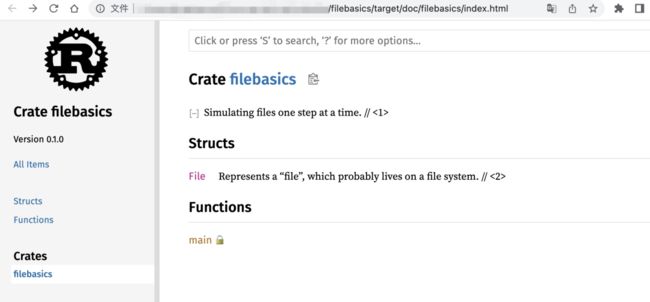
⚠️ 注意:如果依赖较多,生成文档需要一些时间,此时,可以使用 cargo doc --no-deps 命令,–no-deps 会大幅度减少 rustdoc 要完成的工作。
rustdoc 支持将 Markdown 格式内容渲染为富文本,这允许在文档中添加标题、列表和链接等内容。使用(```…```)包裹的代码片段会高亮显示(Markdown 语法)。
参考资料
[1] ASCII 码: https://www.asciitable.com/
[2] close: http://pubs.opengroup.org/onlinepubs/9699919799/functions/close.html
