Rasa是一个主流的构建对话机器人的开源框架,它的优点是几乎覆盖了对话系统的所有功能,并且每个模块都有很好的可扩展性。参考文献收集了一些Rasa相关的开源项目和优质文章。
一.Rasa介绍
1.Rasa本地安装
直接Rasa本地安装一个不好的地方就是容易把本地计算机的Python包版本弄乱,建议使用Python虚拟环境进行安装:
pip3 install -U --user pip && pip3 install rasa2.Rasa Docker Compose安装
查看本机Docker和Docker Compose版本: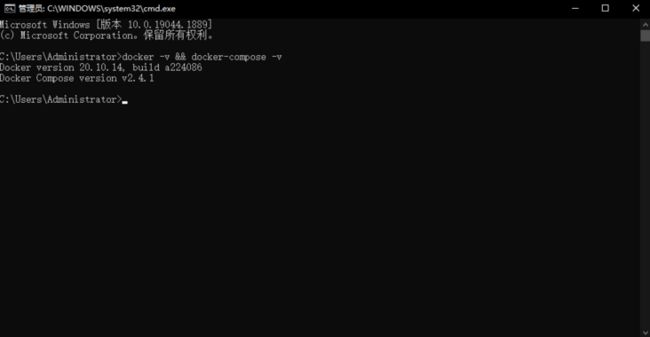
docker-compose.yml文件如下所示:
version: '3.0'
services:
rasa:
image: rasa/rasa
ports:
- "5005:5005"
volumes:
- ./:/app
command: ["run", "--enable-api", "--debug", "--cors", "*"]3.Rasa命令介绍
用到的相关的Rasa命令如下所示: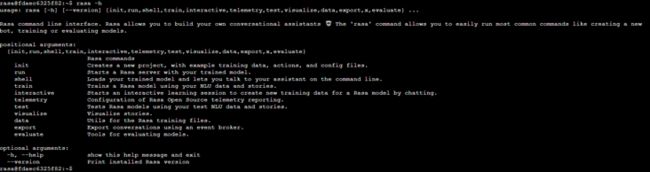
rasa init:创建一个新的项目,包含示例训练数据,actions和配置文件。
rasa run:使用训练模型开启一个Rasa服务。
rasa shell:通过命令行的方式加载训练模型,然后同聊天机器人进行对话。
rasa train:使用NLU数据和stories训练模型,模型保存在./models中。
rasa interactive:开启一个交互式的学习会话,通过会话的方式,为Rasa模型创建一个新的训练数据。
telemetry:Configuration of Rasa Open Source telemetry reporting.
rasa test:使用测试NLU数据和stories来测试Rasa模型。
rasa visualize:可视化stories。
rasa data:训练数据的工具。
rasa export:通过一个event broker导出会话。
rasa evaluate:评估模型的工具。
-h, --help:帮助命令。
--version:查看Rasa版本信息。
rasa run actions:使用Rasa SDK开启action服务器。
rasa x:在本地启动Rasa X。4.Rasa GitHub源码结构
Rasa的源码基本上都是用Python实现的:
二.Rasa项目基本流程
1.使用rasa init初始化一个项目
使用rasa init初始化聊天机器人项目:
.
├── actions
│ ├── __init__.py
│ └── actions.py
├── config.yml
├── credentials.yml
├── data
│ ├── nlu.yml
│ └── stories.yml
├── domain.yml
├── endpoints.yml
├── models
│ └── .tar.gz
└── tests
└── test_stories.yml 2.准备自定义的NLU训练数据
nlu.yml部分数据如下:
version: "3.1"
nlu:
- intent: greet
examples: |
- hey
- hello
- hi
- hello there
- good morning
- good evening
- moin
- hey there
- let's go
- hey dude
- goodmorning
- goodevening
- good afternoon上面的intent: greet表示意图为great,下面的是具体的简单例子。稍微复杂点的例子格式是:[实体值](实体类型名),比如[明天](日期)[上海](城市)的天气如何?其中的日期和城市就是NLP中实体识别中的实体了。除了intent必须外,该文件还可以包含同义词synonym、正则表达式regex和查找表lookup等。
3.配置NLU模型
最主要就是pipeline的配置了。相关的config.yml文件如下:
pipeline:
# # No configuration for the NLU pipeline was provided. The following default pipeline was used to train your model.
# # If you'd like to customize it, uncomment and adjust the pipeline.
# # See https://rasa.com/docs/rasa/tuning-your-model for more information.
# - name: WhitespaceTokenizer
# - name: RegexFeaturizer
# - name: LexicalSyntacticFeaturizer
# - name: CountVectorsFeaturizer
# - name: CountVectorsFeaturizer
# analyzer: char_wb
# min_ngram: 1
# max_ngram: 4
# - name: DIETClassifier
# epochs: 100
# constrain_similarities: true
# - name: EntitySynonymMapper
# - name: ResponseSelector
# epochs: 100
# constrain_similarities: true
# - name: FallbackClassifier
# threshold: 0.3
# ambiguity_threshold: 0.1pipeline主要是分词组件、特征提取组件、NER组件和意图分类组件等,通过NLP模型进行实现,并且组件都是可插拔可替换的。
4.准备story数据
stories.yml文件如下:
version: "3.1"
stories:
- story: happy path
steps:
- intent: greet
- action: utter_greet
- intent: mood_great
- action: utter_happy
- story: sad path 1
steps:
- intent: greet
- action: utter_greet
- intent: mood_unhappy
- action: utter_cheer_up
- action: utter_did_that_help
- intent: affirm
- action: utter_happy
- story: sad path 2
steps:
- intent: greet
- action: utter_greet
- intent: mood_unhappy
- action: utter_cheer_up
- action: utter_did_that_help
- intent: deny
- action: utter_goodbye这里面可看做是用户和机器人一个完整的真实的对话流程,对话策略可通过机器学习或者深度学习的方式从其中进行学习。
5.定义domain
domain.yml文件如下:
version: "3.1"
intents:
- greet
- goodbye
- affirm
- deny
- mood_great
- mood_unhappy
- bot_challenge
responses:
utter_greet:
- text: "Hey! How are you?"
utter_cheer_up:
- text: "Here is something to cheer you up:"
image: "https://i.imgur.com/nGF1K8f.jpg"
utter_did_that_help:
- text: "Did that help you?"
utter_happy:
- text: "Great, carry on!"
utter_goodbye:
- text: "Bye"
utter_iamabot:
- text: "I am a bot, powered by Rasa."
session_config:
session_expiration_time: 60 #单位是min,设置为0表示无失效期
carry_over_slots_to_new_session: true #设置为false表示不继承历史词槽领域(domain)中包含了聊天机器人的所有信息,包括意图(intent)、实体(entity)、词槽(slot)、动作(action)、表单(form)和回复(response)等。
6.配置Rasa Core模型
最主要就是policies的配置了。相关的config.yml文件如下:
# Configuration for Rasa Core.
# https://rasa.com/docs/rasa/core/policies/
policies:
# # No configuration for policies was provided. The following default policies were used to train your model.
# # If you'd like to customize them, uncomment and adjust the policies.
# # See https://rasa.com/docs/rasa/policies for more information.
# - name: MemoizationPolicy
# - name: RulePolicy
# - name: UnexpecTEDIntentPolicy
# max_history: 5
# epochs: 100
# - name: TEDPolicy
# max_history: 5
# epochs: 100
# constrain_similarities: truepolicies主要就是对话策略的配置,常用的包括TEDPolicy、UnexpecTEDIntentPolicy、MemoizationPolicy、AugmentedMemoizationPolicy、RulePolicy和Custom Policies等,并且策略之间也是有优先级顺序的。
7.使用rasa train训练模型
rasa train
或者
rasa train nlu
rasa train core使用data目录中的数据作为训练数据,使用config.yml作为配置文件,并将训练后的模型保存到models目录中。
8.使用rasa test测试模型
通常把数据分为训练集和测试集,在训练集上训练模型,在测试集上测试模型:
rasa data split nlu
rasa test nlu -u test_set.md --model models/nlu-xxx.tar.gz说明:当然也是可以通过交叉验证的方式来评估模型的。
9.让用户使用聊天机器人
可以通过shell用指定的模型进行交互:
rasa shell -m models/nlu-xxx.tar.gz还可以通过rasa run --enable-api这种rest方式进行交互。如下:
三.Rasa系统架构
1.Rasa处理消息流程
下图展示了从用户的Message输入到用户收到Message的基本流程: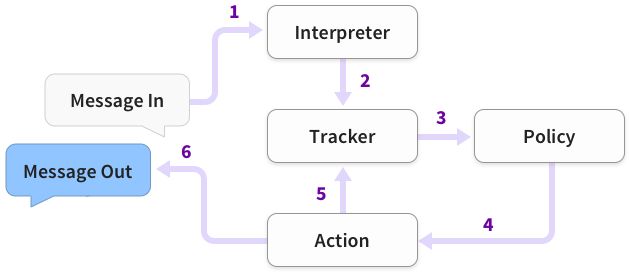
步骤1:用户输入的Message传递到Interpreter(NLP模块),然后识别Message中的意图(intent)和提取实体(entity)。
步骤2:Rasa Core将Interpreter提取的intent和entity传递给Tracker,然后跟踪记录对话状态。
步骤3:Tracker把当前状态和历史状态传递给Policy。
步骤4:Policy根据当前状态和历史状态进行预测下一个Action。
步骤5:Action完成预测结果,并将结果传递到Tracker,成为历史状态。
步骤6:Action将预测结果返回给用户。
2.Rasa系统结构
Rasa主要包括Rasa NLU(自然语言理解,即图中的NLU Pipeline)和Rasa Core(对话状态管理,即图中的Dialogue Policies)两个部分。Rasa NUL将用户的输入转换为意图和实体信息。Rasa Core基于当前和历史的对话记录,决策下一个Action。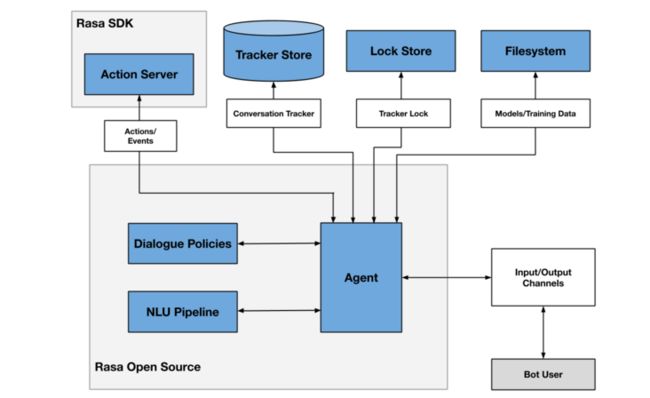
除了核心的自然语言理解(NLU)和对话状态管理(DSM)外,还有Agent代理系统,Action Server自定义后端服务系统,通过HTTP和Rasa Core通信;辅助系统Tracker Store、Lock Store和Event Broker等。还有上图没有显示的channel,它连接用户和对话机器人,支持多种主流的即时通信软件对接Rasa。
(1)Agent组件:从用户角度来看,主要是接收用户输入消息,返回Rasa系统的回答。从Rasa角度来看,它连接自然语言理解(NLU)和对话状态管理(DSM),根据Action得到回答,并且保存对话数据到数据库。
(2)Tracker Store:将用户和Rasa机器人的对话存储到Tracker Store中,Rasa提供的开箱即用的系统包括括PostgreSQL、SQLite、Oracle、Redis、MongoDB、DynamoDB,当然也可以自定义存储。
(3)Lock Store:一个ID产生器,当Rasa集群部署的时候会用到,当消息处于活动状态时锁定会话,以此保证消息的顺序处理。
(4)Event Broker:简单理解就是一个消息队列,把Rasa消息转发给其它服务来处理,包括RabbitMQ、Kafka等。
(5)FileSystem:保存训练好的模型,可以放在本地磁盘、云服务器等位置。
(6)Action Server:通过rasa-sdk可以实现Rasa的一个热插拔功能,比如查询天气预报等。
参考文献:
[1]Rasa 3.x官方文档:https://rasa.com/docs/rasa/
[2]Rasa Action Server:https://rasa.com/docs/action-...
[3]Rasa Enterprise:https://rasa.com/docs/rasa-en...
[4]Rasa Blog:https://rasa.com/blog/
[5]Rasa GitHub:https://github.com/rasahq/rasa
[6]Awesome-Chinese-NLP:https://github.com/crownpku/A...
[7]BotSharp文档:https://botsharp.readthedocs....
[8]BotSharp GitHub:https://github.com/SciSharp/B...
[9]rasa-ui GitHub:https://github.com/paschmann/...
[10]rasa-ui Gitee:https://gitee.com/jindao666/r...
[11]rasa_chatbot_cn:https://github.com/GaoQ1/rasa...
[12]Rasa_NLU_Chi:https://github.com/crownpku/R...
[13]nlp-architect:https://github.com/IntelLabs/...
[14]rasa-nlp-architect:https://github.com/GaoQ1/rasa...
[15]rasa_shopping_bot:https://github.com/whitespur/...
[16]facebook/duckling:https://github.com/facebook/d...
[17]rasa-voice-interface:https://github.com/RasaHQ/ras...
[18]Rasa:https://github.com/RasaHQ
[19]ymcui/Chinese-BERT-wwm:https://github.com/ymcui/Chin...
[20]Hybrid Chat:https://gitlab.expertflow.com...
[21]rasa-nlu-trainer:https://rasahq.github.io/rasa...
[22]crownpku/Rasa_NLU_Chi:https://github.com/crownpku/r...
[23]jiangdongguo/ChitChatAssistant:https://github.com/jiangdongg...
[24]Rasa框架应用:https://www.zhihu.com/column/...
[25]Rasa开源引擎介绍:https://zhuanlan.zhihu.com/p/...
[26]Rasa聊天机器人专栏开篇:https://cloud.tencent.com/dev...
[27]rasa-nlu的究极形态及rasa的一些难点:https://www.jianshu.com/p/553...
[28]Rasa官方文档手册:https://juejin.cn/post/684490...
[29]Rasa官方视频教程:https://www.bilibili.com/vide...
[30]用Rasa NLU构建自己的中文NLU系统:http://www.crownpku.com/2017/...用Rasa_NLU构建自己的中文NLU系统.html
[31]Rasa Core开发指南:https://blog.csdn.net/AndrExp...
本文由mdnice多平台发布