OD-Model【9】:YOLOv5
系列文章目录
YOLO目标检测系列(一):
OD-Model【5】:YOLOv1
YOLO目标检测系列(二):
OD-Model【6】:YOLOv2
YOLO目标检测系列(三):
OD-Model【7】:YOLOv3
YOLO目标检测系列(四):
OD-Model【8】:YOLOv4
YOLO目标检测系列(五):
OD-Model【9】:YOLOv5
文章目录
- 系列文章目录
- 前言
- 1. Introduction
- 2. Network Structure
-
- 2.1. Structure
- 2.2. Backbone
-
- 2.2.1. Focus
-
- 2.2.1.1. Principle
- 2.2.1.2. Effects
- 2.2.2. CSP
- 2.3. Neck
-
- 2.3.1. SPPF
- 2.3.2. CSP
- 3. Data augmentation
-
- 3.1. Mosaic
- 3.2. Copy paste
- 3.3. Random affine
- 3.4. MixUp
- 3.5. Augment HSV
- 3.6. Random horizontal flip
- 4. Training Strategies
-
- 4.1. Eliminate Grid sensitivity
- 4.2. Matching positive samples
- 4.3. Warmup and Cosine LR scheduler
-
- 4.3.1. Warmup 热身
- 4.3.2. Cosine 学习率下降策略
- 4.4. Adaptive image scaling
- 4.5. Multi-scale training (0.5~1.5)
- 4.6. AutoAnchor (For training custom data)
- 4.7. EMA(Exponential Moving Average)
- 4.8. Mixed precision
- 5. Loss calculation
-
- 5.1. Components
- 5.2. Balance
- 6. Comparison
-
- 6.1. Params
- 6.2. Structure
- 6.3. Depth_multiple
-
- 6.3.1. Difference
- 6.3.2. Code
- 6.3.3. Validity
- 6.4. Width_multiple
-
- 6.4.1. Difference
- 6.4.2. Code
- 6.4.3. Validity
- 总结
前言
YOLOv5 并未正式发表过论文,所以本文主要参考源码及网上的高浏览博文进行总结学习
本文参考的 YOLOv5 的版本为 v6.1
YOLOv5 是一种单阶段目标检测算法,该算法在 YOLOv4 的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。虽很多人考虑到 YOLOv5 的创新性不足,对算法是否能够进化,称得上 YOLOv5 而议论纷纷。
本文主要根据网上的各位大佬写的博客以及有关源码进行学习并记录得此博客
1. Introduction
YOLOv5 几种针对输入图片尺寸为 640 × 640 640 \times 640 640×640 的版本的速度与精度如下图所示:
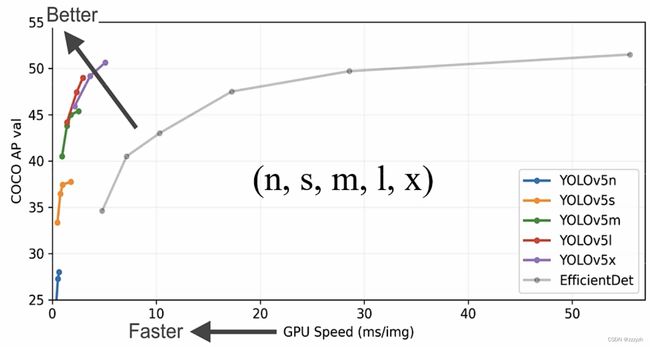
该版本模型的最大池化下采样率为32倍,预设特征层为3层
YOLOv5 几种针对输入图片尺寸为 1280 × 1280 1280 \times 1280 1280×1280 的版本的速度与精度如下图所示:
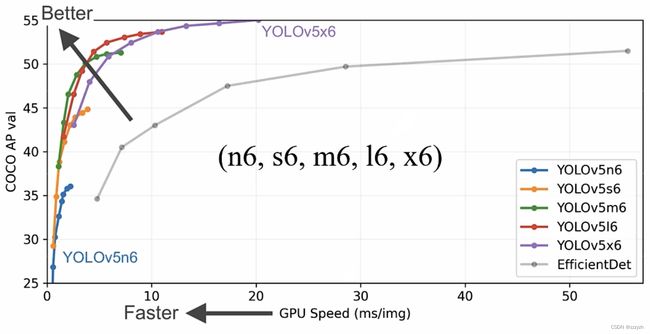
该版本模型的最大池化下采样率为64倍,预设特征层为4层
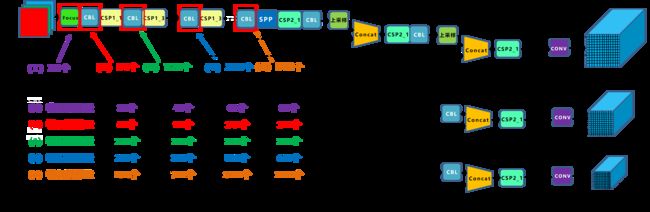
2. Network Structure
2.1. Structure
网络结构主要由以下几部分组成:
- Backbone: New CSP-Darknet53
- Neck: SPPF, New CSP-PAN
- Head: YOLOv3 Head

上图是 YOLOv5l 对应的网络结构图。YOLOv5针对不同大小(n, s, m, l, x)的网络整体架构都是一样的,只不过会在每个子模块中采用不同的深度和宽度。
2.2. Backbone
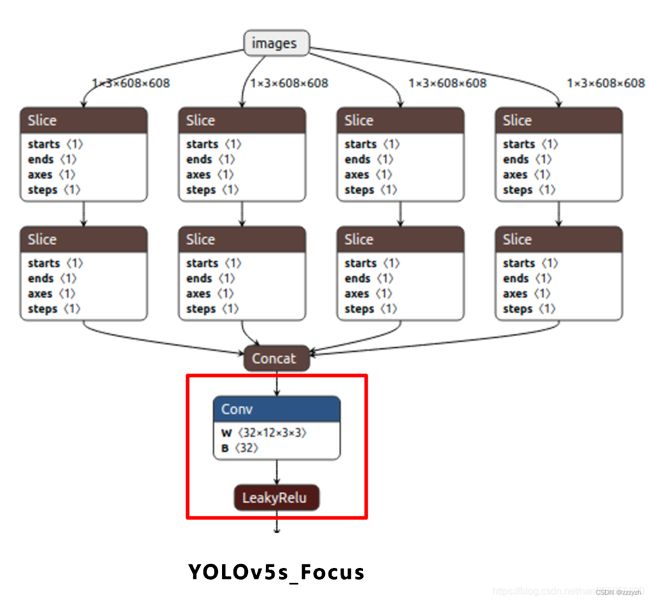
2.2.1. Focus
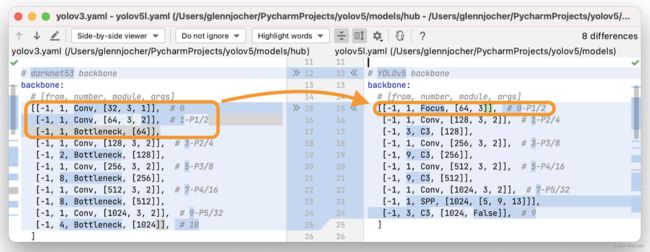
在 YOLOv5 的源代码中,作者使用 Focus 层去替换了前 3 个 YOLOv3 层,所以总的来说在保证了下采样时不丢失休息的同时,在一定程度上降低了参数量、提高了运算的速度
Focus层的主要目的是减少图层,减少参数,减少FLOPS,减少CUDA内存,提高前进和向后速度,同时最大限度地减少对mAP的影响
2.2.1.1. Principle
将每个 2 × 2 2 \times 2 2×2 的相邻像素划分为一个 patch,然后将每个 patch 中相同位置(同一颜色)像素给拼在一起就得到了4个 feature map,然后再接上一个 3 × 3 3 \times 3 3×3 大小的卷积层。
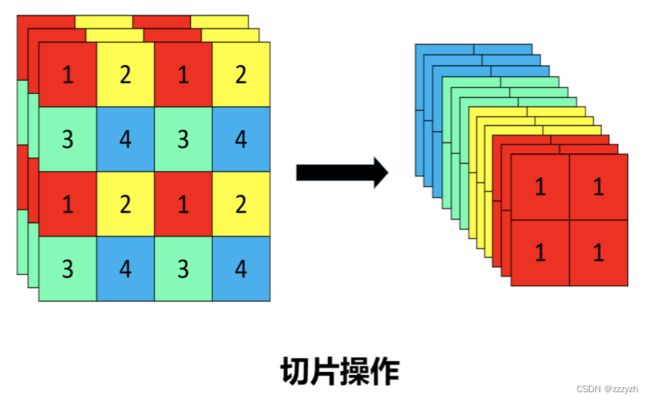
这个操作类似于邻近下采样,这样就拿到了四张图片,四张图片互补,但是没有信息丢失。这样一来,将 W、H 信息集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的 RGB 3 通道模式变成了 12 个通道。最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
Focus 模块与 6 × 6 6 \times 6 6×6 是等效的。到了 v6.1 发现,将 Focus 模块替换成 6 × 6 6 \times 6 6×6 的普通卷积层,可以提高效率
2.2.1.2. Effects
两个关键概念:
- 参数数量(params)
- 定义
- 关系到模型大小,单位通常是M,通常参数用 float32 表示,所以模型大小是参数数量的 4 倍
- 计算公式
- K h × K w × C i n × C o u t Kh \times Kw \times Cin \times Cout Kh×Kw×Cin×Cout
- 定义
- 计算量(FLOPs)
- 定义
- 即浮点运算数,可以用来衡量算法或模型的复杂度,这关系到算法速度,大模型的单位通常为G,小模型单位通常为M
- 通常只考虑乘加操作的数量,而且只考虑 Conv 和 FC 等参数层的计算量,忽略BN和PReLU等
- 一般情况下,Conv 和 FC 层也会忽略仅纯加操作的计算量,如 bias 偏置加和、shoutcut 残差加等,目前技术有 BN 和 CNN 可以不加 bias
- 计算公式
- K h × K w × C i n × C o u t × H × W = p a r a m s × H × W Kh \times Kw \times Cin \times Cout \times H \times W = params \times H \times W Kh×Kw×Cin×Cout×H×W=params×H×W
- 即当前层 filter × 输出的 feature map
- K h × K w × C i n × C o u t × H × W = p a r a m s × H × W Kh \times Kw \times Cin \times Cout \times H \times W = params \times H \times W Kh×Kw×Cin×Cout×H×W=params×H×W
- 定义
对比普通下采样与 Focus:
- 普通下采样
- 将一张 640 × 640 × 3 640 \times 640 \times 3 640×640×3 的图片输入 3 × 3 3 \times 3 3×3 的卷积中,步长为 2,输出通道 32,下采样后得到 320 × 320 × 32 320 \times 320 \times 32 320×320×32 的特征图,那么普通卷积下采样理论的计算量为:
- params(conv): 3 × 3 × 3 × 32 + 32 + 32 = 928 3 × 3 × 3 × 32 +32 +32 = 928 3×3×3×32+32+32=928
- 后面两个 32 分别为 bias 和 BN 层参数(通常占比小可忽略)
- FLOPs(conv): 3 × 3 × 3 × 32 × 320 × 320 = 88473600 3 × 3 × 3 × 32 × 320 × 320 = 88473600 3×3×3×32×320×320=88473600
- 不考虑bias情况下
- Focus
- 将一张 640 × 640 × 3 640 \times 640 \times 3 640×640×3 的图片输入 Focus 结构,采用切片操作,先变成 320 × 320 × 12 320 \times 320 \times 12 320×320×12 的特征图,再经过 3 × 3 3 \times 3 3×3 的卷积操作,输出通道 32,最终变成 320 × 320 × 32 320 \times 320 \times 32 320×320×32 的特征图,那么 Focus 理论的计算量为:
- params(conv): 3 × 3 × 12 × 32 + 32 + 32 = 3520 3 × 3 × 12 × 32 +32 +32 =3520 3×3×12×32+32+32=3520
- 后面两个 32 分别为 bias 和 BN 层参数(通常占比小可忽略)
- FLOPs(conv): 3 × 3 × 12 × 32 × 320 × 320 = 353894400 3 × 3 × 12 × 32 × 320 × 320 = 353894400 3×3×12×32×320×320=353894400
- 不考虑bias情况下
2.2.2. CSP
YOLOv5 的 CSP 结构是将原输入分成两个分支,分别进行卷积操作使得通道数减半,然后一个分支进行 Bottleneck * N 操作,然后 concat 两个分支,使得 BottlenneckCSP 的输入与输出是一样的大小,这样是为了让模型学习到更多的特征。
在 backbone 中,使用 CSP1_X 结构

组件说明:
- Resunit 是 x 个残差组件
- CBS:Conv + BN + SiLU
将输入分为两个分支,一个分支先通过CBS,再经过多个残差结构(Bottleneck * N),再进行一次卷积;另一个分支直接进行卷积;然后两个分支进行 concat,再经过一个 BN 层和一次 SiLU 激活,最后通过一个 CBS
CSP1_X 应用于 backbone 主干网络部分。backbone 是较深的网络,增加残差结构可以增加层与层之间反向传播的梯度值,避免因为加深而带来的梯度消失,从而可以提取到更细粒度的特征并且不用担心网络退化
2.3. Neck
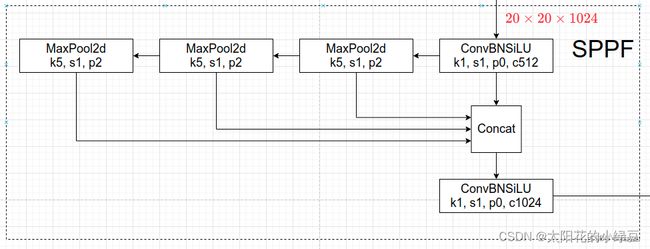
2.3.1. SPPF
将 YOLOv4 中使用的SPP替换成了 SPPF,两者的作用是一样的,但后者效率更高
SPP 结构如下图所示,是将输入并行通过多个不同大小的 MaxPool,然后做进一步融合,能在一定程度上解决目标多尺度问题。
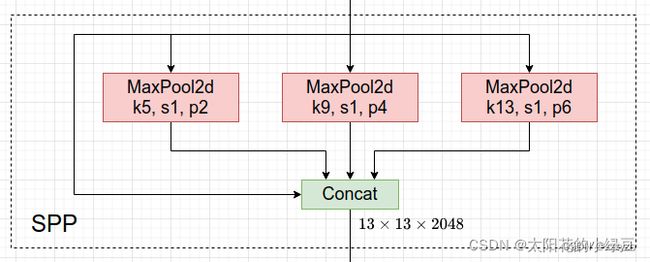
而 SPPF 结构是将输入串行通过多个 5 × 5 5 \times 5 5×5 大小的 MaxPool 层,这里需要注意的是串行两个 5 × 5 5 \times 5 5×5 大小的 MaxPool 层是和一个 9 × 9 9 \times 9 9×9 大小的 MaxPool 层计算结果是一样的,串行三个 5 × 5 5 \times 5 5×5 大小的 MaxPool 层是和一个 13 × 13 13 \times 13 13×13 大小的 MaxPool 层计算结果是一样的(计算量更小,效率更高)。
2.3.2. CSP
YOLOv5 的 CSP 结构是将原输入分成两个分支,分别进行卷积操作使得通道数减半,然后一个分支进行 Bottleneck * N 操作,然后 concat 两个分支,使得 BottlenneckCSP 的输入与输出是一样的大小,这样是为了让模型学习到更多的特征。
在 neck 中,使用 CSP2_X 结构(相比于 CSP1_X 没有了残差结构,因为不需要处理比较深的网络结构)

3. Data augmentation
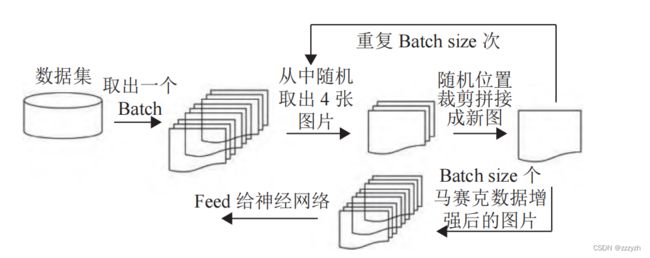
3.1. Mosaic
与 YOLOv4 中使用的 Mosaic 数据增强方法一样,在我的另一篇 blog OD-Model【8】:YOLOv4 中有非常详细的讲解。
3.2. Copy paste
Copy-paste 有生成很多新的训练数据方法:
- 两张图片的选择,是把图片 a 贴到图片 b 还是把图片 b 贴到图片 a
- 也可以选择部分a图片中的实例贴到b中
- 在贴实例的时候,位置的选择
这些都会影响copy-paste的结果,下图就是各种各样的copy-paste方法:
具体实现方法:
- 随机挑选两张图片,两张图片进行随机水平旋转,随机缩放
- 随机挑选其中一张图片的部分实例,贴到另一张图中
- 去掉完全被遮挡的实例
- 使用 α \alpha α 去平滑 paste 的实例,使得与目标图片融合的更好 ,对 pasted image(I2)的 ground-truth 做高斯滤波,得到一个 mask 图片 α \alpha α , target image 是 l1,增强后的结果这样计算 I 1 × α + I 2 × ( 1 − α ) I1 \times \alpha + I2 \times (1 − \alpha) I1×α+I2×(1−α)
需要注意的是:数据要有 segments 数据才行,即每个目标的实例分割信息
3.3. Random affine
随机进行仿射变换:Rotation,Scale,Translation,Shear
3.4. MixUp
mixup 是一种对图像进行混类增强的算法,它可以将不同类之间的图像以线性插值的方式进行混合,从而构建新的训练样本,扩充训练数据集
x ~ = λ x i + ( 1 − λ ) x j y ~ = λ y i + ( 1 − λ ) y j \tilde{x} = \lambda x_i + (1 - \lambda)x_j \\ \tilde{y} = \lambda y_i + (1 - \lambda)y_j x~=λxi+(1−λ)xjy~=λyi+(1−λ)yj
其中, ( x i , y i ) (x_i, y_i) (xi,yi) 和 ( x j , y j ) (x_j, y_j) (xj,yj) 是从训练数据中随机抽取的两个样本,且 λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ∈[0,1]
实现步骤:
- 对于输入的一个 batch 的待测图片 images,我们将其和随机抽取的图片按照系数 λ \lambda λ 加权相加, λ ∈ [ 0 , 1 ] \lambda \in [0, 1] λ∈[0,1],符合 beta 分布
- 将上一步中得到的混合张量 inputs 传递给模型得到输出张量 outputs
- 计算损失函数时,针对两个图片的标签分别计算损失函数,然后按照比例 λ \lambda λ 进行损失函数的加权求和

3.5. Augment HSV
随机调整色度,饱和度以及明度
HSV(Hue, Saturation, Value)是根据颜色的直观特性由 A. R. Smith 在1978年创建的一种颜色空间, 也称六角锥体模型(Hexcone Model)
这个模型中颜色的参数分别是:色调(Hue),饱和度(Saturation),明度(Saturation)
用下面这个圆柱体来表示 HSV 颜色空间,圆柱体的横截面可以看做是一个极坐标系 ,H 用极坐标的极角表示,S 用极坐标的极轴长度表示,V 用圆柱中轴的高度表示
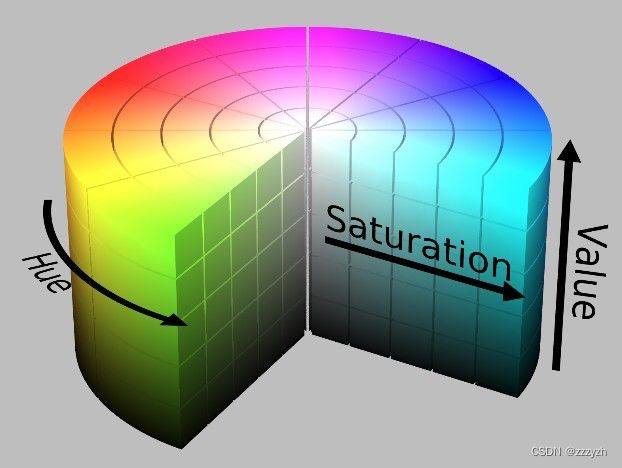
- 色调H
- 用角度度量,取值范围为 0°~360°,表示色彩信息,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°
- 它们的补色是:黄色为60°,青色为180°,紫色为300°;
- 在 RGB 中 颜色由三个值共同决定,比如黄色为即 (255,0,255)
- 在HSV中,黄色只由一个值决定,Hue = 60即可
- 饱和度S:
- 表示颜色接近光谱色的程度。
- 饱和度越高,说明颜色越深,越接近光谱色
- 饱和度越低,说明颜色越浅,越接近白色
- 饱和度为0表示纯白色。通常取值范围为:0%~100%,值越大,颜色越饱和
- 一种颜色,可以看成是某种光谱色与白色混合的结果。其中光谱色所占的比例愈大,颜色接近光谱色的程度就愈高,颜色的饱和度也就愈高。饱和度高,颜色则深而艳
- 表示颜色接近光谱色的程度。
- 明度V
- 表示颜色明亮的程度。
- 对于光源色,明度值与发光体的光亮度有关;
- 对于物体色,此值和物体的透射比或反射比有关
- 通常取值范围为0%(黑)~ 100%(白)
- 明度为0表示纯黑色(此时颜色最暗)
- 表示颜色明亮的程度。
3.6. Random horizontal flip
随机水平翻转
4. Training Strategies
4.1. Eliminate Grid sensitivity
在我的上一篇 blog OD-Model【8】:YOLOv4中,有关于消除 Grid 敏感度优化的讲解
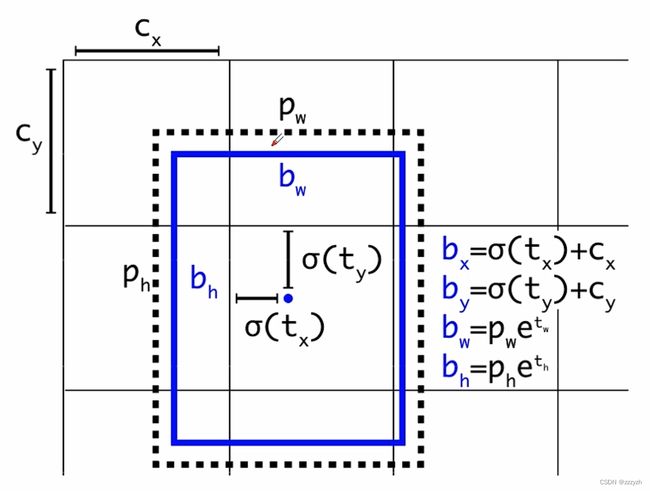
在原来 YOLOv3 中,关于计算预测的目标中心坐标计算公式是:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y bx=σ(tx)+cxby=σ(ty)+cy
其中:
- t x t_x tx 是网络预测的目标中心 x x x坐标偏移量(相对于网格的左上角)
- t y t_y ty 是网络预测的目标中心 y y y坐标偏移量(相对于网格的左上角)
- c x c_x cx 是对应网格左上角的 x x x 坐标
- c x c_x cx 是对应网格左上角的 y y y 坐标
- σ \sigma σ 是sigmoid激活函数,将预测的偏移量限制在0到1之间,即预测的中心点不会超出对应的Grid Cell区域
- σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1 + e^{-x}} σ(x)=1+e−x1
对偏移量进行了缩放从原来的 ( 0 , 1 ) (0, 1) (0,1) 缩放到 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5);通过引入一个大于一的系数,让网络的预测值能够很容易达到0或者1,此时最终预测的目标中心点的坐标的计算公式为:
b x = ( σ ( t x ) ⋅ 2 − 0.5 ) + c x b x = ( σ ( t y ) ⋅ 2 − 0.5 ) + c y b_x = (\sigma(t_x) \cdot 2 - 0.5) + c_x \\ b_x = (\sigma(t_y) \cdot 2 - 0.5) + c_y bx=(σ(tx)⋅2−0.5)+cxbx=(σ(ty)⋅2−0.5)+cy
在 YOLOv5 中除了调整预测Anchor相对Grid网格左上角 ( c x , c y ) (c_x, c_y) (cx,cy) 偏移量以外,还调整了预测目标高宽的计算公式:
原本的:
b w = p w ⋅ e t w b h = p h ⋅ e t h b_w = p_w \cdot e^{t_w} \\ b_h = p_h \cdot e^{t_h} bw=pw⋅etwbh=ph⋅eth
此时 e x e^x ex 不受限,可能出现指数爆炸的情况,也就会导致损失为 NaN 以及训练不稳定的情况
调整过后的:
b w = p w ⋅ ( 2 ⋅ σ ( t w ) ) 2 b h = p w h ⋅ ( 2 ⋅ σ ( t h ) ) 2 b_w = p_w \cdot (2 \cdot \sigma(t_w))^2 \\ b_h = p_wh\cdot (2 \cdot \sigma(t_h))^2 bw=pw⋅(2⋅σ(tw))2bh=pwh⋅(2⋅σ(th))2
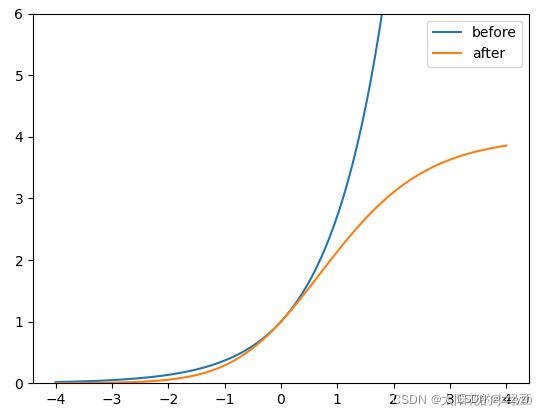
很明显调整后倍率因子被限制在 ( 0 , 4 ) (0, 4) (0,4) 之间
4.2. Matching positive samples
YOLOv5 和 YOLOv4 在匹配正样本上大致相同,主要的区别在于GT Box与Anchor Templates模板的匹配方式:
- YOLOv4
- 直接将每个 GT Box 与对应的 Anchor Templates 模板计算IoU,只要 IoU 大于设定的阈值就算匹配成功
- YOLOv5
- 先计算每个 GT Box 与对应的 Anchor Templates 模板的高宽比例,即:
r w = w g t / w a t r h = h g t / h a t r_w = w_{gt} / w_{at} \\ r_h = h_{gt} / h_{at} rw=wgt/watrh=hgt/hat - 然后统计这些比例和它们倒数之间的最大值,这里可以理解成计算 GT Box 和 Anchor Templates 分别在宽度以及高度方向的最大差异(当相等的时候比例为1,差异最小):
r w m a x = m a x ( r w 1 / r w ) r h m a x = m a x ( r h 1 / r h ) r_w^{max} = max(r_w 1/r_w) \\ r_h^{max} = max(r_h 1/r_h) rwmax=max(rw1/rw)rhmax=max(rh1/rh) - 接着统计 r w m a x r_w^{max} rwmax 和 r h m a x r_h^{max} rhmax 之间的最大值,即宽度和高度方向差异最大的值:
r m a x = m a x ( r w m a x , r h m a x ) r^{max} = max(r_w^{max}, r_h^{max}) rmax=max(rwmax,rhmax)
- 先计算每个 GT Box 与对应的 Anchor Templates 模板的高宽比例,即:
如果 GT Box 和对应的 Anchor Template 的 r m a x r^{max} rmax 小于阈值 anchor_t(在源码中默认设置为4.0,由上一小节我们也可以知道,在消除 grid 敏感度的同时,已经将网络预测的相对于 anchor 模版的缩放因子限制在了对应的值内),即 GT Box 和对应的 Anchor Template 的高、宽比例相差不算太大,则将 GT Box 分配给该 Anchor Template 模板。
假设对某个 GT Box 而言,其实只要 GT Box 满足在某个 Anchor Template 宽和高的 × 0.25 \times 0.25 ×0.25 倍和 × 4.0 \times 4.0 ×4.0 倍之间就算匹配成功。
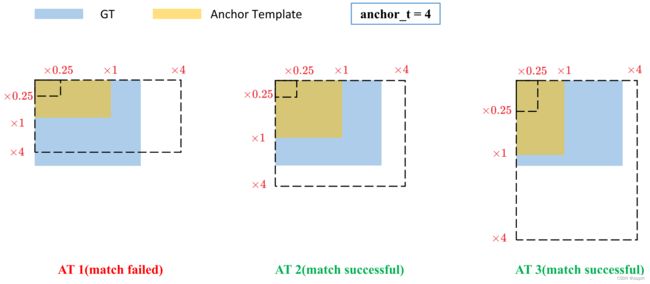
剩下的步骤和 YOLOv4 中一致,想要了解 YOLOv4 中的相关知识可以看我的另一篇 blog OD-Model【8】:YOLOv4:
- 将 GT 投影到对应预测特征层上,根据 GT 的中心点定位到对应 Cell,注意图中有三个对应的 Cell。因为网络预测中心点的偏移范围已经调整到了 ( − 0.5 , 1.5 ) (-0.5, 1.5) (−0.5,1.5),所以按理说只要 Grid Cell 左上角点距离 GT 中心点在 ( − 0.5 , 1.5 ) (−0.5,1.5) (−0.5,1.5) 范围内它们对应的 Anchor 都能回归到 GT 的位置处。这样会让正样本的数量得到大量的扩充。
- 拓展的 Cell 对应的 Anchor 模版也会被视作正样本

需要注意的是,YOLOv5 源码中扩展 Cell 时只会往上、下、左、右四个方向扩展,不会往左上、右上、左下、右下方向扩展。下面又给出了一些根据 G T x c e n t e r GT_x^{center} GTxcenter, G T y c e n t e r GT_y^{center} GTycenter 的位置扩展的一些Cell案例,其中 % 1 \% 1 %1 表示取余并保留小数部分。

4.3. Warmup and Cosine LR scheduler
4.3.1. Warmup 热身
模型的权重一开始训练时是随机初始化的,此时若选择较大的学习率,模型可能出现振荡,选择 Warmup 预热学习率,可使开始训练时学习率较小,模型更容易慢慢趋于稳定
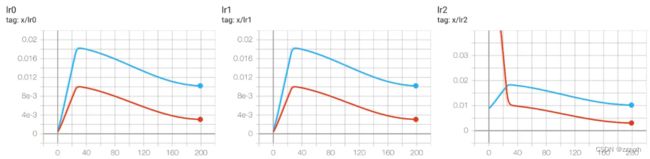
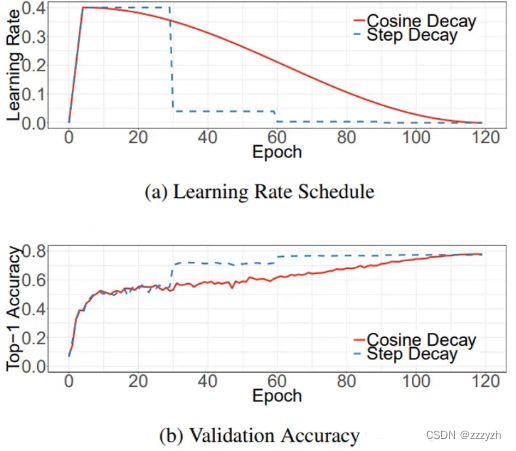
从图中可以看出,前 30 个 epochs 可以认为是一个预热过程(Warmup),在预热的时候可以看到刚开始学习率非常之小,慢慢地学习率会有增加。
4.3.2. Cosine 学习率下降策略
待模型相对稳定后,选择余弦退火调整学习率进行训练,模型收敛速度会变得更快,模型效果更佳

在训练过程中,每个批次的训练通过余弦退火的方式来更新学习率
4.4. Adaptive image scaling
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
作者认为,在项目实际使用时,很多图片的长宽比不同。因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。
通过对原始图像自适应的添加最少的黑边,减少计算量,提升目标检测速度
实现步骤:
- 计算缩放比例
- 计算缩放后的尺寸
- 计算黑边填充数值
4.5. Multi-scale training (0.5~1.5)
多尺度训练
假设设置输入图片的大小为 640 × 640 640 \times 640 640×640,训练时采用尺寸是在 0.5 × 640 ∼ 1.5 × 640 0.5 \times 640 ∼ 1.5 \times 640 0.5×640∼1.5×640 之间随机取值,注意取值时取得都是32的整数倍(因为网络会最大下采样32倍)
4.6. AutoAnchor (For training custom data)
训练自己数据集时可以根据自己数据集里的目标进行重新聚类生成 Anchors 模板
在Yolo算法中,针对不同的数据集,都会有初始设定长宽的锚框。
在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框 ground truth 进行比对,计算两者差距,再反向更新,迭代网络参数。因此初始锚框也是比较重要的一部分
4.7. EMA(Exponential Moving Average)
可以理解为给训练的参数加了一个动量,让它更新过程更加平滑
4.8. Mixed precision
混合精度训练,能够减少显存的占用并且加快训练速度,前提是GPU硬件支持。
5. Loss calculation
5.1. Components
YOLOv5 的损失主要由三个部分组成:
- Classes loss
- 分类损失,采用的是 BCE loss(二值交叉熵损失),注意只计算正样本的分类损失
- Objectness loss
- obj损失,采用的是 BCE loss,注意这里的 obj 指的是网络预测的目标边界框与 GT box 的 CIoU,这里计算的是所有样本的 obj 损失
- Location loss
- 定位损失,采用的是 CIoU loss,注意只计算正样本的定位损失
L o s s = λ 1 L c l s + λ 2 L o b j + λ 2 L l o c Loss = \lambda_1 L_{cls} + \lambda_2 L_{obj} + \lambda_2 L_{loc} Loss=λ1Lcls+λ2Lobj+λ2Lloc
- 定位损失,采用的是 CIoU loss,注意只计算正样本的定位损失
5.2. Balance
平衡不同尺度损失
针对三个预测特征层上的 obj 损失采用不同的权重
- P3,小型目标
- P4,中等目标
- P5,大目标
L o b j = 4.0 ⋅ L o b j s m a l l + 1.0 ⋅ L o b j m e d i u m + 0.4 ⋅ L o b j l a r g e L_{obj} = 4.0 \cdot L_{obj}^{small} + 1.0 \cdot L_{obj}^{medium} + 0.4 \cdot L_{obj}^{large} Lobj=4.0⋅Lobjsmall+1.0⋅Lobjmedium+0.4⋅Lobjlarge
6. Comparison
YOLOv5 代码中的四种网络,都是以yaml的形式来呈现。且四个文件的内容基本上都是一样的,只有最上方的 depth_multiple 和 width_multiple 两个参数不同。
6.1. Params
每个网络结构的两个参数:
- YOLOv5s.yaml

- YOLOv5m.yaml
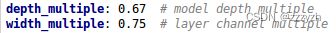
- YOLOv5l.yaml

- YOLOv5x.yaml
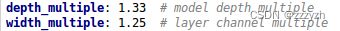
其中 depth_multiple 控制网络的深度,width_multiple 控制网络的宽度
6.2. Structure
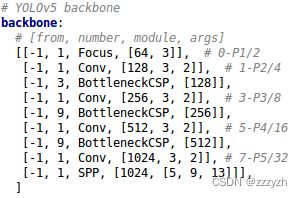
四种结构的yaml文件中,下方的网络架构代码都是一样的。这里我们提出 Backbon 部分,讲解如何控制网络的宽度和深度。
具体使用中:
![]()
上方的代码将四种结构的 depth_multiple,width_multiple 提取出,赋值给gd,gw
6.3. Depth_multiple
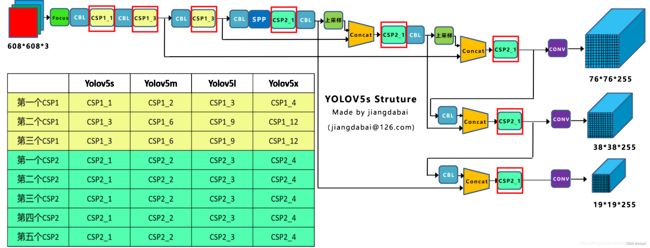
6.3.1. Difference
YOLOv5 有两种CSP结构,CSP1和CSP2,其中CSP1结构主要应用于Backbone中,CSP2结构主要应用于Neck中(需要注意的是,四种网络结构中每个CSP结构的深度都是不同的)
- CSP1_X
- YOLOv5s 在第一个CSP1中,使用了1个残差组件,因此是 CSP1_1
- YOLOv5m 增加了网络的深度,在第一个CSP1中,使用了2个残差组件,因此是 CSP1_2
- YOLOv5l 同样的位置,使用了3个残差组件,因此是 CSP1_3
- YOLOv5x 同样的位置,使用了4个残差组件,因此是 CSP1_4
- CSP2_X
- YOLOv5s 使用了 2 × X = 2 × 1 = 2 2 \times X = 2 \times 1 = 2 2×X=2×1=2 个卷积,因此X=1,所以使用了1组卷积,因此是CSP2_1
- YOLOv5m 使用了2组卷积,因此是CSP2_2
- YOLOv5l 使用了3组卷积,因此是CSP2_3
- YOLOv5x 使用了4组卷积,因此是CSP2_4
6.3.2. Code
控制四种网络结构的核心代码如下所示:
![]()
存在两个变量,n 和 gd。通过将 n 和 gd 带入计算,可以看到每种网络的变化结果
6.3.3. Validity
将 gd (height_multiple) 系数带入

- yolov5s.yaml
- 其中 depth_multiple = 0.33,即 gd = 0.33,而 n 则由上面红色框中的信息获得
- 第一个 CSP1 结构,n 等于第二个数值3,而 gd = 0.33
- 带入 6.3.2. 中的计算代码,得到结果 n = 1
- 因此第一个 CSP1 结构内只有1个残差组件,即 CSP1_1
- 第二个CSP1结构中,n 等于第二个数值9,而 gd = 0.33
- 带入 6.3.2. 中的计算代码,得到结果 n = 3
- 因此第二个CSP1结构中有3个残差组件,即 CSP1_3。
- 第三个残差结构同理
- 其余模型同理
6.4. Width_multiple
6.4.1. Difference
如上图表格中所示,四种 YOLOv5 结构在不同阶段的卷积核的数量都是不一样的,因此也直接影响卷积后特征图的第三维度,即模型的宽度
- 第一个卷积操作
- YOLOv5s 的第一个Focus结构中,最后卷积操作时,卷积核的数量是32个,因此经过Focus结构,特征图的大小变成 304 × 304 × 32 304 \times 304 \times 32 304×304×32
- YOLOv5m 的第一个Focus结构中,最后卷积操作时,卷积核的数量是48个,因此经过Focus结构,特征图的大小变成 304 × 304 × 48 304 \times 304 \times 48 304×304×48
- YOLOv5l 与 YOLOv5x 同理
- 第二个卷积操作
- YOLOv5s 使用了64个卷积核,因此得到的特征图是 152 × 152 × 64 152 \times 152 \times 64 152×152×64
- YOLOv5m 使用了96个卷积核,因此得到的特征图是 152 × 152 × 96 152 \times 152 \times 96 152×152×96
- YOLOv5l 与 YOLOv5x 同理
- 后面三个卷积下采样操作同理
四种不同结构的卷积核的数量不同,这也直接影响网络中比如:CSP1 结构,CSP2 等结构,以及各个普通卷积,卷积操作时的卷积核数量也同步在调整,影响整体网络的计算量
当然卷积核的数量越多,特征图的厚度,即宽度越宽,网络提取特征的学习能力也越强
6.4.2. Code
![]()
![]()
6.4.3. Validity
将 width_multiple 系数带入

- yolov5s.yaml
- width_multiple = 0.5,即gw=0.5
- 第一个卷积下采样
- Focus 结构中下面的卷积操作
- 按照上面 Backbone 的信息,我们知道 Focus 中,标准的 c2 = 64,而 gw = 0.5,代入 6.4.2. 中的计算公式,最后的结果为32
- 即 YOLOv5s 的 Focus 结构中,卷积下采样操作的卷积核数量为32个。
- 第二个卷积下采样
- 标准的 c2 = 128,gw=0.5,代入 6.4.2. 中的计算公式,最后的结果为64
- 后面的卷积下采样与前面的同理
- width_multiple = 0.5,即gw=0.5
- 其余模型同理
总结
添加链接描述
网络参考