OD-Model【7】:YOLOv3
系列文章目录
YOLO目标检测系列(一):
OD-Model【5】:YOLOv1
YOLO目标检测系列(二):
OD-Model【6】:YOLOv2
YOLO目标检测系列(三):
OD-Model【7】:YOLOv3
YOLO目标检测系列(四):
OD-Model【8】:YOLOv4
YOLO目标检测系列(五):
OD-Model【9】:YOLOv5
文章目录
- 系列文章目录
- 前言
- 1. Background
- 2. Model
-
- 2.1. Backbone
- 2.2. YOLOv3 Structure
- 3. The Deal
-
- 3.1. Bounding Box
-
- 3.1.1. Bounding box prior
- 3.1.2. Bounding Box Prediction
- 3.1.3. Matching of positive and negative samples
- 3.2. Output Processing
- 3.3. Loss function
- 4. YOLOv3 - SPP
-
- 4.1. Mosaic Image Enhancement
-
- 4.1.1. Introduction
- 4.1.2. Procedure
- 4.2. SPP Module
- 4.3. CIoU Loss
-
- 4.3.1. IoU Loss
- 4.3.2. GIoU (Generalized Intersection over Union) Loss
- 4.3.3. DIoU (Distance-IoU) Loss
- 4.3.4. CIoU (Complete-IoU) Loss
- 4.4. Focal Loss
-
- 4.4.1. Introduction
- 4.4.2. Focal Loss
- 4.4.3. Balanced Cross Entropy
- 4.4.4. Focal Loss Definition
- 总结
前言
因为原作者写的有关 YOLOv3 的论文十分的“不正经”,所以本文直接对 YOLOv3 的网络结构等内容进行分析,不再翻译有关原文的内容。
本文主要包含 YOLOv3 的基本神经网络框架,以及加入了 SPP 结构之后的神经网络框架。如果仅需要了解 YOLOv3 神经网络的基本框架,仅需要阅读 1-3 章节,如果希望了解可以提升 YOLOv3 网络性能的 Tricks 可以阅读第 4 章节
原论文链接:
YOLOv3: An Incremental Improvement
1. Background
YOLOv3算法使用一个单独神经网络作用在图像上,将图像划分多个区域并且预测边界框和每个区域的概率。
2. Model
2.1. Backbone
YOLOv3 所使用的主干特征提取网络为 Darknet53

- YOLOv3 仅使用卷积层,使其成为一个全卷积网络,可以兼容任意输入尺寸的图像
- 但是必须保证输入的图像的尺寸是32的倍数,因为下采样的倍数是32、16和8
- 取消 Max Pooling 层,通过卷积层的步距设计实现下采样(步距 stride 默认为1)
- 卷积层替代最大池化下采样带来提升的原因:卷积层的参数是可以学习的
- DarkNet-53相比于ResNet的卷积核个数少,训练参数少,所以训练速度更快
- Convolutional 层由3个部分组成
- Conv + BN + Leaky ReLu
- 卷积层无偏置的参数
- Leaky ReLU 与一般 ReLu 的区别:
- 一般的 ReLu 将所有的负值都设为零
- Leaky ReLU 给所有负值赋予一个非零斜率
- Conv + BN + Leaky ReLu
- 具有残差结构
- 首先进行一次卷积核大小为 3 × 3 3 \times 3 3×3、步长为 2 2 2 的卷积,该卷积会压缩输入进来的特征层的宽和高,此时我们可以获得一个特征层
- 然后将该特征层进行一次 1 × 1 1 \times 1 1×1 的卷积和一次 3 × 3 3 \times 3 3×3 的卷积
- 最后将开始得到的特征层的输出,与主分支的输出进行相加得到最终的输出
- 需要注意的是:
- 此时的残差结构并不是额外添加的,而是 Darknet - 53 的一部分卷积层直接构成了 Residual block
- 通过不断的 1 × 1 1 \times 1 1×1 卷积和 3 × 3 3 \times 3 3×3卷积以及残差边的叠加,可以大幅度的加深网络
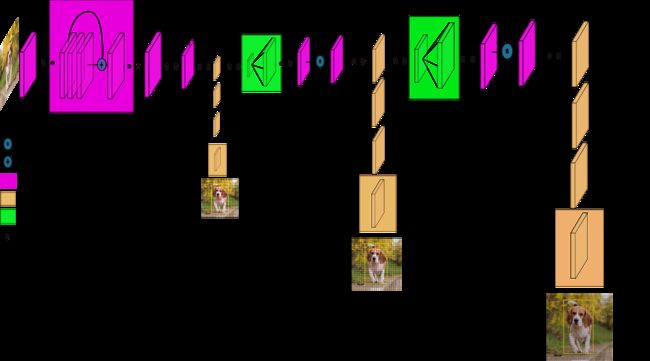
2.2. YOLOv3 Structure

- 去掉全局平均池化层以及全连接层
- 预测特征层
- YOLOv3 借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为 N × N × [ 3 × ( 4 + 1 + 80 ) ] N \times N \times [3 \times (4 + 1 + 80)] N×N×[3×(4+1+80)]
- N × N N \times N N×N:特征图尺寸
- 一共3个 anchor 框,每个 anchor 框有
- 4维预测框数值: t x , t y , t w , t h t_x, t_y, t_w, t_h tx,ty,tw,th
- 1维预测框置信度
- 80维分类物体类别数(COCO数据集)
- YOLOv3 总共输出3种尺寸不同的特征图

- 13 × 13 13 \times 13 13×13
- 下采样32倍
- 对应原图上的感受野为 32 × 32 32 \times 32 32×32,负责预测较大的物体
- 26 × 26 26 \times 26 26×26
- 下采样16倍
- 对应原图上的感受野为 16 × 16 16 \times 16 16×16,负责预测中等大小的物体
- 52 × 52 52 \times 52 52×52
- 下采样8倍
- 对应原图上的感受野为 8 × 8 8 \times 8 8×8,负责预测较小的物体
- 13 × 13 13 \times 13 13×13
- 上采样
- 作用是将小尺寸特征图通过插值等方法,生成大尺寸图像
- 具体有关上采样的内容可以观看我的另一篇博文:SS-Model【1】:FCN
- Concat
- 将特征图按照通道维度直接进行拼接
- YOLOv3 借鉴了金字塔特征图思想,小尺寸特征图用于检测大尺寸物体,而大尺寸特征图检测小尺寸物体。特征图的输出维度为 N × N × [ 3 × ( 4 + 1 + 80 ) ] N \times N \times [3 \times (4 + 1 + 80)] N×N×[3×(4+1+80)]
3. The Deal
3.1. Bounding Box
3.1.1. Bounding box prior
使用 k-means聚类算法 来确定 bounding box,YOLOv3 预测三个不同尺度的 boxes,使用特征金字塔网络来提取这些对于尺度boxes的特征。
Tensor: N × N × [ t y p e s × ( 4 + 1 + c l a s s e s ) ] N \times N \times [types \times (4 + 1 + classes)] N×N×[types×(4+1+classes)]
- N:预测特征层的大小
- types:预测框的种类
- 4 + 1:预测框位置参数 + 置信度
- classes:待分类的目标的个数
3.1.2. Bounding Box Prediction
YOLOv3 采用直接预测相对位置的方法。预测出 b-box 中心点相对于网格单元左上角的相对坐标。直接预测出 ( t x , t y , t w , t h , t o ) (t_x, t_y, t_w, t_h, t_o) (tx,ty,tw,th,to),然后通过以下坐标偏移公式计算得到 b-box 的位置大小和 confidence。
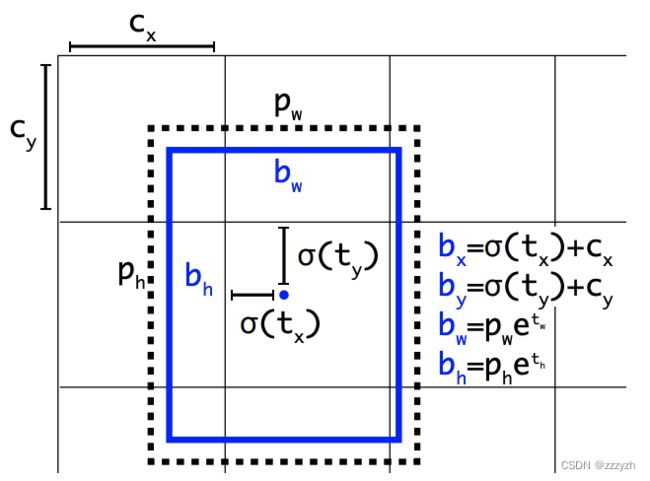
网络在输出的 feature map 中预测每个单元格的5个边界框。网络预测每个边界框的 5 个坐标,即相对于 anchor 的偏移量, t x t_x tx, t y t_y ty, t w t_w tw, t h t_h th 和 t o t_o to。如果单元格从图像的左上角偏移 ( c x , c y ) (c_x, c_y) (cx,cy) 并且前面的 anchor 具有宽度和高度 p w p_w pw, p h p_h ph,则预测对应于:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) + c_y \\ b_w = p_w e^{t_w} \\ b_h = p_h e^{t_h} \\ Pr(object) * IOU(b, object) = \sigma(t_o) bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)
注: P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) Pr(object) * IOU(b, object) = \sigma(t_o) Pr(object)∗IOU(b,object)=σ(to) 表示框中含有object的置信度和这个box预测的有多准。也就是说,如果这个框对应的是背景,那么这个值应该是 0,如果这个框对应的是前景,那么这个值应该是与对应前景 GT box 的IoU
参数解析:
- c x c_x cx:grid cell 左上角x坐标
- c y c_y cy:grid cell 左上角y坐标
- p w p_w pw:anchor 宽度
- p h p_h ph:anchor 高度
- b x b_x bx:预测框x坐标
- b y b_y by:预测框y坐标
- b w b_w bw:预测框宽度
- b h b_h bh:预测框高度
- σ \sigma σ:即 sigmoid 函数,将值限定在 ( 0 , 1 ) (0, 1) (0,1),因为要将 anchor 的中心限定在 grid cell 中,而每个 grid cell 的边框长度都是1
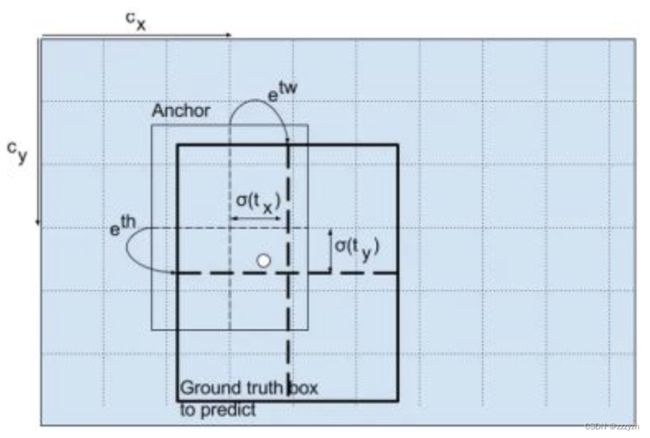
3.1.3. Matching of positive and negative samples
- 正样本
- 任取一个 GT box,与上面计算的 10647 个框全部计算 IOU,IOU 最大的预测框,即为样本。并且一个预测框, 只能分配给一个 GT box。
- 有几个 GT box,就有几个正样本
- 例如第一个 GT box 已经匹配了一个正例检测框,那么下一个 GT box,就在余下的 10646 个检测框中,寻找 IOU 最大的检测框作为正例。
- 在 YOLOv3 的训练策略中,不再像 YOLOv1 那样,每个cell负责中心落在该cell中的 GT box。
- 原因是 YOLOv3 一共产生3个特征图,3个特征图上的cell,中心是有重合的。训练时,可能最契合的是特征图1的第3个box,但是推理的时候特征图2的第1个box置信度最高。
- 所以 YOLOv3 的训练,不再按照 GT box 中心点严格分配指定cell,而是根据预测值寻找 IOU 最大的预测框作为正例。
- 任取一个 GT box,与上面计算的 10647 个框全部计算 IOU,IOU 最大的预测框,即为样本。并且一个预测框, 只能分配给一个 GT box。
- 忽略样本
- 除正样本外,对于与任意一个 GT box 的 IOU 大于阈值的先验框,为忽略样本,丢弃该预测结果。
- 忽略样本产生的原因是 YOLOv3 采用了多尺度检测,在检测时会有重复检测现象
- 比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。
- 负样本
- 除正样本外,对于与任意一个 GT box 的 IOU 小于阈值的先验框,为负样本
- 与 YOLOv3 计算后IOU最大的检测框,即使 IOU 小于阈值,仍为正样本
- 即如果一个先验框没有分配给任意一个 GT box 的话,为负样本
- 除正样本外,对于与任意一个 GT box 的 IOU 小于阈值的先验框,为负样本

- 阈值: I O U > 0.3 IOU > 0.3 IOU>0.3
- 黑色圆点:GT box 中心点
- 预测在哪个 grid cell 中,其对应的 anchor template 就为正样本
- 如果3个 anchor template 的 IOU 都大于阈值,这个 grid cell 当中对应的3个 anchor template 都会被视为正样本
- 可以起到扩充正样本数量的作用
3.2. Output Processing
- 解决措施
- 通过物体分数过滤一些锚框,低于阈值的 anchor 直接舍去
- 使用NMS(非极大值抑制)解决多个锚框检测一个物体的问题(3个 anchor 检测一个框或者连续的 grid cell 检测相同的物体,产生冗余),NMS用于去除多个检测框。
- 使用步骤
- 抛弃分数低的框(意味着框对于检测一个类信心不大)
- 当多个框重合度高且都检测同一个物体时只选择一个框(NMS)。
- 例子:选用下图的汽车图像
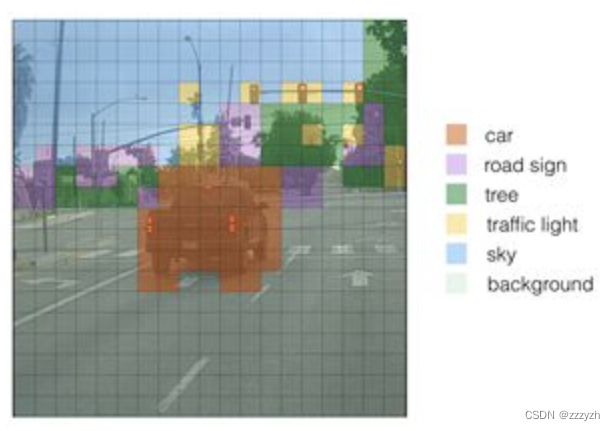
- 使用阈值进行过滤一部分锚框
- 模型有 19 × 19 × 3 × 85 19 \times 19 \times 3 \times 85 19×19×3×85 个数,每个盒子由85个数字描述。将 ( 19 , 19 , 3 , 85 ) (19, 19, 3, 85) (19,19,3,85) 分割为下面的形状:
- box_confidence: ( 19 , 19 , 3 , 1 ) (19, 19, 3, 1) (19,19,3,1) 表示 19 × 19 19 \times 19 19×19 个cell,每个cell的 3个框,每个框有物体的置信度概率;
- boxes: ( 19 , 19 , 3 , 4 ) (19, 19, 3, 4) (19,19,3,4) 表示每个cell 的3个框,每个框的表示;
- box_class_probs: ( 19 , 19 , 3 , 80 ) (19, 19, 3, 80) (19,19,3,80) 表示每个cell的3个框,每个框80个类检测概率。
- 每个锚框我们计算下面的元素级乘法并且得到锚框包含一个物体类的概率,如下图:
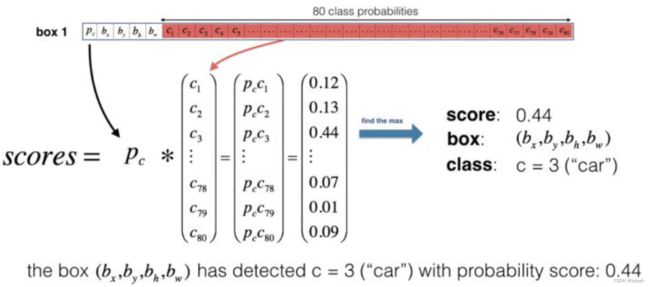
- 即使通过类分数阈值过滤一部分锚框,还剩下很多重合的框。
- 模型有 19 × 19 × 3 × 85 19 \times 19 \times 3 \times 85 19×19×3×85 个数,每个盒子由85个数字描述。将 ( 19 , 19 , 3 , 85 ) (19, 19, 3, 85) (19,19,3,85) 分割为下面的形状:
- 使用NMS(非极大值抑制)
- IOU

- 使用步骤:
- 选择一个最高分数的框;
- 计算它和其他框的重合度,去除重合度超过IoU阈值的框;
- 回到第一步迭代直到没有比当前所选框低的框。

- IOU
- 使用阈值进行过滤一部分锚框
3.3. Loss function

- λ 1 , λ 2 , λ 3 \lambda_1, \lambda_2, \lambda_3 λ1,λ2,λ3 为平衡系数,控制三个损失之间的比例
- 置信度损失
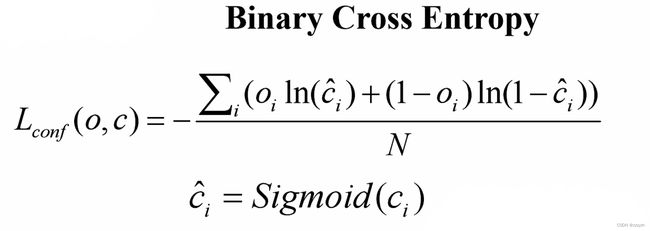
- 其中 o i ∈ [ 0 , 1 ] o_i \in [0, 1] oi∈[0,1],表示预测目标边界框与真实目标边界框的 IOU
- 计算IOU

- 蓝色框:anchor
- 绿色框:GT box(真实目标边界框)
- 黄色框:通过预测目标边界框偏移量,应用到anchor上,得到的预测目标边界框
- 也可以直接取 { 0 , 1 } \{ 0, 1 \} {0,1} (原论文中使用的方法)
- 计算IOU
- c c c 为预测值, c ^ i \hat{c}_i c^i 为 c c c 通过 S i g m o i d Sigmoid Sigmoid 函数得到的预测置信度
- N N N 为正负样本个数
- 其中 o i ∈ [ 0 , 1 ] o_i \in [0, 1] oi∈[0,1],表示预测目标边界框与真实目标边界框的 IOU
- 分类损失

- 其中 O i j ∈ { 0 , 1 } O_{ij} \in \{ 0, 1 \} Oij∈{0,1},表示预测预测目标边界框 i i i中是否存在第 j j j类目标
- C i j C_{ij} Cij 为预测值, C i j ^ \hat{C_{ij}} Cij^ 为 C i j C_{ij} Cij 通过 S i g m o i d Sigmoid Sigmoid 函数得到的目标概率
- N p o s N_{pos} Npos 为正样本个数
- 例子:分类 [老虎,豹子,猫]

- 真实标签
- 目标1:[0., 0., 1.]
- 目标2:[0., 0., 1.]
- 预测标签
- 目标1:[0.1, 0.8, 0.9]
- 目标2:[0.2, 0.7, 0.8]
- 使用Sigmoid处理
- 如果是 softmax,每个类别的概率之后为1
- 对于这里使用的 binary,对于每个类别经过 sigmoid 函数进行处理,每个预测值之间相互独立
- 真实标签
- 定位损失

4. YOLOv3 - SPP

p.s. 图源自b站up主霹雳吧啦Wz
4.1. Mosaic Image Enhancement
4.1.1. Introduction
Mosaic 图像增强算法将多张图片按照一定比例组合成一张图片,使模型在更小的范围内识别目标。
方法优点:
- 增加数据多样性
- 随机选取四张图像进行组合,组合得到图像个数比原图个数要多。
- 增强模型鲁棒性
- 混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
- 加强批归一化层(Batch Normalization)的效果
- 当模型设置 BN 操作后,训练时会尽可能增大批样本总量(BatchSize),因为 BN 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
- 比如输入一张由四张图像拼接的图像等效并行输入四张(batch_size = 4)原始图像
- Mosaic 数据增强算法有利于提升小目标检测性能
- Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标。
4.1.2. Procedure
- 随机选取图片拼接基准点坐标 x c , y c x_c, y_c xc,yc,另随机选取四张图片。
- 分别对四张图片进行数据增广操作,并分别粘贴至与最终输出图像大小相等掩模的对应位置。
- 翻转(对原始图片进行左右的翻转)
- 缩放(对原始图片进行大小的缩放);
- 色域变化(对原始图片的明亮度、饱和度、色调进行改变)等操作。
- 设置最小偏移参数
- 进行图片的组合和框的组合
- 根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
- 依据指定的横纵坐标,对大图进行拼接。
- 处理超过边界的检测框坐标。
4.2. SPP Module
注意:这里的 SPP 和 SPPnet 中的 SPP 结构不一样
实现了不同尺度的特征融合
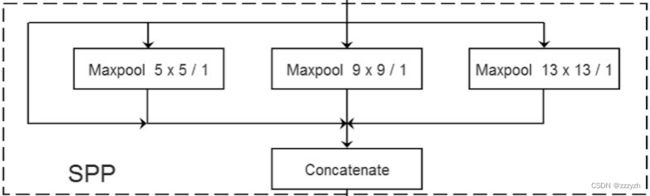
输出由四部分组成:
- 输入直接连接到输出
- 池化核大小为 5 × 5 5 \times 5 5×5,步长为 1 的最大池化下采样
- 池化核大小为 9 × 9 9 \times 9 9×9,步长为 1 的最大池化下采样
- 池化核大小为 13 × 13 13 \times 13 13×13,步长为 1 的最大池化下采样
- 需要注意的是,因为这里的步长均为 1,所以在进行池化操作之前,需要对特征矩阵进行 padding填充
- 输出的特征矩阵的高和宽与输入的相同,深度变为原来的 4 倍
- 上面 4 步操作最后需要进行 Concatenate 操作(在深度方向进行拼接),所以需要使用padding来保证每一次池化之后的特征矩阵与原矩阵的高和宽相同
在多个预测特征图之前都加上 SPP 模块,提升不大,且推理速度降低。所以在 YOLOv3 网络中添加一个 SPP 模块即可
4.3. CIoU Loss
4.3.1. IoU Loss
IoU 就是我们所说的交并比,是目标检测中最常用的指标
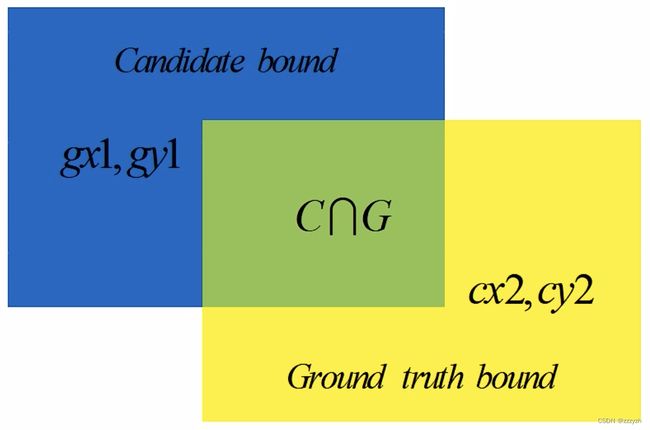
在 anchor-based 的方法中,他的作用不仅用来确定正样本和负样本,还可以用来评价输出框(predict box)和 ground-truth 的距离。
I o U = a r e a ( C ) ⋂ a r e a ( G ) a r e a ( C ) ⋃ a r e a ( G ) IoU = \frac{area(C) \bigcap area(G)}{area(C) \bigcup area(G)} IoU=area(C)⋃area(G)area(C)⋂area(G)
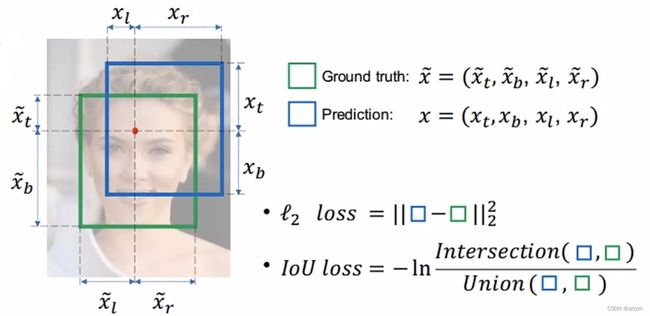
I o U l o s s = − l n I n t e r s e c t i o n ( b l u e , g r e e n ) U n i o n ( b l u e , g r e e n ) I o U l o s s = 1 − I o U IoU \ loss = -ln\frac{Intersection(blue, green)}{Union(blue, green)} \\ IoU \ loss = 1 - IoU IoU loss=−lnUnion(blue,green)Intersection(blue,green)IoU loss=1−IoU
与 l 2 l o s s l_2 \ loss l2 loss 相比:
- 优点
- 能够更好的反应重合程度
- 具有尺度不变性
- 缺点
- 当不相交时 loss 为 0
- IoU无法精确的反映两者的重合度大小。

- 由上图我们可以发现,三组的损失相同,IoU不同,这种 l 2 l_2 l2 损失计算方式不能很好的反应边界框的重合程度。
4.3.2. GIoU (Generalized Intersection over Union) Loss
由于IoU是比值的概念,对目标物体的 scale 是不敏感的。然而检测任务中的 BBox 的回归损失(MSE loss, l1-smooth loss等)优化和IoU优化不是完全等价的,而且 Ln 范数对物体的 scale 也比较敏感,IoU无法直接优化没有重叠的部分。
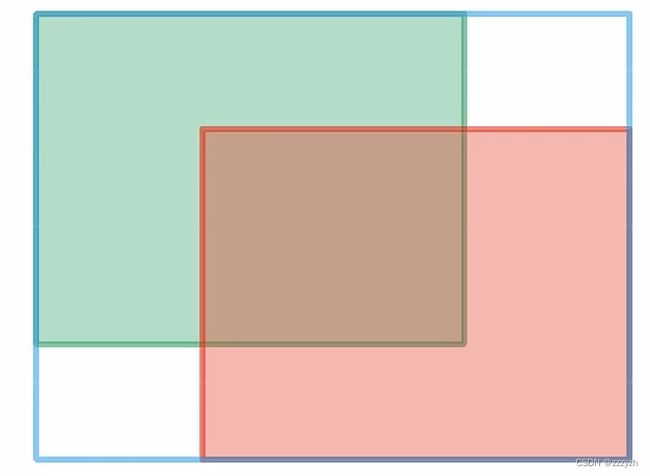
G I o U = I o U − A c − u A c − 1 ≤ G I o U ≤ 1 GIoU = IoU - \frac{A^c - u}{A^c} \ \ \ -1 \le GIoU \le 1 GIoU=IoU−AcAc−u −1≤GIoU≤1
- 参数解析
- 绿色目标边界框:真实目标边界框
- 红色目标边界框:网络中预测的目标边界框
- 蓝色目标边界框:能框住绿色目标边界框与红色目标边界框的最小矩形,即 A c A^c Ac
- u u u,即两个目标边界框并集的面积
- 取值范围
- 1
- 真实目标边界框与网络中预测的目标边界框重合
- -1
- 真实目标边界框与网络中预测的目标边界框相距无穷远,此时 IoU 的值为0
- 也就是说,当我们的两个目标边界框不相交的时候,也能计算损失,进行误差的反向传播
- 1
损失计算:
L G I o U = 1 − G I o U 0 ≤ G I o U ≤ 2 L_{GIoU} = 1 - GIoU \ \ \ 0 \le GIoU \le 2 LGIoU=1−GIoU 0≤GIoU≤2
与 IoU 相比
- 优点
- 与IoU只关注重叠区域不同,GIoU不仅关注重叠区域,还关注其他的非重合区域,能更好的反映两者的重合度。
- 缺点
- GIoU对scale不敏感
- GIoU 退化成 IoU

- 如果真实目标边界框与网络中预测的目标边界框高度和宽度一样,并处于水平或垂直相交的情况,GIoU 退化成 IoU
4.3.3. DIoU (Distance-IoU) Loss
DIoU要比GIou更加符合目标框回归的机制,将目标与anchor之间的距离,重叠率以及尺度都考虑进去,使得目标框回归变得更加稳定,不会像IoU和GIoU一样出现训练过程中发散等问题。
基于IoU和GIoU存在的问题,提出DIoU的作者在论文中提出两个问题:
- 直接最小化anchor框与目标框之间的归一化距离是否可行,以达到更快的收敛速度
- 如何使回归在与目标框有重叠甚至包含时更准确、更快
使用 GIoU 与 DIoU 训练网络

- 参数
- 黑色边界框:anchor、default box
- 绿色边界框:真实边界框
- 蓝色边界框:预测边界框
- 目标:通过训练,将蓝色的预测目标边界框与真实边界框重合
- 第一行使用 GIoU 训练网络
- 第二行使用 DIoU 训练网络
- 速度更快,效果更好

DIoU 相比 GIoU 和 IoU,能更好地辨别边界框重合的情况
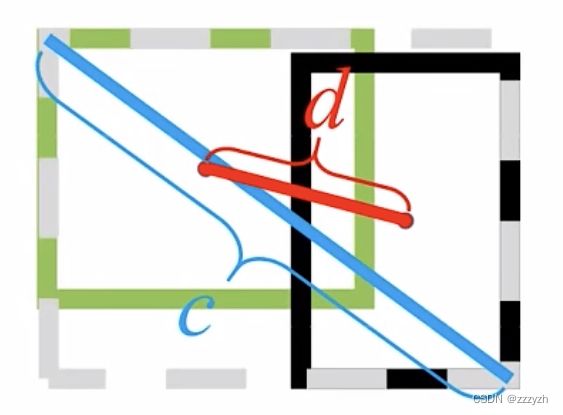
D I o U = I o U − ρ 2 ( b , b g t ) c 2 = I o U − d 2 c 2 − 1 ≤ D I o U ≤ 1 DIoU = IoU - \frac{\rho^2(b, b^{gt})}{c^2} = IoU - \frac{d^2}{c^2} \ \ \ \ \ -1 \le DIoU \le 1 DIoU=IoU−c2ρ2(b,bgt)=IoU−c2d2 −1≤DIoU≤1
- 参数:
- ρ \rho ρ: b b b 与 b g t b^{gt} bgt 之间的欧式距离
- b b b:预测目标边界框的中心坐标
- b g t b^{gt} bgt:真实目标边界框的中心点坐标
- 取值范围:
- 1
- 预测目标边界框与真实目标边界框完美重合时
- -1
- 预测目标边界框与真实目标边界框相距无穷远时
- 1
损失计算:
L D I o U = 1 − D I o U 0 ≤ D I o U ≤ 2 L_{DIoU} = 1 - DIoU \ \ \ 0 \le DIoU \le 2 LDIoU=1−DIoU 0≤DIoU≤2
优点:
- 与GIoU loss类似,DIoU loss 在与目标框不重叠时,仍然可以为边界框提供移动方向
- DIoU loss 可以直接最小化两个目标框的距离,因此比 GIoU loss 收敛快得多
- 对于包含两个框在水平方向和垂直方向上这种情况,DIoU 损失可以使回归非常快,而 GIoU损失几乎退化为 IoU 损失
- DIoU 还可以替换普通的 IoU 评价策略,应用于 NMS 中,使得 NMS 得到的结果更加合理和有效
4.3.4. CIoU (Complete-IoU) Loss
一个优秀的回归定位损失应该考虑到 3 种几何参数:重叠面积、中心点距离、长宽比
考虑到bbox回归三要素中的长宽比还没被考虑到计算中,因此,进一步在DIoU的基础上提出了CIoU。其惩罚项如下面公式:
R C I o U = ρ 2 ( b , b g t ) c 2 + α υ R_{CIoU} = \frac{\rho^2(b, b^{gt})}{c^2} + \alpha \upsilon RCIoU=c2ρ2(b,bgt)+αυ
而 υ \upsilon υ 用来度量长宽比的相似性,定义为:
υ = 4 π 2 ( a r c t a n w g t h g t − a r c t a n w h ) 2 \upsilon = \frac{4}{\pi^2}(arctan\frac{w^{gt}}{h^{gt}} - arctan\frac{w}{h})^2 υ=π24(arctanhgtwgt−arctanhw)2
α = υ ( 1 − I o U ) + υ \alpha = \frac{\upsilon}{(1-IoU) + \upsilon} α=(1−IoU)+υυ
所以完整的 CIoU 的计算公式为:
C I o U = I o U − R C I o U = I o U − ( ρ 2 ( b , b g t ) c 2 + α υ ) CIoU = IoU - R_{CIoU} = IoU - (\frac{\rho^2(b, b^{gt})}{c^2} + \alpha \upsilon) CIoU=IoU−RCIoU=IoU−(c2ρ2(b,bgt)+αυ)
损失计算:
L C I o U = 1 − C I o U L_{CIoU} = 1 - CIoU LCIoU=1−CIoU
需要注意的是:当长宽在范围 [ 0 , 1 ] [0, 1] [0,1]之间的情况下, w 2 + h 2 w^2 + h^2 w2+h2 的值通常很小,会导致梯度爆炸,因此需要在实现时将 1 w 2 + h 2 \frac{1}{w^2 + h^2} w2+h21 替换成1。
4.4. Focal Loss
4.4.1. Introduction
主要针对 one-stage 目标检测模型,而 one-stage 目标检测模型大多都面临 class imbalance 的问题,即正负样本不平衡
一张图像中能够匹配到目标的候选框(正样本)个数一般只有十几个或几十个,而没有匹配到的候选框(负样本)大概有 1 0 4 10^4 104 - 1 0 5 10^5 105 个。在这 1 0 4 10^4 104 - 1 0 5 10^5 105 个未匹配到目标的候选框中大部分都是简单易分的负样本(对训练网络起不到什么作用,但由于数量太多会淹没掉少量但是有助于训练的样本
4.4.2. Focal Loss
在分类损失中最经典的损失函数为标准交叉熵,以二分类为例可以写为:
C E ( p , y ) = { − l o g ( p ) i f y = 1 − l o g ( 1 − p ) o t h e r w i s e CE(p, y) = \begin{cases} -log(p) & if \ y = 1 \\ -log(1-p) & otherwise \end{cases} CE(p,y)={−log(p)−log(1−p)if y=1otherwise
其中 y ∈ { ± 1 } y \in \{ \pm 1 \} y∈{±1}, p ∈ [ 0 , 1 ] p \in [0, 1] p∈[0,1] 是判断是正样本 ( y = 1 ) (y = 1) (y=1) 的概率,为了统一,我们定义函数 p t p_t pt
p t = { p i f y = 1 1 − p o t h e r w i s e p_t = \begin{cases} p & if \ y = 1 \\ 1-p & otherwise \end{cases} pt={p1−pif y=1otherwise
于是可以得到 C E ( p , y ) = C E ( p t ) = − l o g ( p t ) CE(p, y) = CE(p_t) = -log(p_t) CE(p,y)=CE(pt)=−log(pt)
但是这种损失函数在处理类不均衡问题时非常糟糕,会因为某类的冗余,而主导损失函数,使模型失去效果。
4.4.3. Balanced Cross Entropy
为了解决类不平衡问题,常见的做法是添加权重因子,即平衡交叉熵。在 α ∈ [ 0 , 1 ] \alpha \in [0, 1] α∈[0,1] 的前提下,对 class 1 添加 α \alpha α,对 class -1 添加 1 − α 1- \alpha 1−α。为了形式上的方便,我们定义 α t \alpha_t αt,从而得到:
C E ( p t ) = − α t l o g ( p t ) CE(p_t) = -\alpha_t log(p_t) CE(pt)=−αtlog(pt)
需要注意的是, α \alpha α 只是平衡正负样本的超参数,而不是正负样本之间的比例
但是,当我们处理大量负样本、少量正样本的情况时,即使我们把负样本的权重设置的很低,但是因为负样本的数量太多,积少成多,负样本的损失函数也会主导损失函数。
4.4.4. Focal Loss Definition
上面提到的超参数 α \alpha α,仅能平衡正负样本的权重,但是并不能区分容易的样本与困难的样本。为此,我们引入新的损失函数,以降低简单样本的权重,聚焦于训练难以分辨的负样本。 ( 1 − p t ) γ (1 - p_t)^\gamma (1−pt)γ 能够降低易分样本的损失贡献。
F L ( p t ) = − ( 1 − p t ) γ l o g ( p t ) FL(p_t) = -(1 - p_t)^\gamma log(p_t) FL(pt)=−(1−pt)γlog(pt)

将平衡交叉熵和 focal loss 两者混合就可以得到 focal loss 的 α \alpha α 变体,即
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) FL(p_t) = -\alpha_t (1 - p_t)^\gamma log(p_t) FL(pt)=−αt(1−pt)γlog(pt)
展开形式为
F L ( p ) = { − α ( 1 − p t ) γ l o g ( p ) i f y = 1 − ( 1 − α ) p γ l o g ( 1 − p ) o t h e r w i s e FL(p) = \begin{cases} -\alpha(1 - p_t)^\gamma log(p) & if \ y = 1 \\ -(1 - \alpha) p^\gamma log(1- p) & otherwise \end{cases} FL(p)={−α(1−pt)γlog(p)−(1−α)pγlog(1−p)if y=1otherwise
总结
- YOLOv3网络优点:
- 相比于 YOLOv2 网络,在保持速度优势的前提下,提升了预测精度,尤其是加强了对小物体的识别能力 。
- YOLOv3对相对于 v1 和 v2 的改进
- 使用了 Darknet-53 骨干网络,有更好的特征提取能力,增强了对于小物体的检测能力
- 设置了三种不同规格的 anchor,三种 scale,每种分配三种不同尺度的 anchor
- 使用了不同特征融合,融合不同尺度的特征,增加模型对不同尺度物体的检测
- 对于 softmax 进行改进,将多分类任务分解为多个二分类进行判断(sigmoid)
内容参考
内容参考