大数据入门学习?
第一部分:了解大数据平台架构
大数据有非常大的价值,不管是从帮助企业创造营收还是从提高效率、节省企业成本角度。大数据要是做好了,将会是一个企业增长的发动机,推动业务突飞猛进的发展。要实现大数据的价值,真正让大数据为企业创造贡献,首先必须要积累有大数据,把日常的业务和用户行为数据收集起来。有些数据是可再生资源,但更多的数据是不可再生资源,这就需要我们搭建一个平台负责数据的采集、规整、运算、存储、应用、展现等,有了这样一个大数据平台,我们才能做好数据的积累,从小数据到大数据,数据是企业的资产,好的数据是企业的优质资产。大数据平台该怎样搭建呢?请看下面这幅图,不管我之前在阿里还是在腾讯工作,还是到哪个企业工作,基本上我都是通过这幅图进行一些简单的适应企业的调整,就可以完全搬过来使用了。
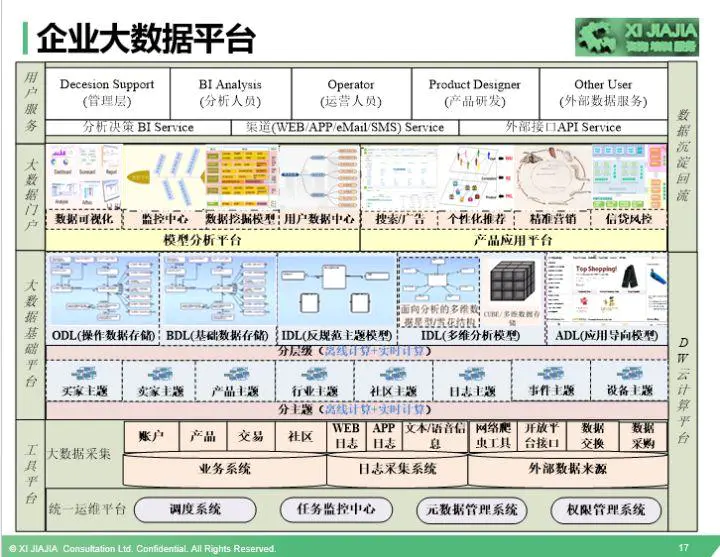
针对上面这幅图,有几点跟大家讲解说明下:
1)大数据平台由三个平台+一个服务组成:工具平台,大数据仓库基础平台、大数据门户,其中,工具平台又包含运维平台和数据采集平台,大数据门户又包含大数据分析平台和大数据产品应用平台。
想成为云计算大数据Spark高手,看这里!戳我阅读
年薪50W的Java程序员转大数据学习路线戳我阅读
大数据人工智能发展趋势与前景 戳我阅读
最全最新的大数据系统交流路径!!戳我阅读
2019最新!大数据工程师就业薪资,让人惊艳!戳我阅读
2)讲讲每个平台的作用。
运维平台主要负责整个大数据平台的任务调度、任务监控、元数据管理、权限管理等,分别由调度系统、任务监控中心、元数据管理系统、权限管理系统等系统组成。
大数据采集平台主要负责把数据采集到大数据仓库平台中。企业的大数据来源从大的角度来说,主要是从三个方面获取数据,业务系统、行为日志采集系统、外部数据来源。每一个方面来源又包含途径,大家可以看上面的图就了解。这里特别要强调的是外部数据来源,可以通过网络爬虫工具收集,通过和相应的合作方进行数据交换,通过从数据商那里采购过来,也有极少部分可以通过一些大公司的开放平台接口获取,比如阿里、腾讯等。
大数据基础平台,在传统的关系数据库时代,这个平台也是企业必须要做的平台,只不过当时叫数据仓库系统,在大数据时代,我称作为大数据仓库基础平台。这部分是整个大数据平台的核心。我们接下来会详细讨论。
大数据门户,是数据成果的集成一体化平台,包含大数据分析平台和数据应用平台。大数据门户作为整个数据部门的窗口,所有数据研究成果都会展现在数据门户中,极大的方便了企业各层级、各职能人员使用数据。我们接下来也将会详细讨论下这部分内容。
用户服务,使用我们数据的人主要有公司的各层级的管理人员、数据分析人员、运营人员、产品经理、技术研发工程师、企业的投资相关方,还可能有部分的公司提供对外的数据服务。提供服务的方式有多种多样,或通过大数据门户、或通过API接口、或是直接在分析报告中体现。
第二部分:掌握大数据常用工具组件
hadoop和Spark是两种不同的大数据处理框架,他们的组件都非常多,往往也不容易学,我把他们两者整理在一幅图中,给大家一个全貌的感觉。初学者可以针对如下图中的组件,逐个的去研究攻破。至于各组件的详细介绍、相关联系和区别,以及它们在大数据平台建设中的具体实施关注点,待点赞数达到1000,我再对帖子进行详细的更新,请大家随手帮忙点个赞。

以上这些大数据组件是日常大数据工作中经常会碰到的,每个组件大概的功能,我已经在图中做了标识。下面,针对这幅图我给大家两点重要提示:
a.蓝色部分,是Hadoop生态系统组件,黄色部分是Spark生态组件,虽然他们是两种不同的大数据处理框架,但它们不是互斥的,Spark与hadoop 中的MapReduce是一种相互共生的关系。Hadoop提供了Spark许多没有的功能,比如分布式文件系统,而Spark 提供了实时内存计算,速度非常快。有一点大家要注意,Spark并不是一定要依附于Hadoop才能生存,除了Hadoop的HDFS,还可以基于其他的云平台,当然啦,大家一致认为Spark与Hadoop配合默契最好摆了。
b.技术趋势:Spark在崛起,hadoop和Storm中的一些组件在消退。大家在学习使用相关技术的时候,记得与时俱进掌握好新的趋势、新的替代技术,以保持自己的职业竞争力。
HSQL未来可能会被Spark SQL替代,现在很多企业都是HIVE SQL和Spark SQL两种工具共存,当Spark SQL逐步成熟的时候,就有可能替换HSQL;
MapReduce也有可能被Spark 替换,趋势是这样,但目前Spark还不够成熟稳定,还有比较长的路要走;
Hadoop中的算法库Mahout正被Spark中的算法库MLib所替代,为了不落后,大家注意去学习Mlib算法库;
Storm会被Spark Streaming替换吗?在这里,Storm虽然不是hadoop生态中的一员,但我仍然想把它放在一起做过比较。由于Spark和hadoop天衣无缝的结合,Spark在逐步的走向成熟和稳定,其生态组件也在逐步的完善,是冉冉升起的新星,我相信Storm会逐步被挤压而走向衰退。
第三部分:关于自学与培训
入门学习大数据,一个方面可以通过自学,另一个方面可以通过参加培训机构的培训,但是,参加培训是否真有用吗?对于哪些人适用参加培训?请看我的分享:
对于学习大数据的同学来说,参加培训肯定是有用的,这毫无疑问。关键在于作用的大小,选择的培训机构,是不是值得你耗费时间和金钱去参加培训。什么情况下,参加培训可以发挥最大的价值呢?我有3点建议,供大家参考:
第一点,自己开始学大数据,但是真的找不到门路,不知道从何入手,不知道该安装哪些大数据软件工具、怎样配置一套学习环境的时候。当然,这一点也可以通过咨询专家解决;
第二点,自己有一定大数据基础,日常学习中,碰到各种问题,一个人摸索,效率较低,希望创建一个多人学习交流的环境,结交更多的大数据同学,以加快速度学习成长的时候。
第三点,家庭环境比较好,或者是工作了几年的同学,在培训费上面比较容易接受,可以参加培训加快自己的成长。
总而言之,参加大数据培训就是以金钱换取时间(快速成长,快速入门)和空间(创造更好的多人学习交流环境),能否发挥更大的价值,就要看个人的情况和选择怎样的培训机构了。一个好的培训机构不仅能够让你快速的学到大数据方面的知识,更是锻炼了你的项目实战能力,让你快速找到一份满意的大数据工作,让你顺利进入到大数据领域工作,开展你的大数据职业生涯。既然培训机构这么重要,我们该如何选择呢?大家知道,培训机构不仅有线下的培训机构,更有众多的线上教育平台,那么该如何选择呢?
首先,我们比较下他们之间的优劣势:
线上教育平台,资源众多,我们可以以比较低成本甚至免费就能获取到物美价廉的教程,学习时间上我们也比较好控制,随时可分配自己的学习时间,对于有一定基础的同学来说,会是一个非常好的选择;
线下培训机构,由于受空间和时间的限制,学员必须在指定时间指定地点完成学习,培训机构提供了练习测试的环境、提供了训练数据,也有老师给学员做指导,更有同学之间的交流切磋,对于有充分时间的零基础学员来说,通过强迫集中式学习,会更容易入门上手。
其次,不管选择线上培训课程还是线下培训机构,核心点就是要扬长避短,充分利用他们之间的优势,如果自己能够在电脑上配置一套测试练习环境、找到一门适合自己的线上优质课程,那么线上课程也一样能收到很好的效果。