机器学习_TF-IDF逆文本频率指数
1. 原理
TF-IDF(term frequency–inverse document frequency)是信息处理和数据挖掘的重要算法,它属于统计类方法。最常见的用法是寻找一篇文章的关键词。
其公式如下:
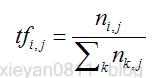
TF(词频)是某个词在这篇文章中出现的频率,频率越高越可能是关键字。它具体的计算方法如上面公式所示:某关键在文章中出现的次数除以该文章中所有词的个数,其中的i是词索引号,j是文章的索引号,k是文件中出现的所有词。
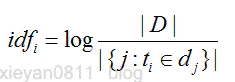
IDF(逆向文档频率)是这个词出现在其它文章的频率,它具体的计算方法如上式所示:其中分子是文章总数,分母是包含该关键字的文章数目,如果包含该关键字的文件数为0,则分子为0,为解决此问题,分母计算时常常加1。当关键字,如“的”,在大多数文章中都出现,计算出的idf值算小。
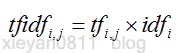
把TF和IDF相乘,就是这个词在该文章中的重要程度。
2. 使用Sklearn提供的TF-IDF方法
Sklearn是最常用的机器学习第三方模型,它也支持对TF-IDF算法。
本例中,先使用Jieba工具分词,并模仿英文句子,将其组装成以空格分割的字符串。
01 import jieba
02 import pandas as pd
03 from sklearn.feature_extraction.text import CountVectorizer
04 from sklearn.feature_extraction.text import TfidfTransformer
05
06 arr = ['第一天我参观了美术馆',
07 '第二天我参观了博物馆',
08 '第三天我参观了动物园',]
09
10 arr = [' '.join(jieba.lcut(i)) for i in arr] # 分词
11 print(arr)
12 # 返回结果:(谢彦的技术博客)
13 ['第一天 我 参观 了 美术馆', '第二天 我 参观 了 博物馆', '第三天 我 参观 了 动物园']
然后使用sklearn提供的CountVectorizer工具将句子列表转换成词频矩阵,并将其组装成DataFrame。
01 vectorizer = CountVectorizer()
02 X = vectorizer.fit_transform(arr)
03 word = vectorizer.get_feature_names()
04 df = pd.DataFrame(X.toarray(), columns=word)
05 print(df)
06 # 返回结果:(谢彦的技术博客)
07 # 动物园 博物馆 参观 第一天 第三天 第二天 美术馆
08 # 0 0 0 1 1 0 0 1
09 # 1 0 1 1 0 0 1 0
10 # 2 1 0 1 0 1 0 0
其方法get_feature_names返回数据中包含的所有词,需要注意的是它去掉了长度为1的单个词,且重复的词只保留一个。X.toarray()返回了词频数组,组合后生成了包含关键词的字段,这些操作相当于对中文切分后做OneHot展开。每条记录对应列表中的一个句子,如第一句“第一天我参观了美术馆”,其关键字“参观”、“第一天”、“美术馆”被置为1,其它关键字置0。
接下来使用TfidfTransformer方法计算每个关键词的TF-IDF值,值越大,该词在它所在的句子中越重要:
01 transformer = TfidfTransformer()
02 tfidf = transformer.fit_transform(X)
03 weight = tfidf.toarray()
04 for i in range(len(weight)): # 访问每一句
05 print("第{}句:".format(i))
06 for j in range(len(word)): # 访问每个词
07 if weight[i][j] > 0.05: # 只显示重要关键字
08 print(word[j],round(weight[i][j],2)) # 保留两位小数
09 # 返回结果 (谢彦的技术博客)
10 # 第0句:美术馆 0.65 参观 0.39 第一天 0.65
11 # 第1句:博物馆 0.65 参观 0.39 第二天 0.65
12 # 第2句:动物园 0.65 参观 0.39 第三天 0.65
经过对数据X的计算之后,返回了权重矩阵,句中的每个词都只在该句中出现了一次,因此其TF值相等,由于“参观”在三句中都出现了,其IDF较其它关键字更低。细心的读者可以发现,其TF-IDF结果与上述公式中计算得出的结果这一致,这是由于Sklearn除了实现基本的TF-IDF算法外,还其行了归一化、平滑等一系列优化操作。详细操作可参见Sklearn源码中的sklearn/feature_extraction/text.py具体实现。
3. 写程序实现TF-IDF方法
TF-IDF算法相对比较简单,手动实现代码量也不大,并且可以在其中加入定制作化操作,例如:下例中也加入了单个字重要性的计算。
本例中使用了Counter方法统计各个词在所在句中出现的次数。
01 from collections import Counter
02 import numpy as np
03
04 countlist = []
05 for i in range(len(arr)):
06 count = Counter(arr[i].split(' ')) # 用空格将字串切分成字符串列表,统计每个词出现次数
07 countlist.append(count)
08 print(countlist)
09 # 返回结果:(谢彦的技术博客)
10 # [Counter({'第一天': 1, '我': 1, '参观': 1, '了': 1, '美术馆': 1}),
11 # Counter({'第二天': 1, '我': 1, '参观': 1, '了': 1, '博物馆': 1}),
12 # Counter({'第三天': 1, '我': 1, '参观': 1, '了': 1, '动物园': 1})]
接下来定义了函数分别计算TF,IDF等值。
01 def tf(word, count):
02 return count[word] / sum(count.values())
03 def contain(word, count_list): # 统计包含关键词word的句子数量
04 return sum(1 for count in count_list if word in count)
05 def idf(word, count_list):
06 return np.log(len(count_list) / (contain(word, count_list)) + 1) #为避免分母为0,分母加1
07 def tfidf(word, count, count_list):
08 return tf(word, count) * idf(word, count_list)
09 for i, count in enumerate(countlist):
10 print("第{}句:".format(i))
11 scores = {word: tfidf(word, count, countlist) for word in count}
12 for word, score in scores.items():
13 print(word, round(score, 2))
14 # 运行结果:(谢彦的技术博客)
15 # 第0句:第一天 0.28 我 0.14 参观 0.14 了 0.14 美术馆 0.28
16 # 第1句:第二天 0.28 我 0.14 参观 0.14 了 0.14 博物馆 0.28
17 # 第2句:第三天 0.28 我 0.14 参观 0.14 了 0.14 动物园 0.28
从返回结果可以看出,其TF-IDF值与Sklearn计算出的值略有不同,但比例类似,且对单个字进行了统计。
最后,需要再探讨一下TF-IDF的使用场景。在做特征工程时,常遇到这样的问题:从一个短语或短句中提取关键字构造新特征,然后将新特征代入分类或者回归模型,是否需要使用TF-IDF方法?首先,TF是词频,即它需要在一个文本中出现多次才有意义,如果在短句中,每个词最多只出现一次,那么计算TF不如直接判断其是否存在。
另外,TF-IDF的结果展示的是某一词针对于它所在文档的重要性,而不是对比两文档的差异。比如上例中虽然三个短句都包含“参观”,IDF较小,由于词量小TF较大,其最终得分TF-IDF仍然不太低。如果两个短语属于不同类别,新特征对于提取分类特征可能没有意义,但是对于生成文摘就是有意义的关键字。对于此类问题,建议使用:先切分出关键词,将是否包含该关键词作为新特征,然后对新特征和目标变量做假设检验,以判断是否保留该变量的方法提取新特征。