serialVersionUID到底有何用?
文章目录
-
- 概念
- 为什么要序列化 / 反序列化?
- 序列化 / 反序列化具体实现
- Serializable 有何用?
- 序列化ID的作用
- 反序列化的约束
- 总结
概念
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
简单来说:
- 序列化:将 Java 对象转化为字节码的过程。
- 反序列化:将字节序列转化为 Java 对象的过程。
为什么要序列化 / 反序列化?
我们在网络上发送各种类型的数据,包括文本、图片、音频、视频等,这些数据都会以二进制序列的形式在网络上传输。那么当两个 Java 进程通信时,如何传送对象呢?就用到 序列化/反序列化了。发送方将Java对象序列化,以便在网络上传输,接收方接收到后将字节序列恢复成Java对象。完美实现了两个Java进程间的通信。
简单来说:以某种存储形式使自定义对象持久化,为了能将对象从一个地方传递到另一个地方。使程序更具维护性。
序列化 / 反序列化具体实现
举个例子,我们将一个类序列化到本地一个文件中,再将文件反序列化成 Java 对象。
// 定义一个Java对象
public class Student implements Serializable {
private String name;
private Integer age;
private Integer score;
@Override
public String toString() {
return "Student:" + '\n' +
"name = " + this.name + '\n' +
"age = " + this.age + '\n' +
"score = " + this.score + '\n';
}
// ... getter setter 略 ...
}
// 序列化
public static void serialize() throws IOException {
Student student = new Student();
student.setName("feiyangyang");
student.setAge(18);
student.setScore(100);
ObjectOutputStream objectOutputStream =
new ObjectOutputStream(new FileOutputStream(new File("student.txt")));
objectOutputStream.writeObject(student);
objectOutputStream.close();
System.out.println("序列化成功!已经生成student.txt文件");
System.out.println("==============================================");
}
// 反序列化
public static void deserialize( ) throws IOException, ClassNotFoundException {
ObjectInputStream objectInputStream =
new ObjectInputStream( new FileInputStream( new File("student.txt") ) );
Student student = (Student) objectInputStream.readObject();
objectInputStream.close();
System.out.println("反序列化结果为:");
System.out.println(student);
}
输出结果:
序列化成功!已经生成student.txt文件
==============================================
反序列化结果为:
Student:
name = feiyangyang
age = 18
score = 100
上述简单的实例,完成了一次 序列化/反序列化。
Serializable 有何用?
上述例子中 Student 类实现了 Serializable 接口,我们去 Serializable 接口一探究竟,发现竟然是个空接口。空接口有什么用?我们反推,让 Student 不实现 Serializable 接口,看看如何。
Exception in thread "main" java.io.NotSerializableException: com.dmsd.serializable.Student
at java.base/java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1185)
at java.base/java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:349)
at com.dmsd.serializable.Serialization.main(Serialization.java:23)
直接抛出了 NotSerializableException 异常。
我们顺着 底层查看,发现有这么一段逻辑,会判断此对象是否是 String,数组,枚举,或者实现了 Serializable 接口,如果都不符合,throw NotSerializableException

原来实现 Serializable 接口只是做了一个是否可以被序列化的标识,并不是实现了序列化这个动作。
序列化ID的作用
不知你是否见过这样的变量,这样声明一个 serialVersionUID 有什么用处?
private static final long serialVersionUID = -4392658638228508589L;
我们继续用上面的实例说话,上面的 Student 类中并没有显式的声明一个 serialVersionUID 字段,但依然不影响序列化。
那如果我们加点小动作呢?在 Student 类中添加一个属性。
public class Student {
private String id;
}
我们拿刚才已经序列化好的txt文件,试图将其反序列化,看看能否成功。

InvalidClassException 异常,看提示得出:序列化前后的serialVersionUID号码不兼容!
咦,我们并没有定义过 serialVersionUID ,从何而来的序列化前后 serialVersionUID 不兼容?
从 exception 信息我们可以得出两个结论:
- serialVersionUID 是序列化前后的唯一标识符
- 如果没有显式的定义 serialVersionUID ,编译器会自动声明一个
既然序列化前后 serialVersionUID 不兼容,说明 JVM 会将序列化前后的 serialVersionUID 最对比,如果两者一致,才能序列化成功,否则异常终止反序列化过程。
如果没有显式的定义serialVersionUID ,编译器会自动生成一个,而一旦修改了类的结构或信息,会再次为此类生成一个serialVersionUID
所以,我们在编码时,无法保证一个类的结构是永久不变的,凡是 implements serializable 的类,最好都显式的定义一个 serialVersionUID
可以使用 IDEA 来自动为类生成和添加 serialVersionUID 字段,十分方便。(如何生成一键三连见文末哦)
是否只要实现了 serializable ,类中的属性都能被序列化/反序列化了呢?
1、凡是被 static 修饰的属性是不会被序列化的,因为序列化保存的是对象的状态,而不是类的状态
2、transient 修饰的变量不会被实例化,至于原因就需要具体了解 transient 修饰符的作用了
如果在序列化某个类时,希望某个字段不被序列化,就可以使用 transient 修饰字段。
我们在 Student 添加一个 password 变量,再序列化/反序列化试试。
private transient String password;
反序列化结果为:
Student{
name=feiyangyang
age=18
score=100
password=null}
password 值为 null ,可以看出 password 并没有被序列化。
在网络传输过程中,数据难免会有安全问题。如果序列化后将其字节流在网络上传输,会有被伪造或篡改的风险,那反序列的内容就难保证正确性了。 毕竟反序列就是一种 “隐式的” 对象构造,通过读取字节流去构造,我们可以给序列化的数据添加一些约束。
反序列化的约束
针对上述问题,我们可以自行编写 readObject 函数,用于对象的反序列化构造,从而提供约束性。
例如,Student 类中 score 的值我们希望在 1-100之间,为了防止 score 在反序列过程中被伪造,自行编写 readObject() 函数用于反序列化的控制。
public class Student implements Serializable {
private void readObject( ObjectInputStream objectInputStream ) throws IOException, ClassNotFoundException {
// 调用默认的反序列化函数
objectInputStream.defaultReadObject();
// 手工检查反序列化后学生成绩的有效性,若发现有问题,即终止操作!
if( 0 > score || 100 < score ) {
throw new IllegalArgumentException("学生分数只能在0到100之间!");
}
}
}
我将 score 设置为 > 100 ,反序列操作会被立即终止并报错。

我们在类中定义的私有方法,怎么会被自动调用呢?我们探探底层源码就明白了。
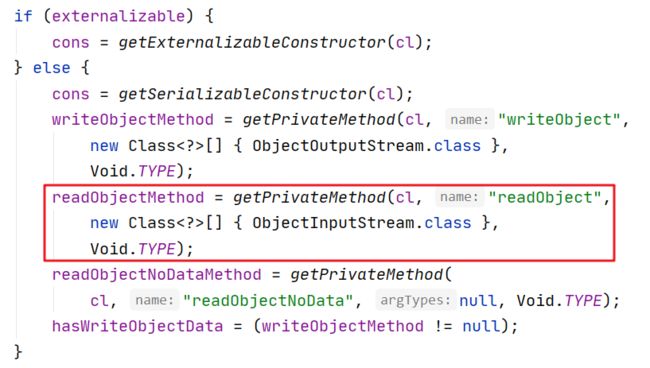
Java中万物皆可反射,通过反射不管你多 private 都能给你揪出来,这就是反射的威力。
总结
Java对象只要是持久化都需要做序列化/反序列化操作,那我们将数据持久化到数据库,这个过程是不是也做了序列化?
是的,数据库的存储部分,本质就是数据结构的序列化存储。数据库的存储和其他文件格式的存储没有本质区别,都是内容索引(格式说明、读写说明)+ 具体数据。
IDEA 设置自动生成 serialVersionUID?
在类上 alt+enter 搞定!别忘记给你的类生成 serialVersionUID 哦。