3D视觉独角兽奥比中光上市,宝藏网站追更神器RSS Please,给果蝇神经元画一幅素描、评论区大战时如何优雅吃瓜、24万张AI合成图片、AI前沿论文 | ShowMeAI资讯日报

ShowMeAI日报系列全新升级!覆盖AI人工智能 工具&框架 | 项目&代码 | 博文&分享 | 数据&资源 | 研究&论文 等方向。点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。
3D视觉独角兽『奥比中光』,成功登陆科创板
7月7日,作为国内最早研发3D视觉相关技术的公司,奥比中光登陆科创板。奥比中光于2013年在深圳创立,专注于3D视觉感知技术研发,技术积累已进入全球第一梯队,主要产品包括3D视觉传感器、消费级应用设备和工业级应用设备,下游主要是消费电子、生物识别、AIoT、工业三维测量等市场。
工具&框架
『ONNX HRNET人体姿态预估』 模型实现
https://github.com/ibaiGorordo/ONNX-HRNET-Human-Pose-Estimation
在 ONNX 中使用HRNET 系列模型(HRNET、Lite-HRNet)进行2D人体姿势估计(Python 语言)。
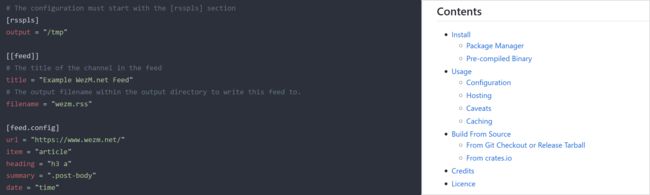
『RSS Please』 Rust 写的网页 RSS feed 自动生成工具
https://github.com/wezm/rsspls
想在某个网站有新内容时收到通知,可以订阅 Feedbin 中的 RSS feed。遇到网站不提供 RSS feed的情况,就可以使用『RSS Please』啦!通过提取网页的特定部分来生成一个RSS feed。『RSS Please』是一个用 Rust 实现的开源命令行应用程序,没有运行时的依赖性,可以在类似 UNIX 的平台上运行,包括FreeBSD、Linux 和 MacOS。
『Skeletor』 3D轮廓主干抽取器
https://github.com/navis-org/skeletor
Skeletor 可以将 mesh(网格)转变成 skeleton(轮廓主干)。实现这一过程并不容易,有大量的研究论文在探索各种不同的方法。 示例图为 Skeletor 对一个果蝇神经元的轮廓主干抽取结果。

『Ivy Gym』 Ivy 全可微强化学习环境
https://github.com/unifyai/gym
Ivy Gym 通过以完全可微的方式实现 RL 环境,为监督学习(SL)、强化学习(RL)和轨迹优化(TO)之间的交叉研究打开了大门。Ivy Gym 建立在 Ivy 机器学习框架之上,同时支持 Jax、Tensorflow、PyTorch、MXNet 和 Numpy 等环境。
『Red Engine』 Python 的现代任务调度库
https://github.com/Miksus/red-engine
Red Engine 用于 Python 应用程序的现代任务调度框架,易于安装,语法简洁,鲁棒性强,内置功能广泛且可定制,能让你的 Python 程序充满活力。Red Engine 的语法也非常优雅,远超其他替代方案。

博文&分享
『视觉表示学习之掩码』 博文分享
地址: http://akosiorek.github.io/ml/2022/07/04/masking_repr_learning_vision.html
遮蔽图像建模(MIM)是说覆盖图像的一部分,然后尝试由剩下的部分恢复来被遮蔽的部分。在这篇博客《Masking for Representation Learning in Vision》中,作者 Adam Kosiorek 探讨了为什么被遮蔽的图像能提供如此强的学习信息,怎么去构建一个好的遮蔽物,并且深入解读了自己的论文《Adversarial Masking for Self-Supervised Learning》(公众号回复『日报』可下载论文)。
『Python项目实战从入门到进阶』 电子书
地址: http://learnbyexample.github.io/practice_python_projects
初学者经常困惑,在完成了 Python 基础书籍或者课程的学习后,该如何进阶呢?那当然是上手撸项目啦!在真实的问题中寻找解决方案,是非常有效地学习方式。《Practice Python Projects》这本书介绍了 5 个初级和中级项目(如『分析评论区的投票数据』『查找文本文件中的错别字』等),并附加了趣味的练习题。一起玩起来吧!

数据&资源
『Simulacra Aesthetic Captions』 面向图像提示生成、审美评级等的合成图像数据集
https://github.com/JD-P/simulacra-aesthetic-captions
Simulacra Aesthetic Captions 数据集包含 238000 多张合成图片。图片由四万多名用户提交的提示生成,使用了 CompVis latent GLIDE 和 Stable Diffusion 等AI工具。数据集包括标题、图像和评分三个要素,其中评分来源是用户对图像的审美价值的评价(1-10分),数量超过176000。
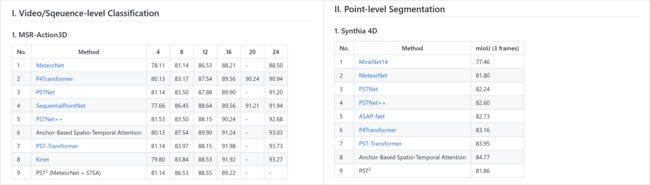
『点云』 相关资源大全
https://github.com/hehefan/Awesome-Dynamic-Point-Cloud-Analysis
Awesome Dynamic Point Cloud / Point Cloud Video / Point Cloud Sequence / 4D Point Cloud Analysis. 超酷的动态点云/点云视频/点云序列/4D点云分析资源大全。
研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
**科研进展**
- 2022.6.30『深度学习』| DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
- 2022.7.04『计算机视觉』| Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks
- 2022.7.03『计算机视觉』| Divert More Attention to Vision-Language Tracking
- 2022.6.30『计算机视觉』| Rethinking Unsupervised Domain Adaptation for Semantic Segmentation
⚡ 论文:DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
论文标题:DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale
论文时间:30 Jun 2022
所属领域:深度学习
论文地址:https://arxiv.org/abs/2207.00032
代码实现:https://github.com/microsoft/DeepSpeed
论文作者:Reza Yazdani Aminabadi, Samyam Rajbhandari, Minjia Zhang, Ammar Ahmad Awan, Cheng Li, Du Li, Elton Zheng, Jeff Rasley, Shaden Smith, Olatunji Ruwase, Yuxiong He
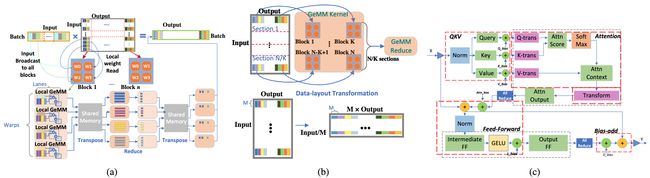
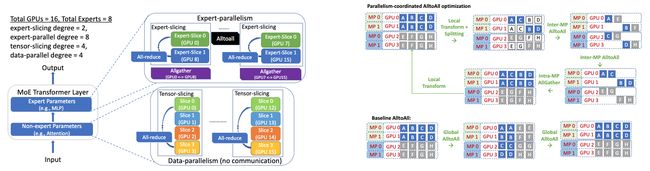
论文简介:DeepSpeed Inference reduces latency by up to 7. 3X over the state-of-the-art for latency-oriented scenarios and increases throughput by over 1. 5x for throughput-oriented scenarios./对于面向延迟的场景,DeepSpeed Inference比最先进的技术减少了高达7.3倍的延迟,并将吞吐量提高了1.5倍以上。在面向吞吐量的情况下,吞吐量增加了5倍。
过去几年见证了基于transformer的模型的成功,其规模和应用场景继续积极地增长。目前,transformer模型的情况越来越多样化:模型规模差异很大,最大的是千亿级的参数;由于专家混合模型(Mixture-of-Experts)引入的稀疏性,模型特征也不同;目标应用场景可以是延迟关键型或吞吐量导向型;部署硬件可以是具有不同类型内存和存储的单GPU或多GPU系统等等。在这种日益增长的多样性和transformer模型快速发展的情况下,设计一个高性能和高效的推理系统是极具挑战性的。在本文中,我们提出了DeepSpeed Inference,一个用于transformer模型推理的综合系统解决方案,以解决上述挑战。DeepSpeed Inference包括:(1)一个多GPU推理解决方案,当密集和稀疏变压器模型适合聚合GPU内存时,可以最大限度地减少延迟,同时最大限度地提高吞吐量;(2)一个异构推理解决方案,除了GPU内存和计算外,还利用CPU和NVMe内存,使不适合聚合GPU内存的大型模型实现高推理产量。DeepSpeed Inference在面向延迟的情况下比最先进的技术减少了7.3倍的延迟,在面向吞吐量的情况下增加了1.5倍以上的吞吐量。此外,它通过利用数以百计的GPU,实现了在实时延迟约束下的万亿级参数规模推理,这是前所未有的推理规模。它可以推理出比纯GPU解决方案大25倍的模型,同时提供84 TFLOPS的高吞吐量(超过A6000峰值的50%)。
⚡ 论文:Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks
论文标题:Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks
论文时间:4 Jul 2022
所属领域:计算机视觉
对应任务:图像识别,图像分类
论文地址:https://arxiv.org/abs/2207.01580
代码实现:https://github.com/raoyongming/DynamicViT
论文作者:Yongming Rao, Zuyan Liu, Wenliang Zhao, Jie zhou, Jiwen Lu
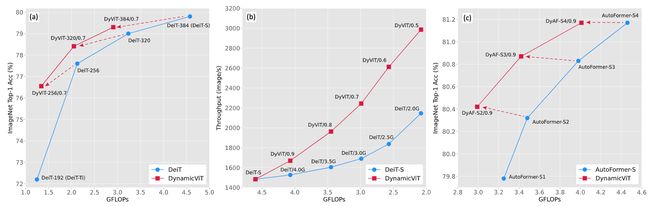
论文简介:We extend our method to hierarchical models including CNNs and hierarchical vision Transformers as well as more complex dense prediction tasks that require structured feature maps by formulating a more generic dynamic spatial sparsification framework with progressive sparsification and asymmetric computation for different spatial locations./我们将我们的方法扩展到层次模型,包括CNN和层次视觉transformer,以及更复杂的密集预测任务,这些任务需要结构化的特征图,我们制定了一个更通用的动态空间稀疏化框架,对不同的空间位置进行渐进式稀疏化和不对称的计算。
在本文中,我们提出了一种通过利用视觉数据中的空间稀疏性进行模型加速的新方法。我们观察到,视觉transformer中的最终预测只基于信息量最大的标记的一个子集,这对于准确的图像识别是足够的。基于这一观察,我们提出了一个动态标记稀疏化框架,根据输入逐步动态地修剪多余的标记,以加速视觉transformer。具体来说,我们设计了一个轻量级的预测模块来估计每个标记在当前特征下的重要性得分。该模块被添加到不同的层中,以分层修剪多余的标记。虽然这个框架的灵感来自于我们对视觉transformer中稀疏注意力的观察,但我们发现自适应和不对称计算的想法可以成为加速各种架构的一般解决方案。我们将我们的方法扩展到包括CNN和分层视觉transformer在内的分层模型,以及需要结构化特征图的更复杂的密集预测任务,通过制定一个更通用的动态空间稀疏化框架,对不同的空间位置进行渐进式稀疏化和不对称的计算。通过对信息量较小的特征采用轻量级的快速路径,对更重要的位置采用更具表现力的慢速路径,我们可以保持特征图的结构,同时大大减少整体计算量。大量的实验证明了我们的框架在各种现代架构和不同的视觉识别任务上的有效性。我们的结果清楚地表明,动态空间稀疏化为模型加速提供了一个新的和更有效的维度。代码可在https://github.com/raoyongming/DynamicViT获取
⚡ 论文:Divert More Attention to Vision-Language Tracking
论文标题:Divert More Attention to Vision-Language Tracking
论文时间:3 Jul 2022
所属领域:计算机视觉
对应任务:Object Tracking,目标跟踪
论文地址:https://arxiv.org/abs/2207.01076
代码实现:https://github.com/JudasDie/SOTS
论文作者:Mingzhe Guo, Zhipeng Zhang, Heng Fan, Liping Jing
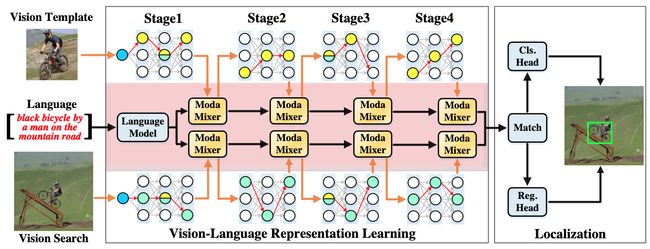
论文简介:By revealing the potential of VL representation, we expect the community to divert more attention to VL tracking and hope to open more possibilities for future tracking beyond Transformer./通过揭示VL表示法的潜力,我们期望社会各界对VL跟踪给予更多的关注,并希望在Transformer之外为未来的跟踪提供更多的可能性。
依靠Transformer进行复杂的视觉特征学习,物体追踪已经见证了新的艺术水平(SOTAs)标准。然而,这种进步伴随着更大的训练数据和更长的训练周期,使得追踪的成本越来越高。在本文中,我们证明了对变压器的依赖是没有必要的,纯粹的ConvNets在实现SOTA跟踪方面仍然具有竞争力,甚至更好,更经济和友好。我们的解决方案是释放多模态视觉语言(VL)跟踪的力量,只需使用ConvNets。其本质在于通过我们的模态混合器(ModaMixer)和不对称的ConvNet搜索来学习新的统一自适应的VL表示。我们表明,我们的统一自适应VL表征,纯粹是通过ConvNets学习的,是Transformer视觉特征的一个简单而强大的替代方案,在具有挑战性的LaSOT(50.7%>65.2%)上,基于CNN的Siamese跟踪器在SUC上不可思议地提高了14.5%,甚至超过了几个基于Transformer的SOTA跟踪器。除了实证结果,我们还从理论上分析了我们的方法以证明其有效性。通过揭示VL表示法的潜力,我们希望社区能将更多的注意力转移到VL跟踪上,并希望在Transformer之外为未来的跟踪提供更多可能性。代码和模型将在 https://github.com/JudasDie/SOTS 发布。
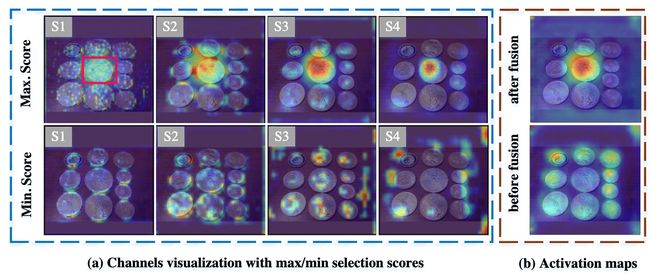
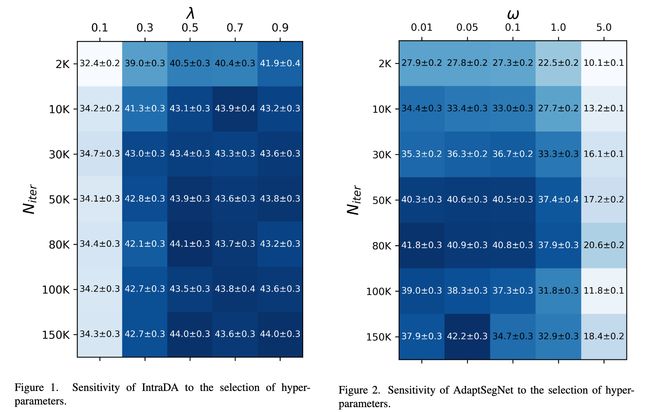
⚡ 论文:Rethinking Unsupervised Domain Adaptation for Semantic Segmentation
论文标题:Rethinking Unsupervised Domain Adaptation for Semantic Segmentation
论文时间:30 Jun 2022
所属领域:计算机视觉
对应任务:Semantic Segmentation,Unsupervised Domain Adaptation,语义分割,无监督域自适应
论文地址:https://arxiv.org/abs/2207.00067
代码实现:https://github.com/feipan664/IntraDA , https://github.com/yzou2/CRST
论文作者:Zhijie Wang, Masanori Suganuma, Takayuki Okatani
论文简介:The existing studies stick to the basic assumption that no labeled sample is available for the new domain./现有的研究坚持的基本假设是,新领域没有标记的样本可用。
无监督领域适应(UDA)将一个在一个领域中训练的模型适应于一个仅使用未标记数据的新领域。已经进行了许多研究,特别是对语义分割的研究,因为其注释成本高。现有的研究坚持的基本假设是,新领域没有标记的样本。然而,这个假设有几个问题。首先,考虑到ML的标准做法是在部署前确认模型的性能,这是很不现实的;确认需要标记的数据。其次,任何UDA方法都会有一些超参数,需要一定量的标注数据。为了纠正这种与现实的不一致,我们从以数据为中心的角度重新思考UDA。具体来说,我们从假设我们确实能够获得最低水平的标记数据开始。然后,我们问有多少标记的样本对于找到现有的UDA方法的满意的超参数是必要的。如果我们使用相同的数据来训练模型,例如微调,其效果如何?我们用流行的场景{GTA5, SYNTHIA}→Cityscapes进行实验来回答这些问题。我们的发现如下:i)对于一些UDA方法,只需几个标记的样本(即图像)就能找到好的超参数,例如5个,但这并不适用于其他方法;ii)微调在只有10个标记的图像的情况下胜过大多数现有的UDA方法。

我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!点击查看 历史文章列表,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。点击 专题合辑&电子月刊 快速浏览各专题全集。点击 这里 回复关键字 日报 免费获取AI电子月刊与资料包。

- 作者:韩信子@ShowMeAI
- 历史文章列表
- 专题合辑&电子月刊
- 声明:版权所有,转载请联系平台与作者并注明出处
- 欢迎回复,拜托点赞,留言推荐中有价值的文章、工具或建议,我们都会尽快回复哒~