笔记 | 基于Yolov5的口罩识别(持续更新)
目录
前言
一、目标检测简介
1.yolo系列的简介
2.yolov5简介
二、数据集处理
1.数据文件处理
2.标签的处理
3.标签的转换
三.模型配置参数
1.train.py参数配置
2.detect.py参数配置
3.模型代码
四.训练效果
总结
参考链接
1.yolov5模型
2.yolov5代码详解
前言
本文主要利用yolov5进行口罩识别,进而介绍在目标检测中如何对数据集进行预处理,以及yolov5模型的介绍以及应用
一、目标检测简介
在输入一张图片到网络中,目标检测与图像分类任务相比,图像分类任务仅仅把一张图片进行不同种类的分类,而且一张图片中只包含一个类别数,而在目标检测中,输入一张图片到网络中,他不仅要进行分类,还要把分出的类别在图片中找到对应的位置,同时一张照片中还将会有不同的类别
1.yolo系列的简介
yolo是一个one-stage单阶段的网络,他的精度虽然没有two-strage(Faster-rcnn,Mark-rcnn)两阶段的精度高,但是他最核心的优势是检测速度十分快,本文选用yolo系列中的yolov5进行尝试
2.yolov5简介
yolov5在参考链接中已经有很好的解释,以下是一些总结和看法
yolov5网络结构主要可以分为以下三个部分,在backbone中先使用卷积进行特征的提取或代替maxpooling;在neck中使用了SPPF结构,改变了SPP原来的分开卷积操作变为进行连续卷积,在保证内容相同的同时,提高了模型的运行速度;在head中使用特征向上融合和向下融合相结合,提高了精度
模型图如图所示,来自一位优秀的博主

二、数据集处理
1.数据文件处理
处理后的文件如图所示:
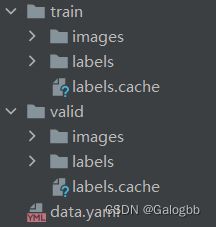
其中train中包含了训练集中的图片和标签信息,vaild中包含了验证集中的图片和标签信息,在images文件夹中不需要像图像分类任务中一样将不同类别的数据分到不同的文件夹中,以为在标签文件中不仅包含了图片的坐标信息还包含了类型信息,所以可以将所有数据都放到同一个images文件夹中,data.yaml配置文件中包含了以下信息:训练集中图片的路径,验证集中图片的路径,分类的类别个数(nc=2)以及分类的类别的名字(一定要和标签数据中的类别对应)
train: ../MaskDataSet/train/images
val: ../MaskDataSet/valid/images
nc: 2
names: ['mask', 'no-mask']2.标签的处理
labels中的文件的名字和images中的文件名要一样对应,而且在labels中的文件格式必须为txt文件
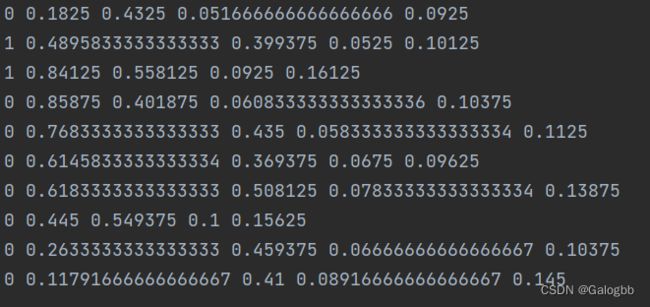
以下是一张图片的标签信息:分别表示类别序号(可有多类)、中心坐标、长宽(归一化的结果)
3.标签的转换
该yolo系列只支持txt格式,因此如果标签是xml或者是json,需要进行转换操作
以下是json转为txt的代码操作
import json
import os
#有多少个类别就在字典中写多少给对应的
name2id = {'mask':0,'no-mask':1}
def convert(img_size,box):
dw = 1./(img_size[0])
dh = 1./(img_size[1])
x = (box[0] + box[2])/2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x,y,w,h)
def decode_json (json_floder_path,json_name):
#改为转换好的标签的路径
txt_name = "..\\labels" + json_name [0:-5] + ".txt"
txt_file = open(txt_name,'w')
json_path = os.path.join(json_floder_path,json_name)
data = json.load(open((json_path), 'r' ,encoding='gb2312'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shape']:
label_name = i['label']
if (i['shape_type']=='rectangel'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1,y1,x2,y2)
bbox = convert((img_w,img_h),bb)
txt_file.write(str(name2id[label_name]) + "" + "".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
#标签的文件夹
json_floder_path = " "
json_names = os.listdir(json_floder_path)
for json_name in json_names:
decode_json(json_floder_path, json_name)以下是xml转为txt的代码操作
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import glob
#有多少个类别就在字典中写多少给对应的
classes = ["mask", "no-mask"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_name):
in_file = open('./ANNOTATIONS/'+image_name[:-3]+'xml')
out_file = open('./LABELS/'+image_name[:-3]+'txt','w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
print(cls)
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
if __name__ == '__main__':
for image_path in glob.glob("./IMAGES/*.jpg"):
print(image_path)
image_name = image_path.split('\\')[-1]
print(image_name)
convert_annotation(image_name)三.模型配置参数
1.train.py参数配置
在yolov5中的train.py文件中实现的首先是参数的配置,如下所示
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')#网络配置
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='data.yaml path')#数据
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')#配置文件
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')#矩形训练
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')#接着之前的训练
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')#不保存
parser.add_argument('--notest', action='store_true', help='only test final epoch')#不测试
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')#是否调整候选框
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')#超参数更新
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')#缓存图片
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--name', default='', help='renames experiment folder exp{N} to exp{N}_{name} if supplied')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')#是否多尺度训练
parser.add_argument('--single-cls', action='store_true', help='train as single-class dataset')#是否一个类别
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')#优化器选择
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')#跨GPU的BN
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')#GPU ID
parser.add_argument('--logdir', type=str, default='runs/', help='logging directory')
parser.add_argument('--workers', type=int, default=0, help='maximum number of dataloader workers')#windows的同学别改
opt = parser.parse_args()但是在训练时,我们不一定要运用他默认的参数,因此我们要自己传数据到模型中,在pycharm中,传入模型参数如图所示,在run configuration中配置中
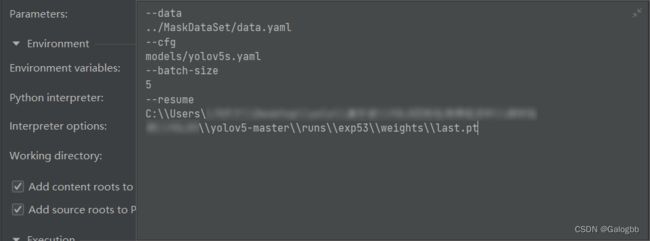
接着在run configuration中添加你所要添加的路径或者参数即可进行训练,在train.py同目录下的run文件夹会存有相关的训练信息(resume为上一次训练保存的模型)
2.detect.py参数配置
同上输入你与默认配置不同的文件即可,source设置为0则开启摄像头进行实时检测
3.模型代码
yolov5官方模型代码以及有很好的解释,在参考链接中选择了两个比较好的代码解释链接
四.训练效果
以下展示部分训练结果,可看出有较好的运算结果
总结
以上就是今天要讲的内容,本文仅仅简单介绍了基于如何使用yolov5的目标检测任务,在代码理解中仍然只理解了皮毛,仍需要继续继续研究学习,不当之处请多多谅解与指教
参考链接
1.yolov5模型
(56条消息) YOLOv5网络详解_太阳花的小绿豆的博客-CSDN博客_yolov5网络结构详解
(56条消息) YOLOv5网络结构完全解读【源码+手绘网络结构+模块结构】_Marlowee的博客-CSDN博客_yolov5网络结构图
2.yolov5代码详解
(56条消息) YOLOv5 最详细的源码逐行解读(一)_supermax2020的博客-CSDN博客_yolov5代码详解
(56条消息) YOLOV5代码解析(小白系列一)_MC.zeeyoung的博客-CSDN博客_yolov5代码详解