盘一盘 Python 系列 11 - Keras (下)

本文含 4708 字,9 图表截屏
建议阅读 24 分钟
0
引言
本文是 Python 系列的第十五篇,也是深度学习框架的 Keras 下篇。整套 Python 盘一盘系列目录如下:
Python 入门篇 (上)
Python 入门篇 (下)
数组计算之 NumPy (上)
数组计算之 NumPy (下)
科学计算之 SciPy
数据结构之 Pandas (上)
数据结构之 Pandas (下)
基本可视化之 Matplotlib
统计可视化之 Seaborn
炫酷可视化之 PyEcharts
机器学习之 Sklearn
机学可视化之 Scikit-Plot
深度学习之 Keras (上)
深度学习之 Keras (中)
深度学习之 Keras (下)
回顾《Keras 中篇》介绍的多输出模型,在线性回归两队得分的模型中,直接使用了三个超参数的值:
Adam 优化器中学习率 learning_rate = 0.1
期数 epochs = 50
批大小 batch_size = 128
这几个参数不是随意设定的,当然很多情况下使用 Adam 优化器中默认学习率 0.001 效果就不错,但是对此同时回归两队得分的任务效果很差,因此需要 Keras 自带的“调参神器” Keras Tuner 来调节学习率。此过程称为超参数调整 (hypertuning)。超参数是控制训练过程和机器学习模型拓扑的变量,它们在训练过程中保持不变,有三种类型:
影响模型选择的模型超参数 (model hyperparameters),如隐藏层包含神经元的个数
影响算法质量的算法超参数 (algorithm hyperparameters),如 learning_rate
影响结果质量的性能超参数 (performance hyperparameters),如 epochs 和 batch_size
Keras Tuner 只能调节前两种超参数,第一节会介绍,而第三种超参数需要通过Keras Wrapper 加上 sklearn.model_selection 库来调节,第二节会介绍。首先安装并引入 Keras Tuner。
!pip install -q -U keras-tuner
import kerastuner as kt
1
Keras Tuner 调参
当构建用于调参模型时,除了原模型架构之外,还需要定义超参数搜索空间,称为超模型 (hypermodel)。定义超模型有两种方式:
用函数
子类化 Keras API 中的 HyperModel 类

注意两种方法都包含参数 hp,实际上需要语句 hp = kt.HyperParameters() 来创建它,但为了代码更好维护,hp 已被内联定义 (defined inline) 在上述两种方法中了。作为超参数采样对象,hp 有以下几种类型:
布尔型:只能取 True 和 False
hp.Boolean(name, default=False, …)
选择型:取事先定义好的多值之一,适用于学习率、激活函数等
hp.Choice(name, values,…)
固定型:取事先定好的单值,该参数不被调节,适用于调节除该参数以外所有参数的情况。
hp.Fixed(name, value,…)
浮点型:最小值和最大值之间分间隔浮点值,sampling 可选 linear 和 log 等,适用于惩罚系数
hp.Float(name, min_value,max_value, step=None,sampling=None, …)
整数型:最小值和最大值之间分间隔整数值,sampling 选项同上,适用于神经元个数
hp.Int(name, min_value,max_value, step=1,sampling=None, …)
此外还可使用 hp.get(name) 可获取超参数的最新值。
超模型构建完毕之后,就需要设定调参方式了,Keras Tuner 有四个选项:
RandomSearch:随机搜索参数组合,调用语法为 kt.tuners.RandomSearch()
Hyperband:基于赌博机的算法 (bandit-based)调参,调用语法为 kt.tuners.Hyperband()
BayesianOptimization:高斯过程调参,调用语法为 kt.tuners.BayesianOptimization()
Sklearn:为 Scikit-Learn 中的模型调参,调用语法为 kt.tuners.Sklearn()
接下来将使用 Hyperband 调参器。要实例化它,需要指定超模型,优化目标以及训练最大期数等。

打印出搜索空间的信息。
tuner.search_space_summary()
Search space summary
Default search space size: 1
learning_rate (Choice)
{'default': 0.1, 'conditions': [], 'values': [0.1, 0.01, 0.001], 'ordered': True}然后搜索最佳的超参数配置。搜索超参的语法 tuner.search() 和拟合模型的语法 model.fit() 很相似。
tuner.search( train[['seed_diff']],
train[['score_1','score_2']],
epochs=10, validation_split=0.2 )
Trial 3 Complete [00h 00m 00s]
val_loss: 68.01530456542969
Best val_loss So Far: 53.07466125488281
Total elapsed time: 00h 00m 02s在搜索中,根据 hp 对象中的超参数空间的每种配置,会调用模型构建函数 build_model里的模型,并记录每种配置下运行的指标。最后用.results_summary() 方法可查看调参总结,或者去 my_dir/ 路径下查找详细的日志。
tuner.results_summary()
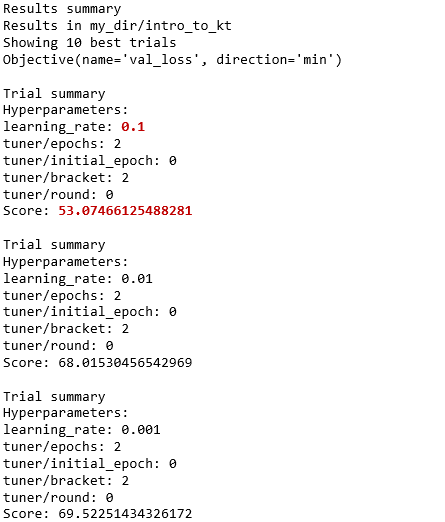
根据上面结果,选取最低 Score 即最低验证损失 53.07 对应的超参数 0.1,这样就定下了 Adam 优化器里的最优学习率为 0.1。
Keras Tuner 中不论是用函数还是子类化创建超模型,只能调节所有在 model.compile() 之前出现的超参数,不能调节在 model.fit() 时出现的超参数,比如 epochs 和 batch_size,要调节这两者需要用到在 Keras 中 Scikit-Learn API 的封装器。在下节讲解它之前先用一图来总结用函数构建超模型的过程。

2
Keras Wrapper 调参
在 Keras 中可通过以下两种方式创建 “ScikitLearn” 中的估计器:
keras.wrappers.scikit_learn.KerasClassifier(build_fn)实现了Scikit Learn 分类器接口
keras.wrappers.scikit_learn.KerasRegressor(build_fn)实现了Scikit Learn 回归器接口
通过包装模型可以利用 Scikit Learn 强大的工具来将深度学习模型应用于一般的机器学习过程,具体而言,Keras 中的神经网络模型可享受 Scikit Learn 中的估计器所有功能,比如原估计器 model_selection 下的超参数调节的几个模块。
首先引入必要模块,由于该模型本质是线性回归,因此引入 kerasRegressor;在本例中使用随机追踪法,因此引入RandomizedSearchCV。
from sklearn.model_selection import RandomizedSearchCV
from keras.wrappers.scikit_learn import KerasRegressor
构建 Keras 模型,配上上节用 Keras Tuner 调节得到的最优学习率 0.1。
def create_model():
input_tensor = Input(shape=(1,))
output_tensor = Dense(2)(input_tensor)
model = Model(input_tensor, output_tensor)
model.compile( optimizer=Adam(learning_rate=0.1),
loss='mae' )
return model
构建模型后,将其签名 create_model 赋予 kerasRegressor 函数中的参数 build_fn,得到 models。可把 models 想象成很多神经网络模型,拟合它们的语法都是
models.fit(X, y, epochs, batch_size,… )
随机追踪 RandomizedSearchCV更进一步,设定好其参数 param_distributions,具体来说:
训练期数 epochs 有 20, 50, 100, 200 和 500 五种
每批大小 batch_size 有 64, 128, 256 和 512 四种
然后在每组参数配置上随机选取运行 models 并记录对应的指标,代码如下:

当运行完 random_search.fit()之后,最优参数、得分和模型可通过以下字段获取。

以上结果都是通过 RandomizedSearchCV 在超参数组合随机选取 10 组 (n_iter=10),然后根据 3 折交叉验证 (cv=3) 得到的。要查看更详细的信息,可用 .cv_results 字段。下图按测试分数均值从高到低排序画出折线图,并添加相对应的拟合模型耗时的折线图。
cv_results = results.cv_results_
idx = np.argsort(cv_results['mean_test_score'])[::-1]
param_grp = [ cv_results['params'][i] for i in idx ]
score = cv_results['mean_test_score'][idx]
std = cv_results['std_test_score'][idx]
fit_time = cv_results['mean_fit_time'][idx]
fit_time_std = cv_results['std_fit_time'][idx]
fig = plt.figure(figsize=(10,3))
x = np.arange(len(param_grp))
ax = fig.add_subplot(1,1,1)
ax.plot( x, score, 'o-', color='b', label='score')
ax.fill_between( x, score-std, score+std, alpha=0.1, color='b')
ax.set_xticks(x)
ax.set_xticklabels( param_grp, rotation=90 )
ax.set_ylabel('score')
ax.legend(loc='upper right')
ax1 = ax.twinx()
ax1.plot( x, fit_time, 'd-', color='r', label='time')
ax1.fill_between( x, fit_time-fit_time_std, fit_time+fit_time_std, alpha=0.1, color='r')
ax1.set_ylabel('time')
ax1.legend(loc='center right')
plt.show()

均衡考虑使用不同参数组合情况下模型的得分和用时,最终选择超参数组 epochs = 50, batch_size = 128,和第一节用 Keras Tuner 选择的 Adam 优化器中 learning_rate = 0.1 一起作为模型的最优超参数。在多输出模型那节也是用这组参数来训练模型的。

Python 付费精品视频课
6 节 Python 数据分析 (NumPy/Pandas/Scipy) 课:
NumPy 上
NumPy 下
Pandas 上
Pandas 下
SciPy 上
SciPy 下
11 节 Python 基础课:
编程概览
元素型数据
容器型数据
流程控制:条件-循环-异常处理
函数上:低阶函数
函数下:高阶函数
类和对象:封装-继承-多态-组合
字符串专场:格式化和正则化
解析表达式:简约也简单
生成器和迭代器:简约不简单
装饰器:高端不简单
今年还会出 Python 三个系列:
数据可视化 (Matplotlib/Seaborn/Bokeh/Plotly/PyEcharts)
机器学习 (Scikit Learn/Scikit Plot)
深度学习 (Keras)