表单识别(六)——票据识别-论文研读:基于深度学习的票据识别系统设计与实现,卞飞飞(中)
票据识别系统文本检测与识别算法研究
- 方法概览
- 票据文本检测算法
-
- 文本单元间边界信息建模设计
- 可微分二值化模块设计
- 网络结构设计
- 网络训练标签的生成与损失函数设计
- 网络推理过程与后处理设计
- 票据文本识别算法
-
- 方法概览
- 变长训练方案设计
- CRNN网络结构改进设计
- 多模型集成设计
- 网络推理过程与后处理
方法概览

- 算法设计具体如下:
- 1)首先进行基于分割的密集文本检测算法设计。票据文本长宽比变化大,文本尺度小,同时存在部分弯曲倾斜文本,基于分割的文本检测算法能够适应以上票据文本特点,同时能够避免左右字符漏检,因此本文采用基于分割的文本检测算法,利用分割网络预测文本区域。针对分割方法存在密集文本区域粘连问题,本文设计建模相邻文本单元间边界区域信息,采用直接预测密集文本单元之间边界区域的方式,构建相邻文本单元之间排斥关系,以此为依据去除分割粘连区域;考虑到文本区域与文本单元间边界区域的相互关系,设计对齐损失函数,使得网络更好的学习文本区域与边界区域的联系;受廖明辉等人[22]研究工作启发,在网络中引入可微分二值化模块使分割网络得到充分训练。
- 2)进行票据文本识别算法设计。在得到票据图片上文本检测结果后,取出图片中所有检测文本行进行文本识别工作。CRNN是目前主流文本识别算法,在场景文本识别任务中得到广泛应用,本文基于 CRNN算法,结合票据文本特点,从训练方式、网络结构、模型集成三个方面进行针对性设计,改进CRNN算法,提高票据文本识别精度。使用变长训练方案代替补零方案,避免图片极端缩放;改进CRNN特征提取网络,提高识别精度;设计多模型集成策略,进一步确保识别结果的准确性。
票据文本检测算法
- 方法概览
- 本文研究对象为票据文本,票据文本密集,且文本尺度小,存在部分弯曲、倾斜文本,因此文本检测算法必须具备密集文本和不规则文本检测能力。基于回归文本框的方法和基于分割的方法均可完成文本检测任务,结合上文分析,基于回归文本框的算法在票据文本检测任务上存在严重缺点,即存在文本左右边缘字符漏检问题,虽然对检测任务的精度没有影响,但对后续的票据文本识别有着不可忽略的影响。左右字符漏检造成整词识别错误,影响后续金融数据的处理和使用,票据文本检测算法应尽可能避免左右字符漏检。在算法的选型上,考虑目标对象特点,结合基于回归文本框算法的缺点,本文选取基于分割的文本检测方法作为基础框架,利用语义分割网络对图片进行文本区域预测,预测每个像素点属于文本区域的概率,再进行二值化即可得到文本单元预测结果,进而获得每个文本单元的包围框。基于分割的方法主要存在以下两个问题:
- 1)票据密集文本间的间隔较小,相邻文本单元的分割结果易出现粘连(如图3-2
所示),导致最终文本框包含多个文本区域,对文字信息的识别任务造成困难,严重影响文本识别精度。 - 2)基于分割的方法二值化后处理操作不可导,无法端到端进行训练。基于分割的文字检测方法首先由分割网络预测文本区域概率,再使用二值化操作得到文本区域预测结果,其中二值化后处理操作不可导,因此整体方法不能端到端进行网络训练优化,导致网络训练不完全。

- 上述问题的存在造成基于分割的文本检测方法检测结果较差且影响识别任务,本文检测算法设计初衷是解决分割方法对于密集票据文本存在的分割区域粘连问题,提出基于建模文本单元间边界的密集文本检测算法,借助密集文本单元间边界区域信息区分不同文本单元实例,解决分割粘连问题,提高检测精度。算法框架如图3-3所示:

- 在如图3-3所示的算法框架中,网络同时预测文本区域(probability map)和文本单元间边界区域(Boundary
map)。分割方法对密集文本区域预测存在区域粘连问题(如图3-3中文本区域预测存在红色区域粘连),通过预测相邻文本单元边界区域构建文本单元之间的排斥信息,以此为依据解决probability map存在区域粘连的问题。对于二值化操作不可导,无法加入网络导致训练不完全,借鉴廖明辉等人DB[22]网络的思想,引入可微分二值化(Differentiable
Binarization)模块[22],解决二值化操作不可导问题,完成端到端的网络训练。
文本单元间边界信息建模设计
- 为解决分割区域粘连问题,Text Field算法与DB算法从不同的角度考虑建模文本单元间边界信息,Text Field算法通过构建方向场从侧面表征相邻文本之间的边界信息,通过网络预测文本区域内每一个像素到最近文本边界的方向向量来区分不同文本单元,解决分割区域粘连问题。但构建方向向量过程复杂,且包含复杂的后处理过程。DB算法从分割结果二值化角度考虑,认为不同区域应使用不同的阈值进行二值化,对于文本区域内部,使用较低阈值进行二值化,对于文本边界附近区域,应使用较高阈值进行二值化。DB算法预测文本区域分割结果,同时预测二值化阈值,为分割结果的每个像素提供预测阈值进行二值化。密集文本间边界区域因使用较高的阈值进行二值化,粘连区域被去除,从而区分相邻的不同文本单元。


-相邻密集文本单元间存在部分背景区域,即文本与文本之间的边界区域,如图3-4所示,边界区域并不单独存在,边界区域一定由两个相邻文本单元共同决定,相邻文本单元共同决定边界区域的位置、大小,同时边界区域的位置和大小反应了相邻文本单元的位置和关系。边界区域可以表征相邻文本之间的排斥关系,排斥关系在区分不同文本实例过程有极其重要的作用,如图3-5
所示,依赖于边界区域可将粘连部分去除,从而将紧密相邻的文本分割预测结果区分开,这是本文考虑解决分割区域粘连问题的出发点和思路。
- 受文本单元间边界区域作用的启发,不同于 Text Field、DB算法从侧面表征文本单元间的边界信息,本文基于分割的文本检测算法直接预测相邻文本单元间边界区域,利用边界区域的辅助信息帮助去除文本区域预测存在粘连的部分,从而区分相邻的密集文本单元实例。具体来说,利用卷积神经网络对输入图片进行特征提取,设计两条上采样支路进行多尺度特征融合,一条上采样支路预测文本区域,即Tseg;另一条上采样支路预测边界区域,即Bseg。Tseg表征每个像素点属于文本区域的概率,而Bseg表征每个像素点属于文本单元间的边界区域的概率,理想情况Tseg∩Bseg=∅,即Tseg与Bseg之间不存在交集,如果存在交集,即为文本分割区域存在粘连,只需将Tseg上属于边界区域的像素分数减小,即Tseg=Tseg−Bseg,即可去除粘连部分,将粘连的文本分割区域区分开,产生相对独立的文本预测单元。
可微分二值化模块设计
- 对于分割网络预测结果,通过固定阈值二值化即可得到文本单元预测结果,如式 3-1 所示:

- 其中x代表分割预测输出,0 ≤x≤ 1。式 3-1 不可导,无法加入到网络中。
- 为解决后处理部分二值化操作不可导,无法端到端优化,可能导致网络训练不完全,本文借鉴DB[22]算法框架的可微分二值化(Differentiable Binarization)思想,引入可微分的二值化模块,可微分二值化模块如式3-2所示:

- 式3-2的函数图像与式3-1函数图像相似,如图3-6所示,可理解为式3-2是式3-1的近似,区别在于式3-2为可微函数,用可微分二值化模块代替原始二值化模块即可加入到网络中进行端到端训练,如图3-7所示。对于文本区域预测Ppm与文本单元间边界预测Pbm,通过式3-3得到近似二值化预测Pabm,其中p=Ppm−Pbm,k= 50。

- 基于以上思路和设计,本文的文本检测算法能够解决分割方法存在的分割区域粘连、后处理不可导问题。值得注意的是,借助边界区域预测解决文本区域粘连的 方法和可微分二值化模块能够应用到其它基于分割的文本检测方法中,具有良好的 通用性和可移植性。
网络结构设计
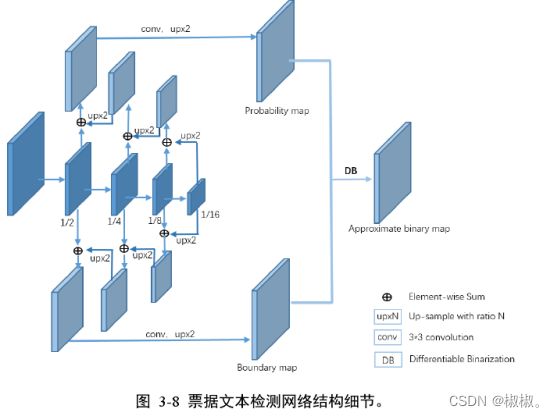
- 本文基于分割的文本检测算法网络结构与FCN[31]网络结构类似,为了同时预测文本区域以及文本单元间的边界区域,本文在基础特征提取网络的两侧设计上采样支路,同时预测文本区域(probability map)和文本单元间边界区域(boundary
map),网络细节如图3-8所示。具体的,采用ResNet50[28]网络作为基础特征提取网络,在ResNet50网络上添加一系列上采样层和卷积层形成金字塔结构,取出ResNet50不同阶段输出特征与低层特征进行特征融合(逐像素相加)。最终分别得到文本区域预测结果与文本单元间边界区域预测结果。网络的具体预测目标分为以下三个部分: - 1)文本区域的预测:ResNet50网络与一侧上采样支路共同预测每个像素点属于文本区域的得分,经过Sigmoid层即得到文本区域概率预测结果。
- 2)文本单元间边界区域的预测:ResNet50网络与一侧上采样支路共同预测每个像素点属于文本单元间边界区域的得分,经过Sigmoid层即得到文本单元间边界区域概率预测结果boundary
map。 - 3)近似二值化结果:首先用减去,得到的差值结果经过可微分二值化(Differentiable
Binarization)模块得到近似的二值化结果(Approximate binarization map)。
网络训练标签的生成与损失函数设计
- 本文收集的票据数据文本框的标注为四边形四个顶点的坐标,为了训练本文基于分割的文本检测网络,需要标注每个像素点的类别。对于文本区域预测任务,标注每个像素点类别,其中对于属于文本框区域内的像素,标注为文本区域类别(类别1),其余为背景类别(类别0);对于文本单元间边界区域预测任务,标注每个像素点类别,其中对于属于文本单元间边界区域的像素,标注为边界区域类别(类别1),其余为背景类别(类别0)。对于只有文本框坐标的票据文本数据集,设计如图3-9所示的标签制作流程。

- 根据文本区域外接框Box,默认Box框内区域即为文本区域,生成文本区域训练标签,如式3-4;默认Box框下底边附近一定区域为文本单元间边界区域,如公式3-5,其中yborder为文本框Box下底边像素点的纵坐标,ℎ为文本框Box高度。对于绝大多数密集文本来说下底边附近一定区域代表其与下侧相邻文本间的边界区域,本文取文本框下底边附近垂直方向[yborder−0.05ℎ,yborder+ 0.2ℎ]区域为相邻文本单元间边界区域。根据上述标签制作流程,可得到本文基于分割的文本检测网络训练标签。其中文字区域预测Probability map与近似二值化预测approximate binarization map属于对同一目标的不同预测方式,使用相同的训练标签,即Pij。
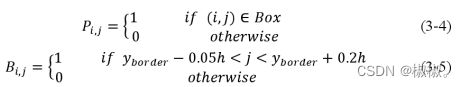
- 本文提出的文本检测网络是同时学习文本区域和文本单元间边界区域的多任务网络,对 于文本区域预测、文本单元间边界区域预测boundary map和近似二值化预测approximate map,采用交叉熵损失函数。文本区域标签和文本单元间边界区域标签分别记为Gt,
Gb,文本区域预测probability map记为Ppm,文本单元间边界区域预测boundary map记为Pbm,近似二值化结果approximate map记为pabm,近似二值化结果与文本区域预测是对同一目标的预测,使用相同的训练标签Gt。相关的损失函数的计算公式如下:


- 鉴于文本单元间边界区域的产生方式,文本区域预测与文本单元间边界区域预测两者具有互斥关系,理想情况下文本区域在文本单元间边界区域预测中属于背景区域,文本单元间边界区域在文本区域预测中属于背景区域,即Ppm×Pbm=0。且文本区域与文本单元间边界区域存在约束关系,文本区域的位置和大小决定文本单元间边界区域,同时文本单元间边界区域的位置和大小反映文本区域的位置。考虑两者间的互斥关系与约束关系,本文设计对齐损失函数,如式 3-9:

- 本文文本检测方法的多任务损失函数如式3-10所示:
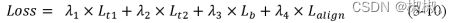
- 其中,λ1,λ2,λ3,λ4为控制各部分损失大小的超参数
网络推理过程与后处理设计
- 得到网络输出后,对近似二值化结果通过固定阈值再次二值化,得到文本区域实例,进而得到每个文本区域的外接包围框。实验发现,直接使用Ppm和Pbm即可达到较好的效果,无需进行可微分二值化模块的计算,减少计算量,加快推理时间。实际测试中通过Ppm−Pbm解决Ppm中分割文本区域粘连问题,完成密集文本检测任务,完整推理流程如图3-10所示。为进一步排除错误预测,本文采用两种文本框过滤策略:过滤面积小于阈值的文本框;过滤长宽比小于阈值的文本框。经过过滤错误预测即可得到最终票据文本预测框。

票据文本识别算法
方法概览
- 本文使用的票据文本识别算法是基于CRNN文字识别算法改进而来,CRNN文字识别算法是近年来文字识别任务中最常用的基于深度学习的文字识别算法,该算法借鉴语音识别中序列识别思想,将文字图片视为序列,将文字识别问题转化为序列识别问题。首先通过卷积神经网络对输入的文字图片提取特征得到文字特征序列,将特征序列输入双向长短期记忆网络(BiLSTM)对特征序列进行解码输出,经过去重操作得到最终的文字识别结果。
- 本文尝试CRNN在票据数据上的实验发现,对于票据文本图片,CRNN网络识别精度较低。考虑到网络结构特点以及训练方法、后处理过程,本文基于CRNN网络改进训练方法、网络结构、后处理部分,提高票据文本识别精度。在网络结构上,本文在CRNN网络中嵌入改进的Inception[29]结构以及CReLU[33]结构;在训练方法上,本文采用变长训练方法,避免文本图片被剧烈缩放;在后处理过程中,本文设计集成策align score,使用多模型集成的方法确保票据文本识别结果的准确性。
变长训练方案设计
- CRNN网络训练过程中,通常由多张文本图片组成一组训练数据输入网络推理、训练,由于卷积层以及BiLSTM层的原因,输入网络的一组图片数据必须具有相同的大小尺寸,而文本图片有着不同的尺寸,通常有两种处理方式,一是将不同尺寸的文本图片缩放到相同的尺寸输入到网络中;二是先缩放到相同高度,再通过补零的方式转换成相同宽度的文本图片,两种方式如图3-11所示:


- 如图3-11所示,经过缩放或者补零的方式虽然可以将不同尺寸文本图片调整为相同尺寸组成一组训练数据,但存在极端情况,如图3-12所示,部分文本图片被极端缩放导致字符变形严重,影响识别结果,且补零的方式存在文本区域与补零区域不协调问题,同样影响网络对文本的识别精度。
- 为避免上述补零和缩放两种方式存在的问题,本文提出一种变长训练方案。首先将文本图片高度缩放到相同尺寸,由于文本图片均有相似高度,缩放图片高度不会产生极端变形;再对所有的训练文本图片根据宽度排序;当从图片集中选择多张文本图片组成一组训练数据时,选择排序后位置临近的一组图片作为一组训练数据,再将该组图片宽度调整为该组图片的平均宽度,如图3-13所示。

- 通过将排序后位置邻近的多张图片组成一组训练数据并将宽度调整为平均宽度的方式,减小因缩放导致的文本图片变形程度,同时不会产生补零造成的背景差异较大问题,最大程度保持文本图片的原始状态,有利于提高网络的识别精度。
CRNN网络结构改进设计
- 基础CRNN网络结构简单,共包含7层卷积层以及两层BiLSTM层,参数量少,推理快。但简单的网络结构同时限制了网络对票据文本图片的特征提取能力,影响网络预测能力和识别精度。因此本文改进CRNN网络的初衷为加强基础特征提取网络的特征提取能力。提高网络特征提取能力的直接方法为增加网络的深度或宽度,其中深度指网络的层数,宽度指网络的并行计算层数。因为BiLSTM层的存在需要固定输入BiLSTM层的特征序列维度大小,直接添加卷积层来增加CRNN网络的深度会导致输入特征序列维度出错,因此本文从网络宽度的角度考虑。增加网络宽度的典型方法为Goog LeNet[29]中的Inception结构,Inception结构对输入图片并行地执行多尺度卷积运算操作,并融合运算结果,1×1、3×3、5×5等不同尺寸卷积核与池化操作可以获得输入图片的多尺度特征信息,能够适应多尺度目标并提升网络特征提取能力。
- 直接引入Inception结构并不能适配CRNN网络,本文在Inception结构的基础上做出调整,改进的Inception结构如图3-14所示。对于每条支路,输入输出具有相同尺寸,最后将各个支路的输出按通道叠加,组成多尺度特征输出。本文设计增加残差分支(Shortcut Connection),将输入特征与多尺度特征逐元素相加,得到Inception结构的最终输出。

- 通过引入Inception结构,使得CRNN基础网络性能得到提升,且能适应多尺度文本,网络特征提取能力得到提升,鲁棒性加强。
- Inception模块的引入带来网络特征提取能力的加强,但同时引入较多的计算量,增加文本识别推理时间,影响使用体验。考虑增加的计算量,本文在CRNN网络中引入改进设计的CRe LU[33]结构,CRe LU是基于Re LU[27]激活函数的改进版本,CRe LU的提出是基于观察发现:网络前部倾向于同时捕获正负相位信息,存在卷积核的冗余。使用CRe LU结构代替Re LU激活函数可以将特征通道减少一半,去掉网络冗余计算,同时一定程度上能够提高网络特征提取能力,提高网络精度。CRe LU激活函数定义如式 3-11:

- 其结构如图3-15 (a)所示:

- 本文在CReLU的基础上,设计残差支路,通过残差支路将低级特征与高级特征融合,增强特征表达能力,有利于提高网络的特征提取能力和性能,改进的 CReLU结构如图 3-15 (b)所示。
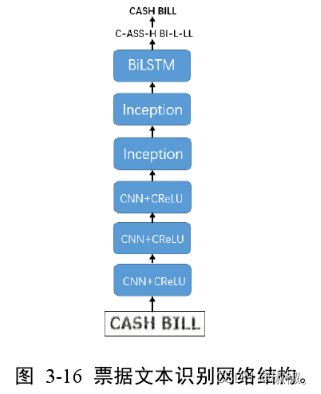
- 结合对Inception模块和CReLU模块的分析设计,本文的票据文本识别网络结构如图3-16所示,使用改进的CRe
LU模块代替ReLU激活函数,并将CRNN网络最后两层卷积层替换为本文所设计的Inception模块。
多模型集成设计
- 为进一步提高票据文本识别精度,确保票据文本识别结果的准确性,本文考虑使用引导聚集算法(Boostrap aggregating,
Bagging)进行多模型集成,参考序列识别任务常用的CTC[34]损失函数,设计Align score集成策略。 - CRNN文字识别是一个序列分类任务,对序列每一帧进行分类,每一帧概率最大的字符类别作为本帧的识别结果,通常多个网络预测输出均可通过去重操作得到相同的识别结果,即存在多对一关系,如图3-17所示:

- 如图3-17所示,将网络预测的一种结果ℎeεllεεlεo称为一条路径,对于识别标签“hello”,ℎeεllεlεo和ℎelllεεlεo均是对“hello”的正确预测,即有多条正确路径可以通过去重操作得到相同的识别结果。如果能够得到每一条正确路径的概率,即可将这些正确路径的概率求和作为网络预测结果的置信度。对于计算每一条正确路径的概率,可通过如图3-18所示的图结构计算:

- 对于网络预测结果pred=zoo,先在预测结果的字符之间以及头尾插入间隔符ε,得到伪标签pred′={εzεoεoε},再从每一帧的预测结果中取出伪标签{εzεoεoε}对应字符类别的预测概率形成概率矩阵。图3-18中,从左上角ε或Z到右下角o或ε的所有路径均可通过去重操作得到结果zoo,对于每一条路径π,假设每帧的识别结果相对独立,则可计算出每一条路径的条件概率,如式 3-12。再对每条路径概率求和即可得到后验概率,即给定输入x,网络预测pred的概率,也是网络对预测结果的置信度,本文称为align
score ,计算公式如式3-13,其中B代表去重操作。

- 对于网络预测结果pred,本文根据式 3-13 计算align score作为网络预测结果的置信度,根据置信度进行模型集成,选择置信度最大的网络输出作为最终的预测结果。通过设计集成策略align score进行模型集成,显著提高票据文本识别精度。
网络推理过程与后处理

如图3-19所示,先将同一张文本图片分别输入两个文本识别网络(使用不同超参数训练的CRNN改进模型),得到模型预测结果prediction1
-
和prediction2,以及各自的置信度align score1和align score 2,根据align score1和align score2的大小确定最终的识别结果。通过align score分数来选择置信度较高的识别结果,能够提高网络整体识别精度,确保识别结果的准确性。
-
本章首先介绍票据文本检测算法框架,针对分割方法存在的文本区域粘连问题,设计基于建模相邻文本单元间边界的文本检测算法框架,使用文本单元间边界的预测解决文本区域预测的粘连问题;针对二值化操作不可导,无法嵌入网络中导致训练不完全的问题,借鉴廖明辉等人[22]的DifferentiableBinarization思想,引入可微分的二值化模块,完成基于分割的票据文本检测算法框架设计。另外详细地介绍了方法设计思路、训练标签制作以及网络推理过程。
-
然后介绍对CRNN网络的改进设计,设计增加Inception模块和CReLU模块,提高网络的识别精度;并设计align
score集成策略,进一步提高票据文本的识别准确率,其中主要对align score的设计思路和计算方法进行了详细说明。 -
本章设计的高精度票据文本检测与识别算法,为本文提出的基于深度学习的票据识别系统构建奠定了模型基础。本文设计的各个模块均可方便的移植到其它文本检测和识别网络,具有良好的通用性和可移植性。