基于机器学习算法和pytorch实现的深度学习模型的中文长文本多分类任务实战
目录
一、贝叶斯算法长文本分类
二、TextCNN模型长文本分类
1、word2vec词向量的训练
2、padding操作
3、文本向量化
4、TexTCNN模型构造
三、TextRNN模型长文本分类
四、TextRNN+ATT模型长文本分类
五、Bert模型长文本分类(不更新bert权重和更新bert权重)
模型训练
1、Bert模型不参与训练
2、Bert模型参数训练
总结和展望
最近实现了中文长文本的多分类任务,主要是使用了机器学习的算法和基于pytorch实现的深度学习的相关模型。采用的模型分别是:机器学习算法贝叶斯和LightGBM、TextCNN、TextRNN、TextRNN+Att、Bert(分为权重是否更新2个版本)。之所以采用这几种模型,是因为这几种模型比较主流典型和常用的,弄懂这些模型的一些应用细节,对于实战的提升还是很有意义的。当然做文本分类任务还有其他许多好的模型,这里就不一一列出来了,可以自己去拓展,如金字塔模型等等。
本文重在整个任务全流程的实现,对于分类的准确率和模型的性能没有做很多考虑。由于这里数据集是专利数据的摘要,文本长度都是很长的,文本长度区间(字为单位)如下图:

文本长度的跨度很大,为了能够把大部分的数据集都考虑到,选取seq_length==400也就是400个字,这个可能分类准确率效果就有点低了,感觉长文本分类目前并没有一个很好的解决办法。主要是因为模型所有的算法和模型并不能生成一个很好的文档向量,目前这块儿的论文也有一些在研究中;同时自己也想过把400个字的文本,每个字的字向量或者对应的多个词向量直接cat起来形成一个大维度的向量来代表一个文本,会不会有一定的效果——还待实验——已知的缺陷就是向量维度比较大,对现存和内存要求比较高,很吃机器,同时训练速度估计也很慢的。
OK,下面就一个一个模型的来详细实现长文本分类任务。先把整体的一个效果公布一下:
| 算法 | 准确率 | 备注 |
| 机器学习算法 | 44.14%(GaussianNB) 66.96%(LGBMClassifier) |
文本向量使用的是bert提取的;文本长度400字;算法没有调参;训练集19.6W,验证集4.9W |
| textCNN |
65% | 词向量使用的是word2vec;文本长度200个单词;训练集19.6W,验证集4.9W |
| TextRNN | 72.88% | Bilstm+Linear;词向量使用的是word2vec;文本长度50个单词;训练集19.6W,验证集4.9W |
| TextRNN+Att | 70.41% | Bilstm+ATT+Linear;词向量使用的是word2vec;文本长度50个单词;训练集19.6W,验证集4.9W |
| Bert | 72.94% | Bert(权重不更新)+Linear;文本长度400字;训练集19.6W,验证集4.9W |
| Bert | 83.59% | Bert(权重更新)+Linear;文本长度400字;训练集19.6W,验证集4.9W |
一、贝叶斯算法长文本分类
首先采用贝叶斯算法主要是因为这个算法很轻量,比较简答,当然也被证实过在文本分类上是有一定的效果的;于是这里就从这个模型开始,关于贝叶斯原理和调参之类的这里不做介绍。
贝叶斯算法做长文本分类的时候,按照一般的步骤就是,数据读取、数据清洗、词袋模型、获取文本对应的向量表示、训练贝叶斯模型。
本文的数据集情况:训练集19W,验证集5W。得出的词袋模型中的词语的总量是24W个(没有去掉高频词),把对应的19W条训练集和5W条验证集数据转化为对应向量,每一条数据都是对应24W维度的向量,用我身边所有的机器都实现不了,内存要爆炸。
然后试着减少数据量,训练集4W条验证集1W条,发现词袋模型的规模还是有10W个词,就算去掉高频词应该也是很大的,而且这个高频的程度也不好把控。身边的机器32G内存仍然扛不住,词袋模型的方案放弃。
其实这里做长文本的分类,采用词袋模型会有一个天然的缺陷性,那就是由词袋模型生成的文本向量维度很大,而且还是稀疏的,这个就对后续的模型训练和使用造成消极的影响。
那就试试Bert模型提取文本向量,然后喂入贝叶斯模型中进行分类。这个方案也是和后面的有些类似,但是又有点不同。首先需要把文本转换为Bert的输入向量,然后输入bert模型,得到下一个模型的输入向量。就需要一个dataLoader,会使用到cuda加速。代码如下:
from torch.utils.data import Dataset
from transformers import BertTokenizer
import torch
from tqdm import tqdm
import os
import logging
logger = logging.getLogger(__name__)
class ReadDataSet(Dataset):
def __init__(self,data_file_name,args,repeat=1):
self.max_sentence_length = args.max_sentence_length
self.repeat = repeat
self.tokenizer = BertTokenizer.from_pretrained(args.model_path)
self.process_data_list = self.read_file(args.data_file_path,data_file_name)
def read_file(self,file_path,file_name):
file_name_sub = file_name.split('.')[0]
file_cach_path = os.path.join(file_path,"cached_{}".format(file_name_sub))
if os.path.exists(file_cach_path):#直接从cach中加载
logger.info('Load tokenizering from cached file %s', file_cach_path)
process_data_list = torch.load(file_cach_path)
return process_data_list
else:
file_path = os.path.join(file_path,file_name)
data_list = []
with open(file_path, 'r') as f:
lines = f.readlines()
for line in tqdm(lines, desc='read data'):
line = line.strip().split('\t')
data_list.append((line[0], line[1]))
process_data_list = []
for ele in tqdm(data_list, desc="Tokenizering"):
res = self.do_process_data(ele)
process_data_list.append(res)
logger.info('Saving tokenizering into cached file %s',file_cach_path)
torch.save(process_data_list,file_cach_path)#保存在cach中
return process_data_list
def do_process_data(self, params):
res = []
sentence = params[0]
label = params[1]
input_ids, input_mask = self.convert_into_indextokens_and_segment_id(sentence)
input_ids = torch.tensor(input_ids, dtype=torch.long)
input_mask = torch.tensor(input_mask, dtype=torch.long)
label = torch.tensor(int(label))
res.append(input_ids)
res.append(input_mask)
res.append(label)
return res
def convert_into_indextokens_and_segment_id(self, text):
tokeniz_text = self.tokenizer.tokenize(text[0:self.max_sentence_length])
input_ids = self.tokenizer.convert_tokens_to_ids(tokeniz_text)
input_mask = [1] * len(input_ids)
pad_indextokens = [0] * (self.max_sentence_length - len(input_ids))
input_ids.extend(pad_indextokens)
input_mask_pad = [0] * (self.max_sentence_length - len(input_mask))
input_mask.extend(input_mask_pad)
return input_ids, input_mask
def __getitem__(self, item):
input_ids = self.process_data_list[item][0]
input_mask = self.process_data_list[item][1]
label = self.process_data_list[item][2]
return input_ids, input_mask,label
def __len__(self):
if self.repeat == None:
data_len = 10000000
else:
data_len = len(self.process_data_list)
return data_len
接下来就是把得出的bert向量输入到NB和LightGBM模型中,整个流程的代码如下:
from Code.ReadDataSet import ReadDataSet
from torch.utils.data import DataLoader
import torch
from tqdm import tqdm
from transformers import BertModel
import argparse
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import f1_score,accuracy_score,precision_score,recall_score
from lightgbm import LGBMClassifier
def get_bert_vector(model,train_iter,dev_iter,args):
model.to('cuda')
model.eval()
train_vec = []
train_label = []
dev_vec = []
dev_label = []
with torch.no_grad():
for step, batch in enumerate(tqdm(dev_iter, desc='dev iteration:')):
batch = tuple(t.to('cuda') for t in batch)
input_ids = batch[0]
input_mask = batch[1]
label = batch[2]
output = model(input_ids, input_mask)[1]#[1]pooler_output,就是cls对应的那个向量,[0]last_hidden_state,这个需要自己取处理才行
label = label.to('cpu').numpy().tolist()
output = output.to('cpu').numpy().tolist()
dev_vec.extend(output)
dev_label.extend(label)
for step, batch in enumerate(tqdm(train_iter, desc='train iteration:')):
batch = tuple(t.to('cuda') for t in batch)
input_ids = batch[0]
input_mask = batch[1]
label = batch[2]
output = model(input_ids, input_mask)[1]
label = label.to('cpu').numpy().tolist()
output = output.to('cpu').numpy().tolist()
train_vec.extend(output)
train_label.extend(label)
return train_vec,train_label,dev_vec,dev_label
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='init params configuration')
parser.add_argument('--batch_size',type=int,default=100)
parser.add_argument('--model_path',type=str,default='./pretrain_model/Chinese-BERT-wwm')
parser.add_argument('--requires_grad', type= bool,default=True)
parser.add_argument('--data_file_path',type=str,default='Data/patent')
parser.add_argument('--max_sentence_length',type=int,default=400)
args = parser.parse_args()
print(args)
train_data = ReadDataSet('train.tsv',args)
train_loader = DataLoader(dataset=train_data, batch_size=args.batch_size, shuffle=True)
dev_data = ReadDataSet('dev.tsv',args)
dev_loader = DataLoader(dataset=dev_data, batch_size=args.batch_size, shuffle=True)
bert_model = BertModel.from_pretrained(args.model_path)
train_vec, train_label, dev_vec, dev_label = get_bert_vector(bert_model,train_loader,dev_loader,args)
clf = LGBMClassifier()
clf.fit(train_vec, train_label)
dev_pred = clf.predict(dev_vec)
f1 = f1_score(dev_label, dev_pred, average='macro')
pre = precision_score(dev_label, dev_pred, average='micro')
acc = accuracy_score(dev_label, dev_pred)
recall = recall_score(dev_label, dev_pred, average='micro')
print('LGBMClassifier f1:', f1)
print('LGBMClassifier pre:', pre)
print('LGBMClassifier recall:', recall)
print('LGBMClassifier acc:', acc)
clf = GaussianNB()
clf.fit(train_vec, train_label)
dev_pred = clf.predict(dev_vec)
f1 = f1_score(dev_label, dev_pred, average='macro')
pre = precision_score(dev_label, dev_pred, average='micro')
acc = accuracy_score(dev_label, dev_pred)
recall = recall_score(dev_label, dev_pred, average='micro')
print('GaussianNB f1:', f1)
print('GaussianNB pre:', pre)
print('GaussianNB recall:', recall)
print('GaussianNB acc:', acc)注意的是bert输出的向量应该是采用[1]pooler_output,就是cls对应的那个向量;否则用[0]就会要自己做一些处理。还有一个值得注意的地方就是这里的最后分类结果中运用到了一定的评价指标,这里由于不是二分类而是多分类,所以就采用了宏观或者微观的召回率之类的。结果如下:
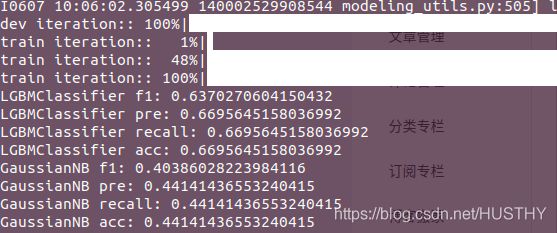
这个效果看起来还是比较差的,只有44.14%的准确率。可以试试其他机器学习里的分类器,比如SVM、xgboost或者LightGBM等,应该会有上升的。LIGHTGBM的准确率就大幅度提高了66.96%——这个是机器学习算法比赛中LIGHTGBM算法广泛被使用的一个原因,效果好速度快。
二、TextCNN模型长文本分类
TextCNN模型的原理不做介绍,这里直接上方案流程。
这里使用jieba分词、去停用词、然后使用word2vec提取词向量,直接cat起来形成文档向量,然后训练TextCNN。这里选取这样的方案,一个是想熟练一下jieba分词处理这一套技术,同时熟悉word2vec,最后也可以横向比较一下和其他向量的一个区别,当然这里没有严格的做对比实验就是简单粗略的感受式比较。(我太懒了。。。。。。)
首先可以看看,分词后的结果,文章词数量的一个分布,然后决策选取多少个词。由下图很直观的可以得出,200个词是不错的选择。
这个时候需要注意的是我们采用的word2vec是使用其他语料训练的,包含了55W个词,但是我们的数据集是特定领域的仍然出现了很多词不在word2vec中,因此我们就需要进行word2vec的增量训练:
1、word2vec词向量的训练
代码如下:
import pandas as pd
from gensim.models import Word2Vec
#文本向量化的时候回出现voo的问题,提前把word2vec做增量训练,得到新的模型
if __name__ == '__main__':
train_text = list(pd.read_csv('data/train_word_cut.csv')['text_word_cut'])
dev_text = list(pd.read_csv('data/dev_word_cut.csv')['text_word_cut'])
train_text.extend(dev_text)
model = Word2Vec.load('pretrain_model/word2vec/word2vec_newtrain.model')
#增量训练Word2Vec,只训练新词,不训练旧词
model.build_vocab(train_text,update=True)
model.train(train_text, total_examples=model.corpus_count, epochs=5)
model.save('pretrain_model/word2vec/word2vec_newtrain.model')2、padding操作
当然由于word2vec训练的时候会把低频词忽略掉,所以得不到低频词的词向量,这里仍然会出现oov的错误。那么就需要过滤掉文本中的那些不在Word2vec模型中的词语。这个过程,耗时比较多,200个词,25W条数据集,然后每个词好需要在word2vec中做65W(增量训练后,模型词典变大)次遍历。当然也可以直接处理为出现oov的错误直接把这个词的向量随意用个固定的向量来代替,这样可以省略很多预处理的时间,也不会对性能产生很大的影响。
上代码:主要是做了padding和除去不在word2vec模型中的词语,保存下来。
import pandas as pd
from gensim.models import Word2Vec
from tqdm import tqdm
from multiprocessing import Pool
"""
分词后的文本做padding操作!方便后续直接形成word2vec向量操作,顺便也
把word2vec外面的词语给去除掉————发现时间还是要40个小时,得用多进程了。
"""
def function(params):
text = params[0]
wv_words = params[1]
keep_words = []
words = text.split(' ')
for word in words:
if word in wv_words:
keep_words.append(word)
if len(keep_words) >= 200:
break
if len(keep_words) < 200:
padding = ['0'] * (200 - len(keep_words))
keep_words.extend(padding)
content = ' '.join(keep_words)
return content
def text_padding():
wv_model = Word2Vec.load('pretrain_model/word2vec/word2vec_newtrain.model')
wv_words = wv_model.wv.index2word
train = pd.read_csv('data/train_word_cut.csv')
train_text = list(train['text_word_cut'])
train_params = []
for text in train_text:
train_params.append((text,wv_words))
with Pool(12) as pool:
new_train_text = list(tqdm(pool.imap(function,train_params),total=len(train_params), desc='train set padding:'))
pool.close()
pool.join()
train['text_padding'] = new_train_text
train = train[['text_padding', 'label']]
train.to_csv('data/train_padding.csv', index=False)
dev = pd.read_csv('data/dev_word_cut.csv')
dev_text = list(dev['text_word_cut'])
dev_params = []
for text in dev_text:
dev_params.append((text, wv_words))
with Pool(12) as pool:
new_dev_text = list(tqdm(pool.imap(function, dev_params), total=len(dev_params), desc='dev set padding:'))
pool.close()
pool.join()
dev['text_padding'] = new_dev_text
dev = dev[['text_padding', 'label']]
dev.to_csv('data/dev_padding.csv', index=False)
if __name__ == '__main__':
text_padding()3、文本向量化
这里已经把文本进行了padding,因此就文本长度就是固定的了。把一篇篇的文档进行向量化,那么操作应该怎样进行呢?直接简单粗暴的使用cat式的操作,就是把文档的每个词的词向量cat起来,形成文档向量(这里是粗糙的做法,有论文提出一些新的方法,怎么构造出一个好的文档向量,进行文本分类和相似性计算)。代码如下:
def word2vec_paddings_tensor(self,data_list):
output = []
for data,label in tqdm(data_list,desc='text to vord2vec:'):
vec = []
for word in data:
v = self.wv_model[word].tolist()
vec.append(v)#这里的vec.append()有点类似cat的操作。
vec = torch.tensor(vec)#这里转化为tensors,后续可以用到GPU上训练,vec就是我们需要的文档向量
label = torch.tensor(int(label))
res = (vec,label)
output.append(res)
return output为了方便的读取文本形成tensor和用于后续的训练,就需要创建一个DataReader之类的。这个比较固定了,直接上代码:
from torch.utils.data import Dataset
import torch
from gensim.models import Word2Vec
import pandas as pd
from tqdm import tqdm
import numpy as np
class ReadDataSet(Dataset):
def __init__(self,file_path,repeat=1):
self.max_sentence_length = 200
self.repeat = repeat
self.wv_model = Word2Vec.load('pretrain_model/word2vec/word2vec_newtrain.model')
self.wv_words = self.wv_model.wv.index2word
self.wv_dim = 100
self.data_list = self.read_file(file_path)
self.output = self.word2vec_paddings_tensor(self.data_list)
def read_file(self,file_path):
data_list = []
df = pd.read_csv(file_path)# tsv文件
texts, labels = df['text_padding'], df['label']
for text, label in tqdm(zip(texts, labels),desc='read data from csv files:'):
text = text.split(' ')[0:self.max_sentence_length]
data_list.append((text,label))
return data_list
def word2vec_paddings_tensor(self,data_list):
output = []
for data,label in tqdm(data_list,desc='text to vord2vec:'):
vec = []
for word in data:
v = self.wv_model[word].tolist()
vec.append(v)#这里的vec.append()有点类似cat的操作。
vec = torch.tensor(vec)#这里转化为tensors,后续可以用到GPU上训练,vec就是我们需要的文档向量
label = torch.tensor(int(label))
res = (vec,label)
output.append(res)
return output
def __getitem__(self, item):
text = self.output[item][0]
label = self.output[item][1]
return text,label
def __len__(self):
if self.repeat == None:
data_len = 10000000
else:
data_len = len(self.output)
return data_len注意上述中的函数:def __getitem__(self, item)和def __len__(self)这两个函数比较重要。
4、TexTCNN模型构造
简单的描叙一下TextCNN,就是把二维的CNN卷积神经网络应用到文本特征提取中。构造模型的时候注意,卷积核和通道数,以及输出数目,直接上代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TextCNN(nn.Module):
def __init__(self):
super(TextCNN,self).__init__()
class_num = 8
embedding_dim = 100
ci = 1
kernel_num = 25
# kernel_sizes = [3,4,5]
# self.convs = nn.ModuleList([nn.Conv2d(ci,kernel_num,(k,embedding_dim/2))for k in kernel_sizes])
# #含义说明:nn.Conv2d(ci,kernel_num,(k,embedding_dim))
# #ci就是输入的通道数目,是要和数据对的上的;kernel_num这里的意思就是输出通道数目;(k,embedding_dim)卷积核的形状,也就是2维度的k*embedding_dim
# #nn.Conv2d(ci,cj,k)这里的K就是表示卷积核的形状是正方形的,k*k
self.conv1 = nn.Conv2d(ci, kernel_num, (3, int(embedding_dim))) #这里一定要输入4维向量[B,C,L,D]
self.conv2 = nn.Conv2d(ci, kernel_num, (5, int(embedding_dim)))
self.conv3 = nn.Conv2d(ci, kernel_num, (7, int(embedding_dim)))
self.conv4 = nn.Conv2d(ci, kernel_num, (9, int(embedding_dim)))
self.dropout = nn.Dropout(0.5)#丢掉10%
self.classificer = nn.Linear(kernel_num*4,class_num)
def conv_and_pool(self, x, conv):
#(B, Ci, L, D)
x = F.relu(conv(x))#(B,kernel_num,L-3+1,D-D+1)
x = x.squeeze(3)# (B, kernel_num, L-3+1)
x = F.max_pool1d(x, x.size(2))#(B, kernel_num,1)
x = x.squeeze(2)# (B,kernel_num) squeeze压缩维度
return x
def forward(self,x):
#size(B,L,D)
x = x.unsqueeze(1) #(B, Ci, L, D)#unsqueeze增加维度
x1 = self.conv_and_pool(x, self.conv1) # (B,kernel_num)
x2 = self.conv_and_pool(x, self.conv2) # (B,kernel_num)
x3 = self.conv_and_pool(x, self.conv3) # (B,kernel_num)
x4 = self.conv_and_pool(x, self.conv4) # (B,kernel_num)
x = torch.cat((x1, x2, x3,x4), 1) # (B,len(Ks)*kernel_num)
x = self.dropout(x) # (B, len(Ks)*kernel_num)
logit = self.classificer(x) # (B, C)
return logit注意每个输入输出向量shape的对应,不熟悉的就需要慢慢调试。代码注释中已经对卷积核的一些情况作了一些说明。
模型训练没有特别注意的事项,只需要把batch_size、学习率,优化器以及学习率调整策略设置好。当然模型可视化监控,可以使用tensorboardx来监控loss、准确率变化以及模型的结构等。具体的代码也不放在这里了,文末放上自己的github,上面有全部的项目代码。这里有必要把tensorboardx监控loss和准确率及模型之类的代码说一说。
from tensorboardX import SummaryWriter
writer = SummaryWriter('runs/exp')
writer.add_scalar('train_loss', loss.item(), global_step=global_step)
writer.add_scalar('dev_loss', dev_loss.item(), global_step=global_step)
writer.add_scalar('train acc', train_acc, global_step=global_step)
writer.add_scalar('dev acc', dev_acc, global_step=global_step)
writer.close()在训练代码中添加上以上代码,其中SummaryWriter('runs/exp')就是确定把你的运行日志保存到'runs/exp‘路径下。然后把各种指标添加到add_scalar中。最后在项目目录下终端执行以下命令:
tensorboard --logdir=runs结果就会出来一个浏览器地址,打开就可以看到我们训练的过程了。上图:
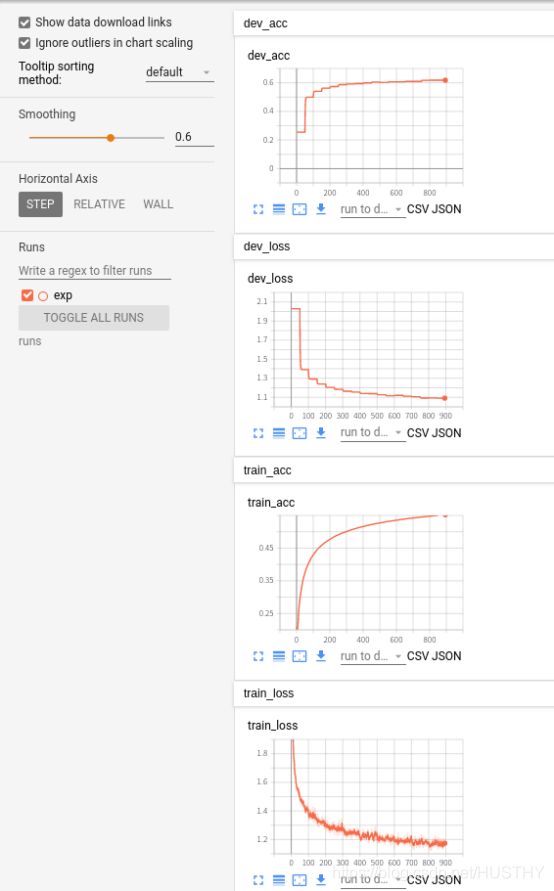
训练过程中的训练集和验证集的准确率已经loss变化情况都能很直观的观测!最终观测到的准确率是65%。
三、TextRNN模型长文本分类
TextRNN其实就是一个Bilstm+Linear的网络,整个流程和方案其实和上面的TextCNN是一样的。主要是模型的结构不一样的,直接上TextRNN结构代码:
import torch
import torch.nn as nn
"""
TextRNN,其实就是利用了Bilstm把句子的最后时刻或者说是最后那个字(这里可能不好理解)的hidden state,拿出来喂入分类器中,进行分类的。
这里仍然没有使用随机的embedding,我们仍然使用word2vec的词向量,经过操作来生成文本向量。
开始hidden_size设置为200,发现效果太差了,loss都不下降的
50词语的时候验证集准确率能到73%
训练过程中还是要监控验证集准确率
"""
class TextRNN(nn.Module):
def __init__(self):
super(TextRNN,self).__init__()
self.embedding_dim = 100 #文本词或者字的向量维度
self.hidden_size = 50 #lstm的长度,可以和seq_legth一样,也可以比它长
self.layer_num = 2
self.class_num = 8
self.lstm = nn.LSTM(self.embedding_dim, # x的特征维度,即embedding_dim
self.hidden_size, # stm的长度,可以和seq_legth一样,也可以比它长
self.layer_num, # 把lstm作为一个整体,然后堆叠的个数的含义
batch_first=True,
bidirectional=True
)
self.classificer = nn.Linear(self.hidden_size*2,self.class_num)#bidirectional双向就是2,单向就是1
def forward(self,x):
#x的维度为(batch_size, time_step, input_size=embedding_dim)
# 隐层初始化
# h0维度为(num_layers*direction_num, batch_size, hidden_size)
# c0维度为(num_layers*direction_num, batch_size, hidden_size)
h0 = torch.zeros(self.layer_num*2,x.size(0),self.hidden_size).to('cuda')
c0 = torch.zeros(self.layer_num*2,x.size(0),self.hidden_size).to('cuda')
#out维度为(batch_size, seq_length, hidden_size * direction_num)
out,(hn,cn) =self.lstm(x,(h0,c0))
#最后一步的输出, 即(batch_size, -1, output_size)
logit = self.classificer(out[:,-1,:]) # (B, C)
return logit这个模型中,需要注意的就是Lstm模型构建的参数,就是embedding_dim、hidden_size和layer_num的设置,还有输入向量和(h0,c0)等。说明一下:这里lstm的time_step也就是代码中的hidden_size应该就是等同于句子的长度,或者要比它长,短了应该不行的。这个方案使用的词向量采用的是word2vec,文档向量仍然是用每个词的词向量进行cat来表示的。另外一方面,关于模型效果和loss变化与输入向量的长度的关系。
TextRNN,其实就是利用了Bilstm把句子的最后时刻或者说是最后那个字(这里可能不好理解)的hidden state,拿出来喂入分类器中,进行分类的。
这里仍然没有使用随机的embedding,我们仍然使用word2vec的词向量,经过操作来生成文本向量。
开始hidden_size设置为200,发现效果太差了,loss都不下降的
50词语的时候验证集准确率能到73%个人经验,lstm对文本的长度300个字以内,训练的时候还算比较容易。直接贴上训练过程的最终结果和训练指标变化。

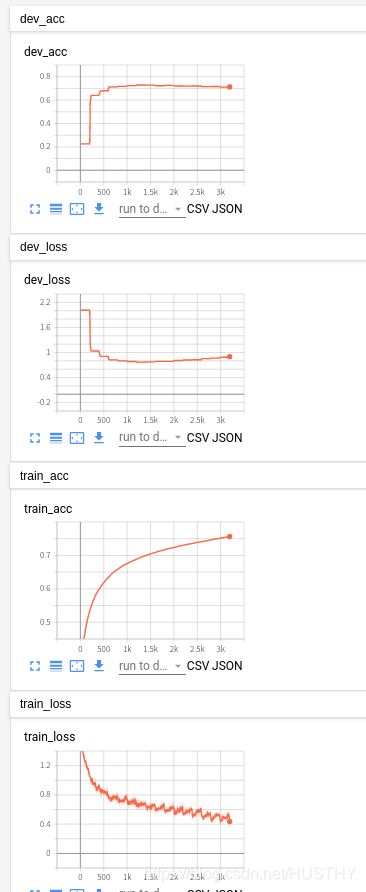
最终的显示结果是验证集准确率72.88%,但是这里用的是50个词语的长度,和上面的TextCNN结果那个不能进行严格的比较。
四、TextRNN+ATT模型长文本分类
顾名思义,这个模型就是在上述的模型中添加一个attention机制。attention机制有很多类型,这里就是用了普通的软注意力机制。直接上代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
"""
这里需要实现一个attention模块,这里就是用一般的attention,而不是特殊的self-attention机制等
attention的一种公式:
M = tanh(H)
a = softmax(WM)
att_score = H*a
上面的是矩阵形式
"""
class TextRNN_Att(nn.Module):
def __init__(self):
super(TextRNN_Att,self).__init__()
self.embedding_dim = 100
self.hidden_size = 50 #lstm的长度,可以和seq_legth一样,也可以比它长
self.layer_num = 2
self.class_num = 8
self.attention_size = 256
self.lstm = nn.LSTM(self.embedding_dim, # x的特征维度,即embedding_dim
self.hidden_size, #lstm的时间长度,这里可以表示为文本长度
self.layer_num, #把lstm作为一个整体,然后堆叠的个数的含义
batch_first=True,
bidirectional=True
)
self.classificer = nn.Linear(self.hidden_size*2,self.class_num)#bidirectional双向就是2,单向就是1
def attention(self,lstm_output):#lstm_output[batch_size, seq_length, hidden_size * direction_num]
"""
:param lstm_output:
:return: output
这个是普通注意力机制attention的一种公式:
M = tanh(H)
a = softmax(WM)
att_score = H*a
上面的是矩阵形式
"""
#初始化一个权重参数w_omega[hidden_size*layer_num,attention_size]
#u_omega[attention_size,1]
w_omega = nn.Parameter(torch.zeros(self.hidden_size*self.layer_num,self.attention_size)).to('cuda')
u_omega = nn.Parameter(torch.zeros(self.attention_size,1)).to('cuda')
#att_u[b,seq_length,attention_size]
att_u = torch.tanh(torch.matmul(lstm_output,w_omega))
# print('att_u',att_u)
# print('att_u', att_u.size())
#att_a[b, seq_length, 1]
att_a = torch.matmul(att_u,u_omega)
# print('att_a', att_a)
# print('att_a', att_a.size())
# att_score[b, seq_length, 1]
att_score = F.softmax(att_a,dim=1)
# print('att_score', att_score)
# print('att_score', att_score.size())
# att_output[b, seq_length, hidden_size * direction_num]
att_output = lstm_output*att_score
# print('att_output', att_output)
# print('att_output', att_output.size())
# output[b, hidden_size * direction_num]
output = torch.sum(att_output,dim=1)
# print('output', output)
# print('output', output.size())
return output
def forward(self,x):
#x的维度为(batch_size, time_step, input_size=embedding_dim)
# 隐层初始化
# h0维度为(num_layers*direction_num, batch_size, hidden_size)
# c0维度为(num_layers*direction_num, batch_size, hidden_size)
h0 = torch.zeros(self.layer_num*2,x.size(0),self.hidden_size).to('cuda') #定义一定要用torch.zeros(),torch.Tensor()只是定义了一个类型,并没有赋值
c0 = torch.zeros(self.layer_num*2,x.size(0),self.hidden_size).to('cuda')
#out维度为(batch_size, seq_length, hidden_size * direction_num)
lstm_out,(hn,cn) =self.lstm(x,(h0,c0))
# attn_output[b, hidden_size * direction_num]
attn_output = self.attention(lstm_out)#注意力机制
logit = self.classificer(attn_output)
return logit
具体的attention模块儿,看对应的公式就可以得到具体的实现。具体的模型中各个向量输入的维度和意义都在注释代码中予以注释,可以详细阅读。后续模型训练和数据文本读取都是同TextCNN那个方案中的是一样的,不做说明了。贴上结果和训练过程:
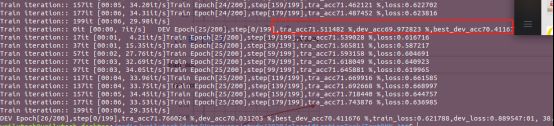
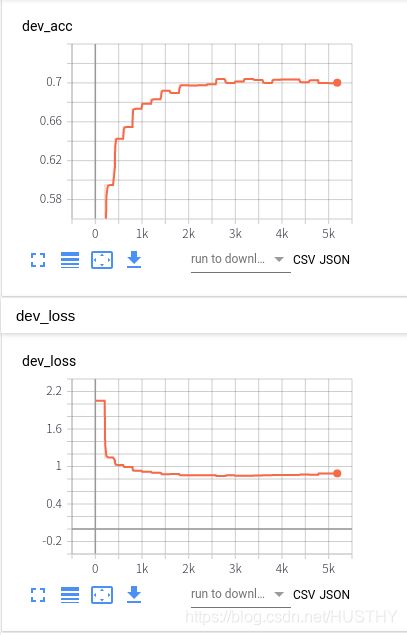
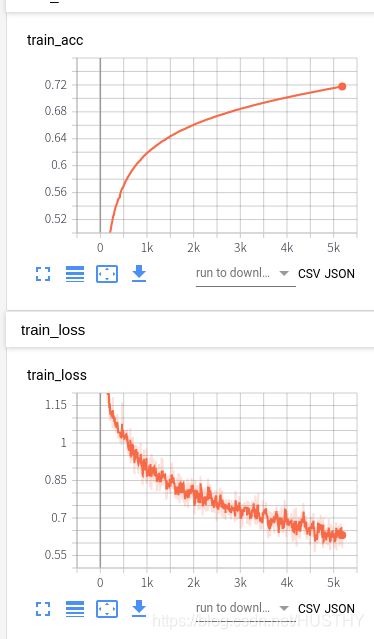
可以看到这里的验证集的准确率在BiLstm添加上了Attention模型了,效果还有些降低。这里可能的原因是attention捕捉的特征用于分类,反而在这里并没有直接使用lstm的效果要好,所以还是不能太迷信模型,一定要去做实验!
五、Bert模型长文本分类(不更新bert权重和更新bert权重)
首先说一下使用bert模型来做分类的方案,其实差不多。第一种就是把Bert模型仅仅是看着一个提取向量的工具,本身不参与任务的训练过程中,bert模型的权重参数就不更新;另外一种还是把bert模型看作一个提取向量的工具,本身也是参与任务的训练过程的,bert模型的权重参数会更新——这种方案其实就是fine-tune。其实这两种方法的代码实现可以说是几乎一模一样的,唯一的一个就是在模型的构建的时候是不是把梯度锁住,这样就能进行权重更新和权重不更新的切换。
TextBert模型的构建,其实逻辑很简单,就是输入文本,经过bert,得到输出向量,然后把输出向量喂入分类器中(nn.Linear())等,就可以得到分类结果。上代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from transformers import BertModel
"""
这里的模型设置的是bert模型在训练的过程中不会改变权重,这个可以和bert权重参与训练做对比
"""
class TextBert(nn.Module):
def __init__(self,args):
super(TextBert,self).__init__()
self.bert = BertModel.from_pretrained(args.model_path)
#param.requires_grad = False 训练的时候不改变初始预训练bert的权重值
for param in self.bert.parameters():
param.requires_grad = args.requires_grad
self.cl1 = nn.Linear(768,768)
self.dropout = nn.Dropout(0.5)
self.cl2 = nn.Linear(768,8)
def forward(self,input_ids,input_mask):
embedding = self.bert(input_ids,input_mask)[0]
mean_embedding = torch.mean(embedding,dim=1)
x = self.dropout(mean_embedding)
x = self.cl1(x)
x = self.dropout(x)
logit = self.cl2(x)
return logitparam.requires_grad = False 训练的时候不改变初始预训练bert的权重值这个参数就能控制Bert模型本身是否参与训练从而更新参数的。这个方案麻烦的地方在于把文本数据转化为向量,然后能够根据batch_size大小来喂入模型中,所以这里就需要一个dataLoader类似的模块。我们自己写一个代码如下:
from torch.utils.data import Dataset
from transformers import BertTokenizer
import torch
from tqdm import tqdm
import os
import logging
logger = logging.getLogger(__name__)
class ReadDataSet(Dataset):
def __init__(self,data_file_name,args,repeat=1):
self.max_sentence_length = args.max_sentence_length
self.repeat = repeat
self.tokenizer = BertTokenizer.from_pretrained(args.model_path)
self.process_data_list = self.read_file(args.data_file_path,data_file_name)
def read_file(self,file_path,file_name):
file_name_sub = file_name.split('.')[0]
file_cach_path = os.path.join(file_path,"cached_{}".format(file_name_sub))
if os.path.exists(file_cach_path):#直接从cach中加载
logger.info('Load tokenizering from cached file %s', file_cach_path)
process_data_list = torch.load(file_cach_path)
return process_data_list
else:
file_path = os.path.join(file_path,file_name)
data_list = []
with open(file_path, 'r') as f:
lines = f.readlines()
for line in tqdm(lines, desc='read data'):
line = line.strip().split('\t')
data_list.append((line[0], line[1]))
process_data_list = []
for ele in tqdm(data_list, desc="Tokenizering"):
res = self.do_process_data(ele)
process_data_list.append(res)
logger.info('Saving tokenizering into cached file %s',file_cach_path)
torch.save(process_data_list,file_cach_path)#保存在cach中
return process_data_list
def do_process_data(self, params):
res = []
sentence = params[0]
label = params[1]
input_ids, input_mask = self.convert_into_indextokens_and_segment_id(sentence)
input_ids = torch.tensor(input_ids, dtype=torch.long)
input_mask = torch.tensor(input_mask, dtype=torch.long)
label = torch.tensor(int(label))
res.append(input_ids)
res.append(input_mask)
res.append(label)
return res
def convert_into_indextokens_and_segment_id(self, text):
tokeniz_text = self.tokenizer.tokenize(text[0:self.max_sentence_length])
input_ids = self.tokenizer.convert_tokens_to_ids(tokeniz_text)
input_mask = [1] * len(input_ids)
pad_indextokens = [0] * (self.max_sentence_length - len(input_ids))
input_ids.extend(pad_indextokens)
input_mask_pad = [0] * (self.max_sentence_length - len(input_mask))
input_mask.extend(input_mask_pad)
return input_ids, input_mask
def __getitem__(self, item):
input_ids = self.process_data_list[item][0]
input_mask = self.process_data_list[item][1]
label = self.process_data_list[item][2]
return input_ids, input_mask,label
def __len__(self):
if self.repeat == None:
data_len = 10000000
else:
data_len = len(self.process_data_list)
return data_len
注意到bert模型输入需要3个向量,它们分别是input_ids、segment_ids和pos_ids等。所以需要把文本对应的这3个向量得到,然后转化为tensor类型。由于数据量比较巨大,所以在第一次得到这些tensor后,可以做一个序列化操作,保存在本地,下次训练的时候,可以直接读取加快速度,这里序列化采用的是torch.save()方法。同时为了提高模型的准确率,我们文本的长度没有选择Bert—base的极限510,而是选择了400,期待能得到好的结果。
模型训练
当bert模型权重更新的时候,这个时候初始的LR一定要设置为比较常见的1e-5、2e-5之类的,另外优化器也使用比较常见的AdamW。其他的也就没有什么可说的了,早停止呀,epoch设置等都是比较基础的。
当bert模型权重不更新的时候,初始的LR可以设置的稍微大一些,0.001之类的比较常见的,其他的同上。
直接上结果:
1、Bert模型不参与训练

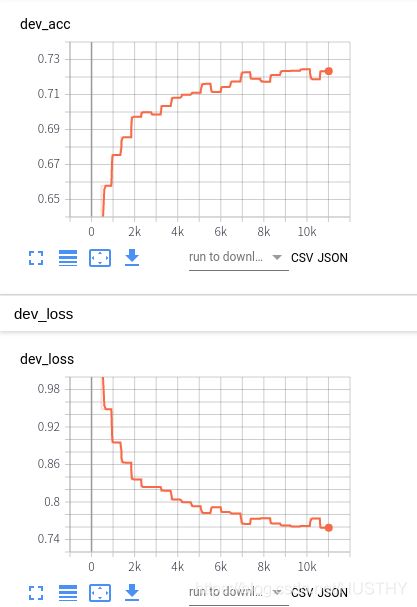
准确率72.94%,都要比上述的模型效果要好,果然还是bert厉害!
2、Bert模型参数训练
![]()
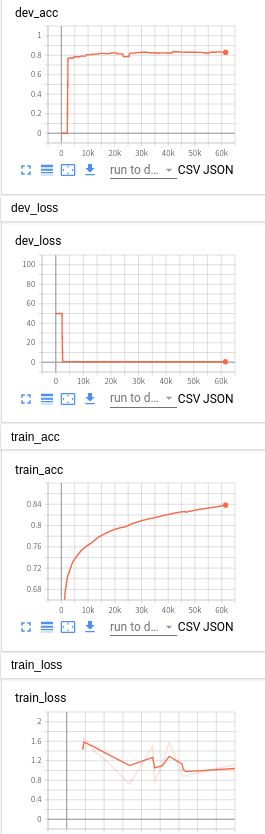
准确率83.59%,比之前的所有模型的性能都要好,而且还是采用了400字的长度。模型可以说这个效果是完全吊打其他的模型。
总结和展望
本文针对中文长文本的多分类问题,做了不同模型的全流程实现方案的展示,意在熟悉每个流程的coding和模型的一些细节。同时也可以对不同模型在长文本分类的效果上有一个基线,以后做类似的任务,就能很快的选择技术方案和排错。同时也对模型训练过程监控的可视化显示有了一个尝试,说明越来越有炼丹师的气质了呀!哈哈哈哈哈哈
展望,其实目前业界对广泛的长文本分类并没有效果很好的方法,不同的论文中也提出了一些尝试和方法。在我的另一篇博客中——bert模型简介、transformers中bert模型源码阅读、分类任务实战和难点总结——是有提到的,比如说暴力截断呀、特定选取、滑窗法之类的。最近在看一篇论文,文章的创新思路也比较奇特,实验部分提到的文本分类的效果很好,得到了state-of-art。有空了可以把它的算法做做实验看看,如果效果挺好,那么长文本分类任务就有了一种好的解决办法。后续应该会有一个博客分享的。
关于这个多模型的长文本分类项目我全部的代码,在我的github上。另外有关数据集的问题,这个是公开的一个专利数据集,可以自行去搜索一下,我记得数据集好像是在国家什么专利机构的网站上,貌似要注册一下,然后才能下载的。
该项目全部代码地址:https://github.com/HUSTHY/classificationTask
参考文章:
Pytorch CNN搭建(NLP)
pytorch实现textCNN
中文文本分类 pytorch实现