NLP发展第四阶段
Prompt learning系列之入门篇
提纲
1 简介
2 NLP发展的四个阶段
3 Prompt learning
4 Prompt engineering
5 Answer engineering
6 Multi-prompt learning
7 Training strategy
8 总结
参考文献
1、简介
Prompt learning作为近期NLP的新宠,热度不断攀升,在接下来的一段日子,大概率还是会处于一个风口的位置。什么是Prompt learing?就是通过引入模版来将原始输入改造成类似于完形填空的格式,让语言模型去回答,进而推断出下游任务的结果。prompt leanring是如何发展形成的?包括组成?类型?面临哪些挑战?带着这些问题,我们对相关内容做了一定的梳理,希望能让大家对于Prompt learning整个框架有个清晰的认识。

2、NLP发展的四个阶段
要了解一个人的话需要去了解他/她的过去。prompt learning作为NLP发展的重大产物,又有怎样的一段过去呢?纵观整个NLP的发展,它可以分为以下几个阶段。
a) 第一个阶段:feature engineering
对应下图中的Fully Supervised Learning (Non-Neural Network),这是大家常提的特征工程阶段,由于缺乏充分的有监督训练数据,早期的NLP倚重于前期的特征工程,这需要相关研究人员或者专业人士利用自己扎实的领域知识从原始数据中定义并提取有用的特征供模型学习。这个阶段构建特征依赖于大量的人工,特征工程的效果也极大程度影响到模型的最终表现。
b) 第二个阶段:architecture engineering
对应下图中的Fully Supervised Learning (Neural Network),随着神经网络的到来,NLP逐渐过渡到架构工程这个阶段,在这个时期,大家更注重于如何设计一个合理的网络结果去学习有用的特征,从而减少对人工构建特征的依赖。
c) 第三个阶段:objective engineering
对应下图中的Pre-train, Fine-tune,这也是前几年常挂在嘴边的预训练时代。在这个时期,NLP流行的方法基本都是在大量语料上进行预训练,然后再在少量的下游任务下完成微调。**在这种范式下,更注重于目标的设计,合理设计预训练跟微调阶段的目标函数,对最终的效果影响深远。**前面两个阶段都依赖于有监督学习,但是这个阶段里的预训练可以不需要有监督的数据,极大的降低了对监督语料的依赖。
d) 第四个阶段:prompt engineering
对应下图中的Pre-train, Prompt, Predict,也就是本章节想要介绍的prompt learning的时期。在这个时期,依旧会在大量语料上进行预训练,但是在特定下游任务下可以通过引入合适的模版(prompt)去重构下游任务,管控模型的行为,实现zero shot或者few shot。一个合适的模版甚至可以让模型摆脱对下游特定任务数据的要求,所以如何构建一个合理有效的prompt成为了重中之重。

3、Prompt learning
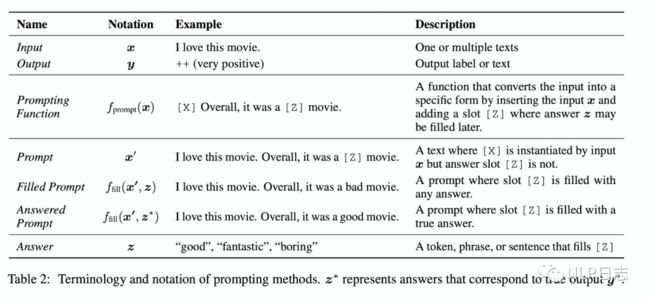
传统的监督学习任务,是去训练一个模型P(y|x),接收x作为输入,去预测y。Prompt learning则不然,它**依赖于预训练语言模型P(x),通过引入合适的模版template将输入x调整为完形填空格式的x’,调整后的输入x’里含有某些空槽,利用语言模型P将空槽填充后就可以推断出对应的y。**例如对于情感分析任务,传统的做法就是训练一个判别模型,去预测输入x对应的标签是positive或者negative,但是如果是prompt learning,则是利用合适模版,将输入x调整为 [x], it is [z]。然后作为语言模型的输入去预测相应z的取值,如果z是positive相关的词,就表示原始输入x是positive,反之就是negative的。
Prompt learning包括三个部分,分别是prompt addition,answer search, answer mapping。
a) Prompt addition
选择合适的模版,定义函数fprompt(x),可以将原始的输入x转化为x‘,即fprompt(x)=x’。经过该函数转化得到的输入都是带有空槽,槽位上的预测值会直接决定最后的结果。另外,这里的模版不仅仅可以是离散化的token,也可以连续的向量。在不同的下游任务,可以灵活调整,选择合适的模版。
b) Answer search
通过prompt函数后,将x’输入到语言模型,去预测使得语言模型得分最高的候选槽值。Answer search指的就是从所有可能的候选槽值进行搜索,然后选择合适的槽值填充到对应的空槽里。这里槽值的所有可能结果的集合为Z,对于生成任务而言,Z包括所有的token,但是对于分类任务而言,Z只包含跟特定分类任务相关的一部分token。例如对于之前那个例子而言,Z={positive相关的词语,negative相关的词语}
c) Answer mapping
当通过answer search得到合适的槽值时,需要根据槽值推断最终的预测结果。这部分比较直接,假如是生成任务,那么填充的槽值就是最终的结果。但如果是分类任务,就需要根据相应的槽值归纳到具体的类中。例如情感分类中,如果把跟positive相关的槽值都归类到positive一类,把跟negative相关的槽值归类到negative一类中。
在了解prompt learning的基本组成后,不容易发现,有以下几个方面都会影响prompt learning的最终效果,后续我们再围绕着这几点分别展开。
a) Prompt engineering,如何选择一个合适的模版,也就是设计合适的模版函数,是整个prompt learning的第一个步。
b) 预训练语言模型的选择, 如何预测空槽位置上的答案依赖于预训练语言模型的得分,同时预训练语言模型又有4大类。(在文本生成系列的文章对这这部分的介绍已经很详细了,这里就不赘述了。)
c) Answer engineering,如何构建一个合适的答案候选集以及一个从答案到最终结果的映射。
d) Expanding the paradigm,如何基于基础的prompt learning去扩展,包括multi prompt等。
e) Training strategy,如何选择训练策略,去训练一个合适的模型。
4、Prompt engineering
Prompt engineering,如何构建一个合适的模版函数,使得在下游任务能取得最高效的表现。Prompt learning利用预训练语言模型去预测最终结果,那么如何将输入x转化为语言模型擅长处理的样式就是Prompt engineering的工作。一个不合适的prompt function会导致语言模型不能做出令人满意的预测。为了最终任务的效果,我们需要根据语言模型和下游任务的特性,去构建合理的prompt。
如果模版处于输入x之中,那么称为cloze prompt,这种情形多应用于使用掩码语言模型的场景,它能够紧密的跟掩码语言模型的预训练过程相配合。如果输入x全部位于模版内容之前,那么称为prefix prompt,这种情形多应用于生成任务或者使用使用自回归的语言模型的场景,它能跟从左往右的回归模型本质更加匹配。
Prompt可以是通过人工构建的,根据人的经验知识构建合理的prompt,这也是最直接的方式。但是通过人工构建的模版需要耗费时间跟精力, 而且即便是专业人员也不一定能构建得到最优的prompt,为此,衍生了不少自动选择prompt的方法,其中包括离散的prompt,也包括连续的prompt。
5、Answer engineering
**Answer engineering旨在寻找一个合适的答案空间Z以及一个从答案到最终输入y的一个映射。Prompt learning之所以能实现few shot甚至zero shot,是依仗于预训练语言模型强大的泛化能力。**但是语言模型在预测时都是针对全词表的,对于下游任务而言并不一定需要全词表的,例如情感分析任务下如果预测到人称代词时要怎么推断最终结果的情绪呢?为此,Answer engineering要去寻找一个跟下游任务匹配的答案空间,也就是构建候选集,并定义好答案空间到最终输出之间的映射,候选词跟最终输出的对应关系。
Answer engineering里的答案空间可以是由token,或者片段,或者完整的句子组成。**Token跟片段的情形多见于分类相关任务,完整的句子多见于生成相关任务。**答案空间同样也可以通过人工构建,也可以通过模型去搜索查找。大部分的方法构造的候选集都是离散化的,只有很少部分方法是连续化的。
6、Multi-prompt learning
跟打比赛时经常会集成多个模型的思路如出一辙,相对于单个prompt,多个prompt往往能提高prompting methods的有效性。常见的多个prompt的方法有以下几种类型。

a) Ensemble
多个prompt,每个prompt都按照单prompt的方法并行进行,然后再把最终的结果汇总,可以通过加权或者投票的方式汇总多个单prompt的方法的结果。
b) Augmentation
增强的方式其实就是找一个跟当前问题相似的case,然后将这个case跟当前输入x‘一起输入,这种模型就可以根据那个case对x‘做出更精准的预测了。
c) Composition
同时利用多个prompt构建prompt函数,每个prompt负责一个子任务,把多个prompt的内容融合到一起,同时进行多个子任务的预测。例如关系抽取任务,有的prompt负责实体识别,有的prompt负责判断实体间的关系。
d) Decomposition
对于有多个预测值的任务,将原始的任务拆分程多个子任务,引入多个prompt,分别处理子任务,彼此隔离。也就是把多个预测值的任务拆分程多个单prompt任务去分别处理。
7、Training strategy
根据是否需要在语言模型的基础上引进新的跟模版相关的参数,以及模型参数是否冻结可以分为以下4种。(图中第一种不算是prompt learning)
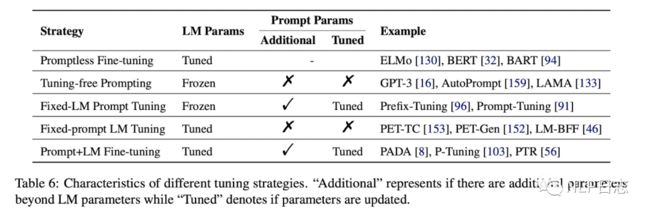
a) Prompt fine-tuning
NLP发展史上第三个阶段的先预训练然后再微调的方法。
b) Tuning-free Prompting
不需要微调,直接利用一个prompt做zero-shot任务
c) Fixed_LM Prompt Tuning
引进了额外的跟prompt相关的的参数,通过固定语言模型参数,去微调跟prompt相关的参数。
d) Fixed-prompt LM Tuning
引进了额外的跟prompt相关的的参数,通过固定prompt相关参数,去微调语言模型参数。
f) Prompt+LM Tuning
同时微调语言模型跟prompt相关的参数。
8、总结
Prompt learning,充分利用了预训练语言模型强大的泛化能力,极大的减少了对下游任务有监督数据的依赖,能实现few shot甚至zero shot,对于当下数量众多的NLP下游任务,有很大的应用前景。但是关于如何构建prompt,如何选择语言模型,构建候选答案空间,构建答案到最终输出的映射,如何选择训练策略,如何寻找一个最佳配置使得下游任务效果达到最优,依旧是个需要持续探索的事情。
参考文献
\1. (2021, ) Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
https://arxiv.org/pdf/2107.13586.pdf