猿创征文|《一文搞懂NMS发展历程》Soft-NMS、Weighted NMS、IoU-Net、Softer-NMS、Adaptive NMS、DIoU-NMS
猿创征文|《一文搞懂NMS发展历程》Soft-NMS、Weighted NMS、IoU-Net、Softer-NMS、Adaptive NMS、DIoU-NMS
文章目录
- 猿创征文|《一文搞懂NMS发展历程》Soft-NMS、Weighted NMS、IoU-Net、Softer-NMS、Adaptive NMS、DIoU-NMS
-
-
- 1. NMS介绍
- 2. NMS算法流程
- 3. NMS 过程图例
-
- 3.1 单类别例子
- 3.2 多类别例子
- 4. Soft-NMS(ICCV2017)
- 5. Weighted-NMS(ICMEW2017)
- 6. 分类置信度优先NMS总结
- 7. IOU-Guided NMS/IOU-Net(ECCV2018)
- 8. Softer NMS(CVPR2019)
- 9. Adaptive NMS(CVPR2019)
- 10. DIOU-NMS(AAAI2020)
- NMS总结
- 参考文献
-
分享个人的技术成长历程:我在去年九月份入门深度学习时只知道一种最基础的
NMS方式,现在我已经了解了不下6中NMS方式;我把这些NMS方式整理成了博文,分享给大家。
1. NMS介绍
在执行目标检测任务时,算法可能对同一目标有多次检测。NMS是一种让你确保算法只对每个对象得到一个检测的方法,即“清理检测”。如下图所示:
如果用一句话概括NMS的意思就是:筛选出一定区域内属于同一种类别得分最大的框

2. NMS算法流程
NMS 算法的大致过程:每轮选取置信度最大的 Bounding Box ,接着关注所有剩下的 BBox 中与选取的 BBox 有着高重叠(IoU)的,它们将在这一轮被抑制。这一轮选取的 BBox 会被保留输出,且不会在下一轮出现。接着开始下一轮,重复上述过程:选取置信度最大 BBox ,抑制高 IoU BBox。
NMS 算法流程:这是一般文章中介绍的 NMS,比较难懂。但实际上 NMS 的实现反而简单很多。

3. NMS 过程图例
- 单类别 NMS 的例子:有两只狗,怎样用 NMS 保证只留下两个 BBox?
- 多类别 NMS 的例子,有1只狗1只猫,我们怎么用NMS将侦测到的物件框将把猫和狗框出来。
3.1 单类别例子
1)理解 BBox 输入或输出格式,通常会见到两种格式:
-
第一种,BBox 中心位置(x, y) + BBox 长宽(h, w) + Confidence Score;
-
第二种,BBox 左上角点(x1,y1) + BBox 右下角点(x2,y2) + Confidence Score;
两种表达的本质是一样的,均为五个变量。与 BBox 相关的四个变量用于计算 IoU,Confidence Score 用于排序。
2)理解评估重叠的 IoU 指标,即“交并比”,如下图所示:

3)步骤:
第一步:对 BBox 按置信度排序,选取置信度最高的 BBox(所以一开始置信度最高的 BBox 一定会被留下来);
第二步:对剩下的 BBox 和已经选取的 BBox 计算 IoU,淘汰(抑制) IoU 大于设定阈值的 BBox(在图例中这些淘汰的 BBox 的置信度被设定为0)。
第三步:重复上述两个步骤,直到所有的 BBox 都被处理完,这时候每一轮选取的 BBox 就是最后结果。

具体流程
-
「确定是物体集合」= {空集合}
-
Run 1: 先将BBox依照置信度排序,置信度最高的BBox (红色) 会被选入「确定是物体集合」內,其他BBox会根据这步骤选出最高的BBox进行IoU计算,如果粉红色的IoU为0.6大于我们设定的0.5,所以将粉红色的BBox置信度设置为0。
此时「确定是物件集合」= {红色BBox }
-
Run 2: 不考虑置信度为0和已经在「确定是物体集合」的BBox,剩下來的物体继续选出最大置信度的BBox,将此BBox(黄色)丟入「确定是物体集合」,剩下的BBox和Run2选出的最大置信度的BBox计算IoU,其他BBox都大于0.5,所以其他的BBox置信度設置为0。
此时「确定是物件集合」= {红色BBox; 黄色BBox}
-
因为沒有物体置信度>0,所以结束NMS。
「确定是物件集合」= {红色BBox; 黄色BBox}。
在上面这个例子中,NMS 只运行了两轮就选取出最终结果:第一轮选择了红色 BBox,淘汰了粉色 BBox;第二轮选择了黄色 BBox,淘汰了紫色 BBox 和青色 BBox。注意到这里设定的 IoU 阈值是0.5,假设将阈值提高为0.7,结果又是如何?
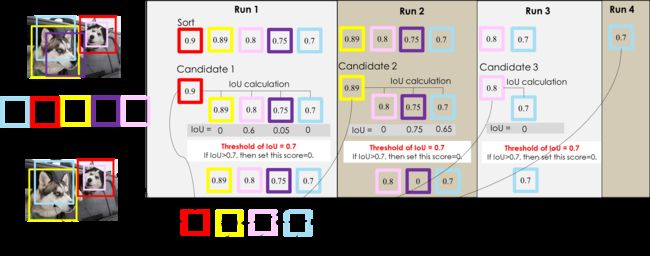
可以看到,NMS 用了更多轮次来确定最终结果,并且最终结果保留了更多的 BBox,但结果并不是我们想要的。因此,在使用 NMS 时,IoU 阈值的确定是比较重要的,但一开始我们可以选定 default 值(论文使用的值)进行尝试。由此可以知道,如果IoU阈值设定太高,可能会造成物件重复检测的问题。
3.2 多类别例子
第二个例子,有1只狗1只猫,我们怎么用NMS将侦测到的物件框将把猫和狗框出来

前面的范例一是标准的NMS程序,这边要搭配一下分类来看,范例二和标准NMS做法一样,先将「确定是物件集合」选出来,此例是NMS选出的BBox是{紫色BBox ; 红色BBox}。
这时候再搭配一下分类的机率,就可以把每个NMS选出的BBox做类别判断了(如下图,每个BBox都会带有一组机率)
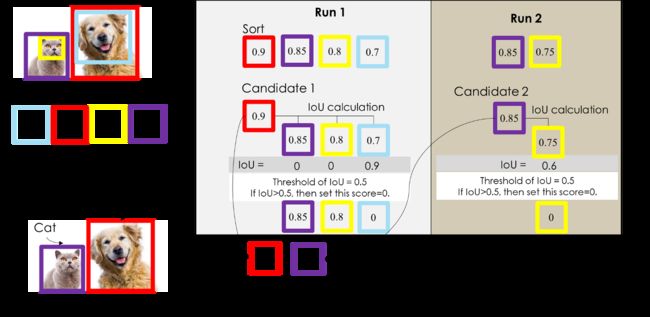
这边附上实际做法,先用一个阈值先初步去掉一些候选的BBox,不然假设一张图预选出一万个BBox,后面用CPU计算NMS会很花时间,所以会依据BBox的confidence score先去掉一些没用的BBox,然后再做NMS,如下图

如果是two stage算法,通常在选出BBox只会带有BBox中心位置(x, y)、BBox长宽(h, w)和confidence score,不会有类别的机率,因为程序是先选出BBox,在将选出BBox的feature map做rescale (一般用ROI pooling),然后再用分类器分类。
但如果是one stage作法,是直接BBox带有BBox中心位置(x, y)、BBox长宽(h, w)和confidence score,以及相对应的分类机率,相对于two stage少了后面rescale和分类的程序,所以计算量相对小。
虽然NMS可以处理掉较多的冗余框,但传统的NMS存在以下局限性:
- 循环步骤,GPU难以并行处理,运算效率低
- 以分类置信度为优先衡量指标 分类置信度高的定位不一定最准,降低了模型的定位准确度
- 直接提高阈值暴力去除bbox 将得分较低的边框强制性地去掉,如果物体出现较为密集时,本身属于两个物体的边框,其中得分较低的框就很有可能被抑制掉,从而降低了模型的召回率,且阈值设定完全依赖自身经验。
4. Soft-NMS(ICCV2017)
- NMS设定的局限性显然,对于
IoU≥NMS阈值的相邻框,传统NMS的做法是将其得分暴力置0,相当于被舍弃掉了,这就有可能造成边框的漏检,尤其是有遮挡的场景。 - Soft-NMS解决方案对
IoU大于阈值的边框,Soft-NMS采取得分惩罚机制,降低该边框的得分,即使用一个与IoU正相关的惩罚函数对得分进行惩罚。当邻居检测框b与当前框M有大的IoU时,它更应该被抑制,因此分数更低。而远处的框不受影响。

从实验结果来看的话,soft-NMS(红色)能够比较好的缓解掉传统NMS(蓝色)暴力剔除所带来的物体遮挡漏检情况。
Soft-NMS的类型
- 线性衰减型(不连续,会发生跳变,导致检测结果产生较大的波动);
- 指数高斯型(更为稳定、连续、光滑)
Soft-NMS的局限性
- 仍采用循环遍历处理模式,而且它的运算效率比
Traditional NMS更低。 - 对双阶段算法友好,但在一些单阶段算法上可能失效。(所以看
soft-NMS论文时会发现它只在two-stage模型上比较,可能是因为one-stage模型在16年才提出来,之后才开始大火)soft-NMS也是一种贪心算法,并不能保证找到全局最优的检测框分数重置。 - 遮挡情况下,如果存在location与分类置信度不一致的情况,则可能导致location好而分类置信度低的框比location差分类置信度高的框惩罚更多
- 评判指标是
IoU,即只考虑两个框的重叠面积,这对描述box重叠关系或许不够全面。
5. Weighted-NMS(ICMEW2017)
如果前面讲的Soft NMS是通过抑制机制来改善剔除结果(降低超阈值的得分策略),那么Weighted NMS(W-NMS)则是从极大值这个方面进行改进。W-NMS认为Traditional NMS每次迭代所选出的最大得分框未必是精确定位的,冗余框也有可能是定位良好的。因此,W-NMS通过分类置信度与IoU来对同类物体所有的边框坐标进行加权平均,并归一化。其中,加权平均的对象包括M自身以及IoU≥NMS阈值的相邻框。
-
优点:
Weighted NMS通常能够获得更高的Precision和Recall,一般来说,只要NMS阈值选取得当,Weighted NMS均能稳定提高AP与AR。 -
缺点:
(1)仍为顺序处理模式,且运算效率比
Traditional NMS更低。(2)加权因子是
IoU与得分,前者只考虑两个框的重叠面积;而后者受到定位与得分不一致问题的限制。
6. 分类置信度优先NMS总结
NMS、Soft-NMS及Weighted NMS的局限性:
- 都是以分类置信度优先的
NMS,未考虑定位置信度,即没有考虑定位与分类得分可能出现不一致的情况,特别是框的边界有模棱两可的情形时。 - 采用的都是传统的
IoU,只考虑两包围盒子之间的重叠率,未能充分反映两包围盒子之间相对位置关系。
7. IOU-Guided NMS/IOU-Net(ECCV2018)
前面所提到的NMS方法只将分类的预测值作为边框排序的依据。然而在某些场景下,分类预测值高的边框不一定拥有与真实框最接近的位置,因此这种标准不平衡可能会导致更为准确的边框被抑制掉。

之前NMS的局限性:
- 分类准确率和定位准确率的误匹配:从左下图看,
IoU与定位置信度高度相关(0.617),而与分类置信度几乎无关(0.217)。 - 边界框回归的非单调性与非可解释性:缺乏localization confidence使得被广泛使用的边界框回归方法缺少可解释性或可预测性。先前的工作曾指出bounding box迭代回归的非单调性,也就是说,应用多次之后bounding box回归可能有损bounding box定位表现。
在此背景下,旷视IOU-Net论文提出了IoU-Guided NMS,即一个预测框与真实框IoU的预测分支来学习定位置信度,进而使用定位置信度来引导NMS的学习。具体来说,就是使用定位置信度作为NMS的筛选依据,每次迭代挑选出最大定位置信度的框M,然后将IoU≥NMS阈值的相邻框剔除,但把冗余框及其自身的最大分类得分直接赋予M。因此,最终输出的框必定是同时具有最大分类得分与最大定位置信度的框。
IOU-Guided NMS优点:
- 通过该预测分解决了
NMS过程中分类置信度与定位置信度之间的不一致,可以与当前的物体检测框架一起端到端地训练,在几乎不影响前向速度的前提下,有效提升了物体检测的精度。 IoU-Guided NMS有助于提高严格指标下的精度,如AP75,AP90。(在IoU阈值较高时IoU-guided NMS算法的优势还是比较明显的(比如AP90),原因就在于IoU阈值较高时需要预测框的坐标更加准确才能有较高的AP值,这正好和IoU-guided NMS的出发点吻合。)
IoU-Guided NMS缺点:
- 顺序处理的模式,运算效率与
Traditional NMS相同。 - 需要额外添加
IoU预测分支,造成计算开销。 - 评判标准为
IoU,即只考虑两个框的重叠面积。
8. Softer NMS(CVPR2019)
总体概览从Softer-NMS的公式来看,Softer-NMS可以看成是前面三种NMS变体的结合,即:其极大值的选择/设定采用了与类似Weighted NMS(加权平均)的方差加权平均操作,其加权的方式采用了类似Soft NMS的评分惩罚机制(受Soft-NMS启发,离得越近,不确定性越低,会分配更高的权重),最后,它的网络构建思路与IOU-Guided NMS相类似。

与IOU-Guided NMS区别Softer-NMS与IOU-Guided NMS的出发点同样是解决定位与分类置信度之间非正相关的问题,所采用的思路一样是增加一个定位置信度的预测,但不一样的是前面提到的IoU-Guided NMS采用IoU作为定位置信度来优先排序,而这里Softer-NMS则是通过定位分布的方差来拉近预测边框与真实物体分布,即IoU-Guided NMS采用IoU作为定位置信度而Softer-NMS采用坐标方差作为定位置信度,具体的做法就是通过KL散度来判别两个分布的相似性。
其中,Softer NMS论文中有两个先验假设:
(1)Bounding box的是高斯分布
(2)ground truth bounding box是狄拉克delta分布(即标准方差为0的高斯分布极限)。
Softer-NMS的优点:
- 增加了定位置信度的预测,是定位回归更加准确与合理。
- 使用便捷,可以与
Traditional NMS或Soft-NMS结合使用,得到更高的AP与AR。
Softer-NMS的缺点:
- 顺序处理模式,且运算效率比
Traditional NMS更低。 - 额外增加了定位置信度预测的支路来预测定位方差,造成计算开销。
- 评判标准是
IoU,即只考虑两个框的重叠面积,这对描述box重叠关系或许不够全面。
9. Adaptive NMS(CVPR2019)
背景Adaptive NMS是在行人检测问题上来对Soft NMS改进的一种自适应阈值处理方法(即在软化得分的前提下继续软化阈值)。行人检测任务中,一个最大的问题就是目标在常规场景下一般处于密集状态。如何在解决密集检测以及密集检测之中目标之间相互遮挡的问题是行人检测的一大问题。在以往的研究中,NMS都采用单一阈值的处理方式。使用单一阈值的NMS会面临以下困境:较低的阈值会导致丢失高度重叠的对象(图中蓝框是未检测出来的目标),而较高的阈值会导致更多的误报(红框是检测错误的目标)。

所以,在密集检测场景中,我们希望:(1)在目标密集时,可以使用较大的阈值以保证更高的召回率;(2)在目标稀疏时,可以使用较小的阈值来剔除掉更多冗余的检测框。
思路与方法基于上述背景,Adaptive NMS应用了动态抑制策略,通过设计计了一个Density-subnet网络预测目标周边的密集和稀疏的程度,引入密度监督信息,使阈值随着目标周边的密稀程度而对应呈现上升或衰减。具体做法:
- 当邻框远离M时(即
IoU - 对于高度重叠的相邻检测,抑制策略不仅取决于与M的重叠,还取决于M是否位于拥挤区域。
- 当M处于密集区域时(即
Nm>Nt),目标密度dM作为NMS的抑制阈值;若M处于密集区域,其高度重叠的相邻框很可能是另一目标的真正框,因此,应该分配较轻的惩罚或保留。 - 当M处于稀疏区域时(即
Nm≤Nt),初始阈值Nt作为NMS的抑制阈值。若M处于稀疏区域,惩罚应该更高以修剪误报。
- 当M处于密集区域时(即
Adaptive NMS优点:
- 可以与前面所述的各种
NMS结合使用。 - 对遮挡案例更加友好。
- 双阶段和单阶段的检测器都有效果。(CVPR2019 Oral)
Adaptive NMS缺点:
- 与
Soft-NMS结合使用,效果可能倒退 (受低分检测框的影响)。 - 顺序处理模式,运算效率低。
- 需要额外添加密度预测模块,造成计算开销。
- 评判标准是
IoU,即只考虑两个框的重叠面积,这对描述box重叠关系或许不够全面。
10. DIOU-NMS(AAAI2020)
在以往的NMS中使用的评判指标都是IoU,但就像前面对IoU的介绍,IoU虽然简单直观,但它只考虑两个框的重叠面积(比如下图第一种相比于第三种越不太可能是冗余框)。因此,后面研究相继耶提出了许多IoU变体来使两框之间的相对位置关系描述更加准确。比如DIoU-NMS就直接将IoU指标换为DIoU。当然结合前面对IoU的介绍,这种换掉IoU指标的NMS变体也可以有很多。

DIOU-NMS优点:
- 从几何直观的角度,将中心点考虑进来有助于缓解遮挡案例。
- 可以与前述
NMS变体结合使用。 - 保持
NMS阈值不变的情况下,必然能够获得更高recall(因为保留的框增多了)。
DIOU-NMS缺点:
顺序处理模式,计算更复杂,运算效率更低。
NMS总结
实际上NMS的变体不止上面提到的方法,还有其他的变体,比如从文本场景中,NMS变体主要是一种基于shape的改变;而在遥感等实时场景中,NMS变体主要是加速策略的改变,提高的的计算效率。
从以上NMS的介绍,可以看出:目前,NMS对传统NMS算法的改进主要是从极大值的选择机制,抑制冗余框的机制,IoU的评价指标,anchor的形态、位置及其所处的环境(周边的密度)等方面来进行优化。虽然NMS算法一直在不断的优化,但未来更主流的方式是NMS-free。
参考文献
機器/深度學習: 物件偵測 Non-Maximum Suppression (NMS) | by Tommy Huang | Medium
https://mp.weixin.qq.com/s/jLnde0Xms-99g4z16OE9VQ
DIoU-NMS:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
soft-NMS(ICCV2017):Soft-NMS – Improving Object Detection With One Line of Code
Weighted-NMS(ICMEW2017):Inception Single Shot MultiBox Detector for object detection
IOU-Guided NMS/IOU-Net(ECCV2018):Acquisition of Localization Confidence for Accurate Object Detection
softer NMS(CVPR2019):Softer-NMS: Rethinking Bounding Box Regression for Accurate Object Detection.
Adaptive NMS(CVPR2019):Adaptive NMS: Refining Pedestrian Detection in a Crowd
DIOU-NMS(AAAI2020):Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression.