图神经网络总结(GCN/GAT/GraphSAGE/DeepWalk/TransE)
文章目录
- 图神经网络
-
- 1 游走类模型
-
- 1.1 DeepWalk
-
- 随机游走
- DeepWalk计算节点向量的方式:
- 1.2 Node2VEC
-
- node2vec改进后的随机游走方式:
- 1.3 LINE
- 2 消息传递类模型
-
- 2.1 GCN
- 2.2 GAT
- 2.3 GraphSage
-
- GraphSAGE 的采样方法:
- GraphSAGE 的聚合函数:
-
- Mean aggregator
- LSTM aggregator
- Pooling aggregator
- 2.4 HAT
-
- 元路径(meta-path)
-
- meta-path的数学定义:
- 基于meta-path的邻居 N i Φ N^Φ_i NiΦ
- HAT结构
- 节点级注意力:
- 语义级注意力:
- 3 知识图谱类模型
-
- 3.1 TransE
- 3.2 TransH
- 3.3 TransR
- 3.4 TransD
图神经网络
图神经网络是用于图结构数据的深度学习架构,将端到端学习与归纳推理相结合,有望解决传统深度学习无法处理的因果推理、可解释性等问题,是非常有潜力的人工智能研究方向。
图神经网络根据理论及思想的差异主要可以分为三大类:
| 类型 | 模型 |
|---|---|
| 游走类模型 | DeepWalk,Node2VEC,Struc2Vec,LINE,GES,Metapath2Vec,Metapath2Vec++,Multi-Metapath2Vec++ |
| 消息传递类模型 | GCN,GAT,GarphSage,SGC,DGI,STGCN,GIN,PinSage,GNN-Index,ERNIESage |
| 知识图谱类模型 | TransE,TransR,RotatE |

1 游走类模型
1.1 DeepWalk
DeepWalk是network embedding的开山之作,它将NLP中词向量的思想借鉴过来做网络的节点表示,提供了一种新的思路,之后有很多工作都在DeepWalk的基础上进行,利用随机游走的特征构建概率模型,用词向量中Negative Sampling的思想解决相应问题。
本文提出了一种网络嵌入的方法叫DeepWalk,网络嵌入是将网络中的点用一个低维的向量表示,这些向量要能反应原先网络的某些特性,比如如果在原网络中两个点的结构类似,那么这两个点表示成的向量也应该类似。DeepWalk的输入是一张图或者网络,输出为网络中顶点的向量表示。DeepWalk通过截断随机游走(truncated random walk)学习出一个网络的社会表示(social representation),在网络标注顶点很少的情况也能得到比较好的效果。并且该方法还具有可扩展的优点,能够适应网络的变化。
随机游走
所谓随机游走(random walk),就是在网络上不断重复地随机选择游走路径,最终形成一条贯穿网络的路径。从某个特定的端点开始,游走的每一步都从与当前节点相连的边中随机选择一条,沿着选定的边移动到下一个顶点,不断重复这个过程。下图所示蓝色箭头组成的路径即为一条随机游走。

DeepWalk中使用的截断随机游走(truncated random walk)实际上就是长度固定的随机游走。
使用随机游走有两个好处:
- 并行化,随机游走是局部的,对于一个大的网络来说,可以同时在不同的顶点开始进行一定长度的随机游走,多个随机游走同时进行,可以减少采样的时间。
- 适应性,可以适应网络局部的变化。网络的演化通常是局部的点和边的变化,这样的变化只会对部分随机游走路径产生影响,因此在网络的演化过程中不需要每一次都重新计算整个网络的随机游走。
DeepWalk计算节点向量的方式:
文中提到网络中随机游走的分布规律与NLP中句子序列在语料库中出现的规律有着类似的幂律分布特征。那么既然网络的特性与自然语言处理中的特性十分类似,就可以将NLP中词向量的模型用在网络表示中,这正是本文所做的工作。
DeepWalk通过截断随机游走,为图中的每个节点生成了一定数量的样本,样本生成后,DeepWalk借鉴了word2vec的思量,对节点进行向量化表示。
word2vec这样的词向量模型计算词向量的方式: w i u = ( w 0 , w 1 , w 2 , . . . , w n ) w^u_i=(w_0,w_1,w_2,...,w_n) wiu=(w0,w1,w2,...,wn)是一个有若干个单词组成的序列,其中 w i ∈ V ( V o c a b u l a r y ) w_i∈V(Vocabulary) wi∈V(Vocabulary),V是词汇表,也就是所有单词组成的集合。词向量模型通过建模 P r ( w n ∣ w 0 , w 1 , w 2 , . . . , w n − 1 ) Pr(w_n|w_0,w_1,w_2,...,w_{n-1}) Pr(wn∣w0,w1,w2,...,wn−1) 计算词的向量化表示。
DeepWalk将网络中的节点看做句子中的单词 ,网络的随机游走得到的序列对应为句子序列,那么对于一个随机游走,可以通过计算 P r ( v i ∣ v 0 , v 1 , v 2 , . . . , v i − 1 ) Pr(v_i|v_0,v_1,v_2,...,v_{i-1}) Pr(vi∣v0,v1,v2,...,vi−1) 得到节点的向量化表示,其中 v i v_i vi为图中的节点。
1.2 Node2VEC
node2vec的思想同DeepWalk一样,生成随机游走,对随机游走采样得到(节点,上下文)的组合,然后用处理词向量的方法对这样的组合建模得到网络节点的表示。不过在生成随机游走过程中做了一些创新,node2vec改进了DeepWalk中随机游走的生成方式,使得生成的随机游走可以反映深度优先和广度优先两种采样的特性,从而提高网络嵌入的效果。
node2vec提出在图网络中很多节点往往有一些类似的结构特征。一种结构特征是很多节点会聚集在一起,内部的连接远比外部的连接多,称之为社区。另一种结构特征是网络中两个可能相聚很远的点,在边的连接上有着类似的特征。比如下图, u , S 1 , S 2 , S 3 , S 4 u,S_1,S_2,S_3,S_4 u,S1,S2,S3,S4就属于一个社区,而 u u u和 S 6 S_6 S6在结构上有着相似的特征。
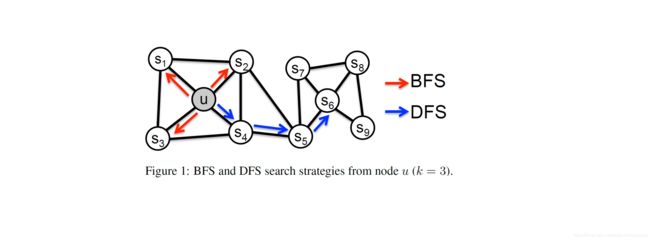
node2vec论文中提出一个好的网络表示学习算法的目标必须满足这两点:
- 同一个社区内的节点表示相似。
- 拥有类似结构特征的节点表示相似。
接下来就是node2vec的主要创新点,node2vec通过改进游走方式,使用深度优先游走DFS和广度优先搜索BFS,实现对上述两种图特征的学习。
复杂网络处理的任务离不开两种特性:一种是同质性,就是上文所说的社区。一种就是结构相似性。广度优先搜索BFS倾向于在初始节点的周围游走,可以反映出一个节点的邻居的微观特性;而深度优先游走DFS一般会跑的离初始节点越来越远,可以反映出一个节点邻居的宏观特性。
node2vec改进后的随机游走方式:

对于节点v,其下一步要采样的节点x,通过下面的转移概率公式计算

- 如果t与x相等,那么采样x的概率为 1 p \frac 1p p1 ;
- 如果t与x相连,那么采样x的概率1;
- 如果t与x不相连,那么采样x概率为 1 q \frac 1q q1 。
参数p、q的意义分别如下:
返回概率p:
- 如果 p > m a x ( q , 1 ) p>max(q,1) p>max(q,1) ,那么采样会尽量不往回走,对应上图的情况,就是下一个节点不太可能是上一个节点t。
- 如果 p < m a x ( q , 1 ) p
出入参数q:
- 如果 q > 1 q>1 q>1,那么游走会倾向于在起始点周围的节点之间跑,可以反映出一个节点的BFS特性。
- 如果 q < 1 q<1 q<1 ,那么游走会倾向于往远处跑,反映出DFS特性。
当p=1,q=1时,游走方式就等同于DeepWalk中的随机游走
1.3 LINE
LINE 这个模型就是把一个大型网络中的节点根据其关系的疏密程度映射到向量空间中去,使联系紧密的节点被投射到相似的位置中去,而在网络中衡量两个节点联系紧密程度一个重要的指标就是这两个节点之间边的权值。在这篇文章中作者在建模的时候不仅仅只考虑了一阶的关系,即两个点之间直接有较大权值的边相连就认为它们比较相似;同时考虑了二阶关系,即两个点也许不直接相连,但是如果它们的一阶公共节点比较多,那么它们也被认为是比较相似的。
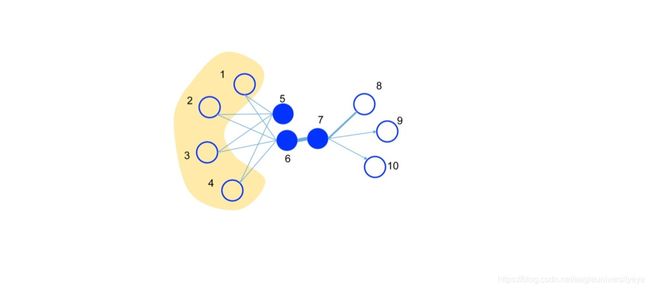
一阶关系和二阶关系的相似性可以从上图获得一个直观的了解:
- 如果两个顶点之间有一条强连接的边(权重很大的边),那么这两个顶点就是相似的。图中顶点6与7就是这种相似,这种相似被称作一阶相似性。
- 如果两个顶点共享了很多相同的邻居顶点,那么这两个顶点也是相似的。图中顶点5和6虽然没有直接相连,但是他们同时连接到了顶点1234,所以顶点5和6也是相似的,这种相似被称作二阶相似性。
一阶相似性是用来衡量两个直接相连的顶点的相似性的,边的权值越大相似性越高。在LINE中,一阶相似性建模为:

二阶相似性描述了两个顶点的邻接节点的相似度,在LINE中,二阶相似性建模为:

LINE通过缩小两个概率分布的距离的方式进行训练,使得两个概率分布尽量相似。概率分布的距离在文中被定义成两个概率分布的KL散度。
2 消息传递类模型
2.1 GCN
GCN是一种非常经典的图神经网络,GCN借助拉普拉斯矩阵,利用特征分解和傅里叶变换得到了一个容易计算卷积核在图网络上进行卷积。GCN的一个简单推导过程:
给定图 G = ( V , E ) G=(V,E) G=(V,E),其中 V , E V,E V,E分别代表其节点集合和边集合,假设每个节点的表示 x v ∈ R q x_v∈R^q xv∈Rq,则节点特征矩阵 X ∈ R ∣ V ∣ ∗ q X∈R^{{|V|}*q} X∈R∣V∣∗q。引入邻接矩阵 A A A来描述图的结构,加上自环得到矩阵 A ′ = A + I A^{'}=A+I A′=A+I,并计算度矩阵 M M M, w h e r e M i i = ∑ j A i j ′ whereM_{ii}=\sum_jA^{'}_{ij} whereMii=∑jAij′。
第一代的GCN即Spectral Network,其直接将一维的信号卷积操作扩展到图结构,设 Φ Φ Φ为图拉普拉斯算子 L = M − A L = M - A L=M−A 的特征向量, θ θ θ 为模型需要学习的卷积核,则图卷积定义为:

之后第二代GCN即ChebNet,用切比雪夫展开式近似卷积核的k阶展开式 T k ( x ) T_k(x) Tk(x),将图卷积改写为:
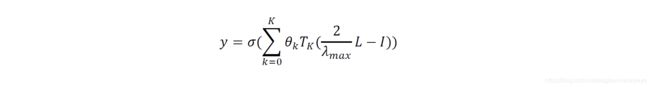
此时再做进一步简化,取 K = 1 K=1 K=1,只考虑一阶邻域信息,通过叠加多层网络的方式来扩大感受野,引入renormalization trick,指定一些参数,简化图卷积,并将结果写成矩阵形式,就得到最终的Graph Convolutional Network:

其中 W W W已经从传统意义上的卷积核扩展为图卷积操作的参数。GCN是一类基于谱图(Spectral)的方法,通过图傅里叶变换将整个图拓扑结构转到频域并在频域对图信号 进行矩阵乘法操作,再傅里叶逆变换到空间域,实现空间域的卷积效果。但是通过两代改进及简化,GCN在空间域上的操作也可以直观的表现出来,即对于相邻节点,累加所有信息并考虑本节点和相邻节点的度做对称归一化:

之后经过参数矩阵 W W W变换到隐空间。这样GCN就和其他基于消息传递的图神经网络统一起来了。GCN的常用表达形式:
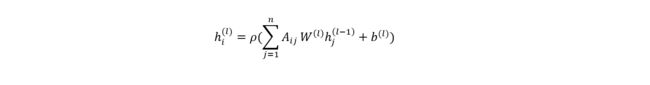
2.2 GAT
GAT假设相邻节点对中心节点的贡献既不像GraphSage一样相同,也不像GCN那样预先确定。GAT在聚合节点的邻居信息的时候使用注意力机制确定每个邻居节点对中心节点的重要性,也就是权重。定义图卷积操作如下:

a v u a_{vu} avu表示节点v和它的邻居节点u之间的连接的权重,通过下式计算:

其中 g ( • ) g(•) g(•)是一个LeakReLU激活函数,a是一个可学习的参数向量。
softmax函数确保节点v的所有邻居的注意权值之和为1。GAT进一步使用multi-head注意力方式,并使用concat方式对不同注意力节点进行整合,提高了模型的表达能力。在节点分类任务上比GraphSage有了显著的改进。
下图展示了GCN和GAN在聚合邻居节点信息时候的不同。

- 图卷积网络GCN在聚集过程中很清楚地分配了一个非参数的权重 a i j a_{ij} aij给 v i v_i vi的邻居 v j v_j vj
- 图注意力网络GAT通过端到端的神经网络结构隐式地捕获 a i j a_{ij} aij的权重,以便更重要的节点获得更大的权重。
2.3 GraphSage
GraphSage出现之前的图网络方法需要图中所有的顶点在训练embedding的时候都出现,这些的方法本质上是transductive,不能自然地泛化到未见过的顶点。GraphSAGE是一个inductive的框架,可以利用顶点特征信息(比如文本属性)来高效地为没有见过的顶点生成embedding。
GraphSAGE是为了学习一种节点表示方法,即如何通过从一个顶点的局部邻居采样并聚合顶点特征,而不是为每个顶点训练单独的embedding。GraphSAGE的具体做法是,训练了一组aggregator functions,这些函数学习如何从一个顶点的局部邻居聚合特征信息。每个聚合函数从一个顶点的不同的hops或者说不同的搜索深度聚合信息。测试或是推断的时候,使用训练好的系统,通过学习到的聚合函数来对完全未见过的顶点生成embedding。

GraphSAGE 是Graph SAmple and aggreGatE的缩写,其运行流程如上图所示,可以分为三个步骤:
- 对图中每个顶点邻居顶点进行采样,因为每个节点的度是不一致的,为了计算高效, 为每个节点采样固定数量的邻居
- 根据聚合函数聚合邻居顶点蕴含的信息
- 得到图中各顶点的向量表示供下游任务使用
GraphSAGE 的采样方法:
出于对计算效率的考虑,对每个顶点采样一定数量的邻居顶点作为待聚合信息的顶点。设需要的邻居数量,即采样数量为S,若顶点邻居数少于S,则采用有放回的抽样方法,直到采样出S个顶点。若顶点邻居数大于S,则采用无放回的抽样。(即采用有放回的重采样/负采样方法达到 S)
当然,若不考虑计算效率,完全可以对每个顶点利用其所有的邻居顶点进行信息聚合,这样是信息无损的。GraphSAGE经常在大规模数据使用,因此,经常采样一个固定大小的邻域集,以保持每个batch的计算占用空间是固定的(即 graphSAGE并不是使用全部的相邻节点,而是做了固定size的采样)。
GraphSAGE 的聚合函数:
在过对邻接节点采样后,GraphSAGE 通过聚合函数将采样得到的节点的信息聚合到中心节点,主要的聚合函数有:Mean aggregator,LSTM aggregator,Pooling aggregator。
Mean aggregator
mean aggregator将目标顶点和邻居顶点的第k−1层向量拼接起来,然后对向量的每个维度进行求均值的操作,将得到的结果做一次非线性变换产生目标顶点的第k层表示向量。

LSTM aggregator
基于LSTM的复杂的聚合器。和均值聚合器相比,LSTMs有更强的表达能力。但是,由于LSTM是对一个序列编码的,而序列是有顺序性的,因此LSTM aggregator不具有排列不变性。因此LSTM aggregator有可解释性上的问题。
Pooling aggregator
pooling聚合器,它既是对称的,又是可训练的。Pooling aggregator 先对目标顶点的邻居顶点的embedding向量进行一次非线性变换,之后进行一次pooling操作(max pooling or mean pooling),将得到结果与目标顶点的表示向量拼接,最后再经过一次非线性变换得到目标顶点的第k层表示向量。

2.4 HAT
HAT全称是基于注意力机制的异质图神经网络 Heterogeneous Graph Attention Network,可以广泛地应用于异质图分析。注意力机制包括节点级注意力和语义级注意力。节点的注意力主要学习节点及其邻居节点间的权重,语义级的注意力是来学习基于不同meta-path的权重。最后,通过相应地聚合操作得到最终的节点表示。
元路径(meta-path)
在异构图中,两个节点可以通过不同的语义路径连接,称为元路径(meta-path),如下图中,Movie-Actor-Movie(MAM)和Movie-Year-Movie(MYM)都是不同的meta-path。不同的meta-path有不同的语义。如图1中, meta-path Movie-Actor-Movie (MAM)表示电影的演员相同, meta-path Movie-Director-Movie (MDM) 表示电影的导演相同。

meta-path的数学定义:
一个meta-pathΦ定义为一条由 A 1 − > R 1 − > A 2 − > R 2 − > . . . R l − > A l + 1 A_1 ->R_1-> A_2 ->R_2-> ... R_l-> A_{l+1} A1−>R1−>A2−>R2−>...Rl−>Al+1组成的路径(可以缩写为 A 1 A 2 . . . A l + 1 A_1A_2...A_{l+1} A1A2...Al+1)。 R = R 1 • R 2 • . . . • R l R=R_1•R_2•...•R_l R=R1•R2•...•Rl定义为对象 A 1 A_1 A1和 A l + 1 A_{l+1} Al+1之间的符合关系。 • • •表示在关系上的符合操作。
基于meta-path的邻居 N i Φ N^Φ_i NiΦ
给定一个节点i和一条meta-pathΦ,节点i的基于meta-path的邻居 N i Φ N^Φ_i NiΦ定义为通过meta-pathΦ和节点i相连的节点构成的集合,包括节点i自身。
在设计异质图神经网络的时候,从异质图的复杂结构出发,需要满足下面三个要求:
- 图的异质性:考虑不同节点和不同关系的差异。不同类型节点有其各自的特征,节点的特征空间也不尽相同。如何处理不同类型的节点并同时保留各自的特征是设计异质图神经网络时迫切需要解决的问题;
- 语义级别注意力:学习meta-path的重要性并融合语义信息。异构图涉及到不同的有意义和复杂的语义信息,这些信息通常由meta-path来反映,对于某个具体任务,不同meta-path表达的语义不同,因此对任务的贡献也不同
- 节点级别注意力:学习基于meta-path的节点邻居的重要性。在异构图中,节点可以通过各种类型的关系(如meta-path)连接。给定meta-path,每个节点都有很多基于meta-path的邻居。如何区分邻居间的细微差别,选择一些信息量大的邻居是有必要的。对于每个节点,节点级注意力的目的是学习基于meta-path的邻居的重要性,并为它们分配不同的注意力值。
HAT结构
下图是HAT在图传播时更新一个节点状态的过程,两幅图的想要表达的含义是相同的,红色方框圈出来的部分在融合节点级信息,蓝色方框圈出来的部分在融合语义级信息,也就是不同类型的meta-path聚合出的信息。

下面是我画的一个简略的模型图,帮助理解,左边是一个异质图的子图,灰色节点通过不同类型的边和不同类型的节点相连接。HAT通过中心节点的邻居节点的信息,更新中心节点的状态。这里的邻居节点是根据meta-path与中心节点相连接,可以是一跳或者多跳的,即meta-path的路径可能有长有短,但是meta-path必须是实现定义好的。
在第一步,首先将节点根据meta-path的不同类型分开进行节点级信息聚合,如下绿色方框圈出的部分,下图中有紫色和蓝色两种meta-path(我图中画的meta-path的长度都是1,但根据定义meta-path可以是随意长度)。第二步,不同的类型的meta-path分开进行节点信息聚合后,再将不同类型的meta-path进行信息聚合,如下图黄色方框中圈出的部分。

节点级注意力:
所有类型的节点都被投影到一个统一的特征空间中,通过节点级的注意力机制来学习基于meta-path的邻居节点的权重并将它们进行聚合得到特定语义的节点embedding。下图可以对如何融合节点进行了清晰的展示:
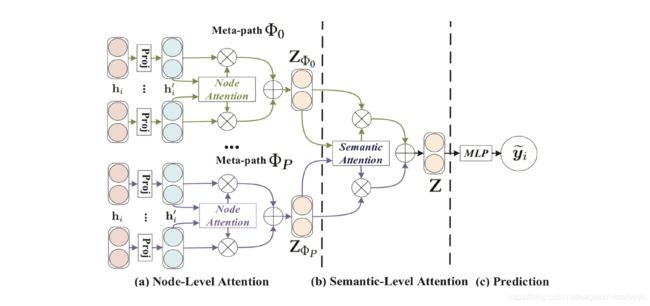
给定某条meta-path,可以利用节点级注意力来学习特定语义下的节点表示。文中应用一个特定类型的转换矩阵 M Φ i M_{Φ_i} MΦi将节点的不同类型的特征通过投影变换到统一的特征空间:

然后,使用self-attention学习各种类型的节点的权重:

和GAT类似,使用masked attention将结构信息注入到模型中,即只计算中心节点和邻居之间的重要性。得到注意力系数以后使用softmax函数进行归一化:

基于meta-pathΦ的邻居特征聚集如下:

为了使训练过程更稳定,使用multi-head机制,即重复节点级attention K次,并将所学到的embeddings进行拼接
语义级注意力:
联合学习每个meta-path的权重,并通过语义级注意力融合前面得到的语义特定的节点embedding。下图可以对如何融合meta-path中的语义信息进行了清晰的展示:

异构图中每个节点包含了很多种类型的语义信息(每个meta-path可以对应一个语义信息)。为了学到更复杂的节点embedding,需要将这些不同的语义信息进行融合。为此,文中提出了一个语义级attention,它可以学习不同的meta-path的重要性并将其融合。语义级attention的输入就是节点级attention的 P P P组输出 Z Φ 0 , Z Φ 1 , . . . , Z Φ P {Z_{Φ_0},Z_{Φ_1},...,Z_{Φ_P}} ZΦ0,ZΦ1,...,ZΦP,令 ( β Φ 0 , β Φ 1 , . . . , β Φ P ) ({β_{Φ_0},β_{Φ_1},...,β_{Φ_P}}) (βΦ0,βΦ1,...,βΦP)为每个meta-path学到的权重:

为了学到每一个meta-path的重要性,使用一个线性转换(文中使用一层MLP)来转换特点语义的embedding。
文中将学到的特定语义的embeddings度量为使用一个语义级的attention向量q转换了的embedding的相似度:

使用softmax函数对每个meta-path的重要性都进行归一化:
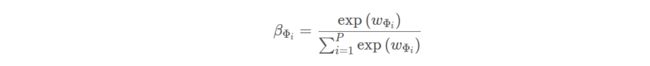
最后融合通过不同的meta-path得到的语义级的embeddings:

3 知识图谱类模型
传统的知识图谱表示方法是采用OWL、RDF等本体语言进行描述;随着深度学习的发展与应用,将知识图谱表示成向量,可以更方便进行构建知识图谱之后的各种应用工作,比如:推理,知识补全等。所以,我们现在的目标就是把每条简单的三元组
而TransE,TransR,RotatE等模型的主要目的就是采用Wrod2Vec的思想将知识图谱向量化。

3.1 TransE
TransE模型属于知识表示学习分支下的翻译模型的一种:直观上,将每个三元组实例(head,relation,tail)中的关系relation看做从实体head到实体tail的翻译,通过不断调整h、r和 t(head、relation和tail的向量),使(h + r) 尽可能与 t 相等,即 h + r = t

TransE 学习的是基于实体和关系的分布式向量表示,受word2vec启发,利用了词向量的 “平移不变现象” 。例如:C(king)−C(queen)≈C(man)−C(woman) 其中,C(w)就是word2vec学习到的词向量表示。
TransE 定义了一个距离函数 d(h + r, t),它用来衡量 h + r 和 t 之间的距离,在实际应用中可以使用 L1 或 L2 范数。在模型的训练过程中,transE采用最大间隔方法,最小化目标函数,目标函数如下:
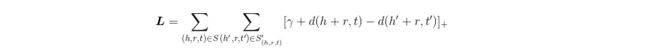
3.2 TransH
为了解决TransE在面对自反关系,以及多对一、一对多、多对多关系的不足。2014年Wang等人提出了transH模型,其核心思想是对每一个关系定义一个超平面 W r W_r Wr,和一个关系向量 d r d_r dr,h⊥、t⊥是h、t在 W r W_r Wr上的投影,这里要求正确的三元组需要满足 h r + d r = t r h_r + d_r = t_r hr+dr=tr。这样能够使得同一个实体在不同关系中的意义不同,同时不同实体,在同一关系中的意义,也可以相同。

TransH的目标函数是:

3.3 TransR
TransE和TransH模型都假设实体和关系是在同一个语义空间的向量,这样相似的实体会在空间中相近的位置,然而每一个实体都可以有很多方面,而不同的关系关注的是实体不同的方面。因此,TransR模型对不同的关系建立各自的关系空间,在计算时先将实体映射到关系空间进行计算。因为是在关系空间做向量叠加,所以这个模型叫做TransR。

3.4 TransD
TransR有许多问题,首先对于一种关系,它的头实体和尾实体使用同样的变换矩阵映射到关系空间,而头实体和尾实体往往是完全不同类的实体,比如(刘康,工作单位,中科院自动化所),其中刘康老师和自动化所就是不同范畴的实体,也应该使用不同的方法进行映射。其次,这种映射是与实体和关系都相关的过程,然而映射矩阵却只由关系确定。最后,TransR模型运算量大且参数较TransE、TransH模型多得多。
TransD模型对每个实体或关系使用两个向量进行表示,一个向量表示语义,另一个用来构建映射矩阵。

TransA,TranSpare,TransG和KG2E