Python3人工智能学习笔记(二)——分类问题
3.1 分类问题
实例
对垃圾邮件进行检测
任务
- 输入:电子邮件
- 输出:此为垃圾邮件/浦东邮件
流程
- (人)标注样本邮件为垃圾/普通
- (计算机)获取匹配的样本邮件及其标签,学习其特征
- (计算机)针对新的邮件,自动识别其类型
特征
- 用于帮助判断是否为垃圾邮件的属性
- 发件人包含字符:%&*
- 正文包含:现金、领取等等
其他分类问题
- 图像分类
- 数字识别
- 考试通过预测
概念
根据已知样本的某些特征,判断一个新的样本属于哪种已知的样本类

分类方法
- 逻辑回归
- KNN近邻模型
- 决策树
- 神经网络
分类任务与回归任务的区别


分类:BCE 回归:AD
3.2 逻辑回归
实例1:是否看电影(线性回归模型)

第一步要去寻找f(x),模拟点的分布
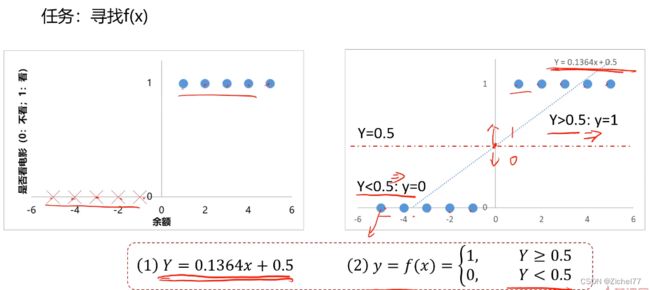
局限性
样本量变大之后,准确率会下降,即离散的点会导致回归曲线偏离
逻辑回归方程
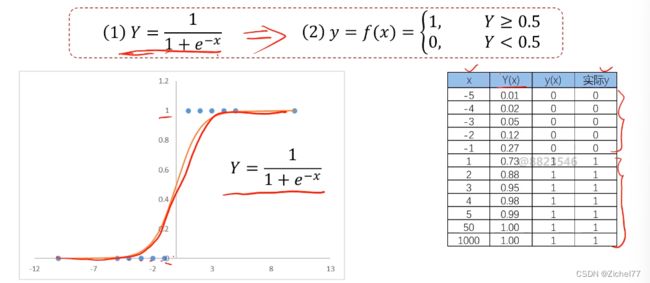
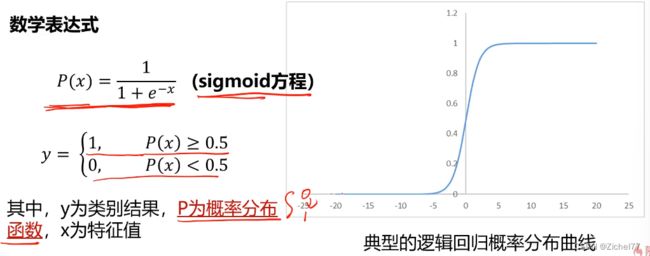
用于解决分类问题的模型,根据数据特征或属性,计算其归属于某一类别的概率P(x),根据概率数值判断其所属类别。主要应用场景:二分类问题
实例2(复杂version)
当有两个x时,分类任务变得更为复杂
- 线性情况
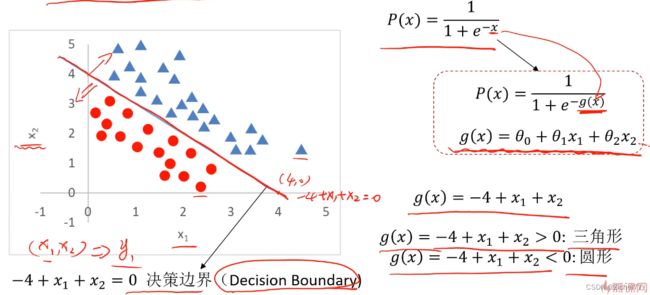
- 非线性情况
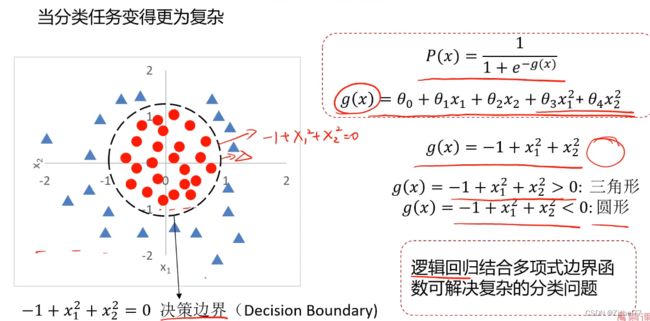
逻辑回归求解
根据训练样本,寻找类别边界以及θ0,θ1,θ2
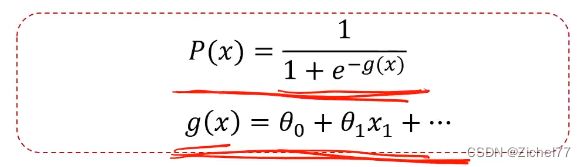
在线性回归求解中,可以使用最小化损失函数(J)

但是在分类问题中
标签与预测结果都是离散点(0和1),使用该损失函数无法寻找极小值点
即我们在预测当中,当y=0时,希望预测结果y’→0;如果预测出来y’→1,那么J会非常大,以此来惩罚,所以也是一种损失函数,通过J的大小变化告诉计算机预测是否准确


3.3 逻辑回归实战准备
1. 分类散点图可视化
除了画图之外还需要体现不同的类别
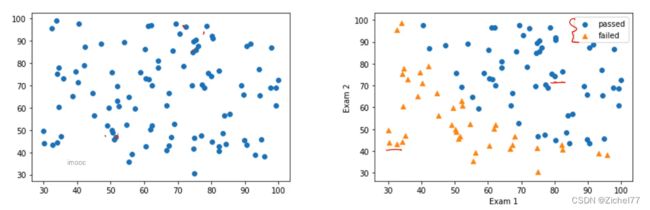
未区分类别散点图
plt.scatter(X1,X2)
区分类别散点图
mask==y==1
通过mask筛选数据中的类别,此处只有y=1时才为true
passed=plt.scatter(X1[mask],x2[mask])
y==1筛选出来并画出来,即蓝色的小圆点,命名为passed
failed=plt.scatter(X1[~mask],X2[~mask],marker=’^’)
y≠1筛选出来,标记为三角形
实现二分类
2. 逻辑回归模型使用
包括引入和训练,最后完成预测
模型训练
from sklearn.linear_model import LogisticRegression
lr_model=LogisticRegression()
lr_model.fit(x,y)
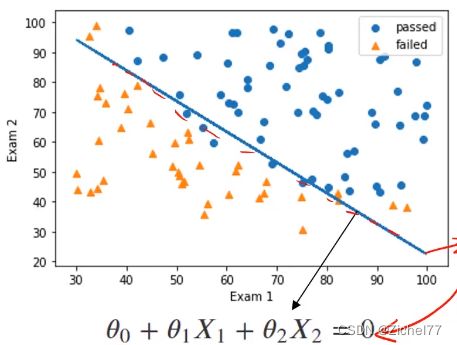
边界函数系数
theta1,theta2=LR.coef_[0][0]
theta0=LR.intercept_[0]
theta就是θ,就是用于下图公式中的替换
对新数据做预测
predictions=lr_modelpredict(x_new)
3. 建立新数据集
根据已有数据集进行扩充,从而让模型有更好的表现
线性的一次边界函数加上二次项,这些二次项就是加入的新的属性数据
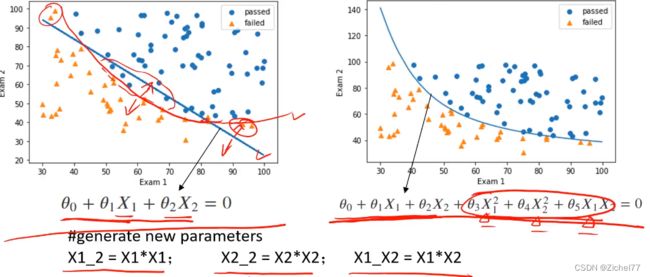
#generate new parameters
X1_2=X1*X1;
X2_2=X2*X2;
X1_X2=X1*X2
生成新数据的字典,引号里面是对应的名称,使得索引起来更加方便
X_new_dic={’X1’:X1,’X2’:X2,’X1^2’:X1_2,’X2^2’:X2_2,’X1X2’:X1_X2}
然后将字典创建为DataFrame的形式
X_new=pd.DataFrame(X_new_dic)
这样就完成了数据的扩展,产生了二次项
就可以把线性的函数转换为非线性
4.模型评估
引入准确率(类别正确预测的比例)
A c c u r a c y = 正确预测样本数量 / 总样本数量 Accuracy =正确预测样本数量/总样本数量 Accuracy=正确预测样本数量/总样本数量zh
准确率越接近1越好
但如果过度追求准确率可能会导致模型的过拟合
计算准确率
from sklearn metrics import accuracy_score
y_Predict = LR.predict(X)
accuracy = accuracy_score(y,y_predict)
画图看决策边界效果, 可视化模型表现
plt.plot{X1,X2_boundary)
passed=plt.scatter(X1[mask],X2[mask])
failed=plt.scatter(X1[~mask],X2[~mask],marker=’^’)