深度学习结构化模型
Deep learning is known to work well when applied to unstructured data like text, audio, or images but can sometimes lag behind other machine learning approaches like gradient boosting when applied to structured or tabular data.In this post, we will use semi-supervised learning to improve the performance of deep neural models when applied to structured data in a low data regime. We will show that by using unsupervised pre-training we can make a neural model perform better than gradient boosting.
众所周知,深度学习在应用于文本,音频或图像等非结构化数据时效果很好,但有时在应用于结构化或表格数据时可能会落后于梯度提升等其他机器学习方法。在本文中,我们将使用半监督学习当在低数据状态下将其应用于结构化数据时,可提高深度神经模型的性能。 我们将展示通过使用无监督的预训练,我们可以使神经模型的性能优于梯度增强。
This post is based on two papers:
这篇文章基于两篇论文:
AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks
AutoInt:通过自专心神经网络进行自动功能交互学习
TabNet: Attentive Interpretable Tabular Learning
TabNet:细心的可解释表格学习
We implement a deep neural architecture that is similar to what is presented in the AutoInt paper, we use multi-head self-attention and feature embeddings. The pre-training part was taken from the Tabnet paper.
我们实现了类似于AutoInt论文中介绍的深度神经体系结构,我们使用了多头自我注意和特征嵌入。 预培训部分摘自Tabnet论文。
方法说明: (Description of the approach:)
We will work on structured data, meaning data that can be written as a table with columns (numerical, categorical, ordinal) and rows. We also assume that we have a large number of unlabeled samples that we can use for pre-training and a small number of labeled samples that we can use for supervised learning. In the next experiments, we will simulate this setting to plot the learning curves and evaluate the approach when using different sizes of labeled sets.
我们将处理结构化数据,即可以写成具有列(数字,分类,序数)和行的表的数据。 我们还假设我们有大量可用于预训练的未标记样本,以及少量可用于监督学习的标记样本。 在下一个实验中,我们将模拟此设置以绘制学习曲线并评估使用不同大小的标记集时的方法。
数据准备: (Data Preparation:)
Let’s use an example to describe how we prepare the data before feeding it to the neural network.
让我们用一个例子来描述在将数据馈送到神经网络之前如何准备数据。
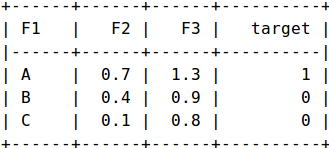
In this example, we have three samples and three features {F1, F2, F3}, and one target. F1 is a categorical feature while F2 and F3 are numeric features.We will create a new feature F1_X for each modality X of F1 and give it a value 1 if F1 == X else it is equal to 0.
在此示例中,我们有三个样本和三个特征{ F1 , F2 , F3 }和一个目标。 F1是分类特征,而F2和F3是数字特征。我们将为F1的每个模态X创建一个新特征F1_X ,如果F1 == X ,则为其赋予值1,否则它等于0。
The transformed samples will be written a set of (Feature_Name, Feature_Value).
转换后的样本将被写入一组( Feature_Name , Feature_Value )。
For example:First Sample -> {(F1_A, 1), (F2, 0.3), (F3, 1.3)}Second Sample -> {(F1_B, 1), (F2, 0.4), (F3, 0.9)}Third Sample -> {(F1_C, 1), (F2, 0.1), (F3, 0.8)}
例如:第一样本- > {(F1_A,1),(F2,0.3),(F3,1.3)}第二样品- > {(F1_B,1),(F2,0.4),(F3,0.9)}第三样品- > {(F1_C,1),(F2,0.1),(F3,0.8)}
The feature names will be fed into an embedding layer and then will be multiplied with feature values.
要素名称将输入到嵌入层,然后与要素值相乘。
模型: (Model:)
The model used here is a sequence of multi-head attention blocks and point-wise feed-forward layers. When training we also use Attention Pooled skip connections. The multi-head attention blocks allow us to model the interactions that might exist between the features while the Attention Pooled skip connections allow us to get a single vector from the set of feature embeddings.
这里使用的模型是一系列多头注意块和逐点前馈层。 训练时,我们还使用“注意力池”跳过连接。 多头注意力块使我们能够对要素之间可能存在的交互进行建模,而注意力池跳过连接使我们能够从要素嵌入集中获得单个向量。
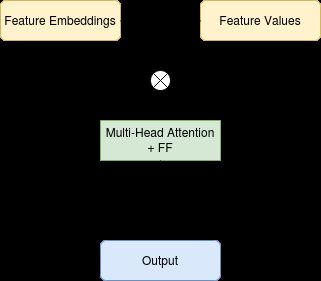
Pre-training:
预训练:
During the pre-training step we use the full unlabeled dataset and we input a corrupted version of the features and train the model to predict the uncorrupted features, similar to what you would do in a denoising auto-encoder.
在预训练步骤中,我们使用完整的未标记数据集,并输入特征的损坏版本,然后训练模型以预测未损坏的特征,这与在降噪自动编码器中执行的操作类似。
Supervised Training:
有监督的培训:
During the supervised part of the training, we add skip connections between the encoder part and the output and we try to predict the target.
在训练的监督部分中,我们在编码器部分和输出之间添加跳过连接,并尝试预测目标。
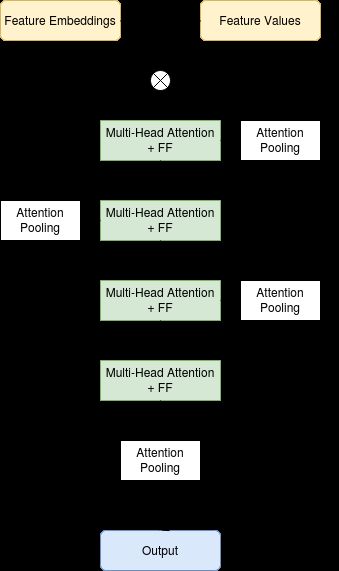
实验:(Experiments:)
In the following experiments, we will use four datasets, two for regression and two for classification.
在以下实验中,我们将使用四个数据集,两个用于回归,两个用于分类。
Sarco: Has Around 50k samples, 21 features, and 7 continuous targets.
Sarco :具有约5万个样本,21个特征和7个连续目标。
Online News: Has Around 40k samples, 61 features, and 1 continuous target.
在线新闻:具有约40k样本,61个功能和1个连续目标。
Adult Census: Has Around 40k samples, 15 features, and 1 binary target.
成人普查:具有约40k样本,15个特征和1个二进制目标。
Forest Cover: Has Around 500k samples, 54 features, and 1 classification targets.
森林覆盖:具有约50万个样本,54个特征和1个分类目标。
We will compare a pre-trained neural model to one that was trained from scratch, and we will focus on the performance on a low data regime, meaning a few hundred to a few thousand labeled samples. We will also do a comparison with a popular implementation of gradient boosting called lightgbm.
我们将预先训练的神经模型与从头开始训练的神经模型进行比较,并且我们将专注于低数据状态下的性能,这意味着数百到几千个标记的样本。 我们还将与称为lightgbm的流行的梯度增强实现进行比较。
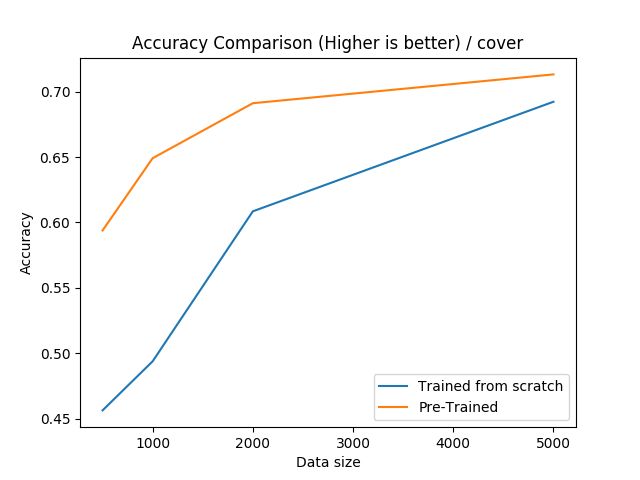
森林覆盖: (Forest Cover:)
成人普查: (Adult Census:)

For this data-set, we can see that pre-training is very effective if the training set is smaller than 2000.
对于此数据集,我们可以看到,如果训练集小于2000,则预训练非常有效。
在线新闻: (Online News:)

For the online news dataset, we can see that pre-training the neural networks are very effective, even over-performing gradient boosting for all sample sizes 500 and bigger.
对于在线新闻数据集,我们可以看到神经网络的预训练是非常有效的,甚至对于所有500和更大的样本量,梯度提升效果都非常好。

For the Sarco dataset, we can see that pre-training the neural networks are very effective, even over-performing gradient boosting for all sample sizes.
对于Sarco数据集,我们可以看到神经网络的预训练非常有效,即使对于所有样本大小,梯度训练的效果也都非常好。
旁注:重现结果的代码 (Side Note: Code to reproduce the results)
The code to reproduce the results is available here: https://github.com/CVxTz/DeepTabular
重现结果的代码在此处提供: https : //github.com/CVxTz/DeepTabular
Using it you can easily train a classification or regression model->
使用它,您可以轻松训练分类或回归模型->
import pandas as pd
from sklearn.model_selection import train_test_splitfrom deeptabular.deeptabular import DeepTabularClassifierif __name__ == "__main__":
data = pd.read_csv("../data/census/adult.csv") train, test = train_test_split(data, test_size=0.2, random_state=1337) target = "income" num_cols = ["age", "fnlwgt", "capital.gain", "capital.loss", "hours.per.week"]
cat_cols = [
"workclass",
"education",
"education.num",
"marital.status",
"occupation",
"relationship",
"race",
"sex",
"native.country",
] for k in num_cols:
mean = train[k].mean()
std = train[k].std()
train[k] = (train[k] - mean) / std
test[k] = (test[k] - mean) / std train[target] = train[target].map({"<=50K": 0, ">50K": 1})
test[target] = test[target].map({"<=50K": 0, ">50K": 1}) classifier = DeepTabularClassifier(
num_layers=10, cat_cols=cat_cols, num_cols=num_cols, n_targets=1,
) classifier.fit(train, target_col=target, epochs=128) pred = classifier.predict(test) classifier.save_config("census_config.json")
classifier.save_weigts("census_weights.h5") new_classifier = DeepTabularClassifier() new_classifier.load_config("census_config.json")
new_classifier.load_weights("census_weights.h5") new_pred = new_classifier.predict(test)结论: (Conclusion:)
Unsupervised pre-training is known to improve the performance of neural networks in the computer vision or natural language domain. In this post we demonstrate that it can also work when applied to structured data, making it competitive with other machine learning methods like gradient boosting in the low data regime.
已知无监督的预训练可以改善计算机视觉或自然语言领域中神经网络的性能。 在本文中,我们证明了将其应用于结构化数据时也可以工作,使其与其他机器学习方法(如低数据环境中的梯度增强)具有竞争力。
翻译自: https://towardsdatascience.com/training-better-deep-learning-models-for-structured-data-using-semi-supervised-learning-8acc3b536319
深度学习结构化模型