MATLAB数学建模(四):机器学习
一、学习目标。
(1)了解机器学习算法在数学建模中的应用。
(2)掌握机器学习算法中的二分类、多分类、回归、聚类算法。
二、实例演练。
1、谈谈你对机器学习算法与数学建模的了解。
机器学习 ( Machine Learning ) 是一门多领域交叉学科,它涉及到概率论、统计学、计算机科学以及软件工程。机器学习是指一套工具或方法,凭借这套工具和方法,利用历史数据对机器进行“训练”进而“学习”到某种模式或规律,并建立预测未来结果的模型。机器学习涉及两类学习方法:有监督学习,主要用于决策支持,它利用有标识的历史数据进行训练,以实现对新数据的标识的预测。有监督学习方法主要包括分类和回归;无监督学习,主要用于知识发现,它在历史数据中发现隐藏的模式或内在结构。无监督学习方法主要包括聚类。
近年来,全国赛的题目中,多多少少都有些数据,而且数据量总体来说呈不断增加的趋势, 这是由于在科研界和工业界已积累了比较丰富的数据,伴随大数据概念的兴起及机器学习技术的发展, 这些数据需要转化成更有意义的知识或模型。 所以在建模比赛中, 只要数据量还比较大, 就有机器学习的用武之地。
2、用二分类算法对fisheriris数据集进行分析。
以下示例显示了利用 MATLAB 提供的支持向量机模型进行二分类,并在图中画出了支持向量的分布情况(图1中圆圈内的点表示支持向量)
(1)导入数据并处理数据。
%% 支持向量机模型
clc,clear,close all
load fisheriris % 导入数据集,fisheriris是Matlab自带的数据集
%fisheriris数据类别分为3类,setosa,versicolor,virginica.每类植物有50个样本,共150个。
% 读取数据集中的两个分类‘versicolor' 和 'virginica'
inds = ~strcmp(species,'setosa'); % 产生样本标签,属于setosa类的样本类别为0,其他类别(versicolor,virginica)样本类别为1
% 使用两个维度,即第三列和第四列数据。
X = meas(inds,3:4); % 在meas数据矩阵中,前50行数据移除,后100行数据移除;保留第三、四列的数据
y = species(inds); % 移除前50行的种类,保留后50行的种类。
tabulate(y) % tabulate()用于统计数值的个数和频率运行结果:
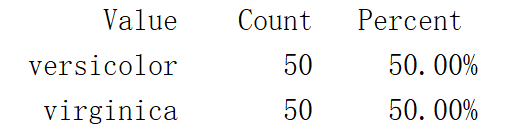
下面,我将对这段代码进行详细的分析:
fisheriris是Matlab自带的数据集,fisheriris数据类别分为3类,setosa,versicolor,virginica.每类植物有50个样本,共150个。fisheriris是matlab系统自带的fisheriris.csv文件,里面有5列数据,151行,第1行是项目名称:SepalLength,SepalWidth,PetalLength,PetalWidth,Species,第2行以后是5.1,3.5,1.4,0.2,setosa;。。。。等等这样的数据。
load fisheriris的意思是读入fisheriris这个文件到系统里,运行之后matlab工作区生成2个文件。meas就是前四列全部数据的矩阵,不含名称这行;species就是最后一列即第五列数据。
strcmp(species,'setosa'); 即把species中的每个元素和‘setosa’做比较,如果一致,则对应位置的元素为1,否则,为0。前50行是'setosa'就变成1,后100行不是就是0。inds = ~strcmp(species,'setosa');% 取反后返回值inds是一个和species有相同size的logical array,inds的元素是1或0。数据文件中species列里面是'setosa'的共有50行。再取反,应该就是一列向量,前50项是0,后面100项是1。
X = meas(inds,3:4); 在meas数据矩阵中,前50行数据移除,后100行数据移除;保留第三、四列的数据
y = species(inds); 移除前50行的种类,保留后50行的种类。
tabulate(y) ; tabulate()用于统计数值的个数和频率
(2)训练SVM模型,并将结果可视化。
%% 使用线性核函数训练SVM模型,并将结果可视化
SVMModel = fitcsvm(X,y,'KernelFunction','linear'); % KernelFunction即核函数
% 查看进行数据划分的支持向量
sv = SVMModel.SupportVectors;
figure
gscatter(X(:,1),X(:,2),y) % gscatter函数可以按分类或分组来画离散点,适用于画多个类别的离散样本分布图。
hold on
plot(sv(:,1),sv(:,2),'ko','MarkerSize',10) % 空心圆圈大小
legend('versicolor','virginica','Support Vector') % 图例
hold off运行结果:
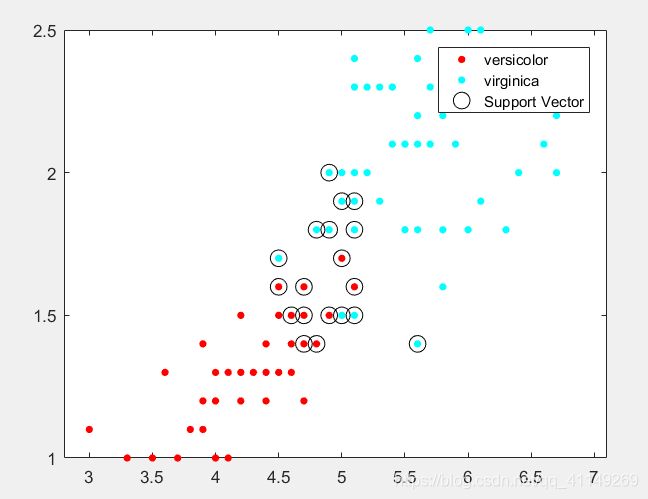
图1
代码分析: gscatter函数可以按分类或分组来画离散点,适用于画多个类别的离散样本分布图。Support Vector为红点与浅蓝点的交界相邻部分。
3、用多分类算法对hospital数据集进行分析。
MATLAB 多分类问题的处理是基于二分类模型.下面的示例演示如何利用 SVM 的二分类模型并结合 fitcecoc 函数解决多分类问题。
%% 导入fisheriris数据集
clc,clear,close all
load fisheriris
X = meas;
Y = species;
tabulate(Y);
%% 创建SVM模板(二分类模型),并对分类变量进行标准化处理
% predictors
t = templateSVM( 'Standardize' , 1); % 对分类变量进行标准化处理
%% 基于SVM二分类模型进行训练并生成多分类模型
Mdl = fitcecoc(X,Y,'Learners',t,...
'ClassNames',{'setosa','versicolor','virginica'})运行结果如下:

4、用回归算法对fisheriris数据集进行分析。
回归模型描述了响应(输出)变量与一个或多个预测变量(输入)变量之间的关系。 MATLAB 支持线性,广义线性和非线性回归模型。以下示例演示如何训练逻辑回归模型。
-
逻辑回归
在 MATLAB 中,逻辑回归属于广义线性回归的范畴,可以通过使用 fitglm 函数实现逻辑回归模型的训练。
%% 判断不同体重、年龄、性别的人的吸烟概率
clc,clear,close all
load hospital % 导入hospital数据集
dsa = hospital;
% 指定模型使用的计算公式
% 公式的书写方式符合 Wilkinson Notation, 详情请查看:
% http://cn.mathworks.com/help/stats/wilkinson-notation.html
modelspec = 'Smoker ~ 1+ Age + Weight + Sex + Age:Weight + Age:Sex + Weight:Sex';
% 通过参数'Disribution'指定'binomial'构建逻辑回归模型
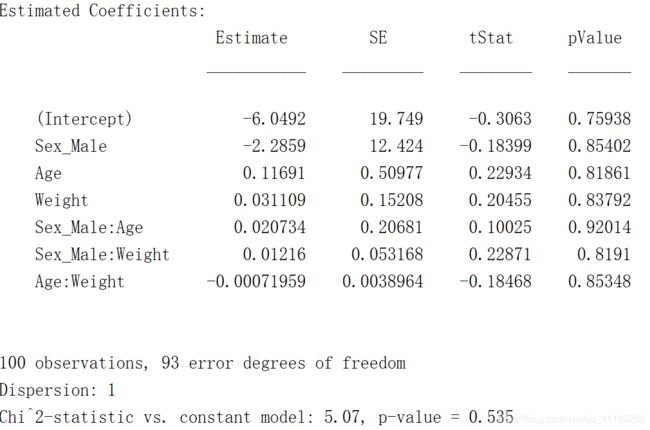
mdl = fitglm(dsa, modelspec, 'Distribution', 'binomial')运行结果:
5、聚类。
例子:设有5个销售员w1,w2,w3,w4,w5,他们的销售业绩由二维变量(v1,v2)描述如下,使用聚类算法将其分类。

聚类:数据中只有数据特征,需要根据某一标准将其划分到不同的类中。
同样的,现在一个教室里面所有人都没什么标签,现在需要你将整个教室的人分为两类,那么你可以从性别、体型、兴趣爱好、位置等等角度去分析。接下来我们以分层聚类为例进行讲解,上面例子来自于《数学建模算法与应用》,用以辅助说明。通常来说,分层聚类有两类,一类是从上到下的分裂(即现将所有个体看做一个类,然后利用规则一步步的分裂成多个类),另一类是从下到上的合并(即先将每个个体看作一个类,然后依据规则一步步合并为一个类)。因此分层聚类最终可以得到一个金字塔结构,每一层都有不同的类别数量,我们可以选取需要的类别数量。
解题步骤:
(1)将5个人的两种数据看作他们的指标,首先,我们简单定义任意两组数据的距离为:
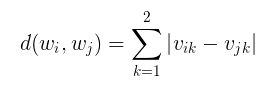
(2)与此相对应的,当有样本归为一类后,我们要计算类间距离就又得需要一个计算方式,我们定义任意两类间的距离为两类中每组数据距离的最小值:

因此,可以得到任意两个销售员的数据距离矩阵:

(3)详细分析:
Step1 首先,最相近的两组样本是w1和w2,他们的距离为1,所以先将其聚为一类;
Step2 然后,剩下的样本为{w1,w2},w3,w4,w5,我们发现除了距离1之外,最相似的是 w3,w4,他们的距离为2,所以将其聚为一类;
Step3 然后,剩下的样本为{w1,w2},{w3,w4},w5,我们发现除了距离1,2之外,最相似的 是{w1,w2}和{w3,w4},他们的距离以 w2和w3的距离为准,距离为3,所以将这两类聚为一类;
Step4 最后,剩下的样本为{w1,w2,w3,w4},w5,只剩最后两类了,所以最后一类为 {w1,w2,w3,w4,w5},类间距以w3/w4与w5的距离4为准。
源代码:
%% 编程实现
clc;clear;close all
data = [1,0;1,1;3,2;4,3;2,5];%原始数据
[m, ~] = size(data);
d = mandist(data');%求任意两组数据的距离
d = tril(d);%取下三角区域数据
nd = nonzeros(d);%去除0元素
nd = unique(nd);%去除重复元素
for i = 1 : m-1
nd_min = min(nd);
[row, col] = find(d == nd_min);
label = union(row,col);%提取相似的类别
label = reshape(label, 1, length(label));%将类别标签转化成行向量
disp(['第',num2str(i),'次找到的相似样本为:',num2str(label)]);
nd(nd == nd_min) = [];%删除已归类的距离
if isempty(nd)%如果没有可分的类就停止
break
end
end
%% 工具箱实现
clc;clear;close all
data = [1,0;1,1;3,2;4,3;2,5];%原始数据
y = pdist(data,'cityblock');%计算任意两样本的绝对值距离
yc = squareform(y);%将距离转化成对称方阵
z = linkage(y);%生成聚类树
[h, t] = dendrogram(z);%画出聚类树
n = 3;%最终需要聚成多少类
T = cluster(z, 'maxclust', n);%分析当分n类时,个样本的标签
for i = 1 : n
label = find(T == i);
label = reshape(label, 1, length(label));
disp(['第',num2str(i),'类有:',num2str(label)]);
end
运行结果:

三、总结与感悟
通过本次学习,我了解到了机器学习算法在数学建模中的应用,掌握了二分类、多分类、回归、聚类算法。对fisheriris数据集有了更深入的了解。