深度学习(PyTorch)——长短期记忆神经网络(LSTM)
一、LSTM网络
ng short term memory,即我们所称呼的LSTM,是为了解决长期以来问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层
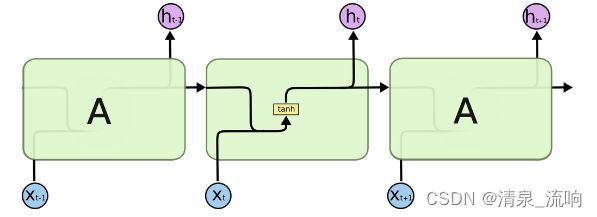
LSTM也有与RNN相似的循环结构,但是循环模块中不再是简单的网络,而是比较复杂的网络单
元。LSTM的循环模块主要有4个单元,以比较复杂的方式进行连接。

先熟悉以下标记:

在上图中,每条线都承载着整个矢量,从一个节点的输出到另一个节点的输入。 粉色圆圈表示按点操作,如矢量加法,而黄色框表示学习的神经网络层。 合并的行表示串联,而分叉的行表示要复制的内容,并且副本到达不同的位置。
二、LSTM核心
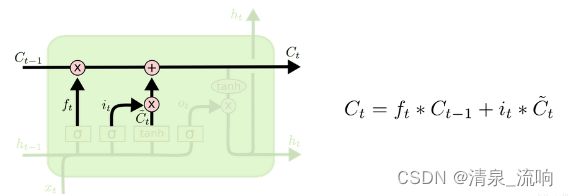
每个LSTM的重复结构称之为一个细胞(cell),在LSTM中最关键的就是细胞的状态,下图中贯穿
的那条横线所表示的就是细胞状态。这条线的意思就是Ct-1先乘以一个系数,再线性叠加后从右侧输出。

门可以实现选择性地让信息通过,主要是通过一个 sigmoid 的神经层 和一个逐点相乘的操作来实现的。
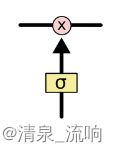
sigmoid层输出的是0-1之间的数字,表示着每个成分能够通过门的比例,对应位数字为0表示不通过,数字1表示全通过。比如一个信息表示为向量[1, 2, 3, 4],sigmoid层的输出为[0.3, 0.5, 0.2,,0.4],那么信息通过此门后执行点乘操作,结果为[1, 2, 3, 4] .* [0.3, 0.5, 0.2, 0.4] = [0.3, 1.0, 0.6, 1.6]。
LSTM共有3种门,通过这3种门控制与保护细胞状态。
2.1、遗忘门
第一步: 通过遗忘门过滤掉不想要的信息;
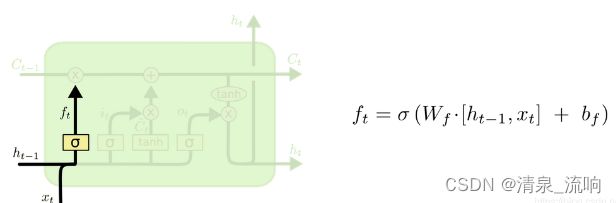
遗忘门决定遗忘哪些信息,它的作用就是遗忘掉老的不用的旧的信息,遗忘门接收上一时刻输出信息h t − 1和当前时刻的输入x t ,然后输出遗忘矩阵f t 决定上一时刻细胞状态C t − 1 的通过状态。
让我们回到语言模型的示例,该模型试图根据所有先前的单词来预测下一个单词。 在这样的问题中,细胞状态可能包括当前受试者的性别,从而可以使用正确的代词。 看到新主语时,我们想忘记旧主语的性别。
左侧的ht-1和下面输入的xt经过了连接操作,再通过一个线性单元,经过一个o也就是sigmoid函数
生成一个0到1之间的数字作为系数输出,表达式如上,Wf和bf作为待定系数是要进行训练学习的。
2.2、输入门
第二步: 决定从新的信息中存储哪些信息到细胞状态中去。即产生要更新的信息。
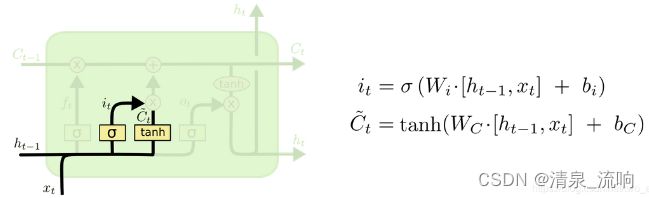
包含两个小的神经网络层,一个是熟悉的sigmoid部分:


第三步: 更新细胞状态
 2.3、输出门
2.3、输出门
第四步: 基于细胞状态,确定输出信息
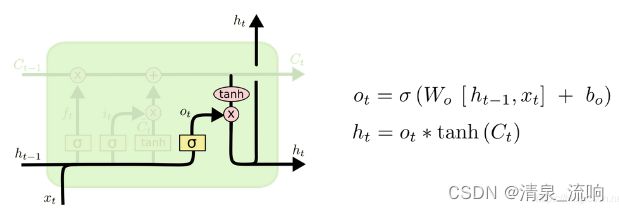
首先利用输出门(sigmoid层)产生一个输出矩阵Ot,决定输出当前状态Ct的哪些部分。接着状态
Ct通过tanh层之后与Ot相乘,成为输出的内容ht。
一个输出到同层下一个单元,一个输出到下一层的单元上,首先,我们运行一个sigmoid层来确定
细胞状态的哪个部分将输出出去。![]()
接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
![]()
在语言模型中,这种影响是可以影响前后词之间词形的相关性的,例如前面输入的是一个代词或名词,后面跟随的动词会学到是否使用“三单形式”或根据前面输入的名词数量来决定输出的是单数形式还是复数形式。
三、案例,代码如下
import torch
from torch import nn
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # hello
y_data = [3, 1, 2, 3, 2] # ohlol
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
# class LSTM(nn.Module):
# def __init__(self, input_size, hidden_size, num_layers, output_size, batch_size):
# super().__init__()
# self.input_size = input_size
# self.hidden_size = hidden_size
# self.num_layers = num_layers
# self.output_size = output_size
# self.num_directions = 1 # 单向LSTM
# self.batch_size = batch_size
# self.lstm = nn.LSTM(self.input_size, self.hidden_size, self.num_layers, batch_first=True)
# self.linear = nn.Linear(self.hidden_size, self.output_size)
#
# def forward(self, input_seq):
# batch_size, seq_len = input_seq.shape[0], input_seq.shape[1]
# h_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# c_0 = torch.randn(self.num_directions * self.num_layers, self.batch_size, self.hidden_size).to(device)
# # output(batch_size, seq_len, num_directions * hidden_size)
# output, _ = self.lstm(input_seq, (h_0, c_0)) # output(5, 30, 64)
# pred = self.linear(output) # (5, 30, 1)
# pred = pred[:, -1, :] # (5, 1)
# return pred
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.num_directions = 1 # 单向LSTM
self.emb = torch.nn.Embedding(input_size, embedding_size) # 嵌入层
self.lstm=torch.nn.LSTM(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
# self.rnn = torch.nn.RNN(input_size=embedding_size,
# hidden_size=hidden_size,
# num_layers=num_layers,
# batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
h_0 = torch.zeros(self.num_directions*num_layers, x.size(0), hidden_size) # 构造h0
c_0 = torch.zeros(self.num_directions * num_layers, x.size(0), hidden_size)
x = self.emb(x) # 把长整型转变成嵌入层稠密的向量模式
x, _ = self.lstm(x, (h_0, c_0))
x = self.fc(x)
return x.view(-1, num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad() # 优化器归零
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward() # 反向传播
optimizer.step() # 优化器更新
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss=%.3f ' % (epoch + 1, loss.item()))
运行结果如下:

参考文献:
https://blog.csdn.net/two_apples/article/details/105150848?ops_request_misc=&request_id=&biz_id=102&utm_term=lstm&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-5-105150848.142^v42^new_blog_pos_by_title,185^v2^tag_show&spm=1018.2226.3001.4187