聚类是信息检索、数据挖掘中的一类重要技术,是分析数据并从中发现有用信息的一种有效手段。它将数据对象分组成为多个类或簇,使得在同一个簇中的对象之间具有较高的相似度,而不同簇中的对象差别很大。作为统计学的一个分支和一种无监督的学习方法,聚类从数学分析的角度提供了一种准确、细致的分析工具。而k-means算法是最常用和最典型的聚类算法之一,k-means算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大。该算法认为簇是由距离靠近的对象组成的,因此把得到紧凑且独立的簇作为最终目标。k-means的优点在于能快速的收敛及易于实现,但是该算法在一些数据量非常大的应用中表现出的性能是比较差的,因此,本文在研究了k-means算法的基础上,提出了利用GPU(Graphic Processing Unit)的并行计算能力来优化k-means算法的方案。
1 聚类分析及k-means算法
1.1 聚类分析技术
对于给定的数据集,按照一定的度量,把其中相似度大的归为一类,这样的过程称为聚类(Clustering)。聚类分析的结果是一个个的数据或对象的集合,称之为簇(Cluster):同一个簇中的对象相似,而与其他簇中的对象则不相似。现在主流的聚类分析技术一般可以分为以下几类:
(1)基于划分的方法。对于给定的n个对象,提供数值k(k≤N),将对象划分为k份,每一份满足“簇”的定义。典型的基于划分的算法有K-Means算法和K-Medoids算法。划分方法需要在运算之前就确定K的值。
(2)基于层次的方法。层次方法创建给定数据对象集的层次分解。层次方法可分为:凝聚法,开始时每个对象为一类,合并相似项,直至所有对象被合并为一个类;分裂法,开始时将所有对象都归类为一个类,逐次将每个类分裂为更小的类,直至所有对象的类满足“簇”的概念,或满足其他既定的收敛条件。典型的基于层次的算法有:BIRCH算法、ROCK(RObust Clusteringusing linKs)算法和Chameleon算法。
(3)基于密度的方法。基于距离的聚类算法更容易发现球形簇,但对于发现任意形状的簇,则力不从心。基于密度的方法能解决这个问题:对于数据集中的每一个点,在给定的半径邻域内,假设包含M个点,如果M满足既定的条件,则算法继续。常用的基于密度的方法有:DBSCAN(Density-Based Spatial Clustering of Applications with Noise)、DENCLUE(DENsity-based CLUstEring)和OPTICS(Ordering Points to Identify the Clustering Structure)。
(4)基于网格的方法[1]。该方法将对象空间划分为一定数量的单元,组成网格,并在此基础上进行聚类。典型的例子有:STING(Statistical Information Grid)、WaveCluster。
1.2 K-Means算法
在众多基于划分方法的聚类算法中,K-Means算法是最著名和最常用的算法之一。K-Means算法以k为输入参数,将给定的n个对象,划分为k个簇,使得簇内的对象相似度高,而不同簇内的对象的相似度低。
K-Means 算法的主要流程如下:
(1)在给定的n个对象中,随机选取k个对象,作为每一个簇的初始均值(中心);
(2)对于其余的n-k个对象,分别计算与k个中心的距离,将对象指派到最接近的簇;
(3)更新每个簇的新均值,得出k个新的中心;
(4)根据k个新的中心,重复(2)(3)两个步骤,直至准则函数收敛。
虽然K-Means算法实现起来比较简单,但K-Means算法也存在以下问题:
(1)需要对全部N个数据进行多次遍历,假设为 M 次;每次遍历中,对每个数据都需要进行 k 次比较运算,则计算复杂度为O(N*M*k),同时还需要反复读取原数据,并将比较结果多次写到存放分类信息的结果集中。虽然通常情况下,M< (2)K的大小需要在算法前确定,并且一般需要用户指定。这就需要依靠用户的经验,在运算前就明确,或大概明确现有的数据有多少个分类; (3)对于异常点、离群点较敏感,一个异常点就可能影响整个算法的结果; (4)初始簇中心的选取可能会对整个聚类结果产生很大的影响,甚至能产生截然不同的聚类结果。 因此,不少学者针对以上问题从不同方面提出了一些优化的方案[2]。例如,文献3中提出了一种使用K-D Tree来加速算法的执行时间的方案[3]。另一种方案是将K-Means算法中的计算部分高度并行化,文献4中提出利用OpenMP来优化K-Means算法[4]。但这种方法不可避免地会产生大量的多线程通信代价。 目前,大多数桌面计算机都配置了可编程的图形处理器(GPU,Graphic Processing Unit)。GPU是一种单指令流多数据流(SIMD)计算模式的处理器,在处理单元的数量上要远远超过CPU ,拥有数十个甚至上百个处理核心。尽管GPU的运行频率低于CPU,但更多的执行单元数量能够使GPU在浮点运算能力上获得大幅优势,同时期主流的GPU性能可以达到CPU性能的10倍左右。近年来,GPU性能的飞速发展,加上基于GPU的可编程性越来越简单,使得基于GPU并行计算来优化K-Means算法成为可行。 本文提出了一种基于GPU并行计算的K-Means算法的优化方案,将传统K-Means算法中计算密集部分采用并行化的方法在GPU上计算。下文将详细介绍GPU并行计算的相关原理及基于GPU并行计算的K-Means算法。 图形处理器技术的迅速发展带来的并不只是速度的提高,还产生了很多全新的图形硬件技术,使GPU具有流处理、高密集并行运算、可编程流水线等特性,从而极大的拓展了GPU的处理能力和应用范围。正是由于GPU具有高效的并行性和灵活的可编程性等特点,越来越多的研究人员和商业组织开始利用GPU完成一些非图形绘制方面的计算,并开创了一个新的研究领域:基于GPU的通用计算(GPGPU,General-Purpose computation on GPU),其主要研究内容是如何利用GPU在图形处理之外的其他领域进行更为广泛的科学计算。 GPU通用计算通常采用CPU+GPU异构模式[5],由CPU负责执行复杂逻辑处理和事务处理等不适合数据并行的计算,由GPU负责计算密集型的大规模数据并行计算。这种利用GPU强大处理能力和高带宽弥补CPU性能不足的计算方式在发掘计算机潜在性能,在成本和性价比方面有显著的优势。在2007年NVIDIA推出CUDA(Compute Unified Device Architecture,统一计算设备架构)之前,GPU通用计算受硬件可编程性和开发方式的制约,开发难度较大。2007年以后,CUDA不断发展的同时,其他的GPU通用计算标准也被相继提出,如由Apple提出Khronos Group最终发布的OpenCL,AMD推出的Stream SDK,Microsoft则在其最新的Windows7系统中集成了Direct Compute以支持利用GPU进行通用计算,程序员利用这些语言可以比较轻松地把一些应用程序移植到GPU上。 CUDA编程模型[6]将CPU作为主机(Host),GPU作为设备(Device)。在一个系统中可以存在一个主机和若干个设备。CPU、GPU各自拥有相互独立的存储地址空间:主机端内存和设备端显存。CUDA对内存的操作与一般的C程序基本相同,但是增加了一种新的pinned memory;操作显存则需要调用CUDA API存储器管理函数。一旦确定了程序中的并行部分,就可以考虑把这部分计算工作交给GPU。运行在GPU上的CUDA并行计算函数称为kernel(内核函数)。一个完整的CUDA程序是由一系列的设备端kernel函数并行步骤和主机端的串行处理步骤共同组成的。这些处理步骤会按照程序中相应语句的顺序依次执行,满足顺序一致性。 从上文对K-Means算法主要流程的介绍中可以看到,K-Means算法的主要计算任务集中在第(2)、(3)这两个步骤,即计算每个对象与K个簇的距离,并将每个对象分配到一个簇中以及更新每个簇的新中心。因此,基于GPU的K-Means算法主要从这两方面来考虑如何进行并行优化。 基于GPU的K-Means算法在进行数据对象分配这一步骤的时候有两种策略。第一种策略是面向每个簇的中心,通过计算出该簇的中心与每个数据对象的距离,然后将每个数据对象归并到距离簇中心最近的那个簇中。这种策略适应于GPU的处理核心数量比较少的情况,此时,GPU中的每个处理核心可以对应一个簇的中心,并且能够连续的处理所有的数据对象。另一种策略是面向每个数据对象,每个数据对象计算与所有簇中心的距离,然后数据对象将会被分配到距离簇中心最近的那个簇当中。该策略适应于GPU的处理核心比较大的情况,目前主流的GPU一般都有超过100个处理核心,因此第二种处理策略比较合适。图1展示了上述两种策略的不同思想。 图1 数据分配过程不同策略对比图 新的簇中心是通过计算原有簇中所有数据对象的数学平均值得到的。K-Means算法中K个簇中心的位置也可以通过GPU来计算,CUDA中的每个线程负责一个簇中心,如图2所示。 图2 更新K个簇的中心 当数据对象分配结束之后,可以得到每个数据对象所属的簇的下标。要重新计算每个簇的中心位置,一个直观的想法就是读取所有的数据对象,然后判断哪些属于一同个簇。但是,在GPU上如果大量线程都需要同时访问共享内存的话,势必会因为等待访问造成大量的延时,因此这里先将数据对象分配的结果从设备(GPU)传送到主机(CPU),然后由主机来重新安排,并计算出每个簇包含数据对象的数量。之后,将处理过的数据再传送给设备的共享内存。通过这种途径,CUDA中每个线程只需连续地读取属于该簇的数据对象的数据来计算平均值,从而不会发生多个线程对共享内存竞争的情况。 基于GPU的K-Means算法的主要思想是将传统的K-Means算法中的数据独立,计算密集的部分从主机转移到设备上处理,从而提高性能。更具体的说,数据对象的分配过程和K个簇中心的更新过程虽然要执行很多次,但每次计算以及每次计算的数据之间都是相互独立的,并不存在前后依赖的关系,因此可以将其分离成两个单独的内核函数,交给GPU的大量的处理核心来并行计算。 尽管GPU的SIMD的计算模式擅长并行计算,但是基于GPU的K-Means算法有三个重要的原则需要说明。第一,GPU设备的分支转移控制和数据缓存机制都非常弱,因为大量的计算处理单元占用了GPU内部的大部分空间。第二,GPU与GPU全局内存之间的数据传输速率和CPU与CPU高速缓存之间的数据传输速率相比要慢很多,因此适当的线程块和线程束大小才能体现出GPU的强大计算能力。第三,与传统的K-Means算法相比,基于GPU的K-Means算法增加了在GPU全局内存与CPU内存之间传输数据的时间。因此要达到优化算法性能的目的,必须合理地分配主机与设备的职责,合理地设计与实现数据存储和并行计算的模式。 基于GPU的K-Means算法的主要流程图如图3所示。 图3 基于GPU的K-Means算法流程图 如图3所示,在任务职责分配方面,主机部分主要负责随机产生初始的K个簇的中心,对数据对象分配的结果进行预处理以及判断聚类过程是否已经收敛;而设备部分则主要负责数据独立的密集型计算过程。在数据存储方面,所有的数据对象以及簇中心的数据都需要在设备上以数组的形式存储。在GPU设备上,核函数中所有线程所共享的内存有三类:常量内存,纹理内存以及全局内存。常量内存和纹理内存都是只读的而且其有用的大小也很有限,所以对于算法中的数据是不合适的。另外,在GPU和显存之间的传输带宽要比在主机内存和显存之间传输数据的带宽高得多,考虑到这一点,在基于GPU的K-Means算法中,在主机和设备之间传输的簇中心的下标数据大小要尽量的小。这种基于CPU+GPU异构模式虽然会产生额外的数据I/O的时间消耗,但是GPU的计算模型中,大量线程的并行能够减少读取内存的延迟。 本文阐述了传统的K-Means聚类算法的具体过程以及其中的复杂性和效率问题,并提出将其中计算密集的处理部分分离到GPU上进行处理的优化方案。随着CUDA、OpenCL、Stream SDK等其他GPU通用计算标准的提出和发展,GPU的强大处理能力和高带宽的特点将会越来越突显。本文的主要研究目的在于提出将信息检索和数据挖掘方面的部分经典算法与GPU并行计算相结合的思想,使其通过并行处理在性能上达到高效的优化。2 GPU通用计算编程模型
3 基于GPU的K-Means算法
3.1 数据对象分配
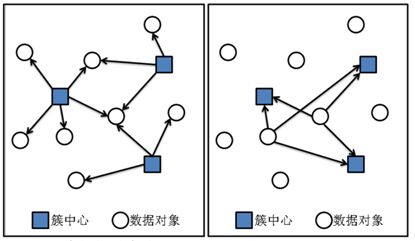
3.2 更新K个簇的中心
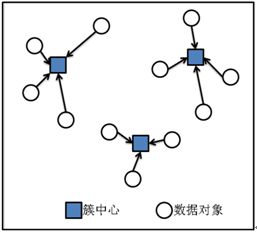
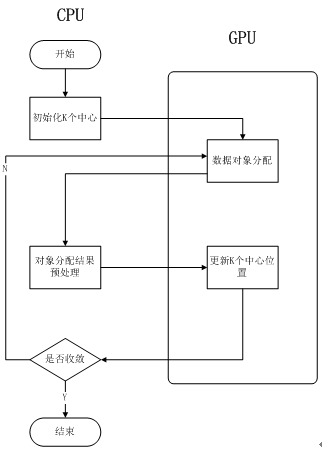
3.3 整体思想
4 总结