OpenCV特征检测与匹配方法概览
openCV特征检测与匹配方法概览
- 初学小白,刚开始学习图像处理,所以汇总了一些基础性的函数以及方法,贴出来供大家参考。有错误欢迎指正。
- 摘要
- 一、常用角点检测器
- 二、常用特征匹配符
- 三、常用匹配器
- 四、 常用匹配函数及匹配绘制函数
- 五、优化
-
- 设置匹配条件
初学小白,刚开始学习图像处理,所以汇总了一些基础性的函数以及方法,贴出来供大家参考。有错误欢迎指正。
摘要
常用角点检测器
1. Harris角点
2. Shi-Tomasi &易于跟踪的特征Good Features to Track(GFtT)
3. 高斯差Difference of Gaussians(DoG)
4. 加速分割测试特征Features from Accelerate Segment(FAST)
5.关键点的绘制
常用特征描述符
1. 图像块(Patch)
2. 尺度不变特征变换Scale Invariant Feature Transform(SIFT)
3. 加速鲁邦特征Speeded Up Robust Features(SURF)
4. 二值鲁棒独立元素特征Binary Robust Independent Elementary Features(BRIEF)
5. Oriented FAST and Rotated BRIEF(ORB)
6. 二值鲁棒可缩放关键点Binary Robust Invariant Scalable Keypoints(BRISK)
常用匹配器
1. 暴力匹配器Brute-Force(BF)
2. FLANN匹配器
常用匹配函数及匹配绘制函数
1. bf.match()和cv2.drawMatches()
2. bf.knnMatch()和cv2.drawMatchesKnn()
3. flann.match()和cv2.drawMatches()
4. flann.knnMatch()和cv2.drawMatches()
优化
1. 掩膜的绘制
2. RANSAC算法过滤
一、常用角点检测器
首先我们要了解什么是角点?在一般的图像处理过程中最开始需要进行的工作就是特征的检测与提取,一般的特征分为边缘、角点以及感兴趣区域。边缘就是图像的轮廓边缘,呈线条状;角点顾名思义是一个个的点;感兴趣区域则是我们认为设定的一个区域范围。在这三类特征值之中,角点,通常也称为感兴趣关键点,使我们最为关心的特征。那么到底什么是角点?角点,就是两个或者更多边缘的交点,一旦角点出现移动或变化,将会引起图像的灰度信息的强烈变化。
这里顺便说明一下为什么在进行特征提取的时候需要将彩色图转化为灰度图。在物体识别的过程中,最主要的因素就是梯度,梯度意味着灰度上的变化,要想计算梯度,自然就需要应用到灰度图像。再者物体上的颜色受到光照影响容易发生较大变化,转化为灰度图像可以加速特征的提取。
上面我们已经说明什么是角点了。接下来就介绍一下角点检测器。
1. Harris角点检测器
应用函数:
cv2.cornerHarris(img, blockSize, ksize, k )
img: 数据类型为float32的输入图像;
blockSize: 角点检测中要考虑的领域大小;
ksize: Sobel求导中使用的窗口大小;
k: Harris角点检测方程中的自由参数,取值参数为[0.04, 0.06]。
优点:稳定性高,尤其对L型角点(直角)检测精度高;
缺点:由于采用了高斯滤波,运算速度相对较慢,角点信息有丢失和位置偏移的现象,而且角点提取有聚簇现象。不具有尺度不变性。
Harris角点检测示例程序
import cv2
import numpy as np
filename = 'chessboard.jpg'
img = cv2.imread(filename)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
gray = np.float32(gray)
dst = cv2.cornerHarris(gray,2,3,0.04)
#result is dilated for marking the corners, not important
dst = cv2.dilate(dst,None)

2. Shi-Tomasi &易于跟踪的特征Good Features to Track(GFtT)
应用函数:
cv2.goodFeaturesToTrack(img, maxCorners, qualityLevel, minDistance)
Img: 浮点型32位灰度图像;
MaxCorners: 想要检测的最大角点数量;
QualityLevel: 角点的质量水平,0~1之间;
minDistance: 两角点之间的最短欧氏距离。
优点:Harris的改进版,通过应用较小的特征值与阈值进行比较获得具更好的强角点;
缺点:由于采用了高斯滤波,运算速度相对较慢,角点信息有丢失和位置偏移的现象,而且角点提取有聚簇现象。不具有尺度不变性。
Shi-Tomasi &易于跟踪的特征Good Features to Track(GFtT)特征点检测示例程序
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('simple.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
corners = cv2.goodFeaturesToTrack(gray,25,0.01,10)
corners = np.int0(corners)
for i in corners:
x,y = i.ravel()
cv2.circle(img,(x,y),3,255,-1)
plt.imshow(img),plt.show()
3. 高斯差Difference of Gaussians(DoG)
DoG是包含在SIFT和SURF特征描述符的,所以没有具体的相关函数介绍。
不同的尺度空间需要使用大小不同的窗口进行极值点检测,原始方法是使用具有不同方差值σ的高斯拉普拉斯算子(LoG)对图像进行卷积。但由于计算量庞大,所以使用高斯差(DoG)进行代替。
首先通过降采样来构成一组图像尺寸不同的金字塔,然后对这一组图像使用具有不同方差σ的高斯卷积核构建出具有不同分辨率的图像金字塔。注意这是两个金字塔。DoG就是具有不同分辨率的图像金字塔中的差值。
优点:图像具有尺度不变性;相对于高斯拉普拉斯(LOG拉普拉斯操作+降采样)来讲,效率更高。
缺点:计算量大。
4. 加速分割测试特征Features from Accelerate Segment(FAST)
应用函数:
cv2.FastFeatureDetector ()
该函数初始化FAST特征检测器对象,没有具体参数。
FAST首先对固定半圆上的像素进行分割测试,通过逻辑测试可以去除大量的候选特征点(比较圆圈边缘像素值与中心点的像素值);然后进行基于分类的角点特征检测,利用ID3分类器根据16个特征判决候选点是否为角点特征,每个特征的状态为-1,0,1;最后利用非极大值抑制进行角点特征的验证。
注意:FAST被称为除上述之外任何其它特征检测器,可以通过设定阈值,是否应用非最大抑制,是否使用领域等来进行任意类型的检测。
优点:计算速度快,可以应用于实时场景;
缺点:容易受到噪声的影响以及阈值t的影响。
加速分割测试特征Features from Accelerate Segment(FAST)特征点检测示例程序
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('simple.jpg',0)
fast = cv2.FastFeatureDetector()
kp = fast.detect(img,None)
img2 = cv2.drawKeypoints(img, kp, color=(255,0,0))
cv2.imwrite('fast_true.png',img2)
fast.setBool('nonmaxSuppression',0)
kp = fast.detect(img,None)
print "Total Keypoints without nonmaxSuppression: ", len(kp)
img3 = cv2.drawKeypoints(img, kp, color=(255,0,0))
cv2.imwrite('fast_false.png',img3)

5. 关键点的绘制
» 在opencv中绘制关键点函数的定义为:
drawKeypoints(image, keypoints, outImage, color, flags)
image:原始图片;
keypoints: 从原始图片中获得的关键点;
outImage: 输出,可以是None;
color: 颜色设置(b, g, r);
flags: 绘图功能的标识设置,默认在关键点部位绘制圆圈,如果设置为flags=cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)在关键点部位绘制圆圈并绘制出关键点的方向。
主要有以下几种绘制方式:
cv2.DRAW_MATCHES_FLAGS_DEFAULT,
cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS,
cv2.DRAW_MATCHES_FLAGS_DRAW_OVER_OUTIMG,
cv2.DRAW_MATCHES_FLAGS_NOT_DRAW_SINGLE_POINTS
二、常用特征匹配符
首先要了解角点、特征点与描述符之间的区别和联系:
角点:包含大量本地信息的像素块,能够在另一张图中快速识别;
特征点:作为角点的扩展,它将像素块的信息进行编码从而使得其更易辨识;
描述符:是对特征点的进一步处理,具有更低的维度,从而使得图像块更容易在另一张图中被识别。
接下来我们来了解主要的描述符都有哪些。
1. 图像块(Patch)
对于一个特征点最直接的描述即围绕其本身的图像块,也就是环绕该特征的小块中所有像素的强度值,一般简称为“外观”。这列描述符的计算只需对给定位置进行二次抽样。“外观”并不是好的描述符,因为他所携带的信息会随着方向、尺度和视角的变化而发生变化,鲁棒性和重复性较差。
应用范围:使用图像块描述符的跟踪系统多假设相机视角变化缓慢,从而使得图像块的变化也缓慢。由于局限大,应用范围小。
2. 尺度不变特征变换Scale Invariant Feature Transform(SIFT)
在2004年由Lowe提出SIFT算法。它不仅具有尺度不变特性也具有旋转不变特性。
首先使用前面提到过的高斯差DoG在每一个不同尺度层使用高斯滤波器对图像进行卷积,构建图像金字塔,检测出特征点p,之后要为其计算一个具有尺度和旋转不变特性的环状多维描述符。
» 应用范围:SIFT描述符已被证明对光照、旋转、尺度和高达60度视角变换都具有很好的稳定性,已经成为视觉领域最流行的描述符。缺点是实时性不高、特征点检测较少。
» 应用函数:
初始化对象:
sift = cv2.xfeatures2d.SIFT_create()
检测特征点:
kp = sift.detect(gray, None)
计算描述符:
kp, des = sift.compute(gray, kp)
同时检测特征点或计算描述符:
kp, des = sift.detectAndCompute(gray,None)
尺度不变特征变换Scale Invariant Feature Transform(SIFT)示例程序
#coding=utf-8
import cv2
import scipy as sp
img1 = cv2.imread('x1.jpg', 0) # queryImage
img2 = cv2.imread('x2.jpg', 0) # trainImage
#Initiate SIFT detector
sift = cv2.xfeatures2d.SIFT_create()
#find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1, None)
kp2, des2 = sift.detectAndCompute(img2, None)

3. 加速鲁棒特征Speeded Up Robust Features(SURF)
在2006年Bay在SIFT算法的基础之上提出了SURF算法。SURF最大的特征在于采用了harr特征以及计分图像的概念,这极大地加快了运行时间。
①利用Hessian矩阵构建高斯金字塔尺度空间;
②初步确定特征点与精确定位极值点与SIFT算法相同
③选取特征点主方向;
④构造SURF特征点描述算子
» 应用范围以及优缺点:
优点:在结果效果相当的情况下SURF的速度是SIFT的3倍,
善于处理模糊和旋转的图像;
缺点:不善于处理视角变化和光照变化的图像。
在选取主方向阶段过于依赖局部区域像素的梯度方向,一旦主方向选取错误将导致特征匹配误差放大。
» 应用函数:
与SIFT描述符类似。

** 4. 二值鲁棒独立元素特征Binary Robust Independent Elementary Features(BRIEF)**
» 应用函数:
kp, des = brief.compute(img, kp)
以此来计算brief描述符。
BRIEF是2010年由CvLab提出的一种采用二值字符串的高校特征描述符。主要思想是在特征点附近随近随机选取若干点对,将这些点对的灰度值大小组合成一个二进制串,这个二进制串就是该特征点的描述子。
» 应用范围以及优缺点:
优点:直接获取二进制字符串,应用汉明距离进行匹配,速度快;
缺点:该描述符不提供特征检测与提取的方法,需要和其他特征检测方法搭配使用(SIFT\SURF\CenSurE),不具备旋转和尺度不变性;对噪声敏感。
二值鲁棒独立元素特征Binary Robust Independent Elementary Features(BRIEF)示例程序
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('simple.jpg',0)
#Initiate STAR detector
star = cv2.FeatureDetector_create("STAR")
#Initiate BRIEF extractor
brief = cv2.DescriptorExtractor_create("BRIEF")
#find the keypoints with STAR
kp = star.detect(img,None)
#compute the descriptors with BRIEF
kp, des = brief.compute(img, kp)
print brief.getInt('bytes')
print des.shape
该程序借助了CenSurE detector特征检测器计算brief描述符。
5. Oriented FAST and Rotated BRIEF(ORB)
ORB可以视为FAST以及BRIEF算法的结合。FAST计算效率高但是特征点没有方向分量。BRIEF在许多方面可以媲美SIFT比如对光照、模糊和透视畸变的鲁棒性,但是同样不具备旋转不变性。
ORB首先为FAST检测的特征点计算方向,接下来为带有方向的FAST特征点计算可知旋转的BRIEF描述符,使其对平面内的旋转具有不变性。
» 适用范围即优缺点:
优点:处理速度快,是sift算法的100倍,SURF算法的10倍,具有旋转不变性;
缺点:不具备尺度不变性。一般应用于实时的视频处理。
»应用函数:
kp1, des1 = orb.detectAndCompute(img1, None)
Oriented FAST and Rotated BRIEF(ORB)示例程序
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('simple.jpg',0)
#Initiate STAR detector
orb = cv2.ORB()
#find the keypoints with ORB
kp = orb.detect(img,None)
#compute the descriptors with ORB
kp, des = orb.compute(img, kp)
#draw only keypoints location,not size and orientation
img2 = cv2.drawKeypoints(img,kp,color=(0,255,0), flags=0)
plt.imshow(img2),plt.show()
#Disable nonmaxSuppression

6. 二值鲁棒可缩放关键点Binary Robust Invariant Scalable Keypoints(BRISK)
» 应用函数:
kpt, des = brisk.detectAndCompute(img, None)
» 适用范围即优缺点:
优点:利用FAST进行特征检测,具备尺度不变性、旋转不变性以及对噪声的鲁棒性。
缺点:为了具有旋转不变性需要根据梯度选取特征主方向、一旦选取错误误差值较大,对于旋转不变性影响较大。
首先建立图像的尺度空间,应用FAST检测器对特征点进行检测,接下来在尺度空间上进行非极大值抑制滤除一线特征点,确定特征点后对其进行高斯平滑,计算局部梯度以及长、短距离点对子集,确定特征点的方向。之后将特征点方向进行旋转后再计算描述子。
因为BRISK描述子是二值特征,与BRIEF一样Hamming距离进行匹配。
二值鲁棒可缩放关键点Binary Robust Invariant Scalable Keypoints(BRISK)示例程序
img = cv2.imread(r'F:\projects\src\opencv\images\cotton\39.gray.jpg')
plt.imshow(img)
#创建brisk检测器
brisk = cv2.BRISK_create()
#进行特征点检测与计算
kpt, des = brisk.detectAndCompute(img, None)
bk_img = img.copy()
out_img = img.copy()
out_img = cv2.drawKeypoints(bk_img, kpt, out_img)
plt.figure(2)
plt.imshow(out_img)
三、常用匹配器
1. 蛮力匹配器(Brute-Force, BFMatcher)
(自己绘制的一个理解图)
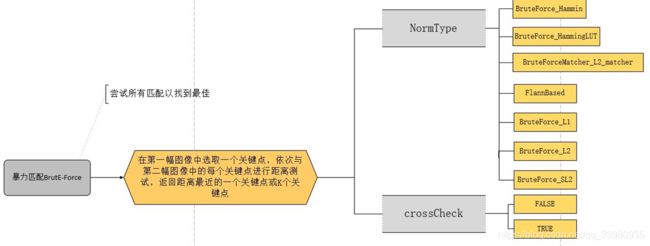
蛮力匹配器首先在第一幅图像中选取一个关键点然后依次与第二幅图像的每个关键点进行描述符距离测试,最后返回最近的关键点。
首先需要使用cv2.BFMatcher()创建一个对象。在终端中输入help可以得知BFMatcher有两个参数:
BFMatcher [normType, crossCheck]
第一个参数normType: 用来指定要使用的距离测试类型。
默认值是cv2.Norm_L2(欧氏距离),这一类型的测试距离适用于SIFT和SURF描述符,同样的cv2.NORM_L1也适用(出租车距离)。
对于ORB、BRIEF、BRISK这类型的二进制描述符,需要使用cv2.NORM_HAMMING汉明距离类型,这样就会返回两侧测试对象之间的汉明距离。当ORB算法的参数设置为VTA_K==3或者4,则normType = cv2.NORM_HAMMING2。
第二个参数是布尔变量crossCheck。
默认值是False,代表单方向的最佳匹配。当选择值为True的时候,匹配条件会更加严格,只有两幅图像中的特征点互相成为最佳匹配才行。
创建匹配器对象示例:
适用于SIFT和SURF的欧氏距离:
bf = cv2.BFMatcher()
都直接默认。
适用于ORB、BRIEF、BRISK的汉明距离:
bf = cv2.BFMatche(cv2.NORM_HAMMING, crossCheck = True)
2. 快速最近邻匹配器FAST_Library_for_Approximate _Nearest_Neighbors(FLANN)
是一个对大数据集和高维特征进行最近邻搜索算法的集合,而且这些算法已经被优化过了。在面对大数据集时效果好于BFMatcher。
FLANN匹配器一共具有两个参数:IndexParams和SearchParams。
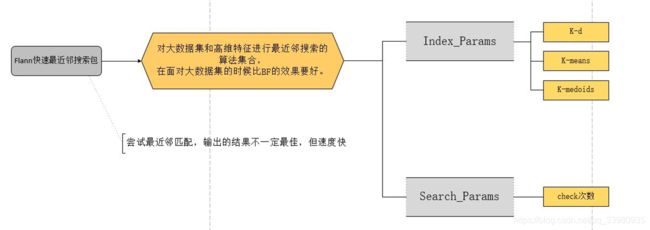
第一个参数IndexParams用来确定使用的算法。包含了随机k-d算法(The Randomized k-d TreeAlgorithm)、优先搜索k-means树算法(The Priority Search k-MeansTree Algorithm)、层次聚类树k-medoids(The Hierarchical Clustering Tree)
示例:
Index_params = dict(algorithm = FLANN_INDEX_KDTREE, tree = 5)
第二个参数值SearchParams,用来指定递归遍历的次数,次数越高结果越准确,但是消耗的时间也越多。
示例:
Search_params = dict(check = 50)
设置参数后,设定匹配器对象,同上述一样选择flann.Match()或者flann.knnMatch()进行匹配,选择cv2.drawMatches()或者cv2.drawMatchesKnn()绘制匹配。
Flann = cv2.FlannBasedMatcher(index_params, search_params)
Matches = flann.knnMatch(des1, des2, k=2)
…
Img3 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, matches, None, **draw_params)
四、 常用匹配函数及匹配绘制函数
暴力匹配器有两个方法来返回匹配:
BFMatcher.match会返回最佳匹配,BFMatcher.knnMatch()会返回k个最佳匹配。K值由用户自己设定。
示例:
Matches = bf.match(des1, des2)
或者是
matches = bf.knnMatch(des1, des2, k=2)
FLANN也相同:
Matches = flann.knnMatch(des1, des2, k=2)
与上述两个返回匹配的方法BFMatcher.match()和BFMatcher.knnMatch()相对应,Opencv提供两种方法来绘制匹配点:
cv2.drawMatches()和cv2.drawMatchesKnn()
Cv2.drawMatches()首先将两幅图像水平排列,在最佳匹配的点之间绘制直线,从源图像到目标图像。在opencv中可以看到次函数的参数如下:
drawMatches(img1, keypoints, img2, keypoints, matches1to2, outImg, matchColor, singlePointColor, matchesMask, flags)
Matches1to2:源图像1的特征点与源图像2匹配的特征点;
outImg: 输出图像由flags决定;
matchColor: 为匹配上的特征点和连线的颜色;
singlePointColor: 为未匹配特征点的颜色;
matchesMask: 为决定那些点被画出的掩膜,若为空则画出所有的匹配点;
示例:
Img3 = cv2.drawMatches(img1, kp1, img2, kp2, matches[:10], flags=2)
Cv2.drawMatchesKnn()为每个关键点和他的k个最佳匹配点绘制匹配线。如果返回匹配的函数中k=2时,则为每个关键点绘制2个最佳匹配点的线。他的参数与cv2.drawMatches()一样。
示例:
Img3 = cv2.drawMatchesKnn(img1, kp1,img2, kp2, good, flags=2)
其中good为挑选较好匹配的掩膜,稍后会讲到。
五、优化
1. 掩膜的绘制
示例:
good = []
For m,n in matches:
If m.distance < 0.75*n.distance:
good.append([m])
创建一个空的掩膜,假设A为原图像中的特征点,m和n为匹配图像的特征点,m为最近点,n为次近点。
当m与n的比值小于一定阈值时,选择特征点为正确的匹配点。
绘制所选择的特征点:
Img3 = cv2.drawMatchesKnn(img1, kp1,img2, kp2, good, flags=2)
2. RANSAC算法结合findHomography和perspectiveTransform函数
MIN_MATCH_COUNT = 10
good = []
for m,n in matches:
if m.distance < 0.7*n.distance:
good.append(m)
if len(good)>MIN_MATCH_COUNT:
src_pts = np.float32([ kp1[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
dst_pts = np.float32([ kp2[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
M, mask = cv2.findHomography(src_pts, dst_pts, cv2.RANSAC, 5.0) #用来计算基础矩阵的匹配点数量
matchesMask = mask.ravel().tolist()
h,w = img1.shape
pts = np.float32([ [0,0],[0,h-1],[w-1,h-1],[w-1,0] ]).reshape(-1,1,2)
dst = cv2.perspectiveTransform(pts,M)
img2 = cv2.polylines(img2,[np.int32(dst)],True,255,3, cv2.LINE_AA)
else:
print("Not enough matches are found - %d/%d" % (len(good),MIN_MATCH_COUNT))
matchesMask = None
设置匹配条件
如果达到足够数量的匹配点:
提取两个图像中匹配关键点的位置信息,应用calib3d模块内的函数cv2.findHomography()函数找到这两组特征点目标的透视转换,即一个3*3的矩阵。之后应用cv2.perspectiveTransform()函数通过这个透视转换来找到目标(需要至少四个点)。
为了消除一些错误的匹配,同时应用上RANSAC或者LEAST_MEDIAN算法,超过误差上线的被认为是outliers,否则则是inliers,应用findHomography函数返回关于内外点的掩膜,从而进行相关点的绘制。
如果未达到足够数量的匹配点:
显示信息说明没有足够数量的匹配点,只绘制已有的匹配。