Spring Cloud Stream函数式编程整合消息中间件
目录
-
- 一、关于配置的问题
- 二、详解SCS三神器
- 三、SCS个性化使用
- 四、多种发送消息的方式
- 五、消息分区
- 六、函数式编程
-
- 6.1. 概述
- 6.2. 入门demo
- 6.3. 手动发送消息
- 6.4. Binding的多端合流
- 6.5. 响应式编程
- 6.6. 函数式编程原理
Spring Cloud Stream入门篇:https://blog.csdn.net/weixin_43888891/article/details/126490478
一、关于配置的问题
上一篇生产者所使用的配置如下:
server:
port: 8801
spring:
application:
name: cloud-stream-provider
cloud:
stream:
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
output: # 这个名字是一个binding的名称(自定义)
destination: studyExchange # 通道,如果用的是RabbitMQ就是交换机名称
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置(binders可以有多个,可以指定binding的binder)
其实RabbitMQ可以直接使用spring.rabbitmq来进行配置,如下:
spring:
rabbitmq:
host: localhost
username: guest
password: guest
port: 5672
application:
name: cloud-stream-provider
cloud:
stream:
bindings: # 服务的整合处理
output: # 这个名字是一个binding的名称(自定义)
destination: studyExchange # 通道,如果用的是RabbitMQ就是交换机名称
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
原因如下,他默认就引用了amqp的starter!

就算我们不配置RabbitMQ的连接信息,只要本地启动了RabbitMQ他照样可以连接上,原因如下:spring.rabbitmq提供了默认的连接方式。


二、详解SCS三神器
- Binder:负责集成外部消息系统的组件
- Binding:由Binder而创建,负责沟通外部消息系统、消息发送者和消息消费者的桥梁
- Message:消息发送者与消息消费者沟通的简单数据结构
注意:配置文件当中可能会存在爆红的现象,原因就是我们是自定义的名称,yml文件有时候会存在识别不出来的情况,所以会出现爆红,但是功能是没有问题的!
spring:
application:
name: cloud-stream-provider
cloud:
stream:
# 负责集成外部消息系统的组件,binders可以绑定多个消息中间件,只需要定义不同的名称和type类型即可
binders: #可以绑定多个消息中间件
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
# 消息发送者和消息消费者的桥梁,由bindings来决定消息发送到什么地方,可以存在多个
bindings: # 服务的整合处理
output: # 这个名字是一个通道的名称
destination: studyExchange # 通道,如果用的是RabbitMQ就是交换机名称
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # defaultRabbit,就是binders设置的名称,如果没设定,就使用default-binder默认的
default-binder: defaultRabbit #defaultRabbit,就是binders设置的名称,假如有多个binder但是发消息的时候没有指定,那么就使用该默认binder
通过MessageChannel.sent(Message message);发送消息是一个message对象。消息分为两个部分,消息头和消息体。

构建message消息对象,withPayload来设置消息内容,setHeader来设置消息头。
Message<String> message = MessageBuilder.
withPayload(serial).setHeader("routingkey","aaaa").build();
三、SCS个性化使用
scs可以集成很多消息中间件,但是每个消息中间件消息模型都不一样,有时候我们就想用某个中间件的自己的功能怎么办呢?scs当然也是支持的。首先说明上哪里找:如下是scs目前支持的中间件,想要查看哪个直接点进去。

通过官网我们也可以知道,scs提供了两种配置方式,一种是常规的,所谓常规就是通用的,RabbitMQ也可以使用,Kafka也可以。还有一种是针对于消息中间件的一种配置方式,如下假如使用RabbitMQ可以通过spring.cloud.stream.rabbit前缀来配置RabbitMQ。
https://github.com/spring-cloud/spring-cloud-stream-binder-rabbit
注意有时候我们的application文件有时候根本就没有这些命令提示,这时候可以通过翻看官网来进行使用!
用法如下:举例RabbitMQ交换机有很多主题,默认采用了topic主题,我们可以通过scs针对中间件的个性化支持进行修改默认主题。
spring.cloud.stream.rabbit.default.<property>=<value>
<property>就是属性名称:<value>就是属性值,例如:exchangeType=主题名称
就是一种key/value的形式,具体的可以参照官网!

四、多种发送消息的方式
上一篇文章使用的是通过 @EnableBinding+ MessageChannel类来发送消息。下面是另外两种发送消息方式。
@Autowired
private Source source;
// 发送消息方式二,通过source.output()获取到MessageChannel来发送消息
@GetMapping("send1")
public String send1() {
String serial = UUID.randomUUID().toString();
// 创建并发送消息
System.out.println("***serial: " + serial);
Message<String> message = MessageBuilder.
withPayload(serial).setHeader("routingkey","aaaa").build();
source.output().send(message);
return serial;
}
@Autowired
private StreamBridge streamBridge;
// 发送消息方式三:新版本当中基本上都会用这种的来发送消息,可以指定bindingName
@GetMapping("send2")
public String send2() {
String serial = UUID.randomUUID().toString();
// 创建并发送消息
System.out.println("***serial: " + serial);
// 第一个参数就是bindingName,就是application当中配置的通道名称,第二个参数就是消息
streamBridge.send("output", serial);
return serial;
}
五、消息分区
有一些场景需要满足, 同一个特征的数据被同一个实例消费, 比如同一个id的传感器监测数据必须被同一个实例统计计算分析, 否则可能无法获取全部的数据。又比如部分异步任务,首次请求启动task,二次请求取消task,此场景就必须保证两次请求至同一实例。
说白了消息分区就是消息发送给谁,就只发送给谁,并且是一直发送给这个人。规则我们可以自己定。

(1)消费者配置:
spring:
application:
name: cloud-stream-consumer
cloud:
stream:
instance-count: 2 #该参数指定了当前消费者的总实例数量;
instance-index: 1 #该参数设置当前实例的索引号,从0开始,必须是跨多个实例的唯一值,其值介于和0--->instanceCount - 1
binders: # 在此处配置要绑定的rabbitmq的服务信息;
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
input: # 这个名字是一个binding的名称(自定义)
destination: studyExchange # 通道,如果用的是RabbitMQ就是交换机名称
content-type: application/json # 设置消息类型,本次为对象json,如果是文本则设置“text/plain”
binder: defaultRabbit # 设置要绑定的消息服务的具体设置
group: gxs # 分组名称,在rabbit当中其实就是交换机绑定的队列名称
consumer:
max-attempts: 3 #重试次数
partitioned: true #通过该参数开启消费者分区功能;
核心配置:

![]()
消费者监听:
@Component
@EnableBinding(Sink.class)
public class ReceiveMessageListener {
@Value("${server.port}")
private String serverPort;
@StreamListener(Sink.INPUT)
public void input(Message<String> message) {
MessageHeaders headers = message.getHeaders();
System.out.println(headers.get("routingkey"));
System.out.println(headers.get("id"));
System.out.println("消费者1号,------->接收到的消息:" + message.getPayload() + "\t port: " + serverPort);
}
}
(2)生产者配置:
spring:
application:
name: cloud-stream-provider
cloud:
stream:
binders: #可以绑定多个消息中间件
defaultRabbit: # 表示定义的名称,用于于binding整合
type: rabbit # 消息组件类型
environment: # 设置rabbitmq的相关的环境配置
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
bindings: # 服务的整合处理
output: # 这个名字是一个binding的名称(自定义)
destination: studyExchange # 通道,如果用的是RabbitMQ就是交换机名称
content-type: application/json # 设置消息类型,本次为json,文本则设置“text/plain”
binder: defaultRabbit # 如果没设定,就使用default-binder默认的
producer:
# 指定了消息分区的数量。
partitionCount: 2
# 指定分区键的表达式规则,我们可以根据实际的输出消息规则来配置SpEL来生成合适的分区键;
partition-key-expression: headers.id1
default-binder: defaultRabbit #假如有多个binder但是发消息的时候没有指定,那么就使用该默认binder
核心配置:

消息发送: 通过以上配置我们可以实现,假如消息请求头中的 id1 = 1的时候,消费者能收到,因为消费者设置的为instance-index = 1。假如多个消费者,可以设置另一个消费者为0。然后通过 请求头当中的id1,来决定发往哪个消费者。
@Autowired
private Source source;
// 发送消息方式二,通过source.output()获取到MessageChannel来发送消息
@GetMapping("send1")
public String send1() {
String serial = UUID.randomUUID().toString();
// 创建并发送消息
System.out.println("***serial: " + serial);
Message<String> message = MessageBuilder.
withPayload(serial).setHeader("id1",1).build();
source.output().send(message);
return serial;
}
所谓的分区主要还是为了区分消息发送给哪个消费者。举例,A区归消费A管,B区归消费者B管,互不干预,各自接 各自的消息。
RabbitMQ本质上是没有分区这一说的,实际上SCS是通过交换机绑定了两个队列来实现的分区。

关于生产者分区配置输出绑定,官方是提供了两种方式,一种是上面配置的partition-key-expression: headers.id1表达式形式,还有一种是我们自己来写一个规则类,然后注入到容器,通过partitionKeyExtractorName来配置注入到容器的名称。

六、函数式编程
6.1. 概述
在Stream v2.1版本之后支持函数式编程:https://docs.spring.io/spring-cloud-stream/docs/current/reference/html/spring-cloud-stream.html#spring_cloud_function

主要是记住命名规则即可!并且需要注意的,不使用函数式编程的时候一定不要这种命名,否则他会去寻找对应的函数名称的Bean。
他是通过bindings的name命名规则,来和容器当中的Function来进行关联的。光通过看 实际上根本不懂,下面我们通过案例来进一步了解。
6.2. 入门demo
在使用函数式编程的时候一定不要用之前的注解,不然函数式编程会失效的!这个一定要注意!!!
(1)生产者:
spring:
rabbitmq:
host: localhost
username: guest
password: guest
port: 5672
cloud:
function:
#代表的是使用哪些函数,函数bean名称,如果bindings有多个,这块名称也可以写多个,通过分号拼起来即可
definition: source
stream:
bindings:
source-out-0: # 绑定名称
destination: transfer # 通道,如果用的是RabbitMQ就是交换机名称
启动类中添加即可:
// 供应商函数,就是发送消息者,供应消息的
@Bean
public Supplier<String> source() {
return () -> {
String message = "from source";
System.out.println("------------------from source--------------");
return message;
};
}
(2)消费者:
spring:
rabbitmq:
host: localhost
username: guest
password: guest
port: 5672
cloud:
function:
#代表的是使用哪些函数
definition: sink
stream:
bindings:
sink-in-0: #binding的名称
destination: transfer # 通道,如果用的是RabbitMQ就是交换机名称
group: sink #分组
启动类中添加即可:
// Consumer消费函数,在stream当中用来当中接受消息者
@Bean
public Consumer<String> sink() {
return message -> {
System.out.println("----------------sink:" + message + "---------------");
};
}
(3)启动测试:
启动之后生产者会一直发送消息,而消费者也会一直消费消息。


启动后会发现创建了transfer交换机,然后绑定了一个如下队列,通过这个队列一直保持发送和消费。
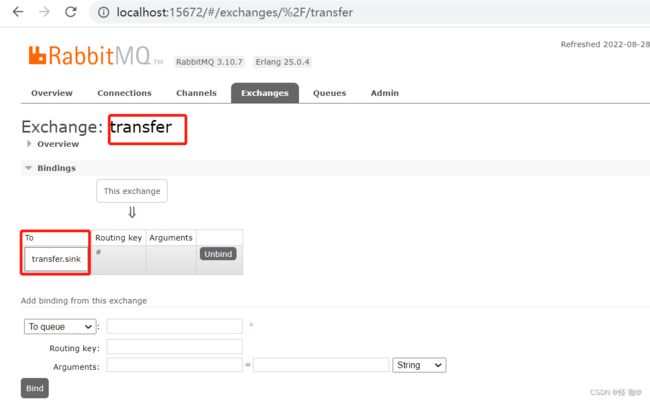
为什么会一直发送消息呢?

6.3. 手动发送消息
通过上面示例我们发现,他是每秒自动发送消息的,实际开发当中很少会有这种场景,一般都是手动发送消息,那么使用函数式编程,怎么发送消息呢?
首先明确一点,函数式编程的生产者不需要函数来发送消息,他是通过StreamBridge来发送消息的。
@Autowired
private StreamBridge streamBridge;
// 发送消息方式三,
@GetMapping("send2")
public String send2() {
String serial = UUID.randomUUID().toString();
// 创建并发送消息
System.out.println("***serial: " + serial);
// 第一个参数就是bindingName,就是application当中配置的通道名称,第二个参数就是消息
streamBridge.send("output", serial);
return serial;
}
其次还需要修改生产者配置文件:这样发送消息,消费者就可以通过那个函数来进行监听了。
#正常的发送,然后消费者通过函数式编程来进行监听
spring:
rabbitmq:
host: localhost
username: guest
password: guest
port: 5672
cloud:
stream:
bindings:
output: # 绑定名称
destination: transfer # 通道,如果用的是RabbitMQ就是交换机名称
6.4. Binding的多端合流
所谓合流就是将两个队列当中的消息合为一个。
(1)生产者:
# Binding的多端合流
spring:
rabbitmq:
host: localhost
username: guest
password: guest
port: 5672
cloud:
stream:
bindings:
gather1: # 绑定名称
destination: input1 # 通道,如果用的是RabbitMQ就是交换机名称
gather2: # 绑定名称
destination: input2 # 通道,如果用的是RabbitMQ就是交换机名称
生产者发送消息:
@Autowired
private StreamBridge streamBridge;
// Binding的多端合流测试
@GetMapping("send3")
public String send3(String message,String message2) {
streamBridge.send("gather1", message);
streamBridge.send("gather2", message2);
return "message sended";
}
(2)消费者:
# Binding的多端合流
spring:
rabbitmq:
host: localhost
username: guest
password: guest
port: 5672
cloud:
function:
#代表的是使用哪些函数
definition: gather;sink
stream:
bindings:
#通过定义名称gather-in-0和gather-in-1来监听两个交换机的消息,gather函数就尤其重要了
gather-in-0:
destination: input1
group: gather1
gather-in-1:
destination: input2
group: gather2
#gather合并流之后转发到transfer
gather-out-0:
destination: transfer
#监听transfer,然后并使用sink函数输出
sink-in-0:
destination: transfer
group: sink
启动类当中将如下两个函数注入到容器当中。
// Consumer消费函数,在stream当中用来当中接受消息者
@Bean
public Consumer<String> sink() {
return message -> {
System.out.println("----------------sink:" + message + "---------------");
};
}
// 通过这个函数进行将流拼接到一块,并输出出去
@Bean
public Function<Tuple2<Flux<String>, Flux<String>>, Flux<String>> gather() {
return tuple -> {
Flux<String> f1 = tuple.getT1();
Flux<String> f2 = tuple.getT2();
// return Flux.merge(f1, f2);
return Flux.combineLatest(f1, f2, (str1, str2) -> str1 + ":" + str2);
};
}
(3)测试:
http://localhost:8801/send3?message=1&message2=aaa
消费者监听到消息,并进行合流输出!

(4)总结:
只要消息进入到中间件当中,就通过配置binding名称 和 函数的搭配 任意的转发消息和监听消息 并处理消息,而消息他就跟流一样可以被任意改动。消息可扩展性极高。只需要通过一个简单的配置就可以更改消息(消息就可以当作是流)的去向。上面消息消费者的配置当中就体现出来了这一点!合流之后将流转发到transfer通道,再由binding名称为
sink-in-0的来监听transfer通道!
6.5. 响应式编程
这里用到了响应式编程当中的Flux,本篇就不过多叙述响应式编程了,后续了会专门写文章!
通过下面示例大家可以简单练习一下,可以大概知道他是干什么的。
Flux和集合不一样,集合我们存储进去值之后,通过get()就可以获取,而Flux是不可以的。

6.6. 函数式编程原理
说到函数式编程原理,首先我们要明白什么是函数式。其次是Lambda表达式。关于这两点不懂的,建议看一下这篇文章:
https://blog.csdn.net/weixin_43888891/article/details/124795863
首先来看消费者配置如下:binding名称为sink-in-0代表的是,他要将这个binding 绑定到spring容器当中sink名称的对象,in代表的就是输入的意思。而输入可以理解为就是接受消息。后面那个index一般用不到,设置为0即可,当然在上面合流场景的时候,我们就用到了 。
spring:
cloud:
function:
#代表的是使用哪些函数
definition: sink
stream:
bindings:
sink-in-0: #binding的名称
destination: transfer # 通道,如果用的是RabbitMQ就是交换机名称
group: sink #分组
通过@Bean注解注入到容器里面,默认的Bean名称就是方法名。
// Consumer消费函数,在stream当中用来当中接受消息者
@Bean
public Consumer<String> sink() {
return message -> {
System.out.println("----------------sink:" + message + "---------------");
};
}
Consumer函数是传入一个对象,没有返回值,所以SCS就利用这个来绑定我们的消息。首先通过配置文件的binding 名称sink-in-0找到了容器当中的Bean名称为sink的Consumer函数,然后监听到transfer通道有消息后,直接发消息给Consumer函数,由他进行消费。
