【Python数据分析学习实例】pandas库数据预处理
问题描述
如数据表字段(工号,姓名,性别[男/女],省份[自定义],学历[大专/本科/硕士/博士],工资[自定义金额],消费[自定义金额],存款[自定义金额])。
| 工号 | 姓名 | 性别 | 省份 | 学历 | 工资 | 消费 |
|---|---|---|---|---|---|---|
| 1001 | 张三 | 女 | 湖南 | 博士 | 10000 | 5000 |
······
要求如下:
- 自定义数据及文件格式。
- 能够存取数据文件。
- 不少于3种数据处理方式(自定义常规处理方法)。
- 根据结果进行绘图(样式不能相同)。
代码实现
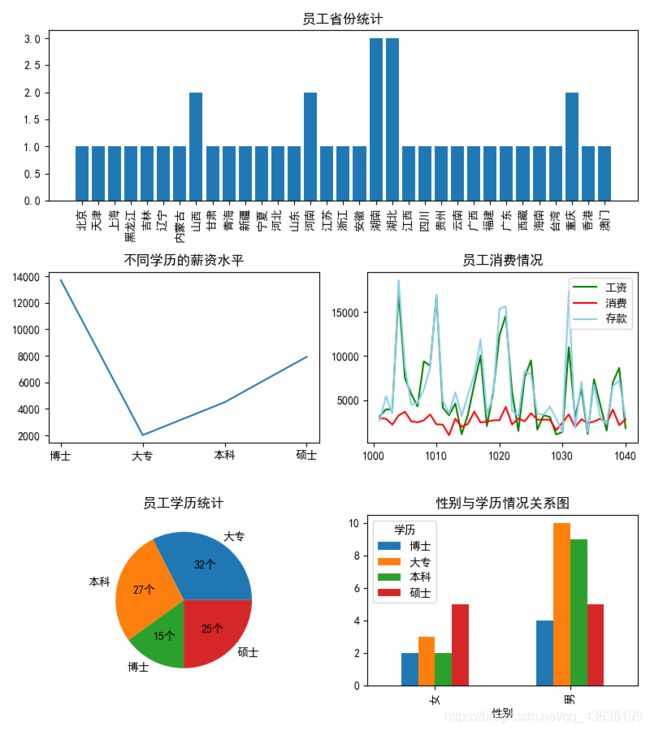
实验结果
完整代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from collections import Counter
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号
data = pd.read_csv("data.csv")
fig = plt.figure(figsize=(8,9))
province = dict(Counter(data.省份))
ax1 = fig.add_subplot(3,1,1)
plt.title('员工省份统计')
plt.bar(province.keys(),province.values(),align='center')
plt.xticks(rotation =90)
Average_salary = dict(data.groupby(data['学历'])['工资'].mean())
ax2 = fig.add_subplot(3,2,3)
plt.title('不同学历的薪资水平')
plt.plot(Average_salary.keys(), Average_salary.values())
ax3 = fig.add_subplot(3,2,4)
plt.title('员工消费情况')
plt.plot(data.工号, data.工资, color='green', label='工资')
plt.plot(data.工号, data.消费, color='red', label='消费')
plt.plot(data.工号, data.存款, color='skyblue', label='存款')
plt.legend() # 显示图例
education = dict(Counter(data.学历))
ax5 = fig.add_subplot(3,2,5)
plt.title('员工学历统计')
plt.pie(x = education.values(),labels = education.keys(),autopct='%d个')
ax6 = fig.add_subplot(3,2,6)
Education_Statistics = pd.crosstab(data.性别,data.学历)
Education_Statistics.plot(kind='bar',title='性别与学历情况关系图',ax = ax6)
plt.tight_layout()
plt.show()