pytorch 深度学习实践 第12讲 循环神经网络高级篇 Basic RNN
第12讲 循环神经网络高级篇 Basic RNN
pytorch学习视频——B站视频链接:《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
以下是视频内容笔记以及源码,笔记纯属个人理解 。
全连接网络以前也叫做稠密网络Dense 或者 深度网络Deep——DNN
1. RNN的基本概念
处理序列化输入
-
理解1
一个RNN Cell将一个多维向量映射成不同维数的向量,本质上相当于是一个线性层。如图所示

-
理解2
展开来看,就是前面特征的输入经过RNN Cell层之后的输出h1(隐藏层)继续和后面特征一起输入到RNN Cell,如图所示,图中的RNN Cell是同一个线性层,所以训练的其实就是一个层的权重。

# 写成伪代码形式大概长这样——所以叫循环神经网络 for x in X: h = linear(x, h)
2. RNN的简单计算
- 公式如下:
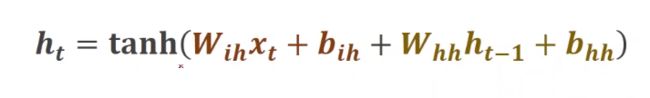
-
具体计算如下:
前一层的隐藏层h和当前层的输入x分别经过线性层处理后相加,激活函数使用tanh,如图所示:

3. RNN的使用方式
-
方式1——定义RNN Cell来构造循环神经网络
# 定义一个RNN Cell,input_size是输入维度,hidden是隐层维度,输出维度和hidden一样 cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size) hidden = cell(input, hidden)-
输入input和输出output的形状定义
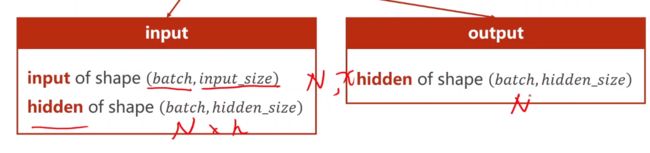
-
举个栗子
构造RNN时,输入、输出以及数据集的形状和维度定义(主要是弄清楚这个)

-
实现
import torch batch_size = 1 seq_len = 3 input_size = 4 hidden_size = 2 cell = torch.nn.RNNCell(input_size=input_size, hidden_size=hidden_size) dataset = torch.randn(seq_len, batch_size, input_size) hidden = torch.zeros(batch_size, hidden_size) for idx, input in enumerate(dataset): print('='*20, idx, '='*20) print('Input size: ', input.shape) hidden = cell(input, hidden) print(input) print('hidden size: ', hidden.shape) print(hidden)
-
-
方式2——直接使用RNN
# 用RNN定义,num_layers是RNNCell个层数 cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers) out, hidden = cell(inputs, hidden)-
输入、输出、隐藏层的维度定义
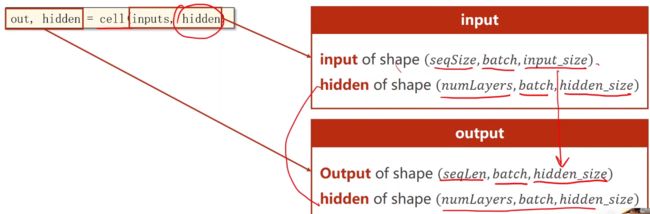
-
举个栗子

-
具有三层RNN Cell的循环神经网络,如图所示:
-
output和hidden表示的各个部分
-
输入x和隐层输入h0表示的各个部分

-
-
实现
import torch batch_size = 1 seq_len = 3 input_size = 4 hidden_size = 2 num_layers = 1 cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers) inputs = torch.rand(seq_len, batch_size, input_size) hidden = torch.zeros(num_layers, batch_size, hidden_size) out, hidden = cell(inputs, hidden) print('Output size: ', out.shape) print('Output: ', out) print('Hidden size: ', hidden.shape) print('Hidden: ', hidden)
-
4. RNN处理过程——实例
-
输入序列“hello”——输出“ohlol”
-
RNN Cell的输入应该是数值向量
-
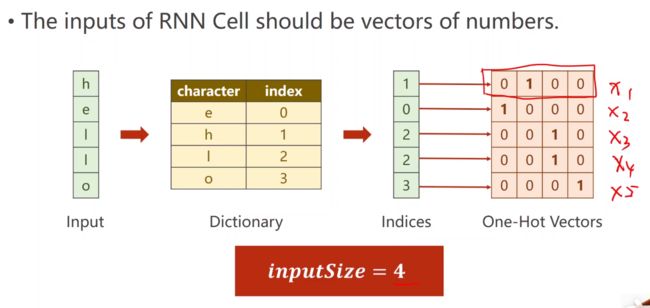
将输入转换成向量的过程如图所示:
先对输入的序列建立索引,每一个索引都有单独的编码,将此编码(即独热向量),用来表示输入的序列,如图所示:
-
 - 每一个隐层的输出是一个类别
- 每一个隐层的输出是一个类别 如图所示:
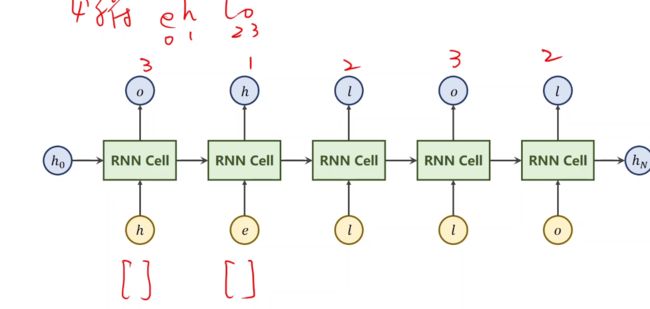
-
通过RNN处理后,结果可用于预测输出
RNN Cell输出的是一个向量,将此向量作为softmax的输入,再经过损失函数与标签的独热向量进行比较,开始训练。如图所示:

-
代码实现
rnn_cell.py
import torch input_size = 4 hidden_size = 4 batch_size = 1 # 准备数据 idx2char = ['e', 'h', 'l', 'o'] x_data = [1, 0, 2, 2, 3] y_data = [3, 1, 2, 3, 2] # 独热编码查询 one_hot_lookup = [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]] x_one_hot = [one_hot_lookup[x] for x in x_data] inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size) labels = torch.LongTensor(y_data).view(-1, 1) # 定义模型 class Model(torch.nn.Module): def __init__(self, input_size, hidden_size, batch_size): super(Model, self).__init__() # self.num_layers = num_layers self.batch_size = batch_size self.input_size = input_size self.hidden_size = hidden_size # 注意RNNCell的形状 self.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size) def forward(self, input, hidden): hidden = self.rnncell(input, hidden) return hidden def init_hidden(self): # h0层;初始化隐藏层 return torch.zeros(self.batch_size, self.hidden_size) net = Model(input_size, hidden_size, batch_size) criterion = torch.nn.CrossEntropyLoss() # 改进的基于随机梯度下降的优化器 optimizer = torch.optim.Adam(net.parameters(), lr=0.1) # 训练 for epoch in range(15): loss = 0 optimizer.zero_grad() hidden = net.init_hidden() print('Predicted string: ', end='') # inputs的形状是(序列长度, 批次大小, 输入向量维度) # labels——(序列长度, 1) # print('\ninputs: ', inputs.shape, inputs) # print('labels: ', labels.shape, labels) for input, label in zip(inputs, labels): hidden = net(input, hidden) loss += criterion(hidden, label) _, idx = hidden.max(dim=1) print(idx2char[idx.item()], end='') loss.backward() optimizer.step() print(', Epoch [%d/15] loss=%.4f' % (epoch+1, loss.item()))rnn.py
import torch input_size = 4 hidden_size = 4 batch_size = 1 num_layers = 1 seq_len = 5 # 准备数据 idx2char = ['e', 'h', 'l', 'o'] x_data = [1, 0, 2, 2, 3] y_data = [3, 1, 2, 3, 2] # 独热编码查询 one_hot_lookup = [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]] x_one_hot = [one_hot_lookup[x] for x in x_data] inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size) labels = torch.LongTensor(y_data) # 定义模型 class Model(torch.nn.Module): def __init__(self, input_size, hidden_size, batch_size, num_layers=1): super(Model, self).__init__() self.num_layers = num_layers self.batch_size = batch_size self.input_size = input_size self.hidden_size = hidden_size # 注意RNNCell的形状 self.rnn = torch.nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size, num_layers=num_layers) def forward(self, input): hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size) out, _ = self.rnn(input, hidden) return out.view(-1, self.hidden_size) net = Model(input_size, hidden_size, batch_size, num_layers) criterion = torch.nn.CrossEntropyLoss() # 改进的基于随机梯度下降的优化器 optimizer = torch.optim.Adam(net.parameters(), lr=0.05) # 训练 for epoch in range(15): optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() _, idx = outputs.max(dim=1) idx = idx.data.numpy() print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='') print(', Epoch [%d/15] loss=%.3f' % (epoch+1, loss.item()))
-
5. Embedding
独热编码特点:维度高、稀疏、硬编码
**——>**变成低维度、稠密、从数据学习到的编码
Embedding——将高纬度稀疏样本映射到低维度的稠密空间,也就是数据降维。
import torch
num_class = 4
input_size = 4
hidden_size = 8
embedding_size = 10
num_layers = 2
batch_size = 1
seq_len = 5
idx2char = ['e', 'h', 'l', 'o']
x_data = [[1, 0, 2, 2, 3]] # (batch, seq_len)
y_data = [3, 1, 2, 3, 2] # (batch * seq_len)
inputs = torch.LongTensor(x_data)
labels = torch.LongTensor(y_data)
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.emb = torch.nn.Embedding(input_size, embedding_size)
self.rnn = torch.nn.RNN(input_size=embedding_size,
hidden_size=hidden_size,
num_layers=num_layers,
batch_first=True)
self.fc = torch.nn.Linear(hidden_size, num_class)
def forward(self, x):
hidden = torch.zeros(num_layers, x.size(0), hidden_size)
x = self.emb(x)
x, _ = self.rnn(x, hidden)
x = self.fc(x)
return x.view(-1, num_class)
net = Model()
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.05)
for epoch in range(15):
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
_, idx = outputs.max(dim=1)
idx = idx.data.numpy()
print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='')
print(', Epoch [%d/15] loss = %.3f' % (epoch+1, loss.item()))
6. 其它几种RNN
-
LSTM长短时记忆网络

相关计算公式如下:

-
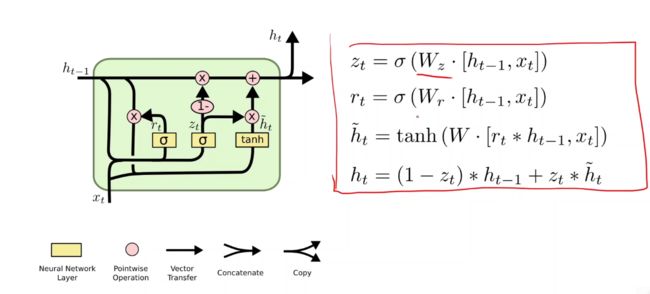
GRU网络
RNN和LSTM的折中
 0922185541105" style="zoom:50%;" />
0922185541105" style="zoom:50%;" />
相关计算公式如下:
-
GRU网络
RNN和LSTM的折中