刘二大人《PyTorch深度学习实践》循环神经网络提升篇
很开心到到今日(2021.12.22) 《PyTorch深度学习实践》这门课已经完成了几乎所有的实验(代码并不是完完全全按照老师PPT里的内容,添加了自己的一些操作和思考吧),对PyTorch有了初步的了解,形成了较为完善的框架,接下来去学CS224自然语言处理和回顾车万翔老师的《自然语言处理:基于与训练模型》。

回到最后一个实验,值得注意的是数据的处理部分以及维度的考虑。
# PyTorch
import torch
from torch.nn.utils.rnn import pack_padded_sequence
from torch.utils import data
from torch import nn
from torch import optim
# Data process
import csv
# For plotting
import matplotlib.pyplot as plt
import os
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
class NameDataSet(data.Dataset):
def __init__(self, path):
super(NameDataSet, self).__init__()
with open(path, 'r') as f:
data_text = list(csv.reader(f))
# print(data_text)
self.names = [row[0] for row in data_text]
self.countries = [row[1] for row in data_text]
self.countries_list = list(sorted(set(self.countries)))
# print(self.countries_list)
self.countries_label = [self.countries_list.index(i) for i in self.countries]
# print(self.countries)
def __getitem__(self, idx):
return self.names[idx], self.countries_label[idx]
def __len__(self):
return len(self.countries)
def idx2country(self, idx):
return self.countries_list[idx]
def get_countries_num(self):
return len(self.countries_list)
batch_size = 256
train_path = 'data/names_train.csv'
train_data = NameDataSet(train_path)
train_iter = data.DataLoader(
dataset=train_data,
shuffle=True,
batch_size=batch_size
)
test_path = 'data/names_test.csv'
test_data = NameDataSet(test_path)
test_iter = data.DataLoader(
dataset=test_data,
shuffle=False,
batch_size=batch_size
)
# SeqLen * BatchSize * InputSize
def make_tensor(names, countries):
label_tensor = torch.tensor(countries, dtype=torch.int64)
names_list = [[ord(i) for i in name] for name in names]
seq_len = torch.tensor([len(name) for name in names])
# BatchSize * SeqLen
max_len = seq_len.max().item()
seq_tensor = torch.zeros(len(seq_len), max_len).long()
for idx, name in enumerate(names_list):
seq_tensor[idx, 0:len(name)] = torch.tensor(name)
# 按照长度排序
seq_len, idx = seq_len.sort(dim=0, descending=True)
seq_tensor, label_tensor = seq_tensor[idx], label_tensor[idx]
return seq_tensor, seq_len, label_tensor
class Module(nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layer=1, bidirectional=True):
super(Module, self).__init__()
self.hidden_size = hidden_size
self.input_size = input_size
self.n_direction = 2 if bidirectional else 1
self.n_layer = n_layer
self.embedding = nn.Embedding(self.input_size, self.hidden_size)
self.gru = nn.GRU(self.hidden_size, self.hidden_size, num_layers=n_layer, bidirectional=bidirectional)
# gru Input Seq, batch, input Output Seq, batch, hidden*nDirection
self.fc = nn.Linear(self.hidden_size * self.n_direction, output_size)
def _init_hidden(self, batch_size):
# 注意,每次调用该函数batch_size会改变
# gru Hidden Input nLayer*nDirection,BatchSize, HiddenSize
# Hidden Output nLayer*nDirection, BatchSize, HiddenSize
hidden = torch.zeros(self.n_layer * self.n_direction, batch_size, self.hidden_size)
return hidden
def forward(self, seq, seq_len):
# BatchSize * SeqLen -> SeqLen * BatchSize
seq = seq.t()
batch_size = seq_len.shape[0]
hidden = self._init_hidden(batch_size)
embedding = self.embedding(seq)
gru_input = pack_padded_sequence(embedding, seq_len)
output, hidden = self.gru(gru_input, hidden)
# 值得注意的是, 我们使用最后一层的hidden作为输出
# n_layer*n_direction, BatchSize, hidden -> Batch, hiddenSize*n_direction
# print('GRU的hidden的shape', hidden.shape)
if self.n_direction == 2:
hidden = torch.cat([hidden[-1], hidden[-2]], dim=1)
# 实际上这里有个问题,对于多层n_layer,如何拿到最后的Hidden_forward和Hidden_back
else:
hidden = hidden[-1]
fc_output = self.fc(hidden)
return fc_output
def test(net, test_iter):
total = 0
correct = 0
with torch.no_grad():
for x, y in test_iter:
seq_tensor, seq_len, label_tensor = make_tensor(x, y)
_y = net(seq_tensor, seq_len)
total += label_tensor.shape[0]
_, pre = torch.max(_y, dim=1)
# print('pre {} label {}'.format(pre.shape, label_tensor.shape))
correct += (pre == label_tensor).sum().item()
return correct / total
if __name__ == '__main__':
# 将128d embedding成 100d
input_size = 128
hidden_size = 100
output_size = train_data.get_countries_num()
n_layer = 1
num_epoch = 100
net = Module(input_size, hidden_size, output_size, n_layer)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001)
acc_set = []
for epoch in range(num_epoch):
total_loss = 0
for names, countries in train_iter:
seq_tensor, seq_len, label_tensor = make_tensor(names, countries)
_y = net(seq_tensor, seq_len)
loss = criterion(_y, label_tensor)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
acc = test(net, test_iter)
acc_set.append(acc)
print('第{}轮, 训练损失为{}, 测试正确率为{}'.format(epoch + 1, total_loss, acc))
plt.figure()
plt.plot([i for i in range(num_epoch)], acc_set)
plt.xlabel('Epoch')
plt.ylabel('Acc')
plt.grid()
plt.show()
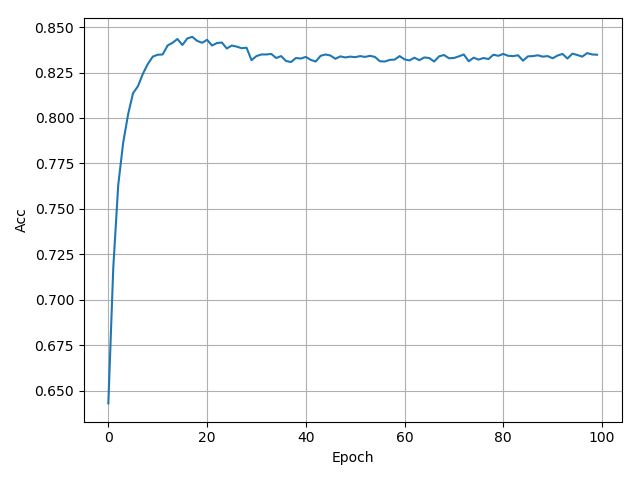
最终的结果如下图所示,实际上也能看出当轮数多了后,有些overfitting